
如何让“GMV下降”实现自动化分析?
前言:
1. 分析思路
1.1 定位问题
1.2 排查影响因素
2. 自动化实现
2.1 必备功能(由始至终)
2.2 面向用户(由内而外)
2.3 前后端逻辑
前言:
作为一名数据分析师,分析“某某指标下降或者提升”是非常日常的工作。但如果每次一遇到这类问题就一通操作分析,着实有些耽误时间。好在这类“指标异动”的分析通常是有一些固定的套路的,逻辑并不复杂。
因此,咱们尝试抽象出这类问题的解决方法,并做一个「自动分析」的工具,来替代数据分析师的这部分日常工作,解放生产力呀。
本文就拿“GMV异动”举例,来介绍这类指标异动的分析思路、以及如何实现自动化。
其中“分析思路”在业内主要有两种:贡献度和基尼系数。本文主要介绍前者。
1. 分析思路
1.1 定位问题
1. 确定发生期和基准期
即:什么时候相对什么时候的下降?
发生期:GMV产生变化的时期,比如2021年11月1号-11月30号 基准期:参照期,比如2021年10月1号-10月31号
这里注意,发生期和基准期的天数是否相同?如果是相同,那么直接对比总GMV变化就行;反之可以对比他们的日均GMV变化。为了方便“自动化”,我们暂且都按日均GMV算。
2. 确定数据准确性
这是我们在收到“GMV异动”时候,第一个要排查的因素!
为什么要把【数据准确性】放到第一个?因为以免我们吭哧吭哧分析半天后发现:“原来只是数据源出问题了”,白白浪费了分析资源!
那么数据准确性可以从以下几个方向确定:
数据传输、存储、清洗有没有问题? 与该指标(GMV)关联的其他指标是否异常? 指标统计口径是否异常? 是否有业务逻辑上的更改? 是否埋点上报异常? 是否指标计算方式更改?
3. 按【GMV=dau转化率客单价】来定位问题所在
到此,我们进入正题,开始开始定位GMV异动的可能原因。
按GMV公式,我们分3步骤探索:
定位GMV下降的特征——对应GMV本身 是否是由于dau基数影响到gmv——对应公式里的dau 定位GMV下降的特征的支付漏斗折损位置——对应公式里的转化率
下面具体展开:
1)定位GMV下降的特征
统计GMV的常见维度,分为固有属性和变化属性,如:
固有属性:(用户从一开始就自带的属性,在之后的行为里都不会发生变化) 新增渠道:ios,华为,小米,vivo,oppo,其他... 城市线 :一线,二线,三线,... ...
变化属性:(用户在之后的行为里可能会产生变化的)
支付时段:0-6点,6-12点,12-18点,18-24点 支付方式:sdk支付,微信支付,... sku类型:包月,包季,包年,... ...
展开这些维度,计算这些维度下的特征对GMV异动的贡献度,并按贡献度降序排名
记:
发生期各维度的特征为gmv2,总值为sum2
基准期各维度的特征为gmv1,总值为sum1
某特征贡献度=(gmv2-gmv1)/(sum2-sum1)
给贡献度设定阈值,认为超过该阈值就是需要重视的特征,比如“贡献度超过20%”就算它是影响GMV异动的特征
把以上特征分为【固有特征】和【变化特征】
2)是否是由于dau基数影响到gmv
计算两个时期下的【固有特征】的特征的DAU相对差异:
同样还是给差异设定阈值,如果超过该阈值就是dau基数影响了GMV。
比如:
“新增渠道-ios,在发生期的dau比基准期的dau低了50%”,那我们就认为ios的基数变化可能是影响GMV异动的因素之一。
3)定位GMV下降的特征的支付漏斗折损位置
计算两个时期下的【固有特征】和【变化特征】的转化漏斗,来看是哪个位置的上级转化率产生较大差异。
比如:
支付路径为【a-b-c-d-e】,其中发生期和基准期的【a-b-c-d】的各级转化率的相对差异不超过5%,比较稳定;但是发生期【d-e】的上级转化率的比对照期低50%,那我们认为【d-e】是一个对GMV异动折损比较大的位置。
综上,我们基本定位到:
是哪些特征的GMV产生了异动? 是否是因为这些特征原本的基数(dau)异动了,而导致GMV异动? 在这些特征下的支付路径上,有哪些位置产生了折损?
1.2 排查影响因素
我们再继续从产品内外部寻找可能导致产生“异动特征和折损位置”的事件。
1. 内部
大盘 拉长时间轴到去年/上季度/上月/上周同期,看历史异常还是近期异常?*添加其他产品的同期数据,看是否大家都是异常? 产品 发生期的版本是否有功能调整、样式改版、策略调整? 发生期的版本是否有其他缺陷? 技术 【支付路径】之间哪里有bug? 运营 运营活动、push效果如何? 拉新渠道、投放推广是否发生变化? 用户 用户群是否发生变化?
2. 外部(PEST)
政治 政策影响、监管 经济 竟品app数据、双11、618 社会 假期效应:开学季、暑期、传统节假日 热点事件:突发热点
综上,我们基本能定位到GMV下降的可能原因:
找出“异动特征和折损位置” 找出产生“异动特征和折损位置”的事件
2. 自动化实现
所谓“自动化”,其实是指:开发一个让“GMV下降”能够一键分析的数据产品。
我们首先需要确认该产品的必备功能;其次是它的面向用户,即“给谁用”;最后确定该产品的前端展示和后端交互逻辑。
2.1 必备功能(由始至终)
把必备功能分为以下3类:
展示现状:刚开始让用户看到他所要分析的2个时期的GMV现状,每天是如何波动的?绝对值差异和相对差异分别是啥样的? 自动一键分析:接下来交给我们后台一键分析,除了给出“异动特征和折损位置”的数据过程,还要对其每一步进行自动化文字解读。 快速:最后尽量使整个“一键分析”的过程控制在秒级别
2.2 面向用户(由内而外)
知道用户是谁,才能知道给他具体做什么功能;以及让这些功能的理解成本最低、用起来顺手又方便。
数据人员: 因为原本的“异动分析”工作是咱们数据分析师承担的,因此得要这个产品首先满足咱们自己人,先要让分析师用起来爽; 即使该产品的理解门槛高,分析师也能比较容易的解读。 业务人员: 其次是最关注“异动分析”的是业务同学,业务同学对“分析思路”的理解成本相对分析师要高一些,因此我们要把该产品的理解成本再降低,让业务更快跑起来! 有的业务同学在获取“GMV异动原因”的信息后,需要把这个解读汇报给领导,因此存在“信息二次传递”的情况,我们还需要继续往外考虑。 领导: 最后我们希望该产品能够被领导们用(称)上(赞)呀!让领导们能够自由分析、提高信息传递的效率,因此就更需要让该产品容易用、好用。
2.3 前后端逻辑
根据以上对产品功能、面向用户的明确,我们最后把产品的设计为如下几部分:
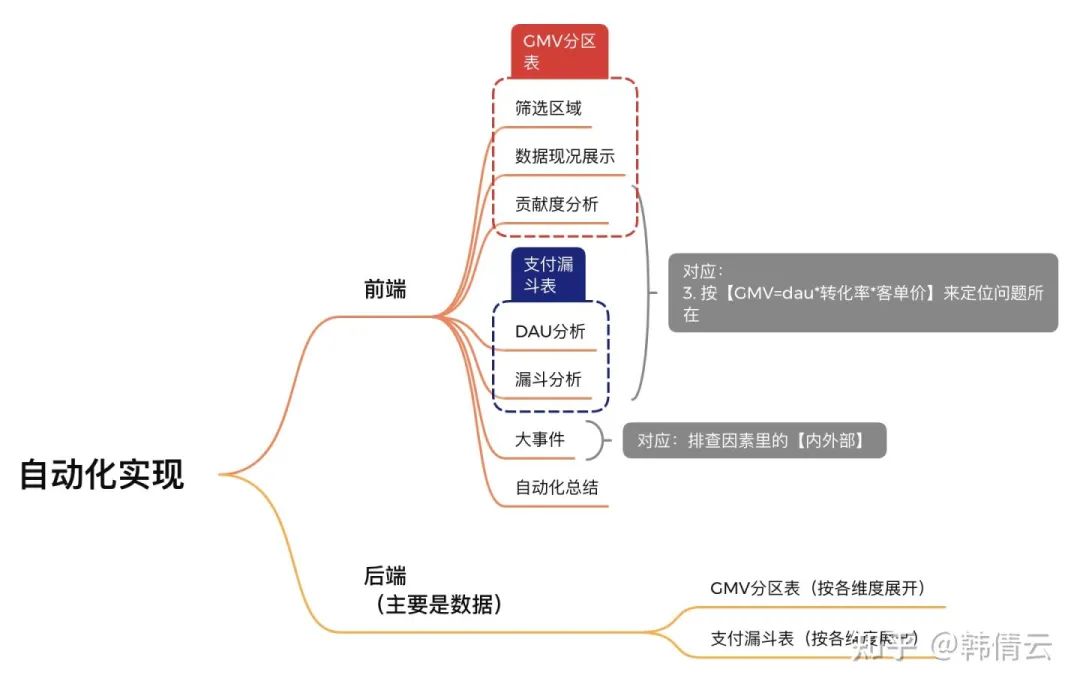
1. 前端
筛选区域: 日期:发生期、基准期 各个维度 数据现况展示:(使用GMV分区表) 相对差异:(发生期-基准期)/基准期,也按day1-dayn展开 基准期是20天、发生期是15天 那么横轴上起点是基准期和发生期的第一天的GMV、以此往后推 基准期的是day1-day20、发生期是day1-day15 横轴上先是基准期、再是发生期 拉长自然日期的GMV展示,比如: 合并2个时期的GMV绝对值展示,比如: 合并2个时期的GMV相对差异展示 贡献度分析:(使用GMV分区表) DAU分析:(使用支付漏斗表) 漏斗分析:(使用支付漏斗表)
以上3个步骤是对应【1.1定位问题:按【GMV=dau转化率客单价】来定位问题所在】
大事件: 大事件是指【排查因素里的内外部事件】,这部分需要人工手动维护。 自动化总结 对以上每个步骤的自动化文字总结,这样更方便用户理解分析过程。
2. 后端数据
GMV分区表(按各维度展开) 支付路径漏斗表(按各维度展开)
到此,实现“自动化GMV异动分析”的讲解就结束啦。总之,本文的分析思路是简化版,具体还需要各位大佬结合实际业务场景做定制化的修改啦~

