
vue3源码解析--数据监听篇
一. 内容简介
vue3自从2020.9.18正式发布以来,受到了前端业界的广泛关注,其中一个重大更新点便是vue3全新的数据监听模式。
本着严谨探究、求根问底的前置思维,以vue3实现数据监听的逻辑链路为导向,逐层破解vue3数据监听的实现原理,为大家揭开vue3源码的神秘面纱
通过本文你可以学习到
vue3通过proxy实现数据监听原理
reative及相关api实现原理
ref及相关api实现原理
computed及相关api实现原理
vue3通过何种方式优化数据性能,对日常开发有何启发
二. 背景介绍
众所周知,vue2采用的是Object.defineProperty()语法来完成针对对象元素的观察监听
而vue3则采用了别具一格的Proxy代理模式来完成对任何复杂数据类型的代理监听
通过对vue两个版本实现数据监听的api特性进行对比,我们可以发现:
Object.defineProperty由于每次只能监听对象一个键的get、set,导致需要循环监听,浪费性能,而vue3的Proxy可以一次性监听到所有属性
Object.defineProperty无法监听数组,必须通过增强并替换原型链方法的方式处理数组监听,而Proxy则可以直接监听数组变化
由于Object.defineProperty只能监听对象,导致vue2的data属性必须通过一个返回对象的函数方式初始化,而vue3则更加多元化,可以监听任意数据
了解完基本原理,接下来我们就开始展开对vue3数据监听实现原理的学习吧~
三. vue3数据监听实现原理
在日常开发中,vue3提供的响应式api,最常用的便是reactive、ref、computed三种
为了配合这三大核心api,vue3又为框架补充了一批辅助性api。
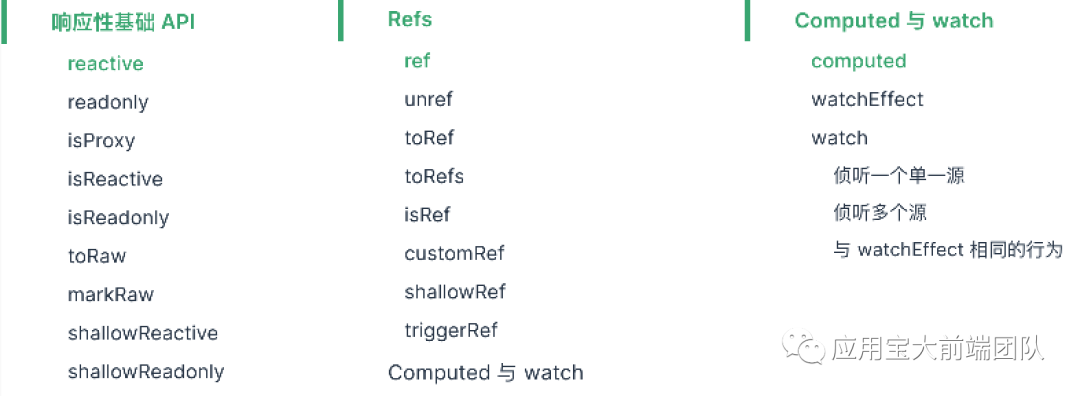
本文也将会以金字塔结构,依托三大核心api的实现
逐层拓展到各个辅助性api的具体实现原理上 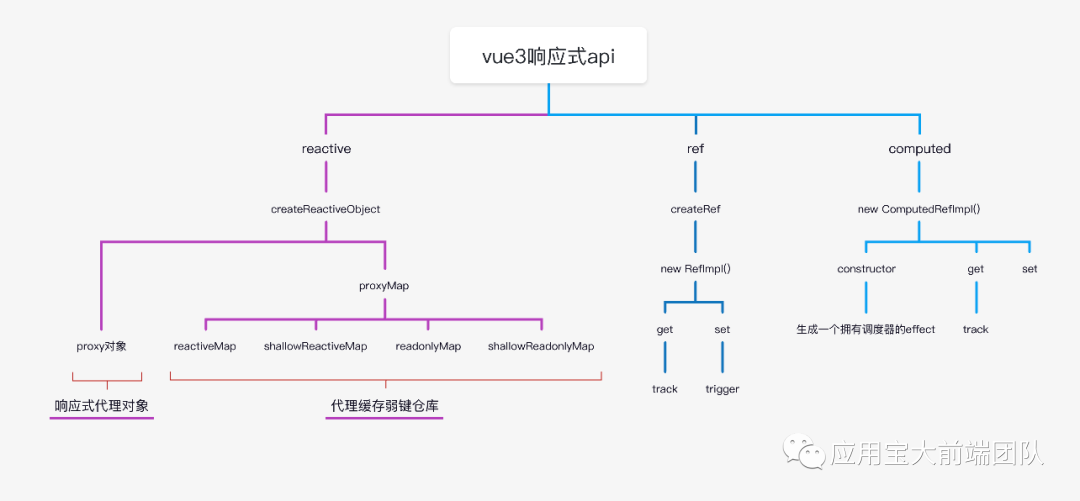
从上图中我们可以了解到
reactive依托于Proxy语法,分别在访问器特性中的get中触发track,set中触发trigger实现数据获取时的依赖收集和数据变化时的触发更新
ref则依托于RefImpl实现类中维护value属性的getter和setter,使实例在使用value属性时分别触发track和trigger方法,实现依赖收集和触发更新
computed方法依托于ComputedImpl实现类,完成对getter函数中的数据进行依赖收集,最后通过构造器中effect属性,构建一个包含调度器的副作用函数来实现数据更新
reactive功能实现
reative的源码位于VUE-NEXT/packages/reactivity/src/reactive.ts中 
reactive.ts为我们提供了reactive、shallowReactive、readonly、shallowReadOnly、isProxy、toRaw、markRaw等vue3框架导出api
同时维护了诸如 SKIP、IS_REACTIVE、IS_READONLY、RAW这些用于标识的私有属性
export interface Target {[ReactiveFlags.SKIP]?: boolean // 是否无效标识,用于跳过监听[ReactiveFlags.IS_REACTIVE]?: boolean // 是否已被reactive相关api处理过[ReactiveFlags.IS_READONLY]?: boolean // 是否被readonly相关api处理过[ReactiveFlags.RAW]?: any // 当前代理对象的源对象,即target}
以及四个基于WeakMap数据类型的代理缓存弱键仓库,用于提升代码运行时的内存性能
export const reactiveMap = new WeakMap<Target, any>()export const shallowReactiveMap = new WeakMap<Target, any>()export const readonlyMap = new WeakMap<Target, any>()export const shallowReadonlyMap = new WeakMap<Target, any>()
reactive.js整体架构图如下图所示
从上图我们可以得知
reactive核心内容reactive、shallowReactive、readonly、shallowReadOnly四个api均与createReactiveObject有着密切联系,只不过传入参数有所不同,为了简单起见,我们就率先基于reactive进行学习
首先reative是作为独立的函数导出自vue,reative需要传入一个对象,并将返回一个经过vue3处理过的代理对象。
源码角度上,我们讲传入的对象称之为 raw object 或者 target,而返回的对象我们则称之为代理对象。
进入项目目录后,我们直接找到了reactive函数本身
export function reactive(target: object) {if (target && (target as Target)[ReactiveFlags.IS_READONLY]) { // 如果监听目标仅可读return target // 那么直接返回目标本身}...}
我们可以看到reactive函数承接一个target对象作为参数,进入函数后,首先判断target是否是仅可读的对象,如果是则直接返回target本身。
这样做的原因在于如果target是一个仅可读的对象,意味着无法对其元素进行修改
无法修改代表其无需进行代理监听,所以直接返回即可
export function reactive(target: object) {if (target && (target as Target)[ReactiveFlags.IS_READONLY]) { // 如果监听目标仅可读return target // 那么直接返回目标本身}return createReactiveObject(target, // 监听目标false, // 不是只读mutableHandlers, // 可变数据的常规处理方案mutableCollectionHandlers, // 可变集合相关数据的特殊处理方案reactiveMap // 一个WeakMap仓库,用于存取,键为监听目标,值为目标的代理对象的映射关系// (由于WeakMap是弱引用,键被销毁则值同步被销毁,一般用以节约内存空间,优化性能))}
随后我们看到,如果target不是仅可读对象,则返回createReactiveObject函数函数的执行结果
createReactiveObject共承接五个参数,分别是:
target(监听目标)
是否只读
常规复杂类型对应的handlers(Object、Array)
非常规复杂类型对应的handler(Set、Map、WeakSet、WeakMap)
缓存弱键仓库,用于提高内存性能
function createReactiveObject(target: Target,isReadonly: boolean,baseHandlers: ProxyHandler<any>,collectionHandlers: ProxyHandler<any>,proxyMap: WeakMap<Target, any>) {if (!isObject(target)) { // 如果监听目标并不是一个Object类型(Object,Array,Set,Map,WeakSet,WeakMap)的数据类型,例如简单数据类型if (__DEV__) { // 开发环境下报一个warning提示用户console.warn(`value cannot be made reactive: ${String(target)}`)}return target // 直接返回目标本身}if (target[ReactiveFlags.RAW] && // 如果监听目标已经是一个proxy对象!(isReadonly && target[ReactiveFlags.IS_REACTIVE]) // 并且不只读,也不是vue为其添加的响应式) { // 这意味着如果使用readonly处理一个已经经过reactive包装过的代理对象时,将会直接返回return target} ...}
首先我们看到createReactiveObject,会对传入的target进行类型判断
如果target即监听目标并不是一个在Object类型(Object,Array,Set,Map,WeakSet,WeakMap)的数据类型,例如简单数据类型,则直接返回target本身,拒不处理的同时报一个warning
随后createReactiveObject会判断target是否携带__v_raw私有属性,如果有,即代表着当前target已经经过了响应式对象api的处理(类似vue的__ob__私有属性)
这意味着如果使用readonly处理一个已经经过reactive包装过的代理对象时,将会直接返回
function createReactiveObject(target: Target,isReadonly: boolean,baseHandlers: ProxyHandler<any>,collectionHandlers: ProxyHandler<any>,proxyMap: WeakMap<Target, any>) {...// 如果目标已经是一个proxyconst existingProxy = proxyMap.get(target) // 先去weakmap里面找一找当前的targetif (existingProxy) { // 如果target已经被监听且推入weakmap仓库中return existingProxy // 则处于节约性能的考虑,直接返回已经被监听过的proxy对象(所以你不必担心自己重新reactive一个目标,因为vue3会为你处理好他,并不会报错)}...}
随后我们会从proxyMap中尝试取到以target作为键的元素
如果取到意味着当前target已经是一个"被代理过的"已存在代理对象
则无需后续的处理,直接返回即可
上文中我们提到,proxyMap本质上是一个WeakMap
export const reactiveMap = new WeakMap<Target, any>()WeakMap数据类型有三个特点:
必须以对象作为键
键为弱键,即作为键的对象被删除或者被重新赋值则键值对会同时消失
由于键是弱键,导致无法判断此时此刻,彼时彼刻任一键值对是否存在,导致没有迭代器
WeakMap这样的特性意味着当某个target消失或者重新赋值后
代理对象所在的键值对在内存中也被自动清除了
极大的提高了内存空间的使用效率
数据量积累到一定程度后,会对性能也有极大优化
function createReactiveObject(target: Target,isReadonly: boolean,baseHandlers: ProxyHandler<any>,collectionHandlers: ProxyHandler<any>,proxyMap: WeakMap<Target, any>)...const targetType = getTargetType(target)if (targetType === TargetType.INVALID) { // 如果目标不可拓展(即configerable 为 false),就直接返回return target // 原因是proxy无法成功代理configerable为false的目标,导致代理失效,所以还不如直接返回目标算了}...}
当然,如果当前target的访问器特性中的configerable为false
Proxy就无法对其进行代理了,直接返回target即可
此处和vue2defineReactive函数中使用Object.getOwnPropertyDescriptor有异曲同工之妙
这里也贴一下vue2同样逻辑的代码供大家参考
export function defineReactive (obj: Object,key: string,val: any,customSetter?: ?Function,shallow?: boolean) {const dep = new Dep()const property = Object.getOwnPropertyDescriptor(obj, key)if (property && property.configurable === false) {return}...使用Object.defineProperty进行数据监听}
随后,也就到了createReativeObject的重头戏了,也就是数据代理
function createReactiveObject(target: Target,isReadonly: boolean,baseHandlers: ProxyHandler<any>,collectionHandlers: ProxyHandler<any>,proxyMap: WeakMap<Target, any>) {...前置判断逻辑const proxy = new Proxy( // 如果上述条件都不符合,则生成一个proxy(当然这也是最常规最常用的逻辑)target,targetType === TargetType.COLLECTION ? collectionHandlers : baseHandlers // 如果监听目标是map,set, wset,wmap之流,就单起一个handler,如果是常规数据就用常规handler)proxyMap.set(target, proxy) // 将目标与目标生成的proxy,作为键值对放入weakmap中,一方面可以自动进行去重,另一方面当监听目标被销毁,proxy也会立即销毁,节约性能return proxy // 返回依托监听目标而生成的proxy对象(不可结构赋值,解构赋值会使代理失效而变成普通属性)}
众所周知,我们在学习Proxy的时候了解到,Proxy实例化的时候需要两个参数,分别是:被代理目标,如对象、数组、构造函数、类、函数、集合、映射等等
处理器,例如常见的访问器属性get set value 等等
1.1、总结
reacitve完成的功能主要是使用new Proxy()对target进行处理
处理器根据target的数据类型,选用collectionHandler或者baseHandler
维护了四个数据类型为WeakMap的缓存仓库
定义了四个vue3私有属性,用于标识代理对象
此时我们也有了一个疑问
上述代码中作为处理器的collectionHandlers以及baseHandlers实现了什么样的功能呢?
带着这样的疑问,我们后续会展开对baseHandlers的学习
2、baseHandler功能实现
我们先来看一下baseHandler.ts的整体架构图 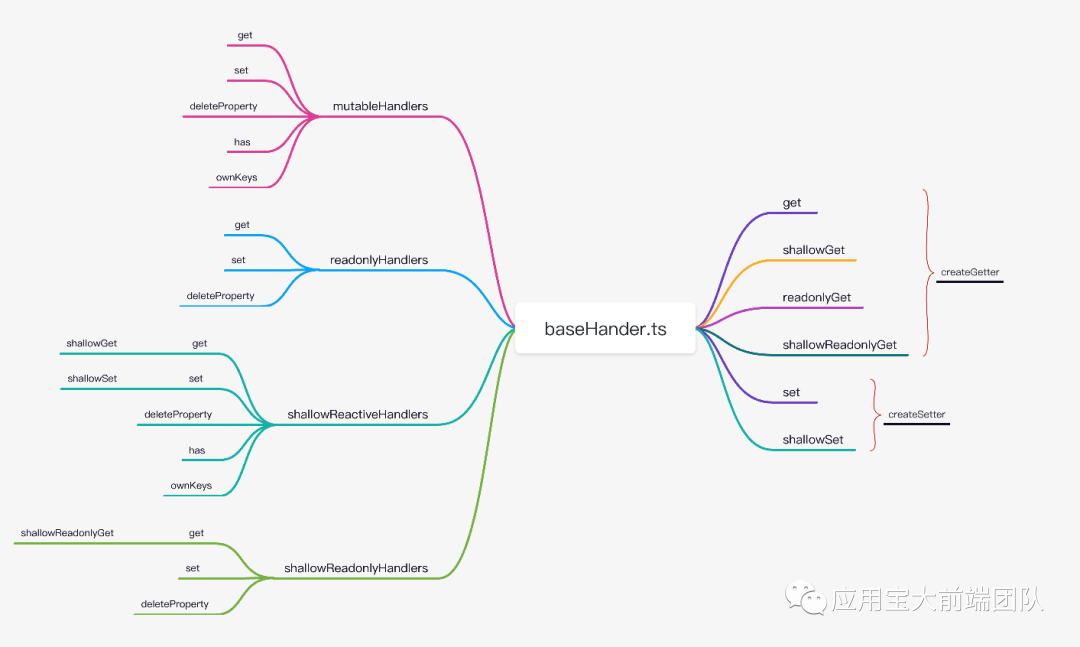
首先,我们需要确定一个概念,所谓proxy的handler其实是一个对象,而在vue3中最核心的对象特性便是get和set
const get = /*#__PURE__*/ createGetter()const shallowGet = /*#__PURE__*/ createGetter(false, true)const readonlyGet = /*#__PURE__*/ createGetter(true)const shallowReadonlyGet = /*#__PURE__*/ createGetter(true, true)
从上述代码中,我们发现:
get特性均为createGetter返回,只不过参数有所不同
set特性均为createSetter返回, 只不过参数有所不同
既然是这样,我们就可以直接把视角定位到createGetter和createSetter中
2.1、createGetter方法
function createGetter(isReadonly = false, shallow = false) {return function get(target: Target, key: string | symbol, receiver: object) {...}
我们可以看到createGetter承接两个参数,分别是
是否只读
是否是浅监听
同时,返回一个getter函数,函数承接三个参数,分别是:
target即监听目标
键:可以是string,也可以是Symbol数据类型
receiver是一个对象
而getter函数具体做了哪些事情呢?
function createGetter(isReadonly = false, shallow = false) {return function get(target: Target, key: string | symbol, receiver: object) {// 这部分判断只要是用来处理reactive中的ReactiveFlags的私有属性的getif (key === ReactiveFlags.IS_REACTIVE) { // 如果取到__v_isReactive私有属性// 这里有两层意思,一来如果数据源不为readonly,则取__v_isReactive直接返回true// 二来如果数据源是readonly的,无法set自然无需触发trigger,即不是响应式的return !isReadonly // 则返回isReadonly的反值} else if (key === ReactiveFlags.IS_READONLY) { // 如果取的是__v_isReadonlyreturn isReadonly // 直接返回传入的isReadonly} else if ( // 如果取的是__v_raw,则直接从监听仓库中取到对应receiver的键(receiver既是new Proxy的返回值),这个键就是代理的原始值key === ReactiveFlags.RAW &&receiver ===(isReadonly? shallow? shallowReadonlyMap: readonlyMap: shallow? shallowReactiveMap: reactiveMap).get(target)) {return target}...}}
我们可以观察到
首先getter会对键进行一系列vue3为其添加的私有属性的判断,意在vue3框架代码可以正常取用到vue3独有的私有属性用于逻辑判断。例如上述代码中提到的IS_REACTIVE、IS_READONLY、RAW
这些私有属性的取用肯定是不需要触发依赖收集的,这对于节约性能有着重要作用
function createGetter(isReadonly = false, shallow = false) {return function get(target: Target, key: string | symbol, receiver: object) {...const targetIsArray = isArray(target) // isArray就是Array.isArray,干净又卫生// 取诸如 push pop shift unshift splice (会更改lenggh) 和 indexOf lastIndexOf includes(获取元素位置)的原型方法// 由于proxy对象的对于get set的代理,所以需要做一些特殊处理if (!isReadonly && targetIsArray && hasOwn(arrayInstrumentations, key)) {return Reflect.get(arrayInstrumentations, key, receiver)}...}}
对于私有属性处理完以后,getter会对target是否为数组进行判断,如果target是一个数组则需要对一些原型方法的get情况做特殊处理
我们在学习vue2源码的时候了解到
由于vue2使用Object.defineProperty,无法对数组生效
所以不得已而通过增强Array原型链方法的方式对数组进行依赖收集和触发更新
而vue3使用的Proxy代理方式,按照道理来说是完全可以代理数组的,那为什么我们还需要对数组原型链上的一些方法进行特殊处理呢?
我们直接看一下vue3对于这块逻辑的代码
const arrayInstrumentations: Record<string, Function> = {};(['includes', 'indexOf', 'lastIndexOf'] as const).forEach(key => {const method = Array.prototype[key] as anyarrayInstrumentations[key] = function(this: unknown[], ...args: unknown[]) {// 由于上面的三种方法,会多对方法本身和length分别进行一个get// 出于节约性能考虑,我们直接取出原始值,然后遍历进行track get// 然后再执行原始方法const arr = toRaw(this)for (let i = 0, l = this.length; i < l; i++) {track(arr, TrackOpTypes.GET, i + '')}// we run the method using the original args first (which may be reactive)const res = method.apply(arr, args)// 如果目标数组所包含的元素中含有已经被代理过的元素// 而此时用户肯定会直接arrTarget.includes(item)// 而不是arrTarget.includes(proxyItem)// 故而我们需要将其原始值取出来,然后再执行一次includes才能获得正确的结果if (res === -1 || res === false) {// if that didn't work, run it again using raw values.return method.apply(arr, args.map(toRaw))} else {return res}}})
首先我们从上述代码,可以了解到对于include、indexOf、lastIndexOf这三种数组原型链方法
会对数组本身元素和length分别做多次get,且这三种方法都需要触发依赖收集,也就是track
出于节约性能考虑,我们直接取出原始值,然后遍历进行track get,然后再执行原始方法
const arr = toRaw(this)for (let i = 0, l = this.length; i < l; i++) {track(arr, TrackOpTypes.GET, i + '')}// we run the method using the original args first (which may be reactive)const res = method.apply(arr, args)
如果目标数组所包含的元素中含有已经被代理过的元素,而此时用户肯定会直接arrTarget.includes(item)
而不是arrTarget.includes(proxyItem)
故而我们需要将其原始值取出来,然后再执行一次includes才能获得正确的结果
if (res === -1 || res === false) {// if that didn't work, run it again using raw values.return method.apply(arr, args.map(toRaw))} else {return res}
除了这三种数组原型方法
还有push、 pop、 shift、 unshift、splice五种方法
也由于proxy的getter取用这几种方法
需要频繁对数组的length进行get set
;(['push', 'pop', 'shift', 'unshift', 'splice'] as const).forEach(key => {const method = Array.prototype[key] as anyarrayInstrumentations[key] = function(this: unknown[], ...args: unknown[]) {pauseTracking()const res = method.apply(this, args)resetTracking()return res}})
会造成track和trigger的无限循环
故而需要在调用前暂停track,调用后重启track
处理完数组的原型方法
我们就可以关注于正常元素的取用getter逻辑的实现了
也是我们学习中最重要的部分
function createGetter(isReadonly = false, shallow = false) {return function get(target: Target, key: string | symbol, receiver: object) {...const res = Reflect.get(target, key, receiver) // 使用原生Reflect进行get取值if ( // 取symbol或者私有属性或者原型对象则直接返回,无需触发trackisSymbol(key)? builtInSymbols.has(key as symbol): isNonTrackableKeys(key)) {return res}...}}
我们可以看到
首先getter使用反射Reflect.get方法从target中取出键为key的元素的值
随后判断取用的属性是否为圆形脸上Symbol相关的属性
例如迭代器Symbol(Symbol.iterator)
这些原型属性无需触发track(也就是依赖收集),故而直接返回值即可
这里也贴上常见的Symbol方法:
Symbol(Symbol.asyncIterator)
Symbol(Symbol.hasInstance)
Symbol(Symbol.isConcatSpreadable)
Symbol(Symbol.iterator)
Symbol(Symbol.match)
Symbol(Symbol.matchAll)
Symbol(Symbol.replace)
Symbol(Symbol.search)
Symbol(Symbol.species)
Symbol(Symbol.split)
Symbol(Symbol.toPrimitive)
Symbol(Symbol.toStringTag)
Symbol(Symbol.unscopables)
function createGetter(isReadonly = false, shallow = false) {return function get(target: Target, key: string | symbol, receiver: object) {...if (!isReadonly) { // 因为readonly只能get不能set,不能set就不需要trigger,不需要trigger就不需要tracktrack(target, TrackOpTypes.GET, key) // 除了上述的部分原型链方法和自由属性等,就需要要触发track}...}}
再往后走,就是我们getter核心逻辑,也就是触发track
首先,先判断是否不为仅可读
这样判断的原因在于
readonly只能get不能set,不能set就不需要trigger,不需要trigger就不需要track
如果该key不为仅可读,且取用到属性不为上文提到的几种原型方法
意味着必须进行数据追踪,也就是track
数据最终完毕后,我们还需要进入一小段逻辑
由于vue提供的reactive或者ref等api为深层次监听
而shallowRef、shallowReavtive等为浅层次监听
所以有以下的逻辑
function createGetter(isReadonly = false, shallow = false) {return function get(target: Target, key: string | symbol, receiver: object) {...if (shallow) { // 如果是浅响应,就不需要走下面的逻辑了,因为不需要深层监听return res // 直接监听完返回就好了}if (isRef(res)) { // 通过__v_isRef判断是否为ref包装的数据// ref unwrapping - does not apply for Array + integer key.const shouldUnwrap = !targetIsArray || !isIntegerKey(key)return shouldUnwrap ? res.value : res}// 如果是对象 数组 集合 映射 (因为这里用的是typeof) 的话,由于proxy只能监听一层数据// 所以需要返回一个深层响应的代理数据(保证底层级数据的get能够触发track,set能触发trigger)if (isObject(res)) {return isReadonly ? readonly(res) : reactive(res)}return res}}
由于Proxy和Object.defineProperty一样
每次监听均只能监听一层
所以如果想要完成深度监听的效果
必须对基于key取到的值进行是否为对象的判断
如果是,还需要进行一次reactive或者readonly的递归监听
直到将所有层级的属性均做一次代理为止
最后的最后,返回通过Reflect.get取到的res
完成getter函数的全部逻辑
2.2、createSetter方法
function createSetter(shallow = false) {return function set(target: object,key: string | symbol,value: unknown,receiver: object): boolean {let oldValue = (target as any)[key] // 首先把老值取出来,没有则undefinedif (!shallow) { // 如果不是浅监听value = toRaw(value)oldValue = toRaw(oldValue)if (!isArray(target) && isRef(oldValue) && !isRef(value)) {// 如果target不是数组且老值是ref数据,新值不是ref数据(常规数据类型)oldValue.value = value // 则用赋值ref的方法,取出value并用新值赋值return true // 直接return}}...}}
同样的,我们观察到createSetter返回了一个setter函数
函数最开始先取出老值,待用
随后判断是否为深监听
如果是深层次监听,就通过上文提到的toRaw将源数据取出
此时的源数据并不是代理数据,而是未经任何处理的原始数据
此时如果判断出老值是ref,则新值的赋值需要赋在老值的value属性上
相信这块对于已经熟练使用ref的同学来说,非常容易理解
既然已经重新赋值,且ref数据会单独走一套trigger逻辑
就无须再触发一次trgger,直接return true即可
function createSetter(shallow = false) {return function set(target: object,key: string | symbol,value: unknown,receiver: object): boolean {...const hadKey =isArray(target) && isIntegerKey(key)? Number(key) < target.length: hasOwn(target, key)const result = Reflect.set(target, key, value, receiver) // 走常规set逻辑// don't trigger if target is something up in the prototype chain of originalif (target === toRaw(receiver)) {if (!hadKey) { // 是否更改的是已有的键trigger(target, TriggerOpTypes.ADD, key, value) // 如果没有则触发新增trigger} else if (hasChanged(value, oldValue)) {trigger(target, TriggerOpTypes.SET, key, value, oldValue) // 如果有则触发触发更改trigger}}return result}}
后续的逻辑就非常简单易懂了
逻辑走到这里,意味着此时的setter就是在set一个普通的未经处理过的数据
这意味着可以直接使用Reflect.set进行新值赋值给老值
并触发trigger,是track了相关数据的其他数据或者是template中的当前数据进行更新
最后返回一个result
这个result是Reflect.set的返回值,正常set成功一般为true
2.3、总结
baseHandler主要是提供了需要使用到的setter和getter
常规情况下setter会触发trigger,getter会触发track
对于数组以及Symbol需要对其原型链上的方法进行特殊处理
vue3使用Reflect进行get、set常规操作
3、effect功能实现
effect.ts的主要内容即是track和trigger
我们将分别对其进行针对性学习
3.1、track方法
我们可以看到
track首先对shouldTrack和activeEffect进行判断
如果是不需要track的数据,例如__v_skip,或者在首次渲染时
setup中并没有返回数据则直接return
随后track维护了一系列复杂的数据结构
用于保存数据追踪时使用的effect函数
为了方便大家理解
笔者准备了一个数据结构导图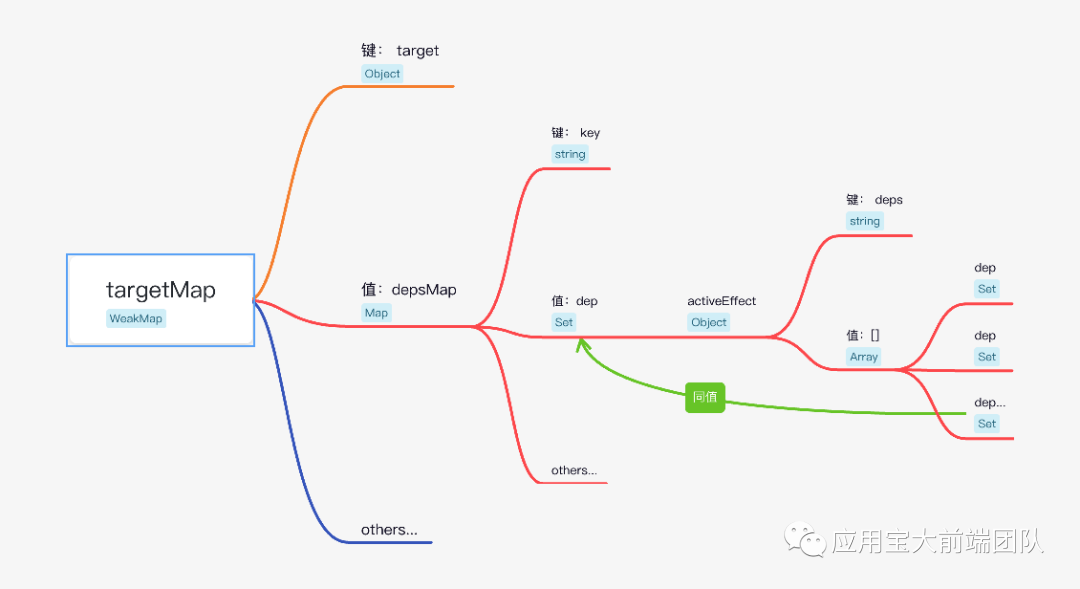
我们可以看到
基于targetMap的数据中,使用了大量的WeakMap进行性能优化
且使用了Set进行effect去重
这也是vue3将性能做到极致的理念的具体体现
虽然数据结构看似复杂
然而通过我们的理解
发现是最最重要的无非是depsMap中维护的数据类型为Set的dep集合
中保存的activeEffect是最值得我们关注的
而activeEffect是一个函数,且执行的结果为新值并触发调度器更新页面
我们来看一下effect函数的逻辑
3.2、effect副作用函数
我们可以观察到effect的逻辑非常简单
首先判断当前传入的fn是否已经是一个effect函数了
如果是则取出其原始函数
并执行createReavtiveEffect生成一个全新的effect函数
如果effect非惰性,则直接执行effect
最后返回effect函数本身
export function effect<T = any>(fn: () => T,options: ReactiveEffectOptions = EMPTY_OBJ // dev环境下empty_obj已被冻结): ReactiveEffect<T> {if (isEffect(fn)) { // 如果参数函数已经是个effectfn = fn.raw // 则取出原函数}const effect = createReactiveEffect(fn, options) // 执行createReactiveEffect生成effectif (!options.lazy) { // 如果此时的effect非惰性effect() // 则直接执行} return effect // 返回生成的effect}
此时看来看似云里雾里
无法窥视effect究竟完成了哪些逻辑
没关系,我们先带着疑问继续看下createReavtiveEffect
看下effect函数中究竟有何玄机
3.3、createReavtiveEffect函数
我们可以看到createReactiveEffect的逻辑主要分为两部分
一部分是生成一个reactiveEffect函数
另一部分则是为effect函数增加一系列属性
function createReactiveEffect<T = any>(fn: () => T,options: ReactiveEffectOptions): ReactiveEffect<T> {const effect = function reactiveEffect(): unknown {if (!effect.active) {return options.scheduler ? undefined : fn()}if (!effectStack.includes(effect)) {cleanup(effect)try {enableTracking()effectStack.push(effect)activeEffect = effectreturn fn()} finally {effectStack.pop()resetTracking()activeEffect = effectStack[effectStack.length - 1]}}} as ReactiveEffecteffect.id = uid++effect.allowRecurse = !!options.allowRecurse // 是否允许重复effect._isEffect = true // 标识是否被createReactiveEffect处理过effect.active = true // 被createReactiveEffect处理过,会被标识激活,active为trueeffect.raw = fn // 原函数会被挂载到raw属性上去,方便溯源effect.deps = [] // 依赖收集器effect.options = options // 将原options直接全量挂载在effect上return effect}
这里需要提一嘴
effect是一个函数,但是函数本质上也是一个对象
这意味着函数上除了函数体以外,还可以像对象一样挂载很多属性
首先我们看到createReactiveEffect函数率先创建了一个崭新的effect
effect函数内部判断当前effect是否处于激活状态
如果不为激活状态则判断是否携带调度器属性,如果不携带则直接执行函数本身
随后从副作用栈,也就是effectStack中搜寻当前effect
如果没有所寻到,意味着是一个未被处理过的effect
那么需要清除当前effect上挂载的所有dep
随后将其设置成激活状态下的effect
并返回effect的执行结果也就是最新的值
创建好一个崭新的effect副作用函数之后
会为当前effect添加一系列属性,并返回effect本身
此时的effect的函数,不光具有唯一的uid标识
还带有deps负责记录依赖
且已经出来active为true的激活状态
而effect的最终作用,以及这一系列的属性和函数体本身都是服务与trigger
也就是数据更新的功能
3.4、trigger方法
trigger的函数体非常长
但是逻辑却非常非常简单
export function trigger(target: object,type: TriggerOpTypes,key?: unknown,newValue?: unknown,oldValue?: unknown,oldTarget?: Map<unknown, unknown> | Set<unknown>) {const depsMap = targetMap.get(target) // 先从监听数据的仓库里把触发trigger的数据源对应的depsMap取出来if (!depsMap) { // 如果没有,说明该target中的属性并没有被track returnreturn}const effects = new Set<ReactiveEffect>()const add = (effectsToAdd: Set<ReactiveEffect> | undefined) => {if (effectsToAdd) {effectsToAdd.forEach(effect => {if (effect !== activeEffect || effect.allowRecurse) {effects.add(effect)}})}}...}
首先我们看到trigger会先尝试着从上文中提到的targetMap中取出依赖映射
依赖映射不存在,意味着此时的taget根本没有被track
那也就是无需执行数据更新
所以直接return即可
随后trigger维护了一个名为effects的集合
并且trigger定义了一个add函数用于将合规的effect函数添加进effects集合中去
export function trigger(target: object,type: TriggerOpTypes,key?: unknown,newValue?: unknown,oldValue?: unknown,oldTarget?: Map<unknown, unknown> | Set<unknown>) {...if (type === TriggerOpTypes.CLEAR) {// collection being cleared// trigger all effects for targetdepsMap.forEach(add)} else if (key === 'length' && isArray(target)) {depsMap.forEach((dep, key) => {if (key === 'length' || key >= (newValue as number)) {add(dep)}})} else {// schedule runs for SET | ADD | DELETEif (key !== void 0) {add(depsMap.get(key))}// also run for iteration key on ADD | DELETE | Map.SETswitch (type) {case TriggerOpTypes.ADD:if (!isArray(target)) {add(depsMap.get(ITERATE_KEY))if (isMap(target)) {add(depsMap.get(MAP_KEY_ITERATE_KEY))}} else if (isIntegerKey(key)) {// new index added to array -> length changesadd(depsMap.get('length'))}breakcase TriggerOpTypes.DELETE:if (!isArray(target)) {add(depsMap.get(ITERATE_KEY))if (isMap(target)) {add(depsMap.get(MAP_KEY_ITERATE_KEY))}}breakcase TriggerOpTypes.SET:if (isMap(target)) {add(depsMap.get(ITERATE_KEY))}break}}...}
在这之后,trigger判断了触发trigger的触发器类型
例如set、delete、add等等
判断后,针对不同情况分别执行add
将从depsMap中取到的各种effect函数分别添加到effect集合中去
而最后一步也就是trigger函数最最核心的逻辑
也就是触发更新
export function trigger(target: object,type: TriggerOpTypes,key?: unknown,newValue?: unknown,oldValue?: unknown,oldTarget?: Map<unknown, unknown> | Set<unknown>) {...const run = (effect: ReactiveEffect) => {if (__DEV__ && effect.options.onTrigger) {effect.options.onTrigger({effect,target,key,type,newValue,oldValue,oldTarget})}if (effect.options.scheduler) { // 如果在template中有使用的话,直接调用调度器,触发rerender更新template数据effect.options.scheduler(effect)} else {effect()}}effects.forEach(run)}
我们可以看到trigger首先定义了一个run函数用于触发更新
run函数的主要逻辑在于取出effect中的调度器
执行调度器即可触发template当前数据的更新或者依赖于当前数据的其他数据的更新
而要如何执行run函数呢?
这时就要用到上文中我们反复强调的effects集合
通过一个迭代器方法forEach传入run函数的方式
依次执行effects集合中的所有effect的函数中调度器
至此,vue3数据监听所有逻辑已经形成妥善逻辑闭环
3.5、总结
vue3通过track和trigger完成数据的依赖收集和触发更新
track通过构建以depsMap为核心的数据结构完成对effect的收集
trigger通过depsMap取出与当前触发trigger的数据相关的依赖
trigger通过依次按顺序执行effect中的调度器实现数据更新
4、ref功能实现
首先我们还是先来看一下ref.ts的架构图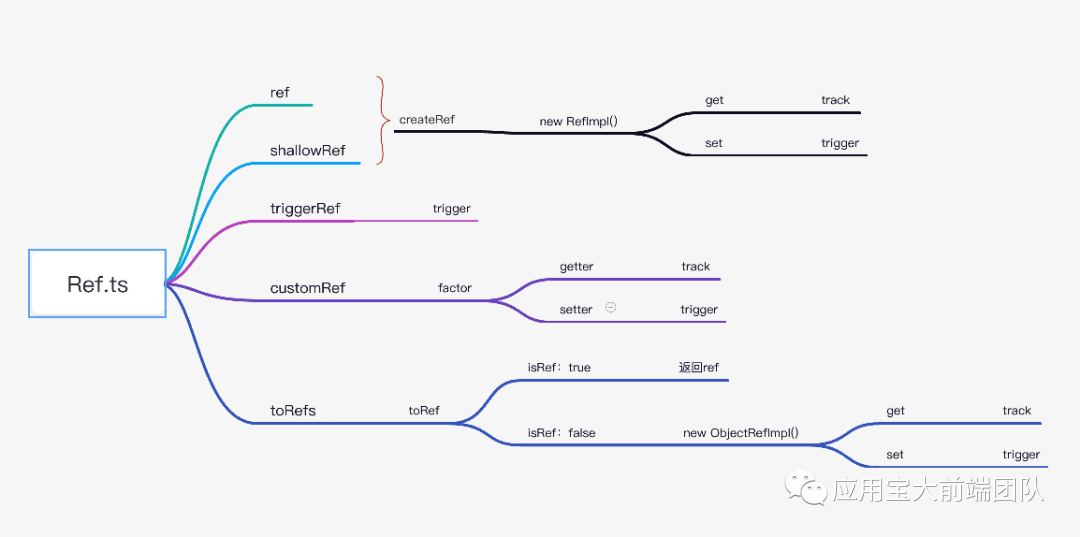
我们可以看到ref.ts总体上维护了ref、shallowRef、triggerRef、customRef、toRefs五个常用api
而ref和shallowRef又都是RefImpl实现类的实例
那么我们就分别对这几块的核心功能进行学习吧~
4.1、ref&shallowRef方法
export function ref(value?: unknown) { // 生成一个ref,上方是ts的重载return createRef(value) // 直接调用createRef}
export function shallowRef<T extends object>(value: T): T extends Ref ? T : Ref<T>export function shallowRef<T>(value: T): Ref<T>export function shallowRef<T = any>(): Ref<T | undefined>export function shallowRef(value?: unknown) { // 生成一个shallowRef,上方是ts的重载return createRef(value, true) // 直接调用createRef}
我们可以看到ref和shallowRef都返回了createRef的执行结果
function createRef(rawValue: unknown, shallow = false) {if (isRef(rawValue)) { // 如果rawValue已经是ref了return rawValue // 那么就直接返回rawValue}return new RefImpl(rawValue, shallow) // 反之则返回一个RefImpl实例}
而createRef则是返回了一个RefImpl实例
那么,我们直接看一下RefImpl实现类的实现吧~
class RefImpl<T> { // ref实现类(Implement)private _value: Tpublic readonly __v_isRef = true // 提一个问题:typescript的readonly和abstract类是如何实现的?constructor(private _rawValue: T, public readonly _shallow = false) { // 传入一个rawValue参数,以及一个用于甄别是否为shallow的参数,默认为deep监听模式this._value = _shallow ? _rawValue : convert(_rawValue) // 如果是浅监听则私有value直接为rawValue,如果是深监听且为对象则直接调用creative进行包装}get value() {// 取值的时候触发track,target为经过toRaw处理过的this(RefImpl的实例)// 至于为什么要使用toRaw处理this,主要是为了处理_rawValue为reactive的情况track(toRaw(this), TrackOpTypes.GET, 'value')return this._value}set value(newVal) {if (hasChanged(toRaw(newVal), this._rawValue)) { // 如果值有所变化且NaN赋值给NaN并不会触发此逻辑,其实用Object.is()会更好this._rawValue = newVal // 修改_rawValuethis._value = this._shallow ? newVal : convert(newVal) // 如果是深度监听需要重新建立reactivetrigger(toRaw(this), TriggerOpTypes.SET, 'value', newVal) // 赋值后触发trigger,同样使用toRaw生成target}}}
我们可以看到RefImpl的实现非常简单
首先在构造器中维护了一个_value的私有属性
随后我们可以看到关于value属性的getter和setter
其中getter核心逻辑就是触发数据追踪也就是track
而setter的核心逻辑则是触发数据更新也就是trigger
这也解释了为何我们在日常使用ref的过程中
传入任意数据,都会返回一个具有value为键,数据源为值的对象
值得注意的是,除了上述逻辑以外
RefImpl还为所有实例添加了一个__v_isRef_的标识
用于后续的性能优化
4.2、triggerRef方法
triggerRef的逻辑及其简单
就是直接触发trigger
换句话说,triggerRef提供了一个让vue3使用者手动触发当前数据的trigger
export function triggerRef(ref: Ref) {// 手动触发与当前ref绑定的副作用trigger(toRaw(ref), TriggerOpTypes.SET, 'value', __DEV__ ? ref.value : void 0)}
4.3、customRef方法
customRef的逻辑其实也非常简单,只不过略微有点嵌套而已
export function customRef<T>(factory: CustomRefFactory<T>): Ref<T> {return new CustomRefImpl(factory) as any // 传入一个工厂参数至用户自定义ref实现类中}
我们可以看到customRef返回了一个CustomRefImpl实现类的实例
class CustomRefImpl<T> {private readonly _get: ReturnType<CustomRefFactory<T>>['get']private readonly _set: ReturnType<CustomRefFactory<T>>['set']public readonly __v_isRef = true // 添加ref标识constructor(factory: CustomRefFactory<T>) {const { get, set } = factory( // 工厂参数是一个拥有track和trigger的函数,返回的是经过用户自定义逻辑的get和set() => track(this, TrackOpTypes.GET, 'value'), // 触发监听() => trigger(this, TriggerOpTypes.SET, 'value') // 触发响应)this._get = getthis._set = set}get value() {return this._get() // 触发get}set value(newVal) {this._set(newVal) // 触发set}}
而CustomRefImpl的实现也非常简单粗暴
就是直接取出来vue3使用者传入的可以提供开发者自定义的get、set的factory
然后为其添加到value属性的getter和setter中去
这也就是为vue3的使用者们提供了一个自定义get、set逻辑并增强逻辑的api
4.4、toRefs&toRef方法
toRefs和toRef都是我们日常开发中常用的api
我们有了解到proxy对象解构赋值后会丧失响应式
所以vue3为了使用方便
特意提供了这两个api方便我们在取值的同时保证响应式
export function toRefs<T extends object>(object: T): ToRefs<T> {if (__DEV__ && !isProxy(object)) { // 如果传入的object不是proxy处理过的响应式数据则直接报错console.warn(`toRefs() expects a reactive object but received a plain one.`)}const ret: any = isArray(object) ? new Array(object.length) : {} // 创建一个空值,等长数组或者一个空对象for (const key in object) {ret[key] = toRef(object, key) // 调用toRef依次取值赋值}return ret}
我们可以看到toRefs的实现是通过枚举传入的proxy对象并执行toRef来实现的
所以我们直接跳到toRef的源码即可
export function toRef<T extends object, K extends keyof T>(object: T,key: K): ToRef<T[K]> {return isRef(object[key]) // 值已经为ref了,必定内嵌响应式? object[key] // 则直接返回,兜底逻辑,实际开发无意义: (new ObjectRefImpl(object, key) as any) // 如果不是ref则返回ObjectImpl实例}
我们可以看到
toRef首先对其值进行判断
如果已经是ref就直接返回
而如果不是ref值,则返回一个ObjectRefImpl实现类的实例
class ObjectRefImpl<T extends object, K extends keyof T> {public readonly __v_isRef = true // 为其打上ref标记constructor(private readonly _object: T, private readonly _key: K) {}get value() { // 相较于上方的refimpl缺啥了track逻辑,这是为什么呢???return this._object[this._key] // 直接取值}set value(newVal) { // 相较于上方的refimpl缺啥了trigger逻辑,这是为什么呢???this._object[this._key] = newVal // 直接赋值}}
而ObjectRefImpl的实现也非常简单
首先也是维护了一个__v_isRef私有特性用于标识所有实例为ref数据类型
同时维护了value属性的get和set
这里笔者提出一个问题
为何而ObjectRefImpl相较于上文中提到的Refimpl缺少了track和trigger的逻辑呢?
其实这个问题回答起来也很简单:
由于ObjectRefImpl此时处理的数据已经是响应式的了
如果再写一次track和trigger逻辑会导致重复的追踪和触发
这里还是希望各位同学着重体会一下其中的逻辑
4.5、总结
ref本质上通过维护value属性的getter、setter时分别触发track和trigger来实现数据监听
ref数据类型维护一个私有属性来标识ref数据
5、computed功能实现
computed内容十分精简,无非是实现了一个ComputedRefImpl实现类
5.1、computed方法
export function computed<T>(getter: ComputedGetter<T>): ComputedRef<T>export function computed<T>(options: WritableComputedOptions<T>): WritableComputedRef<T>export function computed<T>(getterOrOptions: ComputedGetter<T> | WritableComputedOptions<T>) {let getter: ComputedGetter<T>let setter: ComputedSetter<T>if (isFunction(getterOrOptions)) { // 传入options是函数则默认为settergetter = getterOrOptionssetter = __DEV__? () => {console.warn('Write operation failed: computed value is readonly')}: NOOP} else { // 若是对象则拆解set,get分别赋值getter = getterOrOptions.getsetter = getterOrOptions.set}return new ComputedRefImpl( // 返回一个 ComputedRefImpl 实例,get会触发trackgetter,setter,isFunction(getterOrOptions) || !getterOrOptions.set) as any}
我们可以看到
日常开发中我们可能会为computed传入一个函数作为默认getter
或者传入一个包含了setter、getter的对象
而computed的核心逻辑也就是返回了一个ComputedRefImpl的实例
5.2、ComputedRefImpl实现类
class ComputedRefImpl<T> {private _value!: Tprivate _dirty = truepublic readonly effect: ReactiveEffect<T>public readonly __v_isRef = true;public readonly [ReactiveFlags.IS_READONLY]: booleanconstructor(getter: ComputedGetter<T>, // 一个getter参数private readonly _setter: ComputedSetter<T>, // 一个原则上只读的setter参数isReadonly: boolean // 原则上只读,除非传入computed的参数既不是函数,而且对象中包含了set,当然,这样的情况开发环境会报错) {this.effect = effect(getter, {lazy: true,scheduler: () => {if (!this._dirty) {this._dirty = truetrigger(toRaw(this), TriggerOpTypes.SET, 'value')}}})this[ReactiveFlags.IS_READONLY] = isReadonly}get value() {// the computed ref may get wrapped by other proxies e.g. readonly() #3376const self = toRaw(this)console.log('this=======>', this)if (self._dirty) {self._value = this.effect()self._dirty = false}track(self, TrackOpTypes.GET, 'value') // 追踪依赖当前computed的数据,由于computed原则上也是一个ref,所以取得是valuereturn self._value // 返回通过effect执行后返回的最新值}set value(newValue: T) {this._setter(newValue) // set则直接执行传入的setter即可}}
我们可以看到ComputedRefImpl在构造器中为实例新增了一个effect属性
而属性对应的值为effect函数执行的结果
值得注意的是传入第二个参数中的调度器
我们可以看到调度器中触发trigger
这意味着computed的getter可以在getter函数内部依赖的其他响应式数据的更新时更新自身值
而getter和setter则十分乏善可陈
无非就是触发各自的getter和setter
5.3、总结
computed可以通过调度器的方式触发trigger获取依赖数据的更新而触发自身更新
不推荐在computed中传入setter,造成开发逻辑混乱
四. 学习感悟及收获
阅读到这里
相信各位同学都已经对vue3的数据监听原理有所了解
也大致知道了vue2数据监听有何缺点,以及为何要升级到vue3
同时也对学习vue3源码的储备知识有所学习
文章的最后想要引用教员的一段话作为结尾
人的正确思想是从哪里来的是从天上掉下来的吗?
不是
是自己头脑里固有的吗?
不是
人的思想,只能从社会实践中来
希望各位同学包括笔者自己都能从实践中学习到正确的思想
而vue3的学习也只是工程思想实践的一部分
最后祝愿各位同学都能工作顺利,实现理想~
那么,我们下期再见吧👋🏻
内推社群
我组建了一个氛围特别好的腾讯内推社群,如果你对加入腾讯感兴趣的话(后续有计划也可以),我们可以一起进行面试相关的答疑、聊聊面试的故事、并且在你准备好的时候随时帮你内推。下方加 winty 好友回复「面试」即可。