
GUI实战|Python做一个文档图片提取软件

大家好,在上周的办公自动化系列文章中,我们已经讲解了如何用Python读取与写入Excel图片,在上上周的GUI系列文章中,也讲解了如何制作一个图片查看软件。
本文将进一步讲解如何用Python提取PDF与Word中图片,并结合之前讲解过的GUI框架PysimpleGUI,做一个多文件图片提取软件,效果如下: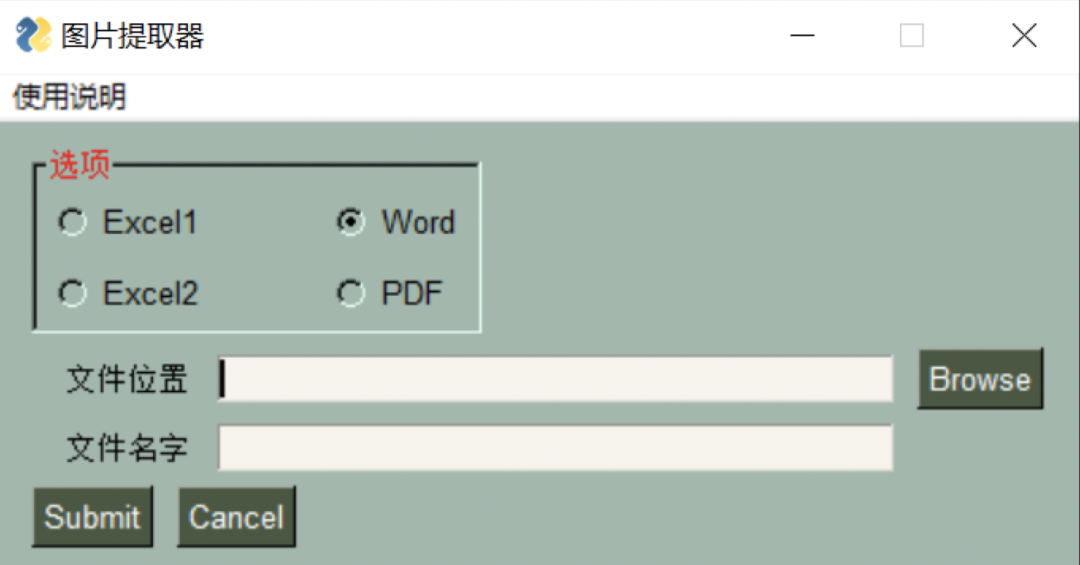
本文主要将分为以下部分讲解:
PDF、Word、Excel文件图片提取 构造图片提取器GUI框架 整合代码并打包
主要涉及的Python模块有:
PILPySimpleGUIrewin32oszipfilefitz
准备工作
首先使用pip安装相关依赖模块
pip install pillow #这是对模块PTL的安装
pip install pypiwin32 #这是对win32的安装
pip install os
pip install zipfile
pip install PyMuPDF #这是引用fitz对PDF操作的包
pip install PySimpleGui
一、提取各文件内嵌图片
在之前的文章有讲过,读取Excel有两种方法。一种是将后缀名改成.zip格式进行提取,一种是通过Pillow模块对Excel进行图片复制与保存。而在我们这次3种文件格式的图片提取当中,Excel提取图片方法和之前一样。
Word提取图片方法和通过.zip提取方法类似,PDF提取图片方法要用到新的模块。由于Excel提取图片的两种方法在之前的文章讲过,故这里只讲解PDF和Word的提取方法。
1.1 提取Word图片思路
和以前一样,我们先看代码再讲解
path = values["lujing"]
count = 1
for file in os.listdir(path):
new_file = file.replace(".docx",".zip")
os.rename(os.path.join(path,file),os.path.join(path,new_file))
count+=1
number = 0
craterDir = values["lujing"] + '/' # 存放zip文件的文件夹路径
saveDir = values["lujing"] + '/' # 存放图片的路径
list_dir = os.listdir(craterDir) # 获取所有的zip文件名
for i in range(len(list_dir)):
if 'zip' not in list_dir[i]:
list_dir[i] = ''
while '' in list_dir:
list_dir.remove('')
for zip_name in list_dir:
# 默认模式r,读
azip = zipfile.ZipFile(craterDir + zip_name)
# 返回所有文件夹和文件
namelist = (azip.namelist())
for idx in range(0,len(namelist)):
if namelist[idx][:11] == 'word/media/':#图片是在这个路径下
img_name = saveDir + str(number)+'.jpg'
f = azip.open(namelist[idx])
img = Image.open(f)
img = img.convert("RGB")
img.save(img_name,"JPEG")
number += 1
azip.close() #关闭文件,必须有,释放内存
这里的代码和GUI中通过.zip方式提取Excel图片的代码思路是一样的。
“
path = values["lujing"]这里是读取GUI中键为**“lujing”**的值,也即文件存储位置,用于os模块读取与操作。
new_file = file.replace(".docx",".zip")是替换后缀名,如果是Excel的话,就把.docx改成.xlsx或xls。
craterDir = values["lujing"] + '/'这是存放zip文件的文件夹路径,注意这里读取到的键为“lujing”的值后要在后面添加/。”
saveDir = values["lujing"] + '/'这是存放图片的路径,同理,和上面一样加个/号。
最后说一下与Excel提取相比,最大的不同是下面的代码
if namelist[idx][:11] == 'word/media/':细心的读者可以发现,与Excel提取相比,中括号里面的值改了。
很好理解,我们可以打印namelist[idx],可以发现在索引0到10是'word/media/'所在位置。而在Excel中是前9位。
感兴趣的读者可以翻看之前的文章,那里有对这段代码的详细解析,这里不多做介绍。
1.2 提取PDF图片思路
和之前的excel提取图片一样,在一个pdf中放入4张图片,我们将它压缩为zip文件👇
读取后👇
相关代码如下:
def pdf2pic(path, pic_path):
doc = fitz.open(path)
nums = doc._getXrefLength()
imgcount = 0
for i in range(1, nums):
text = doc._getXrefString(i)
if ('Width 2550' in text) and ('Height 3300' in text) or ('thumbnail' in text):
continue
checkXO = r"/Type(?= */XObject)"
checkIM = r"/Subtype(?= */Image)"
isXObject = re.search(checkXO, text)
isImage = re.search(checkIM, text)
if not isXObject or not isImage:
continue
imgcount += 1
pix = fitz.Pixmap(doc, i)
img_name = "img{}.png".format(imgcount)
if pix.n < 5:
try:
pix.writePNG(os.path.join(pic_path, img_name))
pix = None
except:
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(pic_path, img_name))
pix0 = None
if __name__ == '__main__':
path = values["lujing"]+ '/' + values["wenjian"]
pic_path = values["lujing"]
pdf2pic(path, pic_path)
先说一下这段代码的思路吧,由于PDF不能像Excel和Word一样改后缀名进行提取,故这里运用python的一个模块PyMuPDF,过程如下
读取PDF并遍历每一页 筛选无用的元素并用正则表达式获取图片 生成并保存图片
fitz.open(path)是打开PDF文件夹,这里的path是需要在GUI界面中获取用户的文件存放路径于文件名的。
for i in range(1, nums):
text = doc._getXrefString(i)
这是我们的第一步读取并遍历,将读取到的字符串内容放入到text中
if ('Width 2550' in text) and ('Height 3300' in text) or ('thumbnail' in text):
continue
由于PDF每一页的背景就是一张图片,故我们可以通过宽高来寻找这些背景图片并用continue把他们剔除。
checkXO = r"/Type(?= */XObject)"
checkIM = r"/Subtype(?= */Image)"
isXObject = re.search(checkXO, text)
isImage = re.search(checkIM, text)
if not isXObject or not isImage:
continue
我们通过实验发现图片所对应的字符串在checkxo与checkIM这两个中。故用正则表达式在text中进行索引提取,用到了re模块的search函数。如果不是这两个字符串就用continue剔除。
pix = fitz.Pixmap(doc, i)
img_name = "img{}.png".format(imgcount)
if pix.n < 5:
try:
pix.writePNG(os.path.join(pic_path, img_name))
pix = None
except:
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(pic_path, img_name))
pix0 = None
这是最后一步生成与保存图片
“
pix = fitz.Pixmap(doc, i)是生成图像语句,doc代表PDF文件,i代表遍历每个图片对象的索引值。”
img_name = "img{}.png".format(imgcount)是设置图像名语句,用提取到的图片的序列号作为命名格式。
而后if嵌套try那几行代码是保存图像语句。如果pix.n<5,可以直接存为PNG,否者将进行RGB变换在保存。
由于代码采用的是def函数编写模式,故最后还要一个函数的初始化:if __name__ == '__main__':
至此,3种文件格式(Excel、Word、PDF)图片提取方法已全部讲解,接下来就是重中之重GUI构建了。
二、GUI框架构建
先看完整代码:
import PySimpleGUI as sg
sg.ChangeLookAndFeel('GreenTan') #更换主题
menu_def = [['&使用说明', ['&注意']]]
layout = [
[sg.Menu(menu_def, tearoff=True)],
[sg.Frame(layout=[
[sg.Radio('Excel1', "RADIO1",size=(10,1),key="Excel1"), sg.Radio('Word', "RADIO1",default=True,key="Word")],
[sg.Radio('Excel2', "RADIO1", enable_events=True, size=(10,1),key="Excel2"), sg.Radio('PDF', "RADIO1",key="PDF")]], title='选项',title_color='red', relief=sg.RELIEF_SUNKEN, tooltip='Use these to set flags')],
[sg.Text('文件位置', size=(8, 1), auto_size_text=False, justification='right'),
sg.InputText(enable_events=True,key="lujing"), sg.FolderBrowse()],
[sg.Text('文件名字', size=(8, 1), justification='right'),
sg.InputText(enable_events=True,key="wenjian")],
[sg.Submit(tooltip='文件'), sg.Cancel()]]
window = sg.Window('图片提取器', layout, default_element_size=(40, 1), grab_anywhere=False)
while True:
event, values = window.read()
if event == "Submit":
if values["Excel2"] == True:
'''
事件绑定
'''
sg.Popup("提取成功")
if values["Excel1"] == True:
'''
事件绑定
'''
sg.Popup("提取成功")
if values["Word"] == True:
'''
事件绑定
'''
sg.Popup("提取成功")
if values["PDF"] == True:
'''
事件绑定
'''
sg.Popup("提取成功")
if event == "Cancel" or event == sg.WIN_CLOSED:
break
if event == "注意":
sg.Popup("作用讲解:",
"Excel1 :解析选定位置中所有的Excel文件,无需在文件名处填写",
"Excel2 :解析选定位置中单个指定的Excel文件,需在文件名处填写",
"Word : 解析选定位置中单个指定的docx结尾的文件,无需在文件名处填写",
"PDF : 解析选定位置中单个指定的PDF文件,需在文件名处填写")
window.close()
效果呈现:
代码解析:做PySimpleGUI还是原来那个步骤:
Import Create some widgets Create the window Create the event loop
当然,做GUI之前就是先想清楚自己的图形交互页面长什么样,像我就是现在纸上画一个大概,这样更有益于制作页面。
第一步先引用模块
第二步添加元素(小部件)到容器(layout)中,这里先介绍一下用到的部件:
“
Menu:顾名思义,这是菜单栏,每个GUI都必带一个菜单栏来提示使用者该如何做,我们这里用了menu_def这个布局来完成菜单的设置。
Frame:这个跟layout布局完全相同,工作方式也一样,他们都是容器元素。可以看到“选项”那里是一个凹槽的正方形,里面装有四个选项,作用就是这个。注意,&这个符号的作用是创建相同类型的菜单,这里只有注意事项这一个菜单,故可以不用管,读者如果想添加同样的菜单的话必须添加一个&。tearoff=True这个参数是菜单栏中每个子选项上面加虚线。
Radio:单选按钮。我们只可以在同样的id上选择一个选项。id就是指代码中的“ra-dio1”。其中每个radio函数的第一个参数是文本内容,这里就是我们要进行提取的4个文件格式。而“size”就是位置,每行的第一个设同样的参数(10,1)。最后就是我们进行事件帮绑定的键,其中“enable_events”可以不写因为我们只是调用它而不用去对它产生事件。
Text:之前有讲是不能改的正文内容。同样这里设置的位置参数(8,1),justification='right'有点类似我们平常用word那个向右对其。
InputText:需要用户输入的正文内容。这里有两个需要我们填写的地方:文件位置和文件名。这里需要设置键,因为在后面事件绑定中我们需要调用文件存储路径和文件名,在文中上半部分有提到过。
FolderBrowse:简易的打开文件路径操作,不用你去复制路径。
Submit:确定按钮,这里绑定为执行提取文档图片事件”
Cancel:退出主程序按钮。
第三步就是创建窗口来容纳这些元素布置。
第四步创建事件循环,可以看到代码,都是一样的套路:当用户按下submit按钮时系统将进行判断你按的是哪个单选按钮,进而进行相对应的事件执行。当你按下cancel或者×时,就是退出主程序。当你按菜单中的注意时,就会弹出一个对话框告诉你这个系统怎么用。
在事件循环中,我们用values[]的布尔值来判断我们选的是哪个单选按钮,有读者疑问为什么不用event=,因为我们在第一个if当中用了event所以第二个if当中需要换一个判断方法。
至此,GUI部分就搞定了!感兴趣的读者可以继续在上面添加功能。
三、打包
我们将完整代码整合在一起,后安装pyinstaller模块
pip install pyinstaller
如果你的上述项目代码文件命名为:photo.py。那么你要用下面命令进行打包
pyinstaller photo.py
最后打包成功之后,你会在py文件所在文件夹看到一个dist的子文件夹。进去之后,找到pachong.exe文件并运行它即可。
注意,文件夹里附带了很多文件,你可以删除它。当然,如果嫌麻烦就直接从photo.py文件用Python执行。
本文的全部代码全部都在文中,你可以将它组合来得到完整代码或者在后台回复1219获取。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】