
深信服aBos一体机介绍
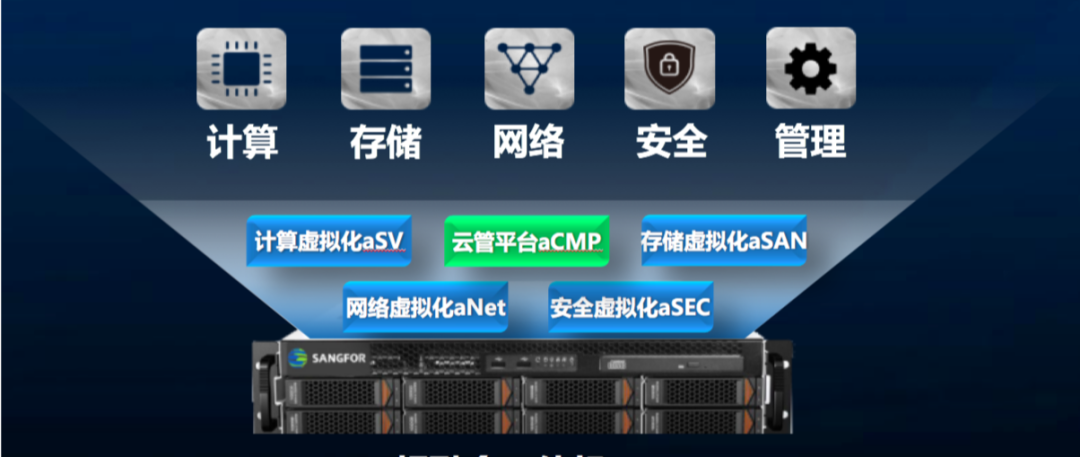

aBos一体机解决方案,是一种将网络设备、计算、存储等资源作为基本组成元素,通过一体机的方式承载中小型或者分支机构的 IT 网络建设技术。深信服的 aBos 一体机解决方案软件架构主要包含三大组件(网络设备虚拟化、服务器虚拟化、存储虚拟化)、一个 WEB 控制平台(虚拟化管理平台 VMP)、总部集中管理(BBC 管理中心)。
深信服的aBos 一体机解决方案中的计算虚拟化采用 aSV 虚拟化系统,通过将服务器资源虚拟化为多台虚拟机。最终用户可以在这些虚拟机上安装各种软件,挂载磁盘,调整配置,调整网络,就像普通的 x86 服务器一样使用它。
Hypervisor 是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,因此也可以看作是虚拟环境中的“元”操作系统,它可以协调访问服务器上的所有物理设备和虚拟机,也叫虚拟机监视器(Virtual Machine Monitor)。
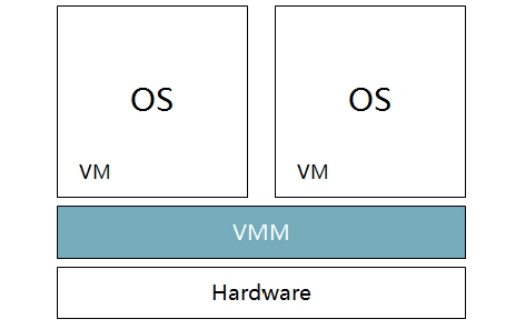
Hypervisor 是所有虚拟化技术的核心。非中断地支持多工作负载迁移的能力是Hypervisor 的基本功能。当服务器启动并执行 Hypervisor 时,它会给每一台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统。
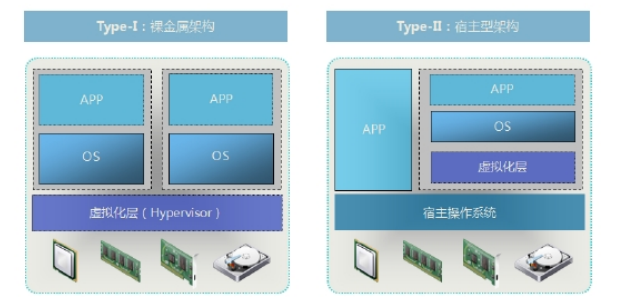
虚拟化技术架构Hypervisor,常见的 Hypervisor 分两类:
Type-I(裸金属型):指 VMM 直接运作在裸机上,使用和管理底层的硬件资源,GuestOS 对真实硬件资源的访问都要通过 VMM 来完成,作为底层硬件的直接操作者,VMM 拥有硬件的驱动程序。裸金属虚拟化中 Hypervisor 直接管理调用硬件资源,不需要底层操作系统,也可以理解为 Hypervisor 被做成了一个很薄的操作系统。这种方案的性能处于主机虚拟化与操作系统虚拟化之间。代表是 VMware ESX Server、Citrix XenServer 和 Microsoft Hyper-V,Linux KVM。
Type-II 型(宿主型):指 VMM 之下还有一层宿主操作系统,由于 Guest OS 对硬件的访问必须经过宿主操作系统,因而带来了额外的性能开销,但可充分利用宿主操作系统ᨀ供的设备驱动和底层服务来进行内存管理、进程调度和资源管理等。主机虚拟化中 VM 的应用程序调用硬件资源时需要经过:VM 内核->Hypervisor->主机内核,导致性能是三种虚拟化技术中最差的。主机虚拟化技术代表是 VMware Server (GSX )、Workstation 和Microsoft Virtual PC、Virtual Server 等。
由于主机型 Hypervisor 的效率问题,深信服的 aSV 采用了裸机型 Hypervisor 中 的 Linux KVM 虚拟化,即为 Type-I(裸金属型)。
KVM(Kenerl-based Virtual Machine) 是基于 linux 内核虚拟化技术,自linux2.6.20 之后就集成在 linux 的各个主要发行版本中。它使用 linux 自身的调度器进行管理,所以相对于 xen,其核心源码很少。KVM 是基于硬件虚拟化扩展(Intel VT- X )和QEMU 的修改版,KVM 属于Linux kernel 的一个模块,可以用命令 modprobe 去加载 KVM 模块。加载了该模块后,才能进一步通过工具创建虚拟机。
但是仅有 KVM 模块是不够的。因为用户无法直接控制内核去做事情,还必须有一个运行在用户空间的工具才行。这个用户空间的工具,我们选择了已经成型的开源虚拟化软件 QEMU,QEMU 也是一个虚拟化软件,它的特点是可虚拟不同的 CPU,比如说在 x86 的 CPU 上可虚拟一个 power 的 CPU,并可利用它编译出可运行在 power 上的 CPU,并可利用它编译出可运行在 power 上的程序。KVM 使用了QEMU 的一部分,并稍加改造,就成了可控制 KVM 的用户空间工具了。这就是 KVM 和QEMU 的关系。
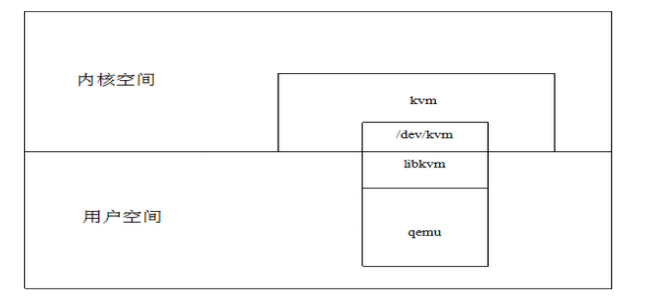
一个普通的 linux 进程有两种运行模式:内核和用户。而 KVM 增加了第三种模式:客户模式(有自己的内核和用户模式)。在 kvm 模型中,每一个虚拟机都是由 linux调度程序管理的标准进程。总体来说,kvm 由两个部分组成:一个是管理虚拟硬件的设备驱动,该驱动使用字符设备/dev/kvm 作为管理接口;另一个是模拟 PC 硬件的用户空间组件,这是一个稍作修改的 qemu 进程。
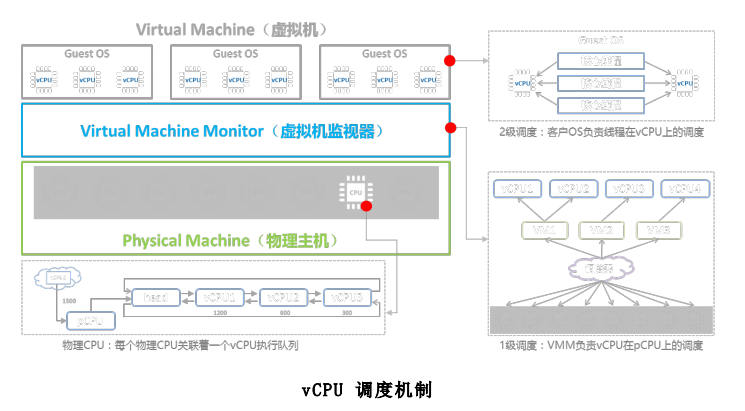
VMM (Virtual Machine Monitor)对物理资源的虚拟可以划分为三个部分:CPU 虚拟化、内存虚拟化和 I/O 设备虚拟化,其中以 CPU 的虚拟化最为关键。
经典的虚拟化方法:现代计算机体系结构一般至少有两个特权级(即用户态和核心态,x86 有四个特权级 Ring0~ Ring3)用来分隔系统软件和应用软件。那些只能在处理器的最高特权级(内核态)执行的指令称之为特权指令,一般可读写系统关键资源的指令(即敏感指令)决大多数都是特权指令(X86 存在若干敏感指令是非特权指令的情况)。如果执行特权指令时处理器的状态不在内核态,通常会引发一个异常而交由系统软件来处理这个非法访问(陷入)。
经典的虚拟化方法就是使用“特权解除”和“陷入-模拟”的方式,即将 GuestOS 运行在非特权级,而将 VMM 运行于最高特权级(完全控制系统资源)。解除了 GuestOS 的特权级后,Guest OS 的大部分指令仍可以在硬件上直接运行,只有执行到特权指令时,才会陷入到 VMM 模拟执行(陷入-模拟)。“陷入-模拟” 的本质是保证可能影响 VMM 正确运行的指令由 VMM 模拟执行,大部分的非敏感指令还是照常运行。
因为 X86 指令集中有若干条指令是需要被 VMM 捕获的敏感指令,但是却不是特权指令(称为临界指令),因此“特权解除”并不能导致他们发生陷入模拟,执行它们不会发生自动的“陷入”而被 VMM 捕获,从而阻碍了指令的虚拟化,这也称之为X86 的虚拟化漏洞。X86 架构虚拟化的实现方式可分为:
1、X86“全虚拟化”(指所抽象的 VM 具有完全的物理机特性,OS 在其上运行不需要任何修改)Full 派秉承无需修改直接运行的理念,对“运行时监测,捕捉后模拟”的过程进行优化。该派内部之实现又有些差别,其中以 VMWare 为代表的基于二进制翻译 (BT) 的全虚拟化为代表, 其主要思想是在执行时将 VM 上执行的 Guest OS 指令,翻译成 x86 指令集的一个子集,其中的敏感指令被替换成陷入指令。翻译过程与指令执行交叉进行,不含敏感指令的用户态程序可以不经翻译直接执行。
2、X86“半虚拟化”(指需 OS 协助的虚拟化,在其上运行的 OS 需要修改)半虚拟化的基本思想是通过修改 Guest OS 的代码,将含有敏感指令的操作,替换为对VMM 的超调用 Hypercall,类似 OS 的系统调用,将控制权转移到 VMM,该技术因 VMM 项目而广为人知。该技术的优势在于 VM 的性能能接近于物理机,缺点在于需要修改GuestOS(如:Windows 不支持修改)及增加的维护成本,关键修改 Guest OS 会导致操作系统对特定 hypervisor 的依赖性,因此很多虚拟化厂商基于 VMM 开发的虚拟化产品部分已经放弃了 Linux 半虚拟化,而专注基于硬件辅助的全虚拟化开发,来支持未经修改的操作系统。
3、X86“硬件辅助虚拟化”:其基本思想就是引入新的处理器运行模式和新的指令,使得 VMM 和 Guest OS 运行于不同的模式下,Guest OS 运行于受控模式,原来的一些敏感指令在受控模式下全部会陷入 VMM,这样就解决了部分非特权的敏感指令的“陷入-模拟”难题,而且模式切换时上下文的保存恢复由硬件来完成,这样就大大ᨀ高了“陷入-模拟”时上下文切换的效率。
Intel VT-x 硬件辅助虚拟化技术为例,该技术增加了在虚拟状态下的两种处理器工作模式:根(Root)操作模式和非根(Non-root)操作模式。VMM 运作在 Root 操作模式下,而 Guest OS 运行在 Non-root 操作模式下。这两个操作模式分别拥有自己的特权级环,VMM 和虚拟机的 Guest OS 分别运行在这两个操作模式的 0 环。这样,既能使 VMM 运行在 0 环,也能使 Guest OS 运行在 0 环,避免了修改 Guest OS。Root 操作模式和 Non-root 操作模式的切换是通过新增的 CPU 指令(如:VMXON、VMXOFF )来完成。
硬件辅助虚拟化技术消除了操作系统的 ring 转换问题,降低了虚拟化门槛,支持任何操作系统的虚拟化而无须修改 OS 内核,得到了虚拟化软件厂商的支持。硬件辅助虚拟化技术已经逐渐消除软件虚拟化技术之间的差别,并成为未来的发展趋势。
对虚拟机来说,不直接感知物理 CPU,虚拟机的计算单元通过 vCPU 对象来呈现。虚拟机只看到 VMM 呈现给它的 vCPU。在 VMM 中,每个 vCPU 对应一个 VMCS(Virtual-MachineControl Structure)结构,当 vcpu 被从物理 CPU 上切换下来的时候,其运行上下文会被保存在其对应的 VMCS 结构中;当 vcpu 被切换到 pcpu 上运行时,其运行上下文会从对应的 VMCS 结构中导入到物理 CPU 上。通过这种方式,实现各 vCPU 之间的独立运行。
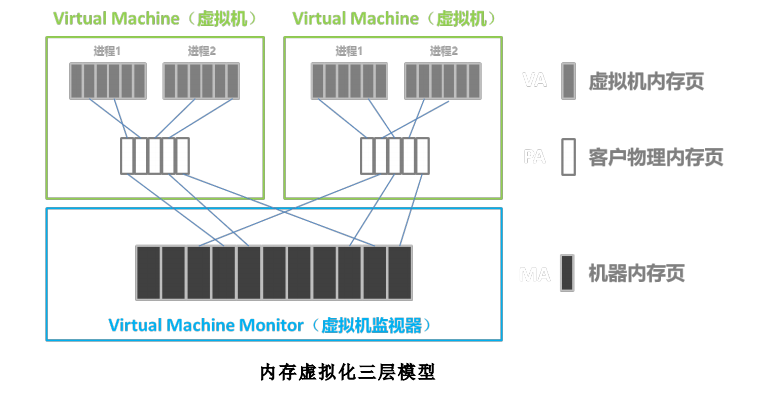
因为 VMM (Virtual Machine Monitor) 掌控所有系统资源,因此 VMM 握有整个内存资源,其负责页式内存管理,维护虚拟地址到机器地址的映射关系。因 Guest OS 本身亦有页式内存管理机制,则有 VMM 的整个系统就比正常系统多了一层映射:
A. 虚拟地址(VA),指 Guest OS ᨀ供给其应用程序使用的线性地址空间;
B. 物理地址(PA),经 VMM 抽象的、虚拟机看到的伪物理地址;
C. 机器地址(MA),真实的机器地址,即地址总线上出现的地址信号;
映射关系如下:Guest OS: PA = f(VA)、VMM: MA = g(PA)VMM 维护一套页表,负责 PA 到 MA 的映射。Guest OS 维护一套页表,负责 VA 到 PA 的映射。实际运行时,用户程序访问 VA1,经 Guest OS 的页表转换得到 PA1,再由 VMM 介入,使用 VMM 的页表将 PA1 转换为 MA1。
普通 MMU 只能完成一次虚拟地址到物理地址的映射,在虚拟机环境下,经过 MMU 转换所得到的“物理地址”并不是真正的机器地址。若需得到真正的机器地址,必须由 VMM 介入,再经过一次映射才能得到总线上使用的机器地址。如果虚拟机的每个内存访问都需要 VMM 介入,并由软件模拟地址转换的效率是很低下的,几乎不具有实际可用性,为实现虚拟地址到机器地址的高效转换,现普遍采用的思想是:由 VMM 根据映射 f 和 g 生成复合的映射 fg,并直接将这个映射关系写入 MMU。当前采用的页表虚拟化方法主要是 MMU 类虚拟化(MMU Paravirtualization)和影子页表,后者已被内存的硬件辅助虚拟化技术所替代。
内存的硬件辅助虚拟化技术是用于替代虚拟化技术中软件实现的“影子页表”的一种硬件辅助虚拟化技术,其基本原理是:GVA(客户操作系统的虚拟地址)-> GPA(客户操作系统的物理地址)-> HPA(宿主操作系统的物理地址)两次地址转换都由CPU 硬件自动完成(软件实现内存开销大、性能差)。
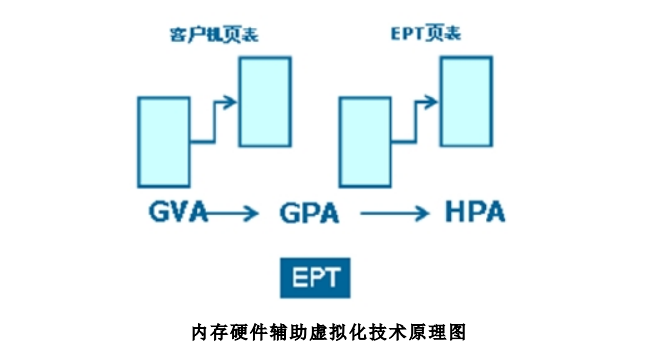
以VT-x 技术的页表扩充技术Extended PageTable(EPT)为例,首先 VMM 预先把客户机物理地址转换到机器地址的 EPT 页表设置到 CPU 中;其次客户机修改客户机页表无需 VMM 干预;最后,地址转换时,CPU 自动查找两张页表完成客户机虚拟地址到机器地址的转换。使用内存的硬件辅助虚拟化技术,客户机运行过程中无需 VMM 干预,去除了大量软件开销,内存访问性能接近物理机。
VMM 通过 I/O 虚拟化来复用有限的外设资源,其通过截获 Guest OS 对 I/O 设备的访问请求,然后通过软件模拟真实的硬件,目前 I/O 设备的虚拟化方式主要有三种:设备接口完全模拟、前端/后端模拟、直接划分。
即软件精确模拟与物理设备完全一样的接口,Guest OS 驱动无须修改就能驱动这个虚拟设备。优点是没有额外的硬件开销,可重用现有驱动程序;缺点在于为完成一次操作要涉及到多个寄存器的操作,使得 VMM 要截获每个寄存器访问并进行相应的模拟,这就导致多次上下文切换;由于是软件模拟,性能较低。
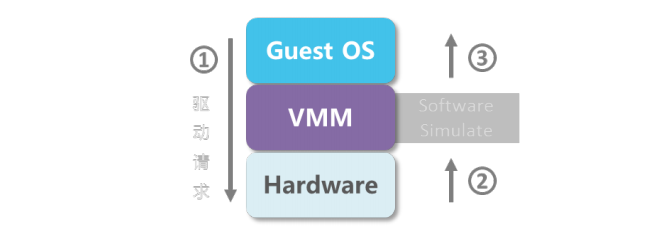
VMM提供一个简化的驱动程序(后端, Back-End),Guest OS中的驱动程序为前端(Front-End, FE),前端驱动将来自其他模块的请求通过与 Guest OS 间的特殊通信机制直接发送给 Guest OS 的后端驱动,后端驱动在处理完请求后再发回通知给前端,VMM 即采用该方法。
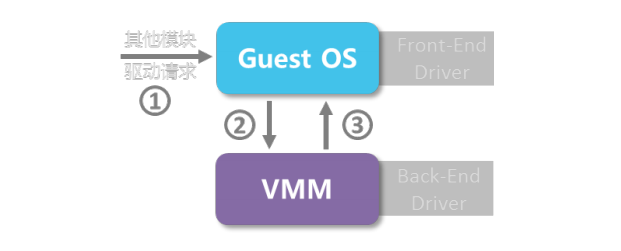
即直接将物理设备分配给某个 Guest OS,由 Guest OS 直接访问 I/O 设备(不经 VMM),目前与此相关的技术有 IOMMU(Intel VT-d, PCI-SIG 之 SR-IOV 等),旨在建立高效的 I/O 虚拟化直通道。
下载链接:
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
