
【关于Transformer】 那些的你不知道的事 (下)
作者:杨夕
项目地址:https://github.com/km1994/nlp_paper_study
论文链接:https://arxiv.org/pdf/1706.03762.pdf
【注:手机阅读可能图片打不开!!!】
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
## 引言
本博客 主要 是本人在学习 Transformer 时的**所遇、所思、所解**,通过以 **十六连弹** 的方式帮助大家更好的理解 该问题。
## 十六连弹
1. 为什么要有 Transformer?
2. Transformer 作用是什么?
3. Transformer 整体结构怎么样?
4. Transformer-encoder 结构怎么样?
5. Transformer-decoder 结构怎么样?
6. 传统 attention 是什么?
7. self-attention 长怎么样?
8. self-attention 如何解决长距离依赖问题?
9. self-attention 如何并行化?
10. multi-head attention 怎么解?
11. 为什么要 加入 position embedding ?
12. 为什么要 加入 残差模块?
13. Layer normalization。Normalization 是什么?
14. 什么是 Mask?
15. Transformer 存在问题?
16. Transformer 怎么 Coding?
## 问题解答
### 十一、为什么要 加入 position embedding ?
- 问题:
- 介绍:缺乏 一种 表示 输入序列中 单词顺序 的方法
- 说明:因为模型不包括Recurrence/Convolution,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的分词相对或者绝对position信息利用起来
- 目的:加入词序信息,使 Attention 能够分辨出不同位置的词
- 思路:
- 在 encoder 层和 decoder 层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,让模型学习到这个值
- 位置向量的作用:
- 决定当前词的位置;
- 计算在一个句子中不同的词之间的距离
- 步骤:
- 将每个位置编号,
- 然后每个编号对应一个向量,
- 通过将位置向量和词向量相加,就给每个词都引入了一定的位置信息。
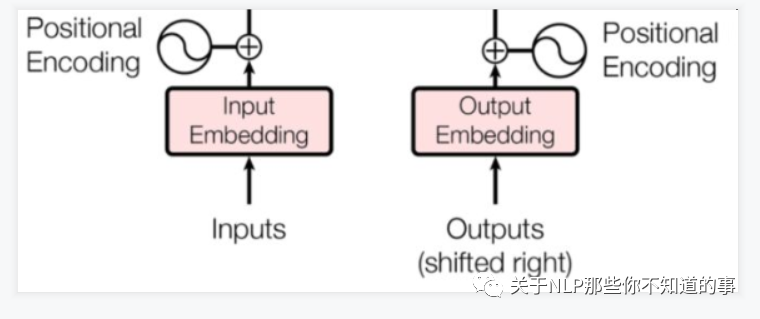
- 论文的位置编码是使用三角函数去计算的。好处:
- 值域只有[-1,1]
- 容易计算相对位置。
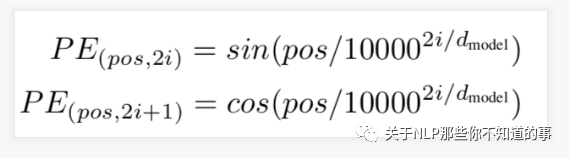
注:
$pos$ 表示当前词在句子中的位置
$i$ 表示向量中每个值 的 index
在偶数位置:使用 正弦编码 $sin()$;
在奇数位置:使用 余弦编码 $cos()$;
### 十二、为什么要 加入 残差模块?
- 动机:因为 transformer 堆叠了 很多层,容易 梯度消失或者梯度爆炸
### 十三、Layer normalization。Normalization 是什么?
- 动机:因为 transformer 堆叠了 很多层,容易 梯度消失或者梯度爆炸;
- 原因:
- 数据经过该网络层的作用后,不再是归一化,偏差会越来越大,所以需要将 数据 重新 做归一化处理;
- 目的:
- 在数据送入激活函数之前进行normalization(归一化)之前,需要将输入的信息利用 normalization 转化成均值为0方差为1的数据,避免因输入数据落在激活函数的饱和区而出现 梯度消失或者梯度爆炸 问题
- 介绍:
- 归一化的一种方式
- 对每一个样本介绍均值和方差【这个与 BN 有所不同,因为他是在 批方向上 计算均值和方差】
- 公式
> BN 计算公式
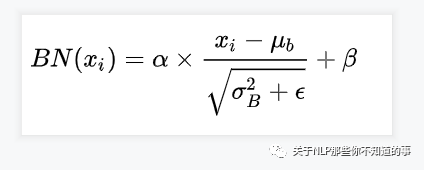
> LN 计算公式
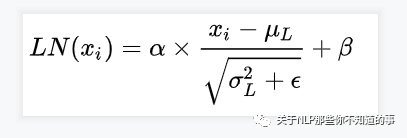
### 十四、什么是 Mask?
- 介绍:掩盖某些值的信息,让模型信息不到该信息;
- 类别:padding mask and sequence mask
- padding mask
- 作用域:每一个 scaled dot-product attention 中
- 动机:
- 输入句子的长度不一问题
- 方法:
- 短句子:后面 采用 0 填充
- 长句子:只截取 左边 部分内容,其他的丢弃
- 原因:
- 对于 填充 的位置,其所包含的信息量 对于 模型学习 作用不大,所以 self-attention 应该 抛弃对这些位置 进行学习;
- 做法:
- 在这些位置上加上 一个 非常大 的负数(负无穷),使 该位置的值经过 Softmax 后,值近似 0,利用 padding mask 标记哪些值需要做处理;
- sequence mask
- 作用域:只作用于 decoder 的 self-attention 中
- 动机:不可预测性;
- 目标:sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
- 做法:
- 产生一个下三角矩阵,上三角的值全为0,下三角全是 1。把这个矩阵作用在每一个序列上,就可以达到我们的目的
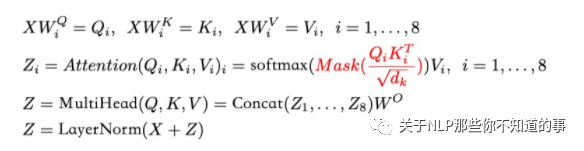
> sequence mask 公式

> 注意力矩阵, 每个元素 $a_{ij}$ 代表 第 i 个词和第 j 个词的内积相似度
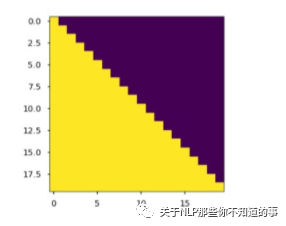
> 下三角矩阵,上三角的值全为0,下三角全是 1
注:
在 decoder 的 scaled dot-product attention 中,里面的 attn_mask = padding mask + sequence mask
在 encoder 的 scaled dot-product attention 中,里面的 attn_mask = padding mask
### 十五、Transformer 存在问题?
- 引言
- 居然 Transformer 怎么厉害,那么 是否也存在不足呢?
- 答案: 有的
- 问题一:不能很好的处理超长输入问题?
- 介绍:Transformer 固定了句子长度;
- 举例:
- 例如 在 Bert 里面,输入句子的默认长度 为 512;
- 对于长度长短问题,做了以下处理:
- 短于 512:填充句子方式;
- 长于 512:
- 处理方式一:截断句子方式(Transformer 处理方式);
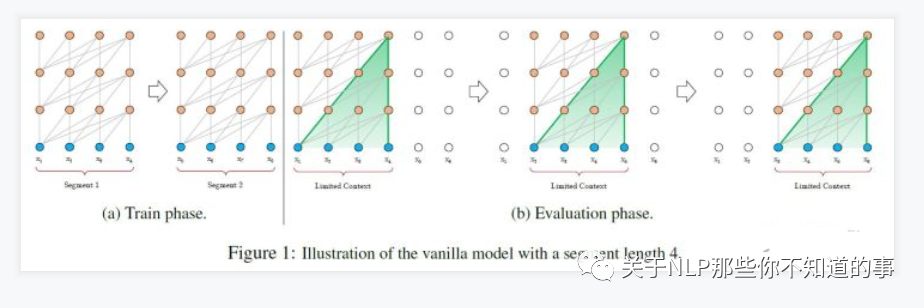
- 处理方式二:将句子划分为 多个 seg ([Vanilla Transformer](https://aaai.org/ojs/index.php/AAAI/article/view/4182) 处理方式);
- 思路:
- 将文本划分为多个segments;
- 训练的时候,对每个segment单独处理;
- 问题:
- 因为 segments 之间独立训练,所以不同的token之间,最长的依赖关系,就取决于segment的长度 (如图(a));
- 出于效率的考虑,在划分segments的时候,不考虑句子的自然边界,而是根据固定的长度来划分序列,导致分割出来的segments在语义上是不完整的 (如图(a));
- 在预测的时候,会对固定长度的 segment 做计算,一般取最后一个位置的隐向量作为输出。为了充分利用上下文关系,在每做完一次预测之后,就对整个序列向右移动一个位置,再做一次计算,这导致计算效率非常低 (如图(b));
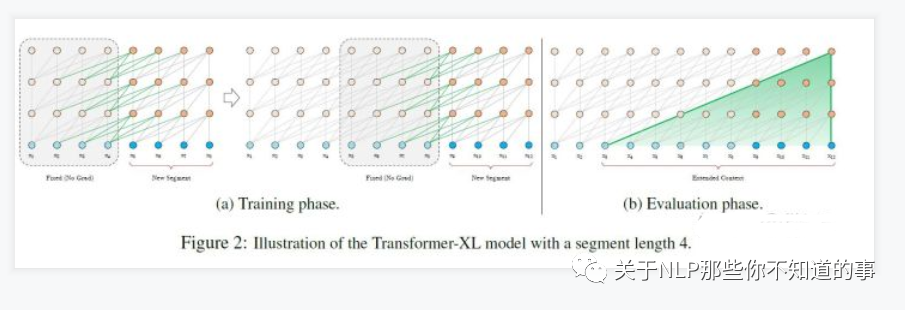
- 处理方式三:Segment-Level Recurrenc ( [Transformer-XL](https://aaai.org/ojs/index.php/AAAI/article/view/4182) 处理方式);
- 思路:
- 在对当前segment进行处理的时候,**缓存**并利用上一个segment中所有layer的隐向量序列;
- 上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播;
- 问题二:方向信息以及相对位置 的 缺失 问题?
- 动机:
- 方向信息和位置信息的缺失,导致 Transformer 在 NLP 中表现性能较差,例如在 命名实体识别任务中;
- 举例:
- 如下图,“Inc”单词之前的词很有可能就是机构组织(ORG),“in”单词之后的词,很有可能是时间地点(TIME);并且一个实体应该是连续的单词组成,标红的“Louis Vuitton”不会和标蓝的“Inc”组成一个实体。但是原始的Transformer无法捕获这些信息。

- 解决方法:
- 可以查看 [TENER: Adapting Transformer Encoder for Name Entity Recognition](https://arxiv.org/pdf/1911.04474.pdf) 【论文后期会做总结】
- 问题三:缺少Recurrent Inductive Bias
- 动机:
- 学习算法中Inductive Bias可以用来预测从未遇到的输入的输出(参考[10])。对于很多序列建模任务(如需要对输入的层次结构进行建模时,或者在训练和推理期间输入长度的分布不同时),Recurrent Inductive Bias至关重要【可以看论文[The Importance of Being Recurrent for Modeling Hierarchical Structure](https://arxiv.org/abs/1803.03585)】
- 问题四:Transformer是非图灵完备的: 非图灵完备通俗的理解,就是无法解决所有的问题
- 动机:
- 在Transformer中,单层中sequential operation ( context two symbols需要的操作数) 是$O(1)$ time,独立于输入序列的长度。那么总的sequenctial operation仅由层数$T$决定。这意味着transformer不能在计算上通用,即无法处理某些输入。如:输入是一个需要**对每个输入元素进行顺序处理**的函数,在这种情况下,对于任意给定的深度$T$的transformer,都可以构造一个长度为 $N>T$;
- 问题五:transformer缺少conditional computation
- 动机:
- transformer在encoder的过程中,所有输入元素都有相同的计算量,比如对于“I arrived at the bank after crossing the river", 和"river"相比,需要更多的背景知识来推断单词"bank"的含义,然而transformer在编码这个句子的时候,无条件对于每个单词应用相同的计算量,这样的过程显然是低效的。
- 问题六:transformer 时间复杂度 和 空间复杂度 过大问题
- 动机:
- Transformer 中用到的自注意力与长度n呈现出$O(n^2)$的时间和空间复杂度
- 解决方法:
- [Linformer](https://arxiv.org/abs/2006.04768)
### 十六、Transformer 怎么 Coding?
- 最后的最后,送上 whalePaper 成员 逸神 的 【[Transformer 理论源码细节详解](https://zhuanlan.zhihu.com/p/106867810)】;
- 理论+实践,干活永不累!
## 参考资料
1. [Transformer理论源码细节详解](https://zhuanlan.zhihu.com/p/106867810)
2. [论文笔记:Attention is all you need(Transformer)](https://zhuanlan.zhihu.com/p/51089880)
3. [深度学习-论文阅读-Transformer-20191117](https://zhuanlan.zhihu.com/p/92234185)
4. [Transform详解(超详细) Attention is all you need论文](https://zhuanlan.zhihu.com/p/63191028)
5. [目前主流的attention方法都有哪些?](https://www.zhihu.com/question/68482809/answer/597944559)
6. [transformer三部曲](https://zhuanlan.zhihu.com/p/85612521)
7. [Character-Level Language Modeling with Deeper Self-Attention](https://aaai.org/ojs/index.php/AAAI/article/view/4182)
8. [Transformer-XL: Unleashing the Potential of Attention Models](https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html)
9. [The Importance of Being Recurrent for Modeling Hierarchical Structure](https://arxiv.org/abs/1803.03585)
10. [Linformer](https://arxiv.org/abs/2006.04768)
