
用 LLM 构建企业专属的用户助手
作者:李粒
文章地址:https://zhuanlan.zhihu.com/p/645658201
转载者:杨夕
【LLMs九层妖塔】 : https://github.com/km1994/LLMsNineStoryDemonTower
推荐系统 百面百搭地址:https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study
TL;DR
本文主要介绍了 PingCAP 如何使用大型语言模型(Large Language Model,LLM)构建一个搭载企业专属知识库的智能客服机器人。除了采用行业内通行的基于知识库的问题解答方法,我们还尝试让模型在“小样本(Few-Shot)”学习下进行不良(毒性)内容识别。本文将详细阐述内测阶段我们是如何对机器人性能进行优化以提高准确度的,包括解决“不准确的不良(毒性)内容识别”、“上下文理解错误”、“语义搜索结果不精确”以及“文档信息不足或过时”等问题。同时,我们也构建了一个内部运营平台,实现对机器人的持续优化和改进。通过这些努力,我们成功地将用户不满意比率由超过 50% 降低到低于 5%。目前,该智能客服机器人已经被广泛应用于 PingCAP 面向全球客户的各类服务渠道。
LLM 的潜力已经显现
自 2022 年以来,大语言模型(LLM)如 ChatGPT 以其自然、流畅的对话让全球瞩目。其中,LangChain 等开发工具的崛起,代表着工程师开始批量地创建基于 LLM 的应用。我们在 PingCAP 也进行了一系列实验,并且陆续完成了一些项目,例如:
OSS Insight 的 Data Explorer:一个用自然语言生成 SQL 以探索 Github 开源软件项目的工具。
TiDB Cloud 的 Chat2Query:一个通过自然语言生成 SQL 来利用 Cloud 内数据库的项目。
在构建了这些应用后,我开始思考是否可以利用 LLM 的能力构建更通用的应用,从而为用户带来更大的价值。
需求考虑
随着全球 TiDB 和 TiDB Cloud 的逐步成长,面向全球用户的支持日益重要。但是,随着用户数量的显著增长,PingCAP 的支持人员数量并未相应增长。因此,如何承接大量用户的请求成为了一个紧迫问题。
根据我们在支持用户方面的经验,以及对全球社区用户提问和内部工单系统的研究,有超过 50% 的用户问题实际上可以在官方文档中找到答案。只不过由于文档内容繁多,用户难以找到所需信息。因此,如果我们能提供一个集成了 TiDB 所有官方文档知识的机器人,可能会帮助用户更好地使用 TiDB。
LLM 的能力与限制
在明确需求后,我们需要了解大语言模型(LLM)的特性和限制,以确定是否可将 LLM 应用于此需求。根据已完成的工作,我们可以总结出 LLM 的以下特性。
LLM 的能力:
理解语义的能力:LLM 具有强大的语义理解能力,能够理解大部分文本,包括不同语言(人类语言或计算机语言)和表达水平的文本,即使是多语言混杂、语法用词错误,也在多数情况下可以理解用户的提问。
逻辑推理的能力:LLM 具有一定的逻辑推理能力,无需额外增加任何特殊提示词,就能做出简单的推理,并挖掘出问题的深层内容。在补充了一定的提示词后,LLM可以展现更强的推理能力,这些提示词的方法包括:Few-Shot,Chain-of-Thought(COT),Self-Consistency,Tree-of-Thought(TOT) 等等。
尝试回答所有问题的能力:特别是 Chat 类型的 LLM,如 GPT-3.5,GPT-4,会尝试以对话形式,回答用户的所有问题,就算是回答“我不能回答这个信息”。
通用知识的能力:LLM 本身拥有海量的通用知识,这些通用知识准确度较高,覆盖范围广泛。
多轮对话的能力:LLM 可以根据设定好的角色,理解不同角色之间的多次对话的含义,这意味着可以在对话中采用追问形式,而不是每一次对话都要把历史所有的关键信息都重复一遍。
LLM 的限制:
被动触发:LLM 是被动触发的,即需要用户输入或给出一段内容,LLM 才会产生回应。因此,LLM 本身无法主动发起交互。
知识过期:特指 GPT-3.5 和 GPT-4,二者的训练数据都截止于 2021 年 9 月,意味着之后的知识,LLM 是不知道的。
细分领域的幻觉:虽然 LLM 在通用知识部分表现优秀,但在特定知识领域,如数据库行业,LLM 的回答往往存在错误,无法直接采信。
对话长度:LLM 每轮对话有字符长度的限制,如果给 LLM 提供的内容超过字符长度,该轮对话会失败。
需求实现的差距
我们期望用 LLM 实现以下需求:
采取多轮对话形式,理解用户的提问,并给出回答。
在回答的内容中,关于 TiDB、TiDB Cloud 的知识点要求准确无误。
不能回答与 TiDB、TiDB Cloud 无关的内容。
对以上需求进行分析:
需求一:基本可以满足,因为 LLM 具有“理解语义的能力”、“逻辑推理的能力”、“尝试回答问题的能力”和“多轮对话的能力”。
需求二:无法满足。因为 LLM 存在“知识过期”和“细分领域的幻觉”这两个限制。
需求三:无法满足。由于 LLM 具有“尝试回答所有问题的能力”,任何问题都会得到回答,而且 LLM 本身并不会限制回答非 TiDB 的问题。
因此,在构建这个助手机器人时,主要的挑战在于如何解决需求二(回答的内容中关于 TiDB、TiDB Cloud 的内容需要正确无误)和需求三(不能回答与 TiDB、TiDB Cloud 无关的内容)的问题。
正确回答细分领域知识
这里讨论针对第二个需求的解决方案。
大型语言模型(LLM)根据特定领域知识来回答用户的问题并非新颖的课题。在之前的项目 Ossinsight - Data Explorer 中,我通过运用特定领域知识,成功提升了自然语言生成 SQL 的可执行率(即,生成的SQL能在TiDB中成功运行并产生结果)25%以上。
为实现这一目标,我们需要利用向量数据库的空间相似度搜索功能,具体分为以下三个步骤:
领域知识存储到向量数据库中
首先,我们需要将 TiDB 和 TiDB Cloud 的官方文档导入到向量数据库中。
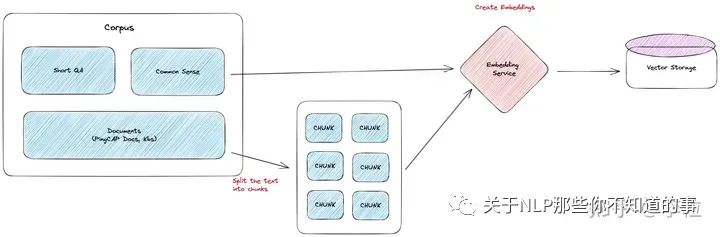
语料放入向量数据库中
当获取到文档后,我们需要将文字内容输入到 Embedding 模型中,生成对应的向量,并将这些向量存储到特定的向量数据库中。
在这个过程中,需要注意的是:
如果文档的质量较差,或者文档的格式不满足预期,我们会首先对文档进行一轮预处理,将文档转化为相对干净,容易被 LLM 理解的文本格式。
如果文档长度超过 LLM 单次的对话长度,我们需要对文档进行裁剪,以满足长度需求。裁剪方法有很多种,比如,按特定字符(如,逗号,句号,分号)裁剪,按文本长度裁剪,等等。
从向量数据库中搜索相关内容
第二步是,当用户提出问题时,我们需要从向量数据库中根据用户的问题搜索相关的文本内容。
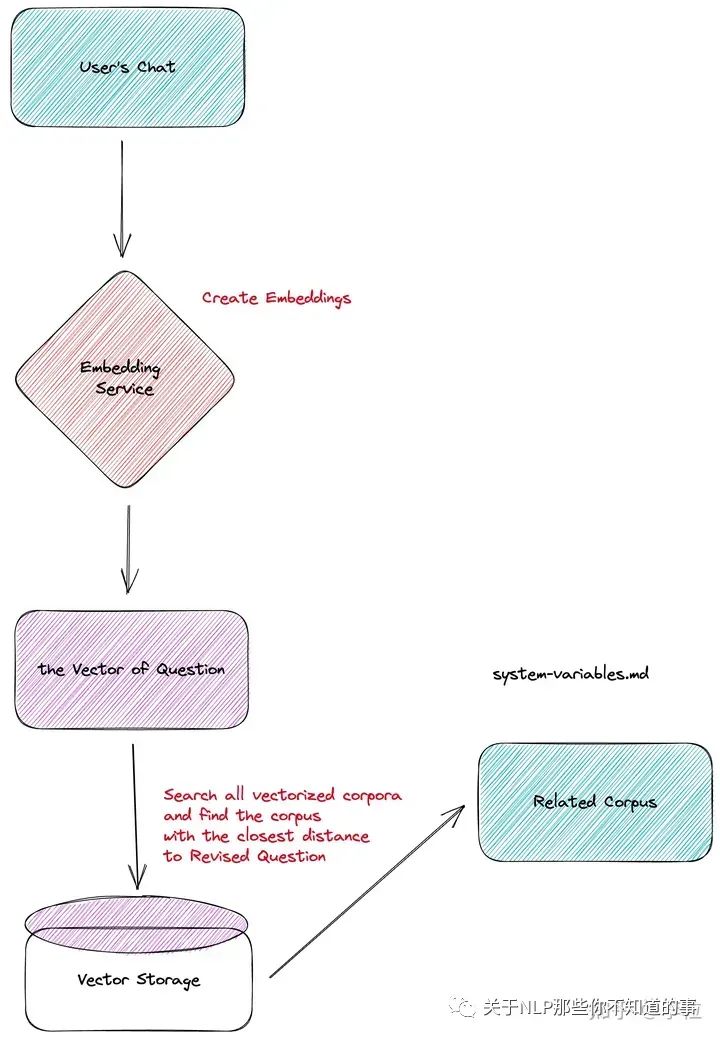
用户提问从向量数据库中搜索语义相关的内容
在用户发起一次对话时,系统会将用户的对话也输入到 Embedding 模型中生成向量,再将这个向量放到向量数据库中和原有的预料进行查询。查询过程中,我们利用相似度算法(比如,Cosine Similarity,Dot-Product,等等),计算出最相似的领域知识向量,并提取出对应向量的文本内容。
考虑到用户的特定问题可能需要多篇文档才能回答,所以在搜索过程中,我们会取相似度最高的 Top N(目前 N 是 5)。这些 Top N 可以满足跨越多个文档的需要,并且都会成为下一步提供给 LLM 的内容。
相关内容和用户提问一起提供给 LLM
最后一步,是组装所有的相关信息,将其提供给 LLM。
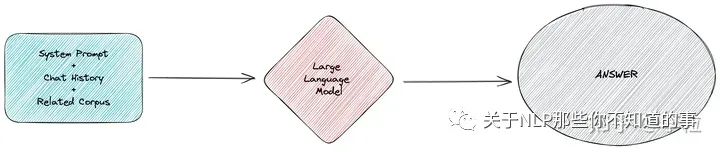
相关的语料内容一起提供给 LLM
我们需要将任务目标和相关的领域知识包含在系统提示语中,同时根据历史对话整理出聊天记录。将所有内容一起提供给 LLM,就可以得到基于这部分领域知识的特定回答。
完成以上步骤后,我们就能基本满足第二个需求,即根据特定领域知识回答问题。与直接向 LLM 提问相比,这种方式能极大提升回答的正确性。
限定回答领域
这里要解决需求三的问题。
该机器人是为了提供企业支持而设立,专门为用户解答和企业相关的问题,比如,TiDB、TiDB Cloud 本身,SQL 问题,应用构建问题等等。如果问题超过这些范围,我们期望机器人拒绝回答,比如,天气、城市、艺术等等。
我们之前提到过 LLM 有“尝试回答所有问题”的能力,但是,对于 LLM 本身的设定,任何问题的回答都应该符合人类的价值观。因此,我们不能仅依赖LLM来构建这一层限制,只能在应用侧进行限制。
只有满足了这个需求,一个业务才有可能真正上线并为用户提供服务。遗憾的是目前工业界没有一个较好的解决方案,大部分的应用设计中并未涉及此问题。
概念:毒性
我们提到,LLM 会努力让其回答符合人类的价值观,这一工作在模型训练中叫做“对齐”(Align),让 LLM 拒绝回答仇恨、暴力相关的问题。如果 LLM 未按照设定回答了仇恨、暴力相关问题,我们就称之为检测出了毒性(Toxicity)。
因此,对于我们即将创造的机器人,其毒性的范围实际上增加了,即,所有回答了非公司业务的内容都可以称之为存在毒性。在此定义下,我们可以参考前人在去毒(Detoxifying)方面的工作。比如,DeepMind 的 Johannes Welbl 等人在 2021 年的研究中介绍了一种采用语言模型进行毒性检测的方法,目前,LLM 的能力得到了足够的加强,用 LLM 来直接判断用户的提问是否属于公司业务范围,这已经成为可能。
“限定回答领域”要实现,需要两个步骤。
限定领域的判断
首先,需要对用户的原始提问进行判断。
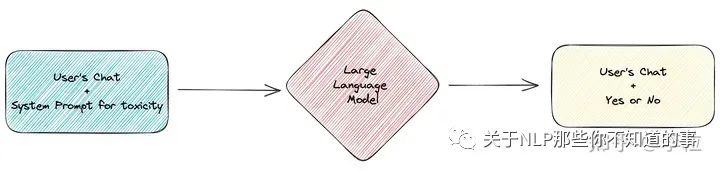
通过 LLM 判断是否有毒
这里需要使用 Few-Shot 的方法去构建毒性检测的提示词,让 LLM 在拥有多个示例的情况下,判断用户的提问是否符合企业服务的范围。
比如一些示例:
<< EXAMPLES >>instruction: who is Lady Gaga?question: is the instruction out of scope (not related with TiDB)?answer: YESinstruction: how to deploy a TiDB cluster?question: is the instruction out of scope (not related with TiDB)?answer: NOinstruction: how to use TiDB Cloud?question: is the instruction out of scope (not related with TiDB)?answer: NO
在判断完成后,LLM 会输出 “Yes” 或 “No”,其中 “Yes” 意味着问题有毒(和业务不相关),“No” 意味着问题无毒(和业务有关),以供后续流程处理。
判断后的处理
第二步,得到了是否有毒的结果后,我们将有毒和无毒的流程分别处理,进行异常流程和正常流程的处理。
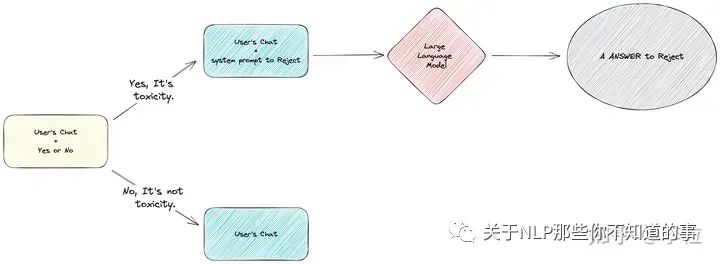
有毒/无毒的执行流程
正常流程是上文中的“正确回答细分领域知识”的相关内容,此处主要说明异常内容的流程。
当系统发现产出的内容是 “Yes” 时,将流程引导进入毒性内容回复环节。此时,会将一个拒绝回答用户问题的系统提示词和用户对应的问题提交给 LLM,最终用户会得到一个拒绝回答的回复。
当完成这两步后,需求三基本完成。
讨论:为什么不直接在 System Prompt 中要求限制输出?
根据我在两种方法中的经验,我得出一个结论:仅在 System Prompt 中要求 LLM 避免回答某个方面的内容是会被恶意攻破的。
在OpenAI的设定中,System Prompt 并没有特殊的权重,这意味着用户在提问时可以输入 ‘Jailbreaking’ 的语句(例如,著名的 DAN 语句)以绕过 System Prompt 的限制。
这个现象可能由以下三个原因引起:
用户的输入很长,比 System Prompt 长很多:一般 Jailbreaking 的语句都很长,远长于绝大部分的 System Prompt,因此模型可能会更倾向于关注更具体的用户请求,而忽略较为模糊的系统提示。
模型的决策权重:GPT-3.5 及其他神经网络语言模型在生成回复时会根据输入文本的权重进行决策。如果 Jailbreaking 部分包含的信息比系统提示更具相关性,模型可能会更关注用户请求的内容。
用户请求的位置:在进行对话式交互时,用户请求通常是在系统提示之后提供的。由于模型是逐词生成回复的,用户请求的信息在输入中出现得更晚,因此可能更影响最终的回复内容。
因此,仅在 System Prompt 中进行限制是不行的,依然会被人 Jailbreaking,这在 LLM 应用到商业产品中是一个极高风险的事情。
而我们采用的判断链避免了这一情况,仅根据上一个 LLM 输出的 Yes 或 No 来知道后续的输出。如果用户尝试 Jailbreaking,那么在进行判断的 LLM 中就会出现非定义的回答,系统可以设定在出现非定义内容时,委婉的拒绝用户的提问。
整体逻辑架构
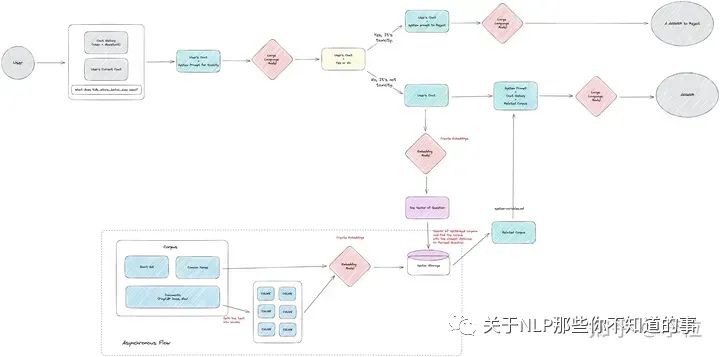
TiDB Bot 的逻辑架构
至此,我们成功开发出了一款具备特定企业领域知识的助手机器人,我们将它命名为 TiDB Bot,它已经可以为用户提供基本的服务。
内测阶段遇到的问题
然而,在首次上线时,模型的回答效果不尽满意,用户反馈中,不满意的比例超过了 50%。
为了对目前存在的问题进行深入分析,我进行了一系列测试,并发现在存在问题的对话中,问题大致可以分为以下几类:
不准确的不良(毒性)内容识别:一些与公司业务相关的问题被模型误判并拒绝回答。例如,“dumpling” 实际上是 TiDB 的一个数据导出工具,但当用户直接提问 “ dumpling 是什么?”时,模型却误以为是关于食物的问题,拒绝回答并建议用户去咨询食物专家。
上下文理解失误:在执行多轮对话时,用户常会对之前的对话内容进行追问,此时他们通常只会简洁地描述,如:“这个参数的默认值是多少?”但是,当我们在向量数据库中使用用户的原始问题进行语义相关内容的搜索时,往往无法得到有意义的答案。这样一来,即使将问题输入到 LLM,也无法根据官方文档给出正确的答案。
语义搜索结果不精确:有时候,用户的问题非常明确,但是由于向量数据库搜索出的内容排序有误,导致在排名前N的答案中无法找到能正确回答问题的文档内容。
文档信息不足或过时:有些情况下,尽管用户的问题表述得很清楚,但由于官方文档不够完整或过时,没有包含相关内容,导致 LLM 在回答时只能凭借猜测,因此,很多时候其给出的答案是错误的。
毒性检测的漏网之鱼
问题分析
虽然我们采用了 Few-Shot 的方法来辅助 LLM 判断用户的问题是否属于 TiDB 业务范围。但是,预设的示例总是有限的,然而实际用户可能会从各种不同的角度提出问题。因此,仅根据系统提示词中的示例,机器人无法做出正确的判断,导致出现漏网之鱼。
解决方案
幸运的是,企业的应用场景总是有限的,因此用户的提问角度理论上也是有限的。理论上,如果我们将所有可能的用户问题都输入给 LLM,LLM 应该能够准确判断出任何问题是否属于TiDB的业务范畴。
那么,如何将所有可能的问题都输入给 LLM 呢?这个场景其实并不孤立,机器人最初的设计中,就是依靠官方文档来回答用户问题的,但是把所有的官方文档都一次性塞入 LLM 中是不现实的,因此我们设计了从向量数据库中按照语义相似度来搜索出相关的文档。在这个场景下,我们也可以使用语义搜索的这一特性来解决这个问题。
实现这个方案,需要做到以下事情:
数据准备
第一步:收集线上和测试中所有的相关问题,进行毒性标记,并且清洗成与现有系统提示词中示例一样的格式。格式如下:
instruction: {user's querstion}question: is the instruction out of scope (not related with TiDB)?answer: YES or NO
数据导入向量数据库中,支持搜索语义相似的结果
第二步:参考 正确回答细分领域知识 的方法,将清洗后的数据放入向量数据库中,并且支持在用户提问的时候,到向量数据库中进行搜索,找到语义最相似的示例,一起提供给 LLM 模型。
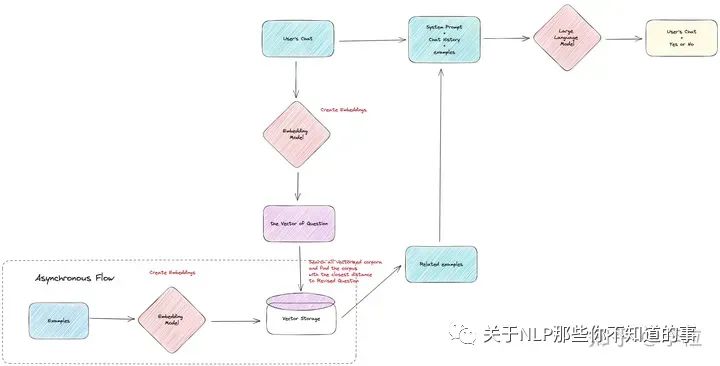
给毒性检测补充示例
这样,LLM 模型在判断问题的毒性时,就会根据最相关的示例来给出尽可能准确的答案。
讨论:示例和领域文档搜索的异同
虽然示例和领域文档的搜索都是在向量数据库中找出语义相似度较高的内容,都使用同一种向量数据库、同样的嵌入模型、相同长度的向量以及相同的相似度计算函数。然而,它们在实际执行上仍然存在一些区别:
在嵌入(Embedding)的内容上:领域知识文档搜索时,需要将文档内容切分成块,然后将所有内容进行嵌入,存储在向量数据库中。而在示例搜索时,只有
instruction部分与用户的提问相关,因此只有instruction部分需要进行嵌入,而answer部分则不需要。在切分上:领域知识文档由于较长,需要切分后进行嵌入。而示例中需要嵌入的都是问题,每个问题都不会太长,不需要切分,可以作为一个独立的块(chunk),这样最终搜索出来的都是独立的问题和答案示例。"
上下文理解的困难
问题分析
LLM 模型具备上下文理解能力,这使得应用可以提供连续对话的特性。然而,如果机器人需要根据上下文动态提供相关的领域知识,一般会遇到一些困难。
当用户在多轮对话中对之前的对话内容进行追问,如:“这个参数默认值是多少?”时,系统会直接使用这个问题在向量数据库中对领域知识进行搜索,这样搜索出来的结果的质量通常很差。
解决方案
这个问题的本质原因在于,人类聊天时主观上都带有上下文语义,而系统却无法理解。好在 LLM 模型具备上下文理解能力,因此,一个简单的解决方案就是,让 LLM 在系统进行领域知识搜索前对用户的原始提问进行改写,尽可能地用一句话描述清楚用户的意图,这种操作被称为“修订问题”(revise question)。
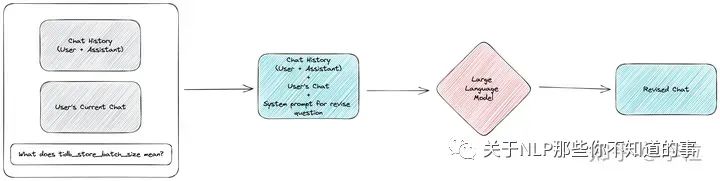
修订用户的提问
为了保证整个机器人系统中面对的用户问题保持一致,避免因为问题不一致导致的错误,我们将修订问题特性放在了系统信息流的最前面,让用户问题刚刚进入机器人就进行修订。
修订时,机器人会要求 LLM 模型根据整体对话的上下文来用一句话描述用户提问的意图,尽可能补充详细信息。这样无论是在毒性检测还是在领域知识搜索中,系统都可以根据更具体的意图来执行。
如果在修订问题中发现了明显的错误怎么办?事实上也可以利用 few shot + 语义搜索 的办法,特定的优化这些错误。
为了保证整个机器人系统中面对的用户问题保持一致,避免因为问题不一致导致的错误,我们将修订问题步骤放在了系统信息流的最前面,让用户的问题在进入机器人时就进行修订。
在修订问题的过程中,我们会要求 LLM 模型根据整体对话的上下文来用一句话描述用户提问的意图,尽可能补充详细信息。这样无论是在毒性检测还是在领域知识搜索中,系统都可以根据更具体的意图来执行。
如果在修订问题中发现了明显的错误,我们也可以利用 Few-Shot 和语义搜索的方法来优化这些错误。
语义搜索的局限
讨论:语义搜索的流程和优化方法
在探讨“利用向量做语义搜索的方法是 TiDB Bot(一款基于算法的对话机器人)的基石”之前,我们需要了解仅依赖 LLM 模型自身的能力,是无法如此简单的搭建一个机器人,为用户回答特定细分领域的知识。因此,熟知这个基石的内容,尤其是其潜在的问题,才能找到一些正向优化的方法。
为了优化领域知识数据准备、切分、向量化、搜索的过程,在此分享一些我尝试过的优化方法:
数据准备阶段的优化方法:对文档进行清洗,剔除图片,链接,及其他无意义的符号和文档结构。
切分阶段的优化方法:使用不同方法对文档进行切分(Split),如按 token 切分,按自然段切分,按符号切分等等。切分后是否需要提供一定的重复(Overlap),重复的比例多少比较合适。
向量化阶段的优化方法:Embedding 模型是使用未开源的模型还是开源模型,使用多长的向量,是否支持多语言的向量化。使用开源模型如何进行微调(fine-tuning),微调的语料怎么准备,微调的 epoch 和轮次怎么处理能让模型训练高质量收敛。
语义搜索阶段的优化方法:使用哪一种相似度算法最优,使用多少文档内容搜索满足意图,搜索出来后切分的内容是否需要再次聚合。
以上的方法的优点:
每一种方法都是系统的解决方案,能够对所有的领域知识文档都有效,没有倾向性。
数据准备和切分的阶段方法基本上可以稳定的正向优化,可以更高质量的数据材料。
缺点:
关键的向量化和语义搜索阶段的优化方法,无法做到稳定正向优化,优化方向是随机的,模型在增强了一方面的能力后,可能会造成另一能力弱化。
每一个优化都需要深刻的理解业务和优化方法的结合关系,需要在业务测试集下反复进行微调,不断试验,加深技术和业务适配性的理解,才有机会得到相对较好的效果。
问题分析
在内测阶段,经常遇到的问题是:用户的提问很清楚,但是向量数据库搜索出的 Top N 中无法看到对应的文档内容。这意味着系统内并不是没有问题相关的文档,而是没有搜索出来。这有几种可能性:
文档写的不够好,过于隐晦,语义相似度很难检索。
Embedding 模型有待加强,用户提问与直接相关的领域知识之间的向量距离不是最近。
相似度算法不是最优,可以尝试其他相似度算法来解决。
而要去解决这几种可能性问题,会需要若干个月的时间,可能会有一些提升,但是也不能确保提升的效果。因此,想要稳定地提升语义搜索的产出质量,其实有两个直接、有效、快速实现的方法:
一、直接调整领域内容和提问之间的向量距离。
二、在召回领域知识的内容之外,额外召回特定内容的示例。
这两个方法都可以在系统提示词中提供争取的信息,但是二者优缺点不同:
方法一
缺点:
直接调整向量距离,需要移动、旋转现有的向量,会对用户提出的其他问题造成影响,破坏整体领域知识向量分布。
直接调整向量距离,也可以用一个额外的度量、函数来表达新的向量距离,但是直接创造了一个新的相似度函数,新的函数不一定能解决问题。
方法二
优点:
在系统提示词中额外引入了一个新的内容(示例),不影响原有的领域知识的向量空间,相对解耦。
而且自由度相对高,在未来可以快速进行补充和删除。
缺点:
当领域知识更新时,需要在示例部分也进行更新,需要有额外的流程。
反馈信息展示:展示用户对回复的点赞或点踩。针对点踩的信息,展示信息流上每一个节点的处理日志,方便进行问题排查。
示例快速补充:针对每一个与 LLM 交互的节点,都支持提供示例的能力,包括修订问题,毒性检测,领域知识,等所有环节,都能够快速补充示例。
领域知识自动更新:对于有固定来源的领域知识,如官方文档,支持定时自动更新向量数据库中的文档内容,保持领域知识始终最新。
模型迭代数据整理:自动整理 Embedding 模型微调所需的训练数据,包含用户的点赞信息和运营时补充的示例信息等。
模型微调的方法:
优点:
有机会全面提升在特定领域下的回答质量。
一旦训练成功后,回答问题所需的领域知识要求会下降,节约后期领域知识的收集成本。
训练成本可以接受。从开源社区看到使用 Low-Rank Adaptation of Large Language Models(LoRA)方式微调一个模型仅需要 V100 显卡花费 8 小时就可以收敛。
缺点:
需要收集并预处理大量的高质量领域数据。如果需要 Full Fine-Tuning(FFT) 的方法需要 10 万条以上的语料,如果使用 Parameter-Efficient Fine-Tuning(PEFT) 的方法也需要 5 万条以上的语料。
训练效果不明确。训练后,虽然提升了领域知识的回答能力,但在其他通用知识能力、推理能力会下降。在真实面对用户提问时,可能导致无法很好推理而让回答问题的能力变得更差。因为微调的方法是基于一个已有模型来训练,因此无论是变好还是变差都是基于已有模型而言的,如果找到好的已有模型就可以让微调模型有一个更高的起点。
开源的模型质量无法和 OpenAI 媲美。虽然训练成本有机会降低让训练成为可能,目前仍然没有学界或工业界报告能够产出和 OpenAI 相似能力的开源模型。
每次迭代时间较长。每次迭代(以月为单位)需要经历一遍或几遍数据准备、训练、测试流程,才有机会得到一个可用的模型。特别是数据准备,在没有实际训练过几遍之前,可能都无法准备出高质量的训练数据集。
持续运营的方法:
优点:
相对稳定的正向优化。本文采用了系统的方法去优化准确率,而不依赖模型训练产出的随机性。
快速。示例部分的优化可以达到分钟级别的迭代速度,如果用户在使用过程中遇到问题,可以尽快修复。
便宜。仅需要复用已有的语义搜索能力,不需要额外的组件,不额外支出成本。
迁移成本低。本文的方法在任何 Chat 类型的 LLM 模型都可用,因此可以快速迁移到其他模型上。如果开源或商业模型中有更好的模型,我们可以尽快接入。
冷启动友好。遇到问题解决问题,不需要事先准备庞大的训练数据。
缺点:
需要更高频的人工介入。因为示例的方法需要更多的人工审核和补充过程,在产品运营过程中需要比模型微调更高频的人工介入频率。
内容数量过多。在运营一段时间后,补充的内容可能过多,导致难以维护,和搜索准确性的下降。
考虑到系统维护的简单性,优化的实时性,我们最终选择了方法二。
解决方案
我们主要运用的是示例+训练 Embedding 模型的方法。
第一步,先用类似 毒性检测的漏网之鱼 的方法,额外针对易错点补充示例,并将这些示例也随系统提示词一同提供给 LLM 模型,提高准确率。
第二步,在示例积累到一定数量,将示例内容作为训练数据,去训练 Embedding 模型,让 Embedding 模型能更好地理解提问和领域知识之间的相似关系,产出更合适的向量数据结果。
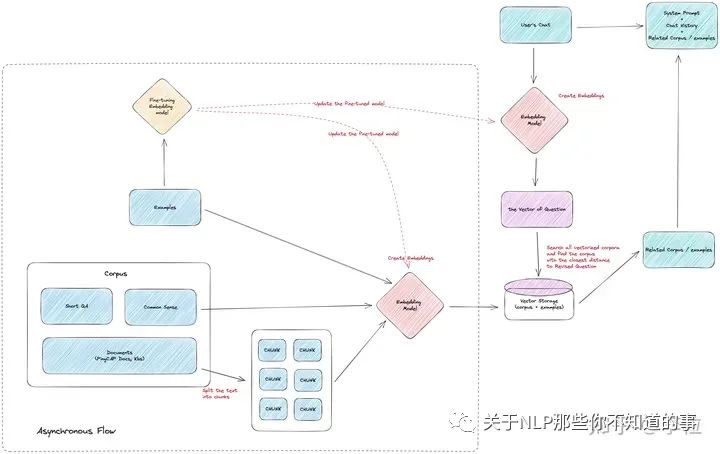
补充示例和更新 Embedding 模型
在实际的工作中,循环使用第一、二步,可以保持示例的数量在一个可以维护的水平,并且能够持续促进 Embedding 模型变得更好。
垃圾进,垃圾出
问题分析
机器学习中最著名的一句话:垃圾进,垃圾出(Garbage In, Garbage Out),意思是:如果将错误的、无意义的数据输入模型中,模型自然也一定会输出错误、无意义的结果。因此,如果领域文档内容质量较差,或者时效性已过,那么 LLM 模型最终给出的回答的质量大概率也很差。
解决方案
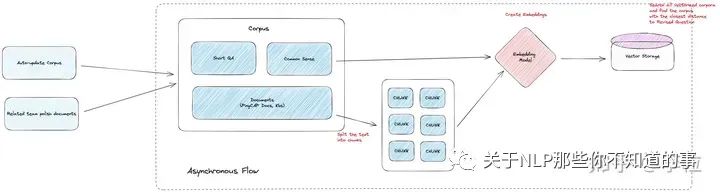
定期更新语料库
我们建立了定期更新领域知识文档的能力,并且在用户反馈错误时,将对应的文档提交给相应的团队,促进领域文档的更新和丰富。
通往产品可用的唯一法则:持续运营
以上的方法是是我们在优化 TiDB Bot 中的一些尝试,这些方法都能够一定程度上优化机器人的回复准确度,但是要将超过 50% 的点踩率优化到低于 5%,这需积跬步,才可至千里。
为了让 TiDB Bot 的优化能够持续进行,我们搭建了一个内部运营平台,该平台能够较为便利的实现本文介绍的几种优化方法。该平台的核心能力有:
最终我们利用这个运营平台,在 103 天的时间逐步提升准确率,最终在社区测试用户的帮助下成功上线。
讨论:模型微调和持续运营的选择
这里的“模型微调”指的是直接使用微调(fine-tuning)的方法使用更多的领域数据来训练模型,包括 Embedding 模型和 LLM 模型。而“持续运营”是指类似本文的做法,利用更多高质量的领域知识和示例,以及尝试与 LLM 进行多次交互,正向提升应用的准确性的做法。
很多人会问,本文为什么重点强调了持续运营的方法,而没有去强调模型微调的方法?为了回答这个问题,需要先看看两种方法的优缺点:
从上文可以看出,两种方法各有优缺点。其实二者并不是对立的,而是相辅相成的,比如,我们对 Embedding 模型进行了微调。
在 TiDB Bot 的前期,我们更倾向于持续运营的方法,利用系统的方法来进行稳定、便宜、快速的正向优化,确保整个团队专注在业务问题上。也许在 TiDB Bot 发展到中后期时,可以考虑模型微调的方法来进行更多的优化。
包含优化方法的整体逻辑架构
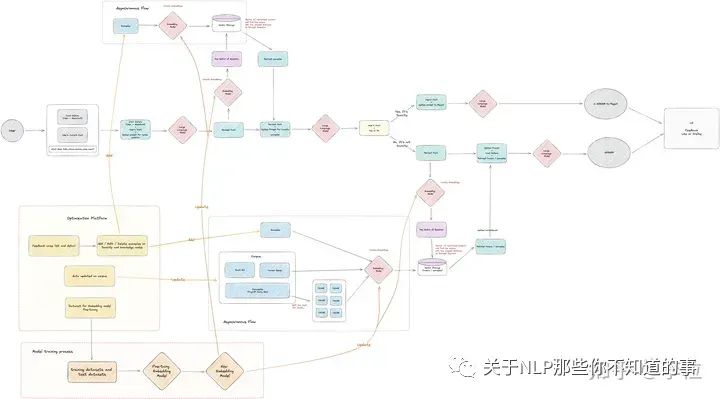
TiDB Bot 的整体逻辑架构
至此,TiDB Bot 得到了可持续优化的能力。
TiDB Bot 测试阶段效果
从3月30日起,TiDB Bot 就开始进行内部测试,直到7月11日正式对 Cloud 的用户开放。
在 TiDB Bot 孵化的 103 天来,感谢无数的社区、开发者对测试产品提出的反馈,让 TiDB Bot 逐步变得可用。在测试阶段,一共 249 名用户使用,发送了 4570 条信息。到测试阶段完成为止,共有 83 名用户给出了 266 条反馈,其中不满意的比例从最初一个月超过 50% 降低到了最终的 3.4%,满意的比例达到了 2.1%。
除了直接使用的社区用户,还有提出建议和思路的用户,给出更多解决方案的社区用户。感谢所有的社区和开发者,没有你们,就没有 TiDB Bot 产品发布。
后续
TiDB Bot 已经在 TiDB Cloud、Slack、Discord 频道上线,欢迎大家使用。
在未来,我们会提供构建类似 TiDB Bot 应用的开源工具,让所有人都能够快速构建自己的 LLM 应用。