
图像处理中的经典机器学习方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在本章中,我们将讨论机器学习技术在图像处理中的应用。首先,定义机器学习,并学习它的两种算法——监督算法和无监督算法;其次,讨论一些流行的无监督机器学习技术的应用,如聚类和图像分割等问题。
我们还将研究监督机器学习技术在图像分类和目标检测等问题上的应用。使用非常流行的scikit-learn库,以及scikit-image和Python-OpenCV(cv2)来实现用于图像处理的机器学习算法。在本章中,我们将带领读者深入了解机器学习算法及其解决的问题。
本章主要包括以下内容:
监督与无监督学习;
无监督机器学习——聚类、PCA和特征脸;
监督机器学习——基于手写数字数据集的图像分类;
监督机器学习——目标检测。
机器学习算法主要有以下两种类型。
(1)监督学习:在这种类型的学习中,我们得到输入数据集和正确的标签,需要学习输入和输出之间的关系(作为函数)。手写数字分类问题是监督(分类)问题的一个例子。
(2)无监督学习:在这种类型的学习中,很少或根本不知道输出应该是什么样的。人们可以推导得到数据的结构而不必知道变量影响。聚类(也可以看作分割)就是一个很好的例子,在图像处理技术中,并不知道哪个像素属于哪个段。
如果计算机程序在T上的性能正如P所度量的,随着经验E而提高,那么对于某些任务T和某些性能度量P,计算机程序被设计成能够从经验E中学习。
例如,假设有一组手写数字图像及其标签(从0到9的数字),需要编写一个Python程序,该程序学习了图片和标签(经验E)之间的关联,然后自动标记一组新的手写数字图像。
在本例中,任务T是为图像分配标签(即对数字图像进行分类或标识),程序中能够正确识别的新图像的比例为性能P(准确率)。在这种情况下,这个程序可以说是一个学习程序。
本章将描述一些可以使用机器学习算法(无监督或监督)解决的图像处理问题。读者将从学习一些无监督机器学习技术在解决图像处理问题中的应用开始。
本节将讨论一些流行的机器学习算法及其在图像处理中的应用。从某些聚类算法及其在颜色量化和图像分割中的应用开始。使用scikit-learn库实现这些聚类算法。
基于图像分割与颜色量化的k均值聚类算法
本节将演示如何对pepper图像执行像素矢量量化(VQ),将显示图像所需的颜色数量从250种减少到4种,同时保持整体外观质量。在本例中,像素在三维空间中表示,使用k均值查找4个颜色簇。
在图像处理文献中,码本是从k均值(簇群中心)获得的,称为调色板。在调色板中,使用1个字节最多可寻址256种颜色,而RGB编码要求每个像素3个字节。GIF文件格式使用这样的调色板。为了进行比较,还使用随机码本(随机选取的颜色)的量化图像。
在使用k均值聚类算法对图像进行分割前,加载所需的库和输入图像,如下面的代码所示:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansfrom sklearn.metrics import pairwise_distances_argminfrom skimage.io import imreadfrom sklearn.utils import shufflefrom skimage import img_as_floatfrom time import timepepper = imread("../images/pepper.jpg")# Display the original imageplt.figure(1), plt.clf()ax = plt.axes([0, 0, 1, 1])plt.axis('off'), plt.title('Original image (%d colors)'%(len(np.unique(pepper)))), plt.imshow(pepper)
输入的辣椒原始图像如图1所示。

图1 辣椒图像
现在,应用k均值聚类算法对图像进行分割,如下面的代码所示:
n_colors = 64# Convert to floats instead of the default 8 bits integer coding. Dividingby# 255 is important so that plt.imshow behaves works well on float data# (need tobe in the range [0-1])pepper = np.array(pepper, dtype=np.float64) / 255# Load Image and transform to a 2D numpy array.w, h, d = original_shape = tuple(pepper.shape)assert d == 3image_array = np.reshape(pepper, (w * h, d))def recreate_image(codebook, labels, w, h):"""Recreate the (compressed) image from the code book & labels"""d = codebook.shape[1]image = np.zeros((w, h, d))label_idx = 0for i in range(w):for j in range(h):image[i][j] = codebook[labels[label_idx]]label_idx += 1return image# Display all results, alongside original imageplt.figure(1)plt.clf()ax = plt.axes([0, 0, 1, 1])plt.axis('off')plt.title('Original image (96,615 colors)')plt.imshow(pepper)plt.figure(2, figsize=(10,10))plt.clf()i = 1for k in [64, 32, 16, 4]:t0 = time()plt.subplot(2,2,i)plt.axis('off')image_array_sample = shuffle(image_array, random_state=0)[:1000]kmeans = KMeans(n_clusters=k, random_state=0).fit(image_array_sample)print("done in %0.3fs." % (time() - t0))# Get labels for all pointsprint("Predicting color indices on the full image (k-means)")t0 = time()labels = kmeans.predict(image_array)print("done in %0.3fs." % (time() - t0))plt.title('Quantized image (' + str(k) + ' colors, K-Means)')plt.imshow(recreate_image(kmeans.cluster_centers_, labels, w, h))i += 1plt.show()plt.figure(3, figsize=(10,10))plt.clf()i = 1for k in [64, 32, 16, 4]:t0 = time()plt.subplot(2,2,i)plt.axis('off')codebook_random = shuffle(image_array, random_state=0)[:k + 1]print("Predicting color indices on the full image (random)")t0 = time()labels_random = pairwise_distances_argmin(codebook_random,image_array,axis=0)print("done in %0.3fs." % (time() - t0))plt.title('Quantized image (' + str(k) + ' colors, Random)')plt.imshow(recreate_image(codebook_random, labels_random, w, h))i += 1plt.show()
运行上述代码,输出结果如图2所示。可以看到,在保留的图像质量方面,k均值聚类算法对于颜色量化的效果总是比使用随机码本要好。
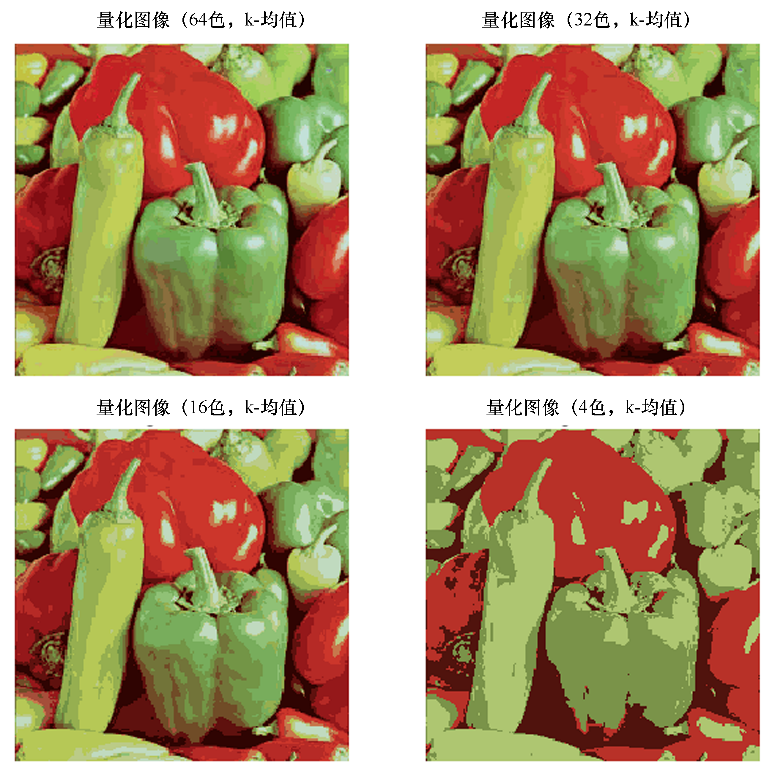

图2 使用k均值聚类算法进行辣椒图像分割与颜色量化
由于图像分割的谱聚类算法
本节将演示如何将谱聚类技术用于图像分割。在这些设置中,谱聚类方法解决了称为归一化图割的问题——图像被看作一个连通像素的图,谱聚类算法的实质是选择定义区域的图切分,同时最小化沿着切分的梯度与区域体积的比值。来自scikit-learn聚类模块的SpectralClustering()将用于将图像分割为前景和背景。
将使用谱聚类算法得到的图像分割结果与使用k均值聚类得到的二值分割结果进行对比,如下面的代码所示:
from sklearn import clusterfrom skimage.io import imreadfrom skimage.color import rgb2grayfrom scipy.misc import imresizeimport matplotlib.pylab as pylabim = imresize(imread('../images/me14.jpg'), (100,100,3))img = rgb2gray(im)k = 2 # binary segmentation, with 2 output clusters / segmentsX = np.reshape(im, (-1, im.shape[-1]))two_means = cluster.MiniBatchKMeans(n_clusters=k, random_state=10)two_means.fit(X)y_pred = two_means.predict(X)labels = np.reshape(y_pred, im.shape[:2])pylab.figure(figsize=(20,20))pylab.subplot(221), pylab.imshow(np.reshape(y_pred, im.shape[:2])),pylab.title('k-means segmentation (k=2)', size=30)pylab.subplot(222), pylab.imshow(im), pylab.contour(labels == 0,contours=1, colors='red'), pylab.axis('off')pylab.title('k-means contour (k=2)', size=30)spectral = cluster.SpectralClustering(n_clusters=k, eigen_solver='arpack',affinity="nearest_neighbors", n_neighbors=100, random_state=10)spectral.fit(X)y_pred = spectral.labels_.astype(np.int)labels = np.reshape(y_pred, im.shape[:2])pylab.subplot(223), pylab.imshow(np.reshape(y_pred, im.shape[:2])),pylab.title('spectral segmentation (k=2)', size=30)pylab.subplot(224), pylab.imshow(im), pylab.contour(labels == 0,contours=1, colors='red'), pylab.axis('off'), pylab.title('spectral contour(k=2)', size=30), pylab.tight_layout()pylab.show()
运行上述代码,输出结果如图3所示。可以看到,谱聚类算法相比k均值聚类算法对图像的分割效果更好。

图3 使用谱聚类与k均值聚类算法得到的图像分割结果对比
PCA与特征脸
主成分分析(PCA)是一种统计/非监督机器学习方法,它使用一个正交变换将一组观测可能相关的变量转化为一组线性不相关的变量的值,从而在数据集中发现最大方向的方差(沿着主要成分)。
这可以用于(线性)降维(只有几个突出的主成分在大多数情况下捕获数据集中的几乎所有方差)和具有多个维度的数据集的可视化(在二维空间中)。PCA的一个应用是特征面,找到一组可以(从理论上)表示任意面(作为这些特征面的线性组合)的特征面。
1.用PCA降维及可视化
在本节中,我们将使用scikit-learn的数字数据集,其中包含1797张手写数字的图像(每张图像的大小为8×8像素)。每一行表示数据矩阵中的一幅图像。用下面的代码加载并显示数据集中的前25位数字:
import numpy as npimport matplotlib.pylab as pltfrom sklearn.datasets import load_digitsfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCAfrom sklearn.pipeline import Pipelinedigits = load_digits()#print(digits.keys())print(digits.data.shape)j = 1np.random.seed(1)fig = plt.figure(figsize=(3,3))fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05,wspace=0.05)for i in np.random.choice(digits.data.shape[0], 25):plt.subplot(5,5,j), plt.imshow(np.reshape(digits.data[i,:], (8,8)),cmap='binary'),plt.axis('off')j += 1plt.show()
运行上述代码,输出数据集中的前25位手写数字,如图4所示。

图4 数据集中的前25个数字
二维投影与可视化。从加载的数据集可以看出,它是一个64维的数据集。现在,首先利用scikit-learn的PCA()函数来找到这个数据集的两个主要成分并将数据集沿着两个维度进行投影;其次利用Matplotlib和表示图像(数字)的每个数据点,对投影数据进行散点绘图,数字标签用一种独特的颜色表示,如下面的代码所示:
pca_digits=PCA(2)digits.data_proj = pca_digits.fit_transform(digits.data)print(np.sum(pca_digits.explained_variance_ratio_))# 0.28509364823696987plt.figure(figsize=(15,10))plt.scatter(digits.data_proj[:, 0], digits.data_proj[:, 1], lw=0.25,c=digits.target, edgecolor='k', s=100, cmap=plt.cm.get_cmap('cubehelix',10))plt.xlabel('PC1', size=20), plt.ylabel('PC2', size=20), plt.title('2DProjection of handwritten digits with PCA', size=25)plt.colorbar(ticks=range(10), label='digit value')plt.clim(-0.5, 9.5)
运行上述代码,输出结果如图5所示。可以看到,在沿PC1和PC2两个方向的二维投影中,数字有某种程度的分离(虽然有些重叠),而相同的数字值则出现在集群附近。
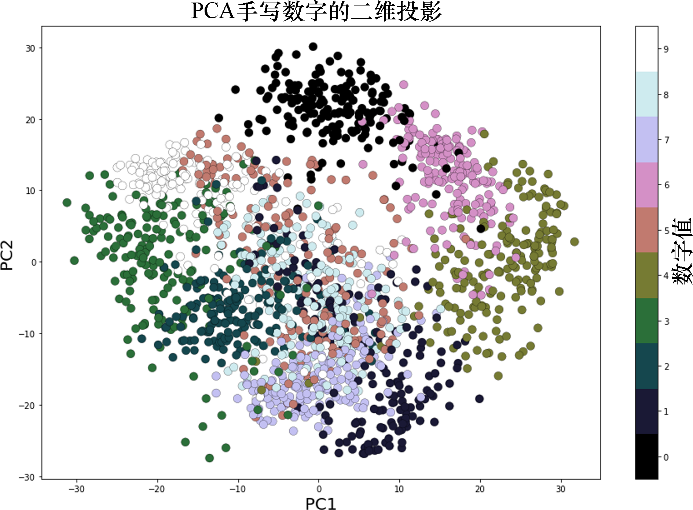
图5 利用PCA进行手写数字的二维投影的颜色散布图
2.基于PCA的特征脸
加载scikit-learn包的olivetti人脸数据集,其中包含400张人脸图像,每张图像的大小为64×64像素。如下代码显示了数据集中的一些随机面孔:
from sklearn.datasets import fetch_olivetti_facesfaces = fetch_olivetti_faces().dataprint(faces.shape) # there are 400 faces each of them is of 64x64=4096 pixelsfig = plt.figure(figsize=(5,5))fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)# plot 25 random facesj = 1np.random.seed(0)for i in np.random.choice(range(faces.shape[0]), 25):ax = fig.add_subplot(5, 5, j, xticks=[], yticks=[])ax.imshow(np.reshape(faces[i,:],(64,64)), cmap=plt.cm.bone,interpolation='nearest')j += 1plt.show()
运行上述代码,输出从数据集中随机选取的25张人脸图像,如图6所示。

图6 从数据集中随机选取的人脸图像
接下来,对数据集进行预处理,在对图像应用PCA之前先执行z分数归一化(从所有人脸中减去平均人脸,然后除以标准差),这是必要的步骤;然后,使用PCA()计算主成分,只选取64个(而不是4096个)主成分,并将数据集投射到PC方向上,如下面的代码所示,并通过选择越来越多的主成分来可视化图像数据集的方差。
from sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCAfrom sklearn.pipeline import Pipelinen_comp =64pipeline = Pipeline([('scaling', StandardScaler()), ('pca',PCA(n_components=n_comp))])faces_proj = pipeline.fit_transform(faces)print(faces_proj.shape)# (400, 64)mean_face = np.reshape(pipeline.named_steps['scaling'].mean_, (64,64))sd_face = np.reshape(np.sqrt(pipeline.named_steps['scaling'].var_),(64,64))pylab.figure(figsize=(8, 6))pylab.plot(np.cumsum(pipeline.named_steps['pca'].explained_variance_ratio_), linewidth=2)pylab.grid(), pylab.axis('tight'), pylab.xlabel('n_components'),pylab.ylabel('cumulative explained_variance_ratio_')pylab.show()pylab.figure(figsize=(10,5))pylab.subplot(121), pylab.imshow(mean_face, cmap=pylab.cm.bone),pylab.axis('off'), pylab.title('Mean face')pylab.subplot(122), pylab.imshow(sd_face, cmap=pylab.cm.bone),pylab.axis('off'), pylab.title('SD face')pylab.show()
运行上述代码,输出结果如图7所示。可以看到,大约90%的方差仅由前64个主成分所主导。
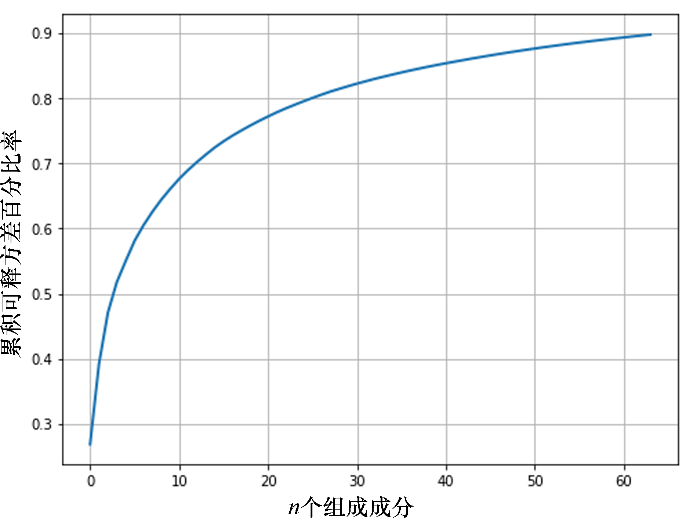
图7 64个主成分的累积方差占比
从数据集中计算得到的人脸图像的均值和标准差如图8所示。

图8 人脸图像数据集的均值与标准差图像
(1)特征脸。在主成分分析的基础上,计算得到的两PC方向相互正交,每个PC包含4096个像素,并且可以重构成大小的64×64像素的图像。称这些主成分为特征脸(因为它们也是特征向量)。
可以看出,特征脸代表了人脸的某些属性。如下代码用于显示一些计算出来的特征脸:
fig = plt.figure(figsize=(5,2))fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05,wspace=0.05)# plot the first 10 eigenfacesfor i in range(10):ax = fig.add_subplot(2, 5, i+1, xticks=[], yticks=[])ax.imshow(np.reshape(pipeline.named_steps['pca'].components_[i,:],(64,64)), cmap=plt.cm.bone, interpolation='nearest')
运行上述代码,输出前10张特征脸,如图9所示。

图9 主成分重构的前10张特征脸
(2)重建。如下代码演示了如何将每张人脸近似地表示成这64张主要特征脸的线性组合。使用scikit-learn中的inverse_transform()函数变换回到原空间,但是只基于这64张主特征脸,而抛弃所有其他特征脸。
# face reconstructionfaces_inv_proj = pipeline.named_steps['pca'].inverse_transform(faces_proj)#reshaping as 400 images of 64x64 dimensionfig = plt.figure(figsize=(5,5))fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05,wspace=0.05)# plot the faces, each image is 64 by 64 dimension but 8x8 pixelsj = 1np.random.seed(0)for i in np.random.choice(range(faces.shape[0]), 25):ax = fig.add_subplot(5, 5, j, xticks=[], yticks=[])ax.imshow(mean_face + sd_face*np.reshape(faces_inv_proj,(400,64,64))[i,:], cmap=plt.cm.bone, interpolation='nearest')j += 1
运行上述代码,从64张特征人脸中随机选择25张重建的人脸图像,如图10所示。可以看到,它们看起来很像原始的人脸(没有很多明显的错误)。

图10 由特征人脸重建的人脸图像
如下代码有助于更近距离地观察原始人脸,并将其与重建后的人脸进行对比:如下代码的输出结果如图11所示。可以看到,重构后的人脸与原始人脸近似,但存在某种程度的失真。
orig_face = np.reshape(faces[0,:], (64,64))reconst_face =np.reshape(faces_proj[0,:]@pipeline.named_steps['pca'].components_,(64,64))reconst_face = mean_face + sd_face*reconst_faceplt.figure(figsize=(10,5))plt.subplot(121), plt.imshow(orig_face, cmap=plt.cm.bone,interpolation='nearest'), plt.axis('off'), plt.title('original', size=20)plt.subplot(122), plt.imshow(reconst_face, cmap=plt.cm.bone,interpolation='nearest'), plt.axis('off'), plt.title('reconstructed',size=20)plt.show()

图11 重建后的人脸图像与原始人脸图像对比
(3)特征分解。每张人脸都可以表示为64张特征脸的线性组合。每张特征脸对于不同的人脸图像有不同的权重(负载)。图12显示了如何用特征脸表示人脸,并显示了前几个相应的权重。其实现代码留给读者作为练习。

图12 由特征脸进行线性组合,重建人脸图像
在本节中,我们将讨论图像分类问题。使用的输入数据集是MNIST,这是机器学习中的一个经典数据集,由28像素×28像素的手写数字的灰度图像组成。
原始训练数据集包含60000个样本(手写数字图像和标签,用于训练机器学习模型),测试数据集包含10000个样本(手写数字图像和标签作为基本事实,用于测试所学习模型的准确性)。给定一组手写数字和图像及其标签(0~9),目标是学习一种机器学习模型,该模型可以自动识别不可见图像中的数字,并为图像分配一个标签(0~9)。具体步骤如下。
(1)首先,使用训练数据集训练一些监督机器学习(多类分类)模型(分类器)。
(2)其次,它们将用于预测来自测试数据集的图像的标签。
(3)然后将预测的标签与基本真值标签进行比较,以评估分类器的性能。
训练、预测和评估基本分类模型的步骤如图13所示。当在训练数据集上训练更多不同的模型(可能是使用不同的算法,或者使用相同的算法但算法具有不同的超参数值)时,为了选择最好的模型,需要第三个数据集,也就是验证数据集(训练数据集分为两部分,一个用于训练,另一个待验证),用于模型选择和超参调优。

图13 监督机器学习图像分类的流程
同样,先导入所需的库,如下面的代码所示:
%matplotlib inlineimport gzip, os, sysimport numpy as npfrom scipy.stats import multivariate_normalfrom urllib.request import urlretrieveimport matplotlib.pyplot as pylab
下载MNIST(手写数字)数据集
从下载MNIST数据集开始。如下代码展示了如何下载训练数据集和测试数据集:
# Function that downloads a specified MNIST data file from Yann Le Cun's websitedef download(filename, source='http://yann.lecun.com/exdb/mnist/'):print("Downloading %s" % filename)urlretrieve(source + filename, filename)# Invokes download() if necessary, then reads in imagesdef load_mnist_images(filename):if not os.path.exists(filename):download(filename)with gzip.open(filename, 'rb') as f:data = np.frombuffer(f.read(), np.uint8, offset=16)data = data.reshape(-1,784)return datadef load_mnist_labels(filename):if not os.path.exists(filename):download(filename)with gzip.open(filename, 'rb') as f:data = np.frombuffer(f.read(), np.uint8, offset=8)return data## Load the training settrain_data = load_mnist_images('train-images-idx3-ubyte.gz')train_labels = load_mnist_labels('train-labels-idx1-ubyte.gz')## Load the testing settest_data = load_mnist_images('t10k-images-idx3-ubyte.gz')test_labels = load_mnist_labels('t10k-labels-idx1-ubyte.gz')print(train_data.shape)# (60000, 784) ## 60k 28x28 handwritten digitsprint(test_data.shape)# (10000, 784) ## 10k 2bx28 handwritten digits
可视化数据集
每个数据点存储为784维向量。为了可视化一个数据点,需要将其重塑为一个28像素×28像素的图像。如下代码展示了如何显示测试数据集中的手写数字:
## Define a function that displays a digit given its vector representationdef show_digit(x, label):pylab.axis('off')pylab.imshow(x.reshape((28,28)), cmap=pylab.cm.gray)pylab.title('Label ' + str(label))pylab.figure(figsize=(10,10))for i in range(25):pylab.subplot(5, 5, i+1)show_digit(test_data[i,], test_labels[i])pylab.tight_layout()pylab.show()
图14所示的是来自测试数据集的前25个手写数字及其真相 (true)标签。在训练数据集上训练的KNN分类器对这个未知的测试数据集的标签进行预测,并将预测的标签与真相标签进行比较,以评价分类器的准确性。

图14 测试数据集的前25个手写数字及其真相标签
通过训练KNN、高斯贝叶斯和SVM模型对MNIST数据集分类
用scikit-learn库函数实现以下分类器:K最近邻分类算法、高斯贝叶斯分类器(生成模型)、支持向量机分类器。
从K最近邻分类器开始介绍。
1.K最近邻分类器
本节将构建一个分类器,该分类器用于接收手写数字的图像,并使用一种称为最近邻分类器的特别简单的策略输出标签(0~9)。预测看不见的测试数字图像的方法是非常简单的。首先,只需要从训练数据集中找到离测试图像最近的k个实例;其次,只需要简单地使用多数投票来计算测试图像的标签,也就是说,来自k个最近的训练数据点的大部分数据点的标签将被分配给测试图像(任意断开连接)。
(1)欧氏距离平方。欲计算数据集中的最近邻,必须计算数据点之间的距离。自然距离函数是欧氏距离,对于两个向量x, y∈Rd,其欧氏距离定义为:

通常省略平方根,只计算欧氏距离的平方。对于最近邻计算,这两个是等价的:对于3个向量x, y, z∈Rd,当且仅当||x−y||2≤||x−z||2时,才有||x−y||≤||x−z||成立。因此,现在只需要计算欧氏距离的平方。
(2)计算最近邻。k最近邻的一个简单实现就是扫描每个测试图像的每个训练图像。以这种方式实施的最近邻分类需要遍历训练集才能对单个点进行分类。如果在Rd中有N个训练点,时间花费将为O (Nd),这是非常缓慢的。幸运的是,如果愿意花一些时间对训练集进行预处理,就有更快的方法来执行最近邻查找。scikit-learn库有两个有用的最近邻数据结构的快速实现:球树和k-d树。如下代码展示了如何在训练时创建一个球树数据结构,然后在测试1−NN(k=1)时将其用于快速最近邻计算:
import timefrom sklearn.neighbors import BallTree## Build nearest neighbor structure on training datat_before = time.time()ball_tree = BallTree(train_data)t_after = time.time()## Compute training timet_training = t_after - t_beforeprint("Time to build data structure (seconds): ", t_training)## Get nearest neighbor predictions on testing datat_before = time.time()test_neighbors = np.squeeze(ball_tree.query(test_data, k=1,return_distance=False))test_predictions = train_labels[test_neighbors]t_after = time.time()## Compute testing timet_testing = t_after - t_beforeprint("Time to classify test set (seconds): ", t_testing)# Time to build data structure (seconds): 20.65474772453308# Time to classify test set (seconds): 532.3929145336151
(3)评估分类器的性能。接下来将评估分类器在测试数据集上的性能。如下代码展示了如何实现这一点:
# evaluate the classifiert_accuracy = sum(test_predictions == test_labels) / float(len(test_labels))t_accuracy# 0.96909999999999996import pandas as pdimport seaborn as snfrom sklearn import metricscm = metrics.confusion_matrix(test_labels,test_predictions)df_cm = pd.DataFrame(cm, range(10), range(10))sn.set(font_scale=1.2)#for label sizesn.heatmap(df_cm, annot=True,annot_kws={"size": 16}, fmt="g")
运行上述代码,输出混淆矩阵,如图15所示。可以看到,虽然训练数据集的整体准确率达到96.9%,但仍存在一些错误分类的测试图像。

图15 混淆矩阵
图16中,当1-NN预测标签和,True标签均为0时,预测成功;当1-NN预测标签为2,True标签为3时,预测失败。

图16 预测数字成功与失败的情形
其中预测数字成功和失败情形的代码留给读者作为练习。
2.贝叶斯分类器(高斯生成模型)
正如我们在上一小节所看到的,1-NN分类器对手写数字MNIST数据集的测试错误率为3.09%。现在,我们将构建一个高斯生成模型,使其几乎可以达到同样的效果,但明显更快、更紧凑。同样,必须像上次一样首先加载MNIST训练数据集和测试数据集,然后将高斯生成模型拟合到训练数据集中。
(1)训练生成模型——计算高斯参数的最大似然估计。下面定义了一个函数fit_generative_model(),它接收一个训练集(x数据和y标签)作为输入,并将高斯生成模型与之匹配。对于每个标签j = 0,1,…,9,返回以下几种生成模型的参数。
πj:标签的频率(即优先的);
μj:784维平均向量;
∑j:784×784协方差矩阵。这意味着π是10×1、μ是10×784、∑是10×784×784的矩阵。最大似然估计(Maximum Likelihood Estimates,MLE)为经验估计,如图17所示。

图17 最大似然估计
经验协方差很可能是奇异的(或接近奇异),这意味着不能用它们来计算,因此对这些矩阵进行正则化是很重要的。这样做的标准方法是加上c*I,其中c是一个常数,I是784维单位矩阵(换言之,先计算经验协方差,然后将它们的对角元素增加某个常数c)。
对于任何c > 0,无论c多么小,这样修改可以确保产生非奇异的协方差矩阵。现在c成为一个(正则化)参数,通过适当地设置它,可以提高模型的性能。为此,应该选择一个好的c值。然而至关重要的是需要单独使用训练集来完成,通过将部分训练集作为验证集,或者使用某种交叉验证。这将作为练习留给读者完成。特别地,display_char()函数将用于可视化前3位数字的高斯均值,如下面的代码所示:
def display_char(image):plt.imshow(np.reshape(image, (28,28)), cmap=plt.cm.gray)plt.axis('off'),plt.show()def fit_generative_model(x,y):k = 10 # labels 0,1,...,k-1d = (x.shape)[1] # number of featuresmu = np.zeros((k,d))sigma = np.zeros((k,d,d))pi = np.zeros(k)c = 3500 #10000 #1000 #100 #10 #0.1 #1e9for label in range(k):indices = (y == label)pi[label] = sum(indices) / float(len(y))mu[label] = np.mean(x[indices,:], axis=0)sigma[label] = np.cov(x[indices,:], rowvar=0, bias=1) + c*np.eye(d)return mu, sigma, pimu, sigma, pi = fit_generative_model(train_data, train_labels)display_char(mu[0])display_char(mu[1])display_char(mu[2])
运行上述代码,输出前3位数字的平均值的最大似然估计,如图18所示。

图18 前3位数字的平均值的最大似然估计
(2)计算后验概率,以对试验数据进行预测和模型评价。为了预测新图像的标签x,需要找到标签j,其后验概率Pr(y = j|x)最大。可以用贝叶斯规则计算,如图19所示。
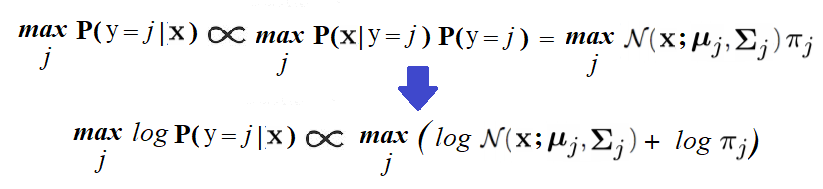
图19 贝叶斯计算规则
如下代码展示了如何使用生成模型预测测试数据集的标签,以及如何计算模型在测试数据集上产生错误的数量。可以看出,测试数据集的准确率为95.6%,略低于1-NN分类器。
# Compute log Pr(label|image) for each [test image,label] pair.k = 10score = np.zeros((len(test_labels),k))for label in range(0,k):rv = multivariate_normal(mean=mu[label], cov=sigma[label])for i in range(0,len(test_labels)):score[i,label] = np.log(pi[label]) + rv.logpdf(test_data[i,:])test_predictions = np.argmax(score, axis=1)# Finally, tally up scoreerrors = np.sum(test_predictions != test_labels)print("The generative model makes " + str(errors) + " errors out of 10000")# The generative model makes 438 errors out of 10000t_accuracy = sum(test_predictions == test_labels) / float(len(test_labels)t_accuracy# 0.95620000000000005
3.SVM分类器
本节将使用MNIST训练数据集训练(多类)支持向量机(SVM)分类器,然后用它预测来自MNIST测试数据集的图像的标签。
支持向量机是一种非常复杂的二值分类器,它使用二次规划来最大化分离超平面之间的边界。利用1︰全部或1︰1技术,将二值SVM分类器扩展到处理多类分类问题。使用scikit-learn的实现SVC(),它具有多项式核(二次),利用训练数据集来拟合(训练)软边缘(核化)SVM分类器,然后用score()函数预测测试图像的标签。
如下代码展示了如何使用MNIST数据集训练、预测和评估SVM分类器。可以看到,使用该分类器在测试数据集上所得到的准确率提高到了98%。
from sklearn.svm import SVCclf = SVC(C=1, kernel='poly', degree=2)clf.fit(train_data,train_labels)print(clf.score(test_data,test_labels))# 0.9806test_predictions = clf.predict(test_data)cm = metrics.confusion_matrix(test_labels,test_predictions)df_cm = pd.DataFrame(cm, range(10), range(10))sn.set(font_scale=1.2)sn.heatmap(df_cm, annot=True,annot_kws={"size": 16}, fmt="g")
运行上述代码,输出混淆矩阵,如图20所示。

图20 混淆矩阵
接下来,找到SVM分类器预测错误标签的测试图像(与真实标签不同)。
如下代码展示了如何找到这样一幅图像,并将其与预测的和真实的标签一起显示:
wrong_indices = test_predictions != test_labelswrong_digits, wrong_preds, correct_labs = test_data[wrong_indices],test_predictions[wrong_indices], test_labels[wrong_indices]print(len(wrong_pred))# 194pylab.title('predicted: ' + str(wrong_preds[1]) +', actual: ' +str(correct_labs[1]))display_char(wrong_digits[1])
运行上述代码,输出结果如图21所示。可以看到,测试图像具有真实的标签2,但图像看起来却更像7,因此SVM预测为7。

图21 预测为7而实际为2的情形
本文摘自《Python图像处理实战》
转自程序员荐书
本文仅做学术分享,如有侵权,请联系删文。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~