
Python 带你做一个自动更换电脑壁纸软件
一、前言
1. 爬取图片
创建一个文件夹, 里面又有按英雄名称分的子文件夹保存该英雄的所有皮肤图片
import requests
import os
import json
from lxml import etree
from fake_useragent import UserAgent
import logging
2. 用Python更换壁纸
用到的 python 模块有win32api、win32con、win32gui、pathlib、time、random等,基本原理要用到电脑注册表、调用 windows 有关API。
win32api:提供了常用的用户API win32gui:提供了有关 windows 用户界面图形操作的API win32con:宏定义文件,基本上所有宏都集成在这里(5k+)
import win32api
import win32con
import win32gui
二、分析网页
首先打开王者荣耀官网,点击英雄资料进去。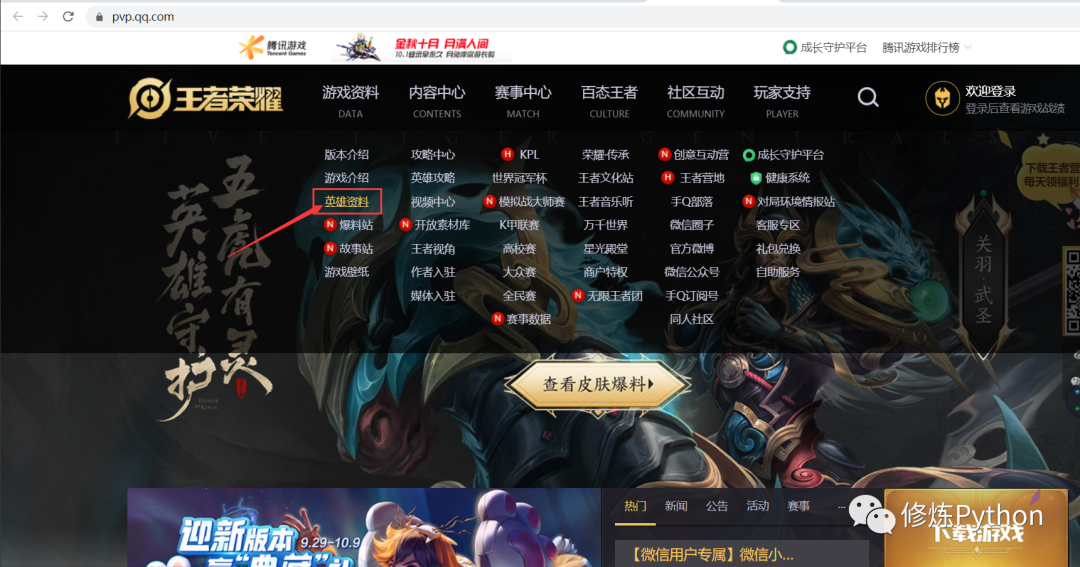 进入新的页面后,任意选择一个英雄,检查网页。
进入新的页面后,任意选择一个英雄,检查网页。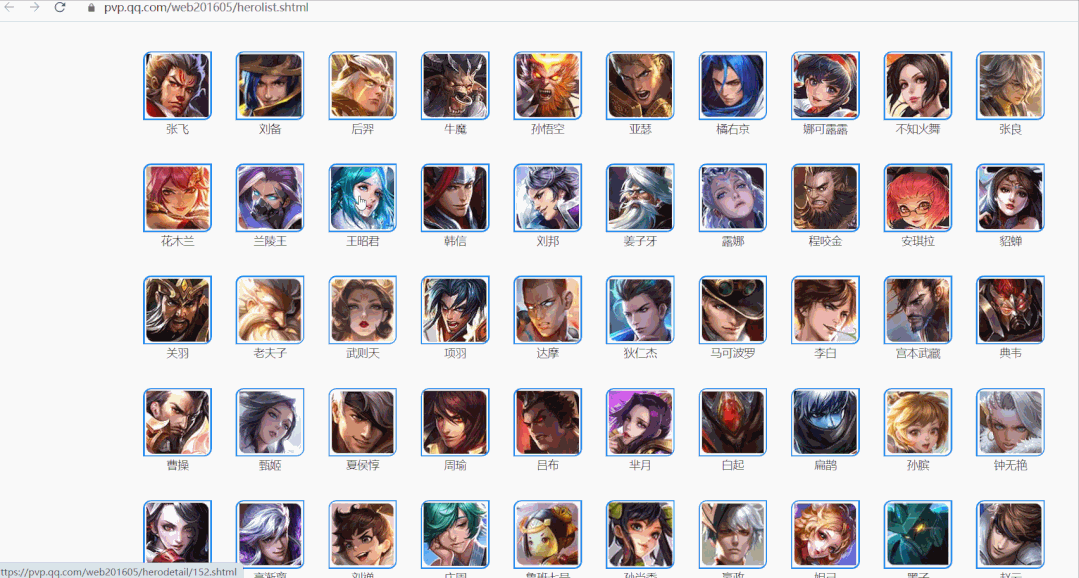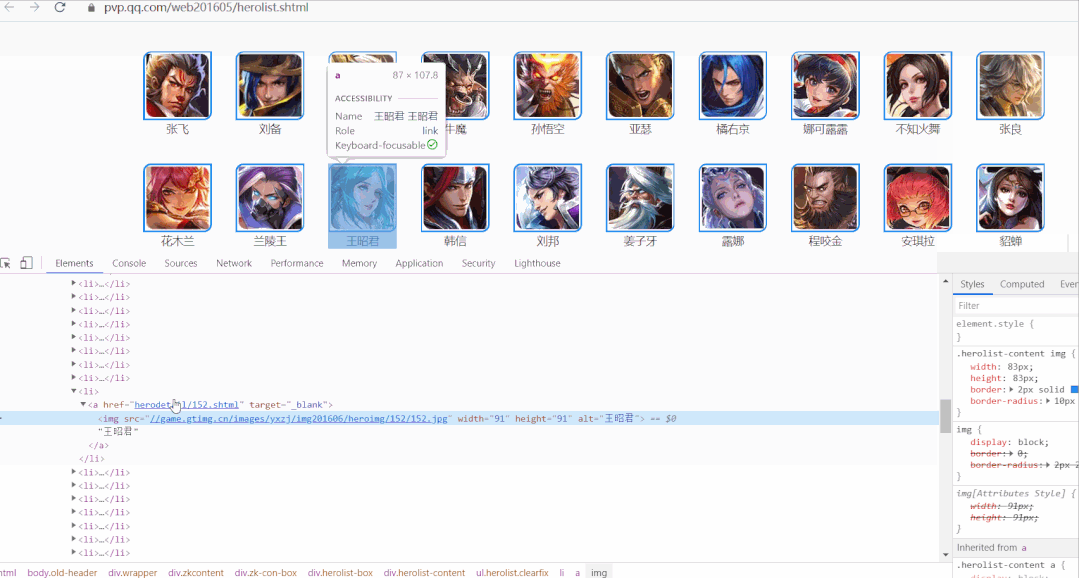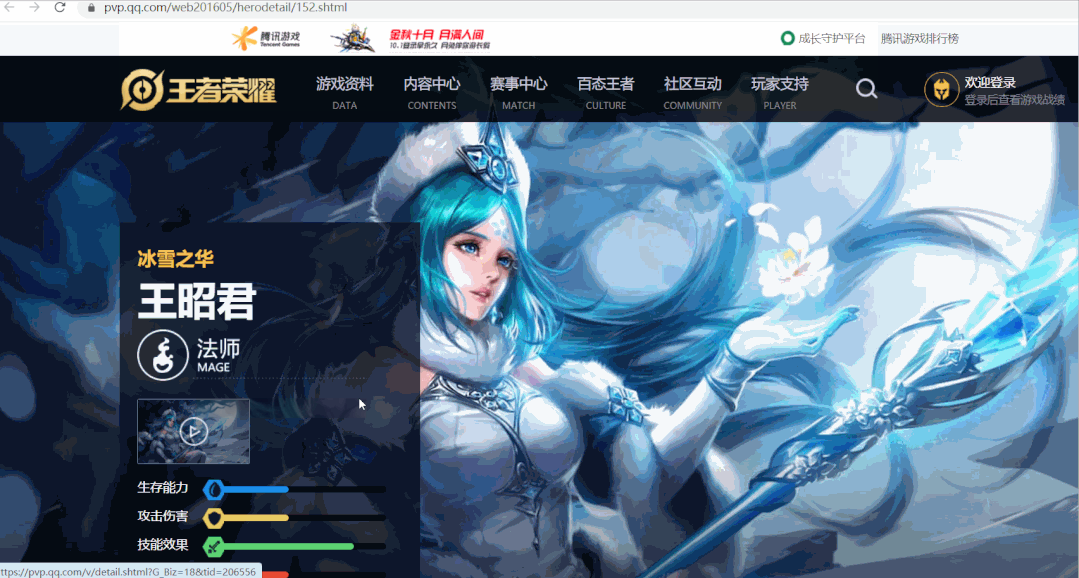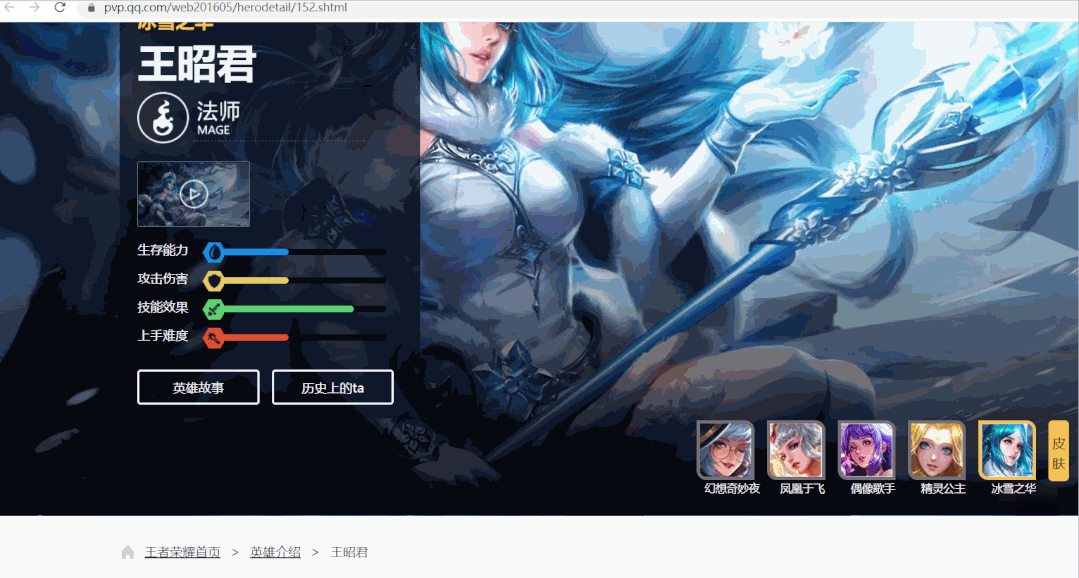
多选择几个英雄检查网页,可以发现各个英雄页面的URL规律
https://pvp.qq.com/web201605/herodetail/152.shtml
https://pvp.qq.com/web201605/herodetail/150.shtml
https://pvp.qq.com/web201605/herodetail/167.shtml
发现只有末尾的数字在变化,末尾的数字可以认为是该英雄的页面标识。
点击Network,Crtl + R 刷新,可以找到一个 herolist.json 文件。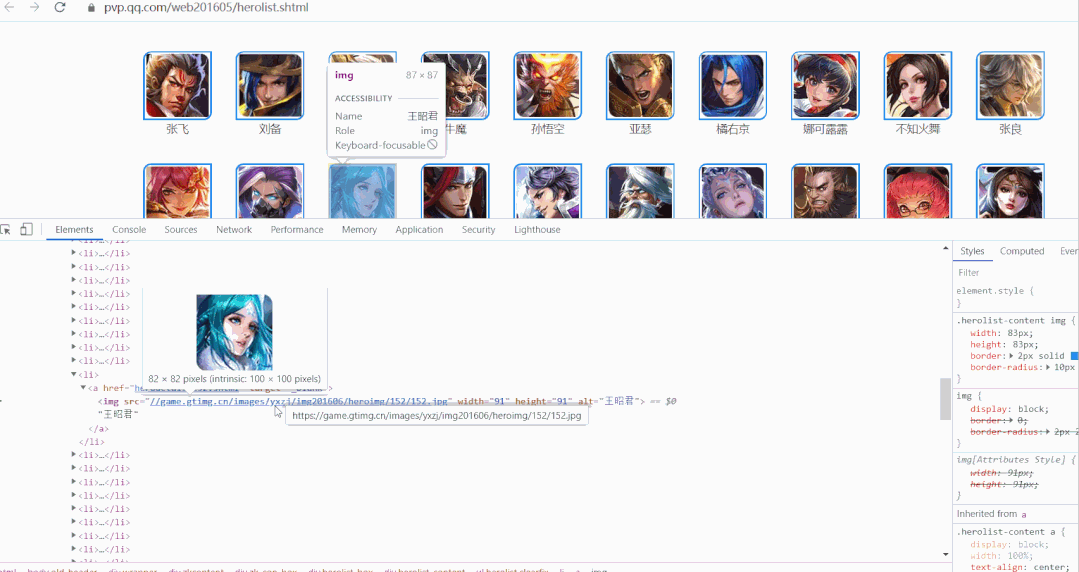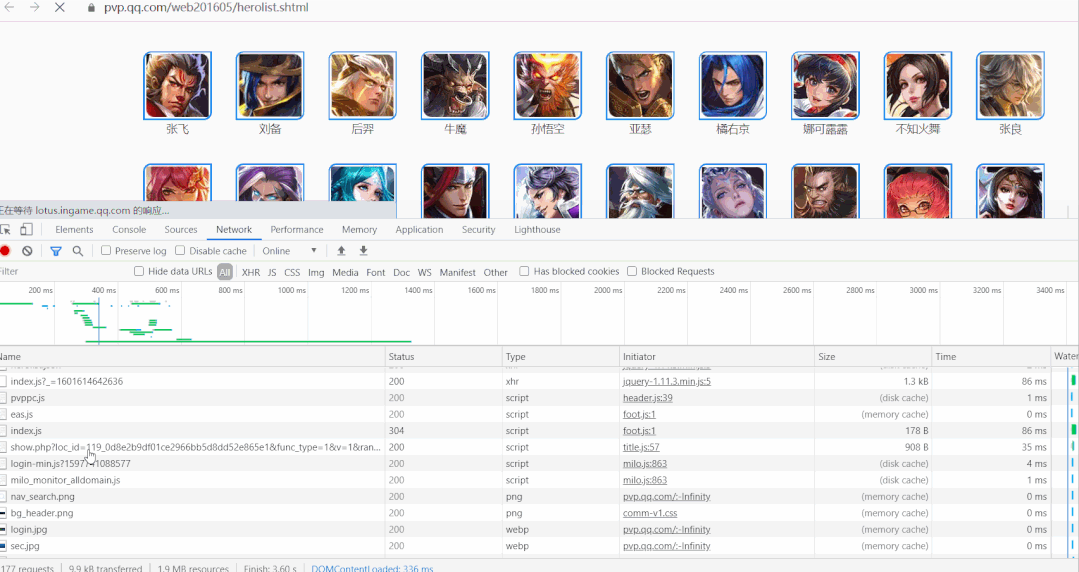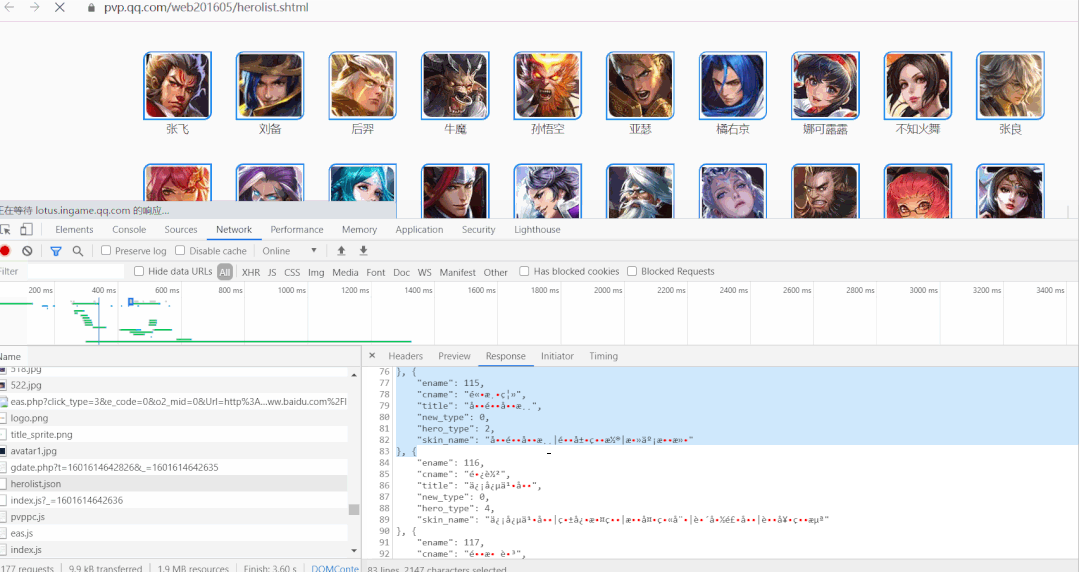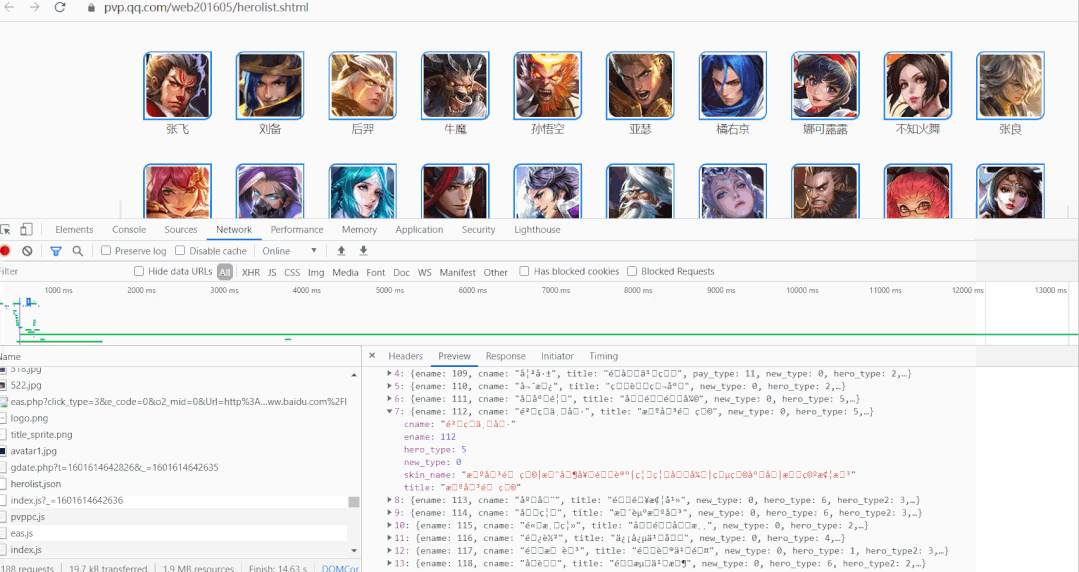 发现是乱码,但问题不大,双击这个 json 文件,将它下载下来观察,用编辑器(我用的是Sublime Text)打开可以看到。
发现是乱码,但问题不大,双击这个 json 文件,将它下载下来观察,用编辑器(我用的是Sublime Text)打开可以看到。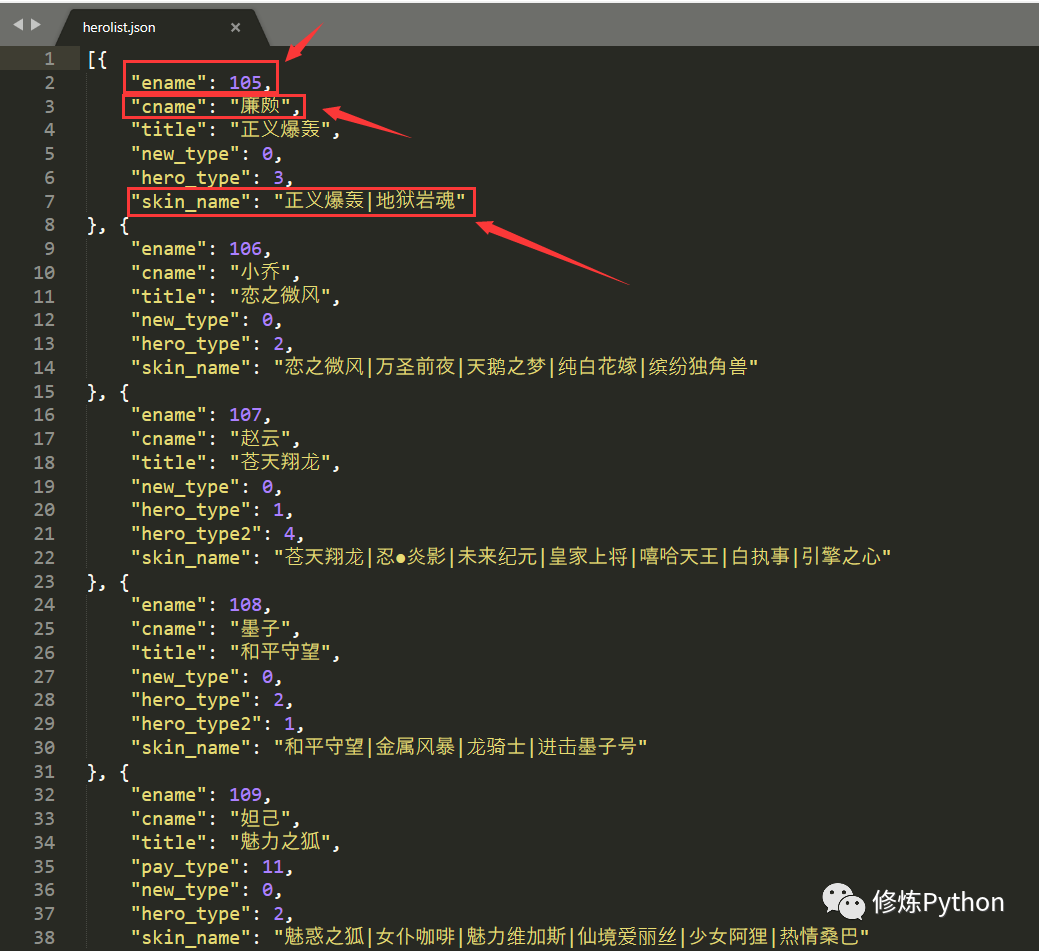
ename是英雄网址页面的标识;而 cname 是对应英雄的名称;skin_name为对应皮肤的名称。
任选一个英雄页面进去,检查该英雄下面所有皮肤,观察url变化规律。
url变化规律如下:
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-2.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-3.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-4.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-5.jpg
观察到同一个英雄的皮肤图片 url 末尾 -{x}.jpg 从 1 开始依次递增,再来看看不同英雄的皮肤图片 url 是如何构造的。会发现, ename这个英雄的标识不一样,获取到的图片就不一样,由 ename 参数决定。
https://game.gtimg.cn/images/yxzj/img201606/heroimg/152/152-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/150/150-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/heroimg/153/153-bigskin-1.jpg
# 可构造图片请求链接如下
https://game.gtimg.cn/images/yxzj/img201606/heroimg/{ename}/{ename}-bigskin-{x}.jpg
三、爬虫代码实现
# -*- coding: UTF-8 -*-
"""
@Author :叶庭云
@公众号 :修炼Python
@CSDN :https://yetingyun.blog.csdn.net/
"""
import requests
import os
import json
from lxml import etree
from fake_useragent import UserAgent
import logging
# 日志输出的基本配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
class glory_of_king(object):
def __init__(self):
if not os.path.exists("./王者荣耀皮肤"):
os.mkdir("王者荣耀皮肤")
# 利用fake_useragent产生随机UserAgent 防止被反爬
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random
}
def scrape_skin(self):
# 发送请求 获取响应
response = requests.get('https://pvp.qq.com/web201605/js/herolist.json', headers=self.headers)
# str转为json
data = json.loads(response.text)
for i in data:
hero_number = i['ename'] # 获取英雄名字编号
hero_name = i['cname'] # 获取英雄名字
os.mkdir("./王者荣耀皮肤/{}".format(hero_name)) # 创建英雄名称对应的文件夹
response_src = requests.get("https://pvp.qq.com/web201605/herodetail/{}.shtml".format(hero_number),
headers=self.headers)
hero_content = response_src.content.decode('gbk') # 返回相应的html页面 解码为gbk
# xpath解析对象 提取每个英雄的皮肤名字
hero_data = etree.HTML(hero_content)
hero_img = hero_data.xpath('//div[@class="pic-pf"]/ul/@data-imgname')
# 去掉每个皮肤名字中间的分隔符
hero_src = hero_img[0].split('|')
logging.info(hero_src)
# 遍历英雄src处理图片名称。
for j in range(len(hero_src)):
# 去掉皮肤名字的&符号
index_ = hero_src[j].find("&")
skin_name = hero_src[j][:index_]
# 请求下载图片
response_skin = requests.get(
"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg".format(
hero_number, hero_number, j + 1))
skin_img = response_skin.content # 获取每个皮肤图片二进制数据
# 把皮肤图片保存到对应名字的文件里
with open("./王者荣耀皮肤/{}/{}.jpg".format(hero_name, skin_name), "wb")as f:
f.write(skin_img)
logging.info(f"{skin_name}.jpg 下载成功!!")
def run(self):
self.scrape_skin()
if __name__ == '__main__':
spider = glory_of_king()
spider.run()
运行效果如下: 程序运行一段时间,英雄皮肤壁纸就都保存在本地文件夹啦,结果如下:
程序运行一段时间,英雄皮肤壁纸就都保存在本地文件夹啦,结果如下: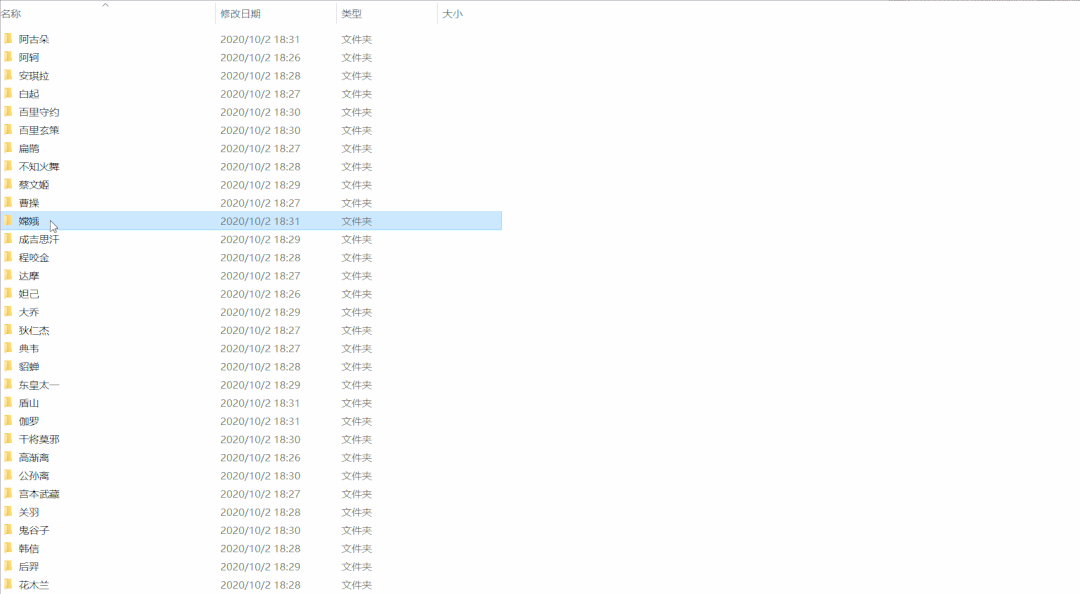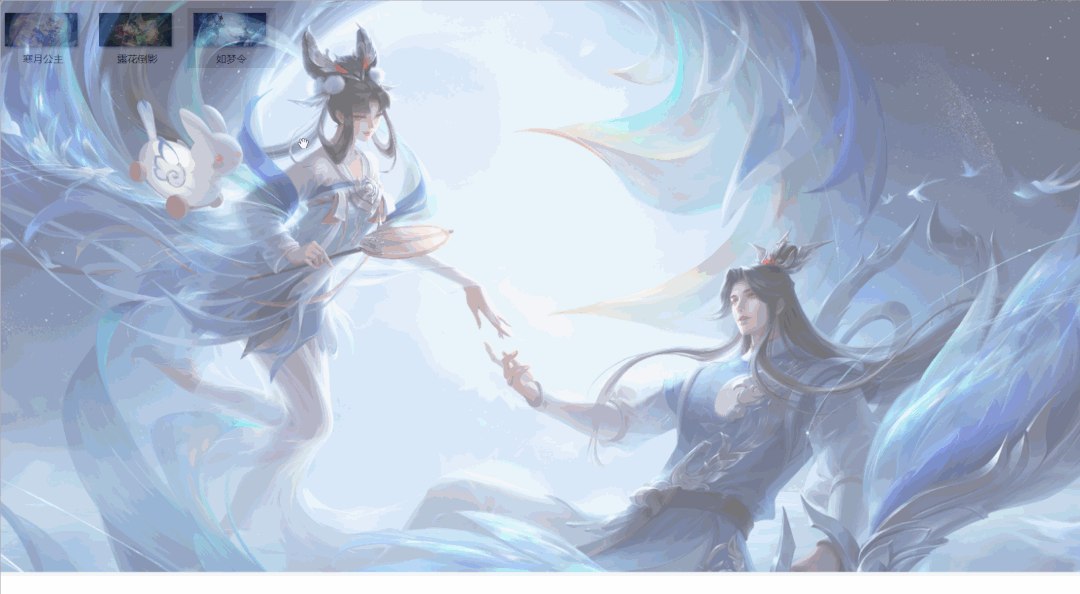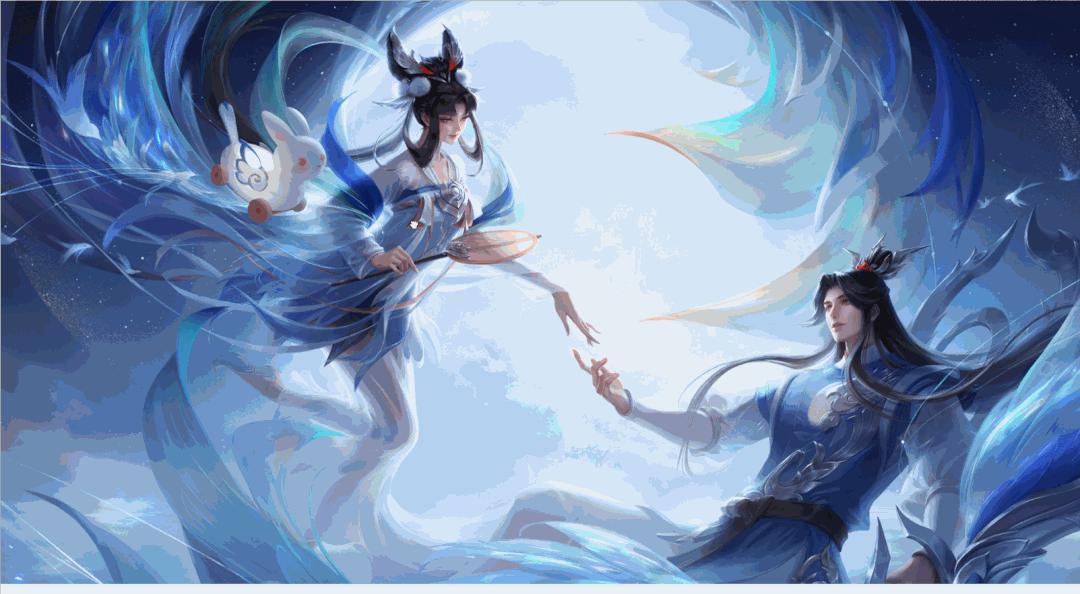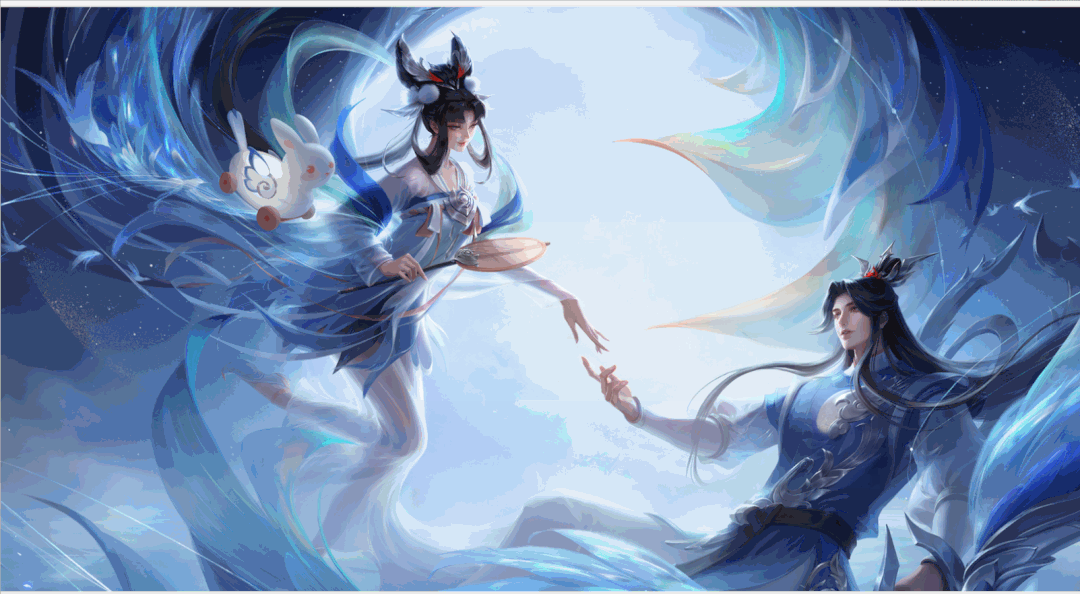
解决报错:fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
# 报错如下
Error occurred during loading data. Trying to use cache server https://fake-useragent.herokuapp.com/browsers/0.1.11
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 1318, in do_open
encode_chunked=req.has_header('Transfer-encoding'))
File "/usr/local/python3/lib/python3.6/http/client.py", line 1239, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/usr/local/python3/lib/python3.6/http/client.py", line 1285, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/usr/local/python3/lib/python3.6/http/client.py", line 1234, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/usr/local/python3/lib/python3.6/http/client.py", line 1026, in _send_output
self.send(msg)
File "/usr/local/python3/lib/python3.6/http/client.py", line 964, in send
self.connect()
File "/usr/local/python3/lib/python3.6/http/client.py", line 1392, in connect
super().connect()
File "/usr/local/python3/lib/python3.6/http/client.py", line 936, in connect
(self.host,self.port), self.timeout, self.source_address)
File "/usr/local/python3/lib/python3.6/socket.py", line 724, in create_connection
raise err
File "/usr/local/python3/lib/python3.6/socket.py", line 713, in create_connection
sock.connect(sa)
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 67, in get
context=context,
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 223, in urlopen
return opener.open(url, data, timeout)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 526, in open
response = self._open(req, data)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 544, in _open
'_open', req)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 504, in _call_chain
result = func(*args)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 1361, in https_open
context=self._context, check_hostname=self._check_hostname)
File "/usr/local/python3/lib/python3.6/urllib/request.py", line 1320, in do_open
raise URLError(err)
urllib.error.URLError:
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 154, in load
for item in get_browsers(verify_ssl=verify_ssl):
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 97, in get_browsers
html = get(settings.BROWSERS_STATS_PAGE, verify_ssl=verify_ssl)
File "/usr/local/python3/lib/python3.6/site-packages/fake_useragent/utils.py", line 84, in get
raise FakeUserAgentError('Maximum amount of retries reached')
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
# 将https://fake-useragent.herokuapp.com/browsers/0.1.11里内容复制 并另存为本地json文件:fake_useragent.json
# 引用
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
print(ua.random)
运行结果如下:
Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1500.55 Safari/537.36
四、自动更换壁纸
用到的 python 模块有win32api、win32con、win32gui、pathlib、time、random等,基本原理要用到电脑注册表、调用 windows 有关API。
win32api:提供了常用的用户API win32gui:提供了有关 windows 用户界面图形操作的API win32con:宏定义文件,基本上所有宏都集成在这里(5k+)
# -*- coding: UTF-8 -*-
"""
@Author :叶庭云
@公众号 :修炼Python
@CSDN :https://yetingyun.blog.csdn.net/
"""
import win32api
import win32con
import win32gui
import time
from pathlib import Path
import random
def windows_img(paper_path):
# 读取注册表
k = win32api.RegOpenKeyEx(win32con.HKEY_CURRENT_USER, "Control panel\\Desktop", 0, win32con.KEY_SET_VALUE)
# 在注册表中写入属性值
win32api.RegSetValueEx(k, "wapaperStyle", 0, win32con.REG_SZ, "2") # 0 代表桌面居中 2 代表拉伸桌面
win32api.RegSetValueEx(k, "Tilewallpaper", 0, win32con.REG_SZ, "2")
# 刷新桌面
win32gui.SystemParametersInfo(win32con.SPI_SETDESKWALLPAPER, paper_path, win32con.SPIF_SENDWININICHANGE)
def change_wallpaper():
# time_ = int(input("请输入壁纸更换时间间隔:"))
# path = input('请输入保存壁纸的路径:')
# 你保存图片的路径
path = r'D:\python\pycharm2020\my_program\Python 王者荣耀皮肤\王者荣耀皮肤'
p = Path(path)
# 该目录下所有jpg图片
imgs = p.glob('**/*.jpg')
wall_papers = []
for img in imgs:
print(img)
wall_papers.append(str(img))
# 随机打乱顺序
random.shuffle(wall_papers)
print(wall_papers)
num = 0
while True:
windows_img(wall_papers[num])
time.sleep(0.5) # 设置壁纸更换间隔,这里为3秒,根据用户自身需要自己设置秒数
num += 1
if num == len(wall_papers): # 如果到了最后一张图片,则重新回到第一张
num = 0
if __name__ == '__main__':
change_wallpaper()
五、打包成exe
有些换壁纸软件是点击 exe 运行就可以更换一次壁纸,我们也可以实现这样的功能,代码改动如下:
import win32api
import win32con
import win32gui
from pathlib import Path
import random
import os
def windows_img(paper_path):
# 读取注册表
k = win32api.RegOpenKeyEx(win32con.HKEY_CURRENT_USER, "Control panel\\Desktop", 0, win32con.KEY_SET_VALUE)
# 在注册表中写入属性值
win32api.RegSetValueEx(k, "wapaperStyle", 0, win32con.REG_SZ, "2") # 0 代表桌面居中 2 代表拉伸桌面
win32api.RegSetValueEx(k, "Tilewallpaper", 0, win32con.REG_SZ, "2")
# 刷新桌面
win32gui.SystemParametersInfo(win32con.SPI_SETDESKWALLPAPER, paper_path, win32con.SPIF_SENDWININICHANGE)
def change_wallpaper():
# time_ = int(input("请输入壁纸更换时间间隔:"))
# path = input('请输入保存壁纸的路径:')
# 你保存图片的路径 与程序在一个目录
path = os.path.abspath('王者荣耀皮肤')
p = Path(path)
# 该目录下所有jpg图片
imgs = list(p.glob('**/*.jpg'))
# 随机选择一张壁纸 切换
choice_index = random.randint(0, len(imgs) - 1)
img = imgs[choice_index]
img = os.path.join(str(img))
# print(img)
windows_img(img)
if __name__ == '__main__':
change_wallpaper()
Python脚本不能在没有安装 Python 的机器上运行。我们想把这个脚本分享给朋友使用,可她电脑又没有装Python。这个时候如果将脚本打包成 exe 文件,微信发送给她,即使她的电脑上没有安装 Python 解释器,这个 exe 程序也能在上面运行。岂不美哉?
PyInstaller是一个跨平台的Python应用打包工具,支持Windows/Linux/MacOS三大主流平台,能够把 Python 脚本及其所在的 Python 解释器打包成可执行文件,从而允许最终用户在无需安装 Python 的情况下执行应用程序。
pip install pyinstaller -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
PyInstaller 最简单使用只需要指定作为程序入口的脚本文件。PyInstaller 执行打包程序后会在当前目录下创建下列文件和目录:main.spec 文件,其前缀和脚本名相同,指定了打包时所需的各种参数;build 子目录,其中存放打包过程中生成的临时文件。warnxxxx.txt文件记录了生成过程中的警告/错误信息。如果 PyInstaller 运行有问题,需要检查warnxxxx.txt文件来获取错误的详细内容。xref-xxxx.html文件输出PyInstaller 分析脚本得到的模块依赖关系图。dist子目录,存放生成的最终文件。如果使用单文件模式将只有单个执行文件;如果使用目录模式的话,会有一个和脚本同名的子目录,其内才是真正的可执行文件以及附属文件。
pyinstaller参数详解
pyinstaller -F -w -i 图标文件路径 .py文件路径
结果如下:
找到 dist 文件夹里的带图标的 exe 程序,将放有壁纸图片的文件夹也剪切到 dist 文件夹里,双击运行,正常运行进入说明打包程序成功,为了使用方便,可以发送到桌面快捷方式。结果如下:
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典