
基于 Golang 的云原生日志采集服务设计与实践

- 背景 -
在这股技术潮流之中,网易推出了轻舟微服务云平台,集成了微服务、Servicemesh、容器云、DevOps等,已经广泛应用于公司集团内部,同时也支撑了很多外部客户的云原生化改造和迁移。
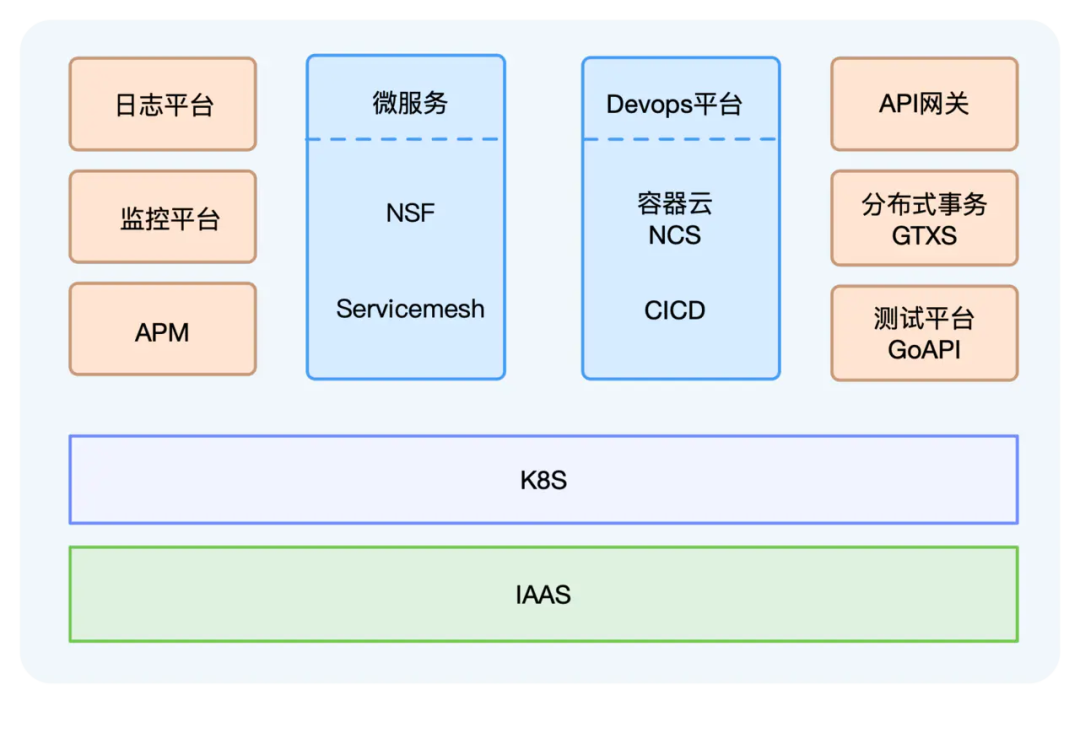
但是在云原生容器化环境下,日志的采集又变得有点不同。
- 容器日志采集的痛点 -
传统主机模式
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或者拿自动化工具把日志采集agent部署在节点上,加一下agent的配置,然后就可以开始采集日志了。同时为了方便后续的日志配置修改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境
一个Kubernetes node节点上有很多不同服务的容器在运行,容器的日志存储方式有很多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中经常存在Pod主动或者被动的迁移,频繁的销毁、创建,我们无法和传统的方式一样人为的给每个服务下发日志采集配置。另外,由于日志数据采集后会被集中存储,所以查询日志时,可以根据namespace、pod、container、node,甚至包括容器的环境变量、label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方式的需求和痛点,究其原因,还是因为传统的方式脱离了Kubernetes,无法感知Kubernetes,更无法和Kubernetes集成。
随着最近几年的迅速发展,Kubernetes已经成为容器编排的事实标准,甚至可以被认为是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的抽象解释如下图所示:
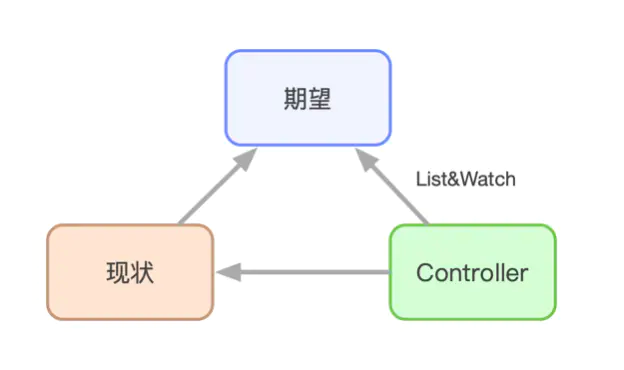
基于这个思路,对于日志采集来说,一个服务需要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就需要我们开发一个日志采集的controller去实现。
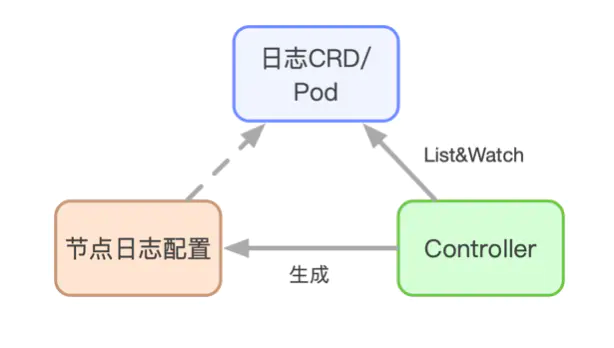
- 探索与架构设计 -
日志采集agent选型
Logstash基于JVM,分分钟内存占用达到几百MB甚至上GB,有点重,首先被我们排除。
Fluentd背靠CNCF看着不错,各种插件也多,不过基于Ruby和C编写,对于我们团队的技术栈来说,还是让人止于观望。
虽然Fluentd还推出了存粹基于C语言的Fluentd-bit项目,内存占用很小,看着十分诱惑,但是使用C语言和不能动态reload配置,还是无法令人亲近。
Loki推出的时间不久,目前还是功能有限,而且一些压测数据表明性能不太好,暂持观望。
Filebeat和Logstash、Kibana、Elasticsearch同属Elastic公司,轻量级日志采集agent,推出就是为了替换Logstash,基于Golang编写,和我们团队技术栈完美契合,实测下来个方面性能、资源占用率都比较优秀,于是成为了我们日志采集agent第一选择。
agent集成方式
- 整体架构 -
选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看到的架构如下所示:
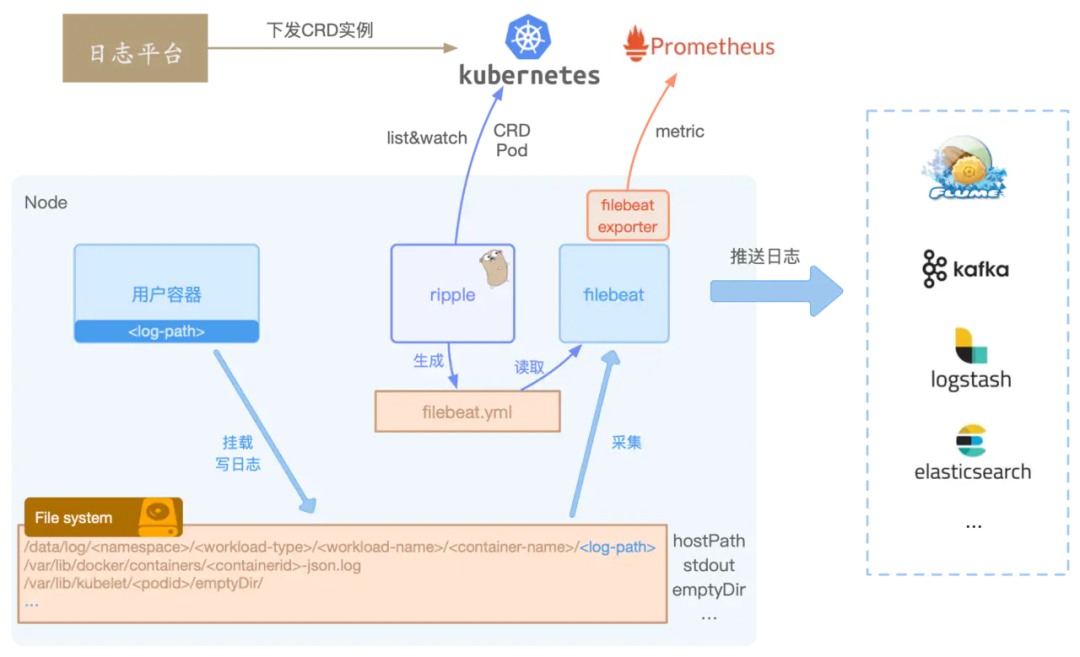
日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。 通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时还会默认把例如PodName、Hostname等配置到日志元信息中。 Filebeat则根据Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或者Elasticsearch等。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv存储日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以除了默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。除此之外,我们还给Ripple加入了日志定时清理,确保日志不丢失等功能,进一步增强了日志采集的功能和稳定性。
- 基于 Filebeat 的实践 -
功能扩展
Filebeat目前只提供了像elasticsearch、Kafka、logstash等几类output客户端,如果我们想要Filebeat直接发送至其他后端,需要定制化开发自己的output。同样,如果需要对日志做过滤处理或者增加元信息,也可以自制processor插件。无论是增加output还是写个processor,Filebeat提供的大体思路基本相同。一般来讲有3种方式:
直接fork Filebeat,在现有的源码上开发。
output或者processor都提供了类似Run、Stop等的接口,只需要实现该类接口,然后在init方法中注册相应的插件初始化方法即可。
当然,由于Golang中init方法是在import包时才被调用,所以需要在初始化Filebeat的代码中手动import。
复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。
本质上和方式1区别不大。
Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。
不过实际上一方面Golang plugin还不够成熟稳定,一方面自研的插件依然需要依赖相同版本的libbeat库,而且还需要相同的Golang版本编译,坑可能更多,不太推荐。
如果想要了解更多关于Filebeat的设计,可以参考这篇文章。 (https://juejin.im/post/6844903888726786055)
- 立体化监控 -
但是,真正的困难是在业务方实际使用之后,各种采集不到日志,多行日志配置或者采集二进制大文件导致Filebeat oom等问题接踵而至。我们又投入了更多的时间在对Filebeat和日志采集的全方位监控上,例如:
接入轻舟监控平台,有磁盘io、网络流量传输、内存占用、cpu使用、pod事件报警等,确保基础监控的完善。 加入了日志平台数据全链路延迟监控。 采集Filebeat自身日志,通过自身日志上报哪些日志文件开始采集,什么时候采集结束,避免每次都需要ssh到各种节点上查看日志配置排查问题。 自研Filebeat exporter,接入prometheus,采集上报自身metrics数据。
- Golang 的性能优化与调优 -
从Docker到Kubernetes,从Istio到Knative,基于Golang的开源项目已然是云原生生态体系的主力军,Golang的简洁高效也不断吸引着新的项目采用它作为开发语言。
但是很多时候,我们看过太多GC原理、内存优化、性能优化,却往往在写完代码、做完一个项目的时候,无从下手。 实践是检验真理的唯一标准。 所以,亲自动手去排查、摸索,才是提升姿势水平、找到关键问题的捷径。
对于性能优化,Golang贴心的为我们提供了三把钥匙:
go benchmark go pprof go trace
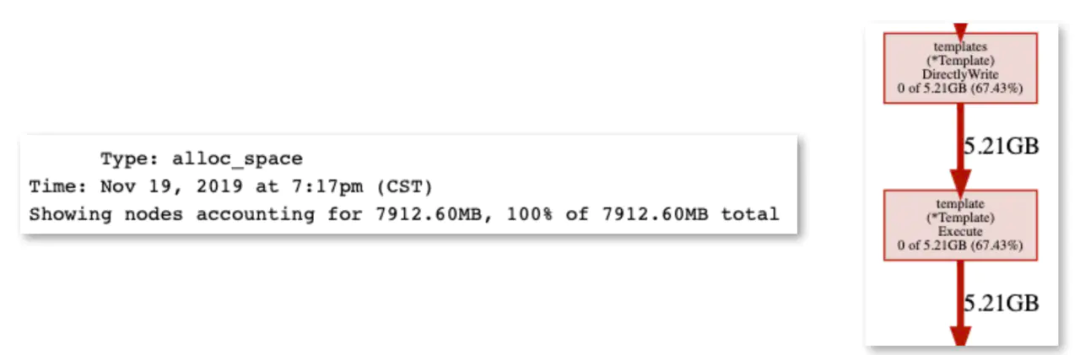
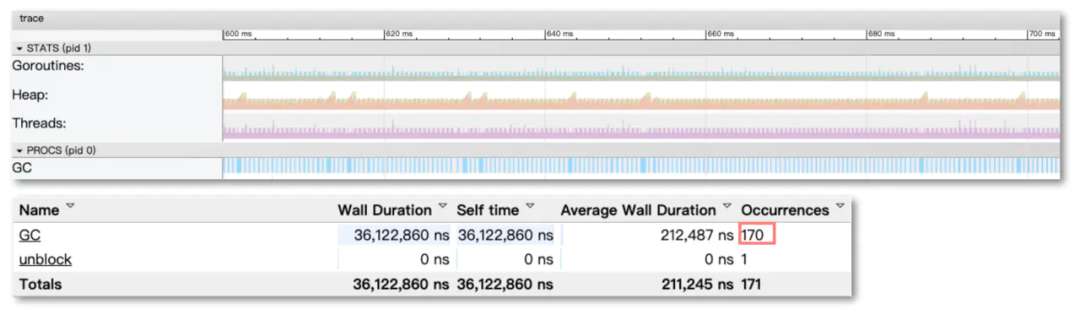
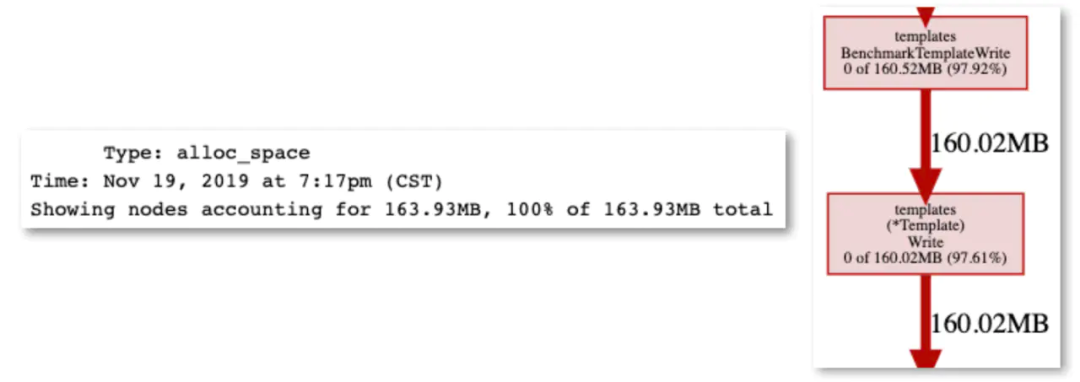
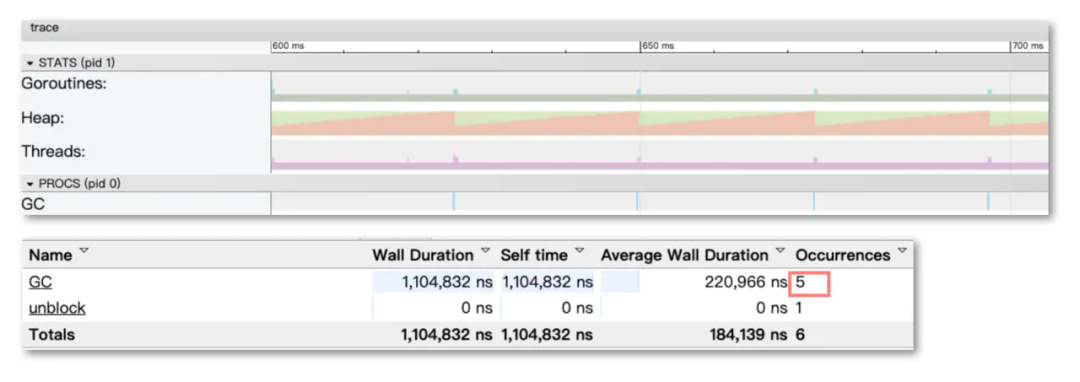
以sync.Pool为例,sync.Pool一般用于保存和复用临时对象,减少内存分配,降低GC压力。有很多的应用场景,例如号称比Golang官方Http快10倍的FastHttp大量使用了sync.Pool,Filebeat使用sync.Pool将批量日志数据聚合成Batch分批发送,Nginx-Ingress-controller渲染生成nginx配置时,也使用sync.Pool优化渲染效率。我们的日志controller Ripple也同样使用了sync.Pool去优化渲染Filebeat配置时的性能。


- 总结与展望 -
来源:
blog.csdn.net/m0_38110132/article/details/81481454

评论