
使用 Python 和 OpenCV 构建 SET 求解器
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

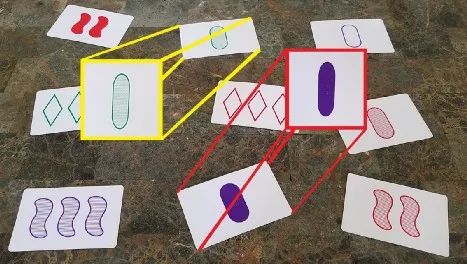
小伙伴们玩过 SET 吗?SET 是一种游戏,玩家在指定的时间竞相识别出十二张独特纸牌中的三张纸牌(或 SET)的模式。每张 SET 卡都有四个属性:形状、阴影/填充、颜色和计数。下面是一个带有一些卡片描述的十二张卡片布局示例。

请注意,卡片的四个属性中的每一个都可以通过三个变体之一来表达。
因为没有两张牌是重复的,所以一副套牌包含 3⁴ = 81 张牌(每个属性 3 个变体,4 个属性)。一个有效的 SET 由三张卡片组成,对于四个属性中的每一个,要么全部共享相同的变量,要么都具有不同的变量。为了直观地演示,以下是三个有效 SET 示例:



构建一个 SET 求解器:一个计算机程序,该程序获取 SET 卡的图像并返回所有有效的 SET,我们使用 OpenCV(一个开源计算机视觉库)和 Python。为了时自己熟悉,我们可以浏览图书馆的文档并和观看一系列教程。此外,我们还可以阅读一些类似项目的博客文章和 GitHub 存储库。¹ 我们将项目分解为四项任务:
在输入图像中定位卡片 (CardExtractor.py)
识别每张卡片的唯一属性 (Card.py)
评估已识别的 SET 卡 (SetEvaluator.py)
向用户显示 SET (set_utils.display_sets)
我们为前三个任务中的每一个创建了一个专用类,我们可以在下面的类型提示 main 方法中看到。
import cv2# main method takes path to input image of cards and displays SETsdef main():input_image = 'PATH_TO_IMAGE'original_image = cv2.imread(input_image)extractor: CardExtractor = CardExtractor(original_image)cards: List[Card] = extractor.get_cards()evaluator: SetEvaluator = SetEvaluator(cards)sets: List[List[Card]] = evaluator.get_sets()original_image)cv2.destroyAllWindows()
1. 图像预处理
在导入OpenCV和Numpy(开源数组和矩阵操作库)之后,定位卡片的第一步是应用图像预处理技术来突出卡片的边界。具体来说,这种方法涉及将图像转换为灰度,应用高斯模糊并对图像进行阈值处理。简要地:
转换为灰度可通过仅保留每个像素的强度或亮度(RGB 色彩通道的加权总和)来消除图像的着色。
对图像应用高斯模糊会将每个像素的强度值转换为该像素邻域的加权平均值,权重由以当前像素为中心的高斯分布确定。这样可以消除噪声并 “平滑” 图像。经过实验后,我们决定高斯核大小设定 (3,3) 。
阈值化将灰度图像转换为二值图像——一种新矩阵,其中每个像素具有两个值(通常是黑色或白色)之一。为此,使用恒定值阈值来分割像素。因为我们预计输入图像具有不同的光照条件,所以我们使用 cv2.THRESH_OTSU 标志来估计运行时的最佳阈值常数。
OpenCV 使这三个步骤变得很简单:
# Convert input image to greyscale, blurs, and thresholds using Otsu's binarizationdef preprocess_image(image):greyscale_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)blurred_image = cv2.GaussianBlur(greyscale_image, (3, 3), 0)thresh = cv2.threshold(blurred_image, 0, 255, cv2.THRESH_OTSU)return thresh



2. 查找卡片轮廓
接下来,我使用 OpenCV 的 findContours() 和 approxPolyDP() 方法来定位卡片。利用图像的二进制值属性,findContours() 方法可以找到 “ 连接所有具有相同颜色或强度的连续点(沿边界)的曲线。”² 第一步是对预处理图像使用以下函数调用:
contours, hierarchy = cv2.findContours(processed_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)cv2.RETR_TREE 标志检索所有找到的轮廓以及描述给定轮廓嵌套或嵌入其他轮廓的级别的层次结构。cv2.CHAIN_APPROX_SIMPLE 标志仅通过编码轮廓端点来压缩轮廓信息。在进行了一些错误检查以排除非卡片之后,我们使用approxPolyDP ()方法使用轮廓端点来估计多边形曲线。以下是一些已识别的卡片轮廓,它们叠加在原始图像上。

轮廓以绘制为红色
3. 重构卡片图像
识别轮廓后,必须重构卡片的边界以标准化原始图像中卡片的角度和方向。这可以通过仿射扭曲变换来完成,仿射扭曲变换是一种几何变换,可以保留图像上线条之间的共线点和平行度。我们可以在示例图像中看到下面的代码片段。
# Performs an affine transformation and crop to a set of card verticesdef refactor_card(self, bounding_box, width, height):bounding_box = cv2.UMat(np.array(bounding_box, dtype=np.float32))frame = [[449, 449], [0, 449], [0, 0], [449, 0]]if height > width:frame = [[0, 0], [0, 449], [449, 449], [449, 0]]affine_frame = np.array(frame, np.float32)affine_transform = cv2.getPerspectiveTransform(bounding_box, affine_frame)refactored_card = cv2.warpPerspective(self.original_image, affine_transform, (450, 450))cropped_card = refactored_card[15:435, 15:435]return cropped_card
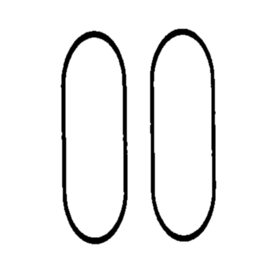
然后我们将每个重构的卡片图像及其坐标作为参数传递给 Card 类构造函数。这是构造函数的简化版本:
class Card:def __init__(self, card_image, original_coord):self.image = card_imageself.processed_image = self.process_card(card_image)self.processed_contours = self.processed_contours()self.original_coord = reorient_coordinates(original_coord) #standardize coordinate orientationself.count = self.get_count()self.shape = self.get_shape()self.shade = self.get_shade()self.color = self.get_color()
作为第一步,一种名为process_card的静态方法应用了上述相同的预处理技术,以及对重构后的卡片图像进行二进制膨胀和腐蚀。简要说明和示例:
膨胀是其中像素 P 的值变成像素 P 的 “邻域” 中最大像素的值的操作。腐蚀则相反:像素 P 的值变成像素 P 的 “邻域” 中最小像素的值。
该邻域的大小和形状(或“内核”)可以作为输入传递给 OpenCV(默认为 3x3 方阵)。
对于二值图像,腐蚀和膨胀的组合(也称为打开和关闭)用于通过消除落在相关像素 “范围” 之外的任何像素来去除噪声。在下面的例子中可以看到这一点。
#Close card image (dilate then erode)dilated_card = cv2.dilate(binary_card, kernel=(x,x), iterations=y)eroded_card = cv2.erode(dilated_card, kernel=(x,x), iterations=y)



带有噪声的卡片 → 预处理后的图像 → 膨胀+腐蚀的“闭合”图像,注意噪声消除。
我获取了生成的图像,并使用不同的方法从处理后的卡片中提取每个属性——形状、阴影、颜色和计数。我使用了 Github 上@piratefsh 的 set-solver 存储库中的代码来识别卡片颜色和阴影,并设计了我自己的形状和计数方法。
形状
为了识别卡片上显示的符号的形状,我们使用卡片最大轮廓的面积。这种方法假设最大的轮廓是卡片上的一个符号——这一假设在排除非极端照明的情况下几乎总是正确的。
阴影
识别卡片阴影或 “填充” 的方法使用卡片最大轮廓内的像素密度。
颜色
识别卡片颜色的方法包括评估三个颜色通道 (RGB) 的值并比较它们的比率。
计数
为了识别卡片上的符号数量,我们首先找到了四个最大的轮廓。尽管实际上计数从未超过三个,但我们选择了四个,然后进行了错误检查以排除非符号。在使用 cv2.drawContours 填充轮廓后,为了避免重复计算后,我们需要检查一下轮廓区域的值以及层次结构(以确保轮廓没有嵌入到另一个轮廓中)。

另外:识别卡片属性的另一种方法可能是将有监督的 ML 分类模型应用于卡片图像。根据一些快速研究,似乎可以使用 Scikit 的 SVM 或 KNN 和 Keras ImageDataGenerator 来增强数据集。
然后每个变体都被编码为一个整数,这样任何卡片都可以用四个整数的数组表示。例如,带有两个空菱形符号的紫色卡片可以表示为 [1,1,3,2]。
现在卡片表示为数组,让我们评估一下 SET!
为了检查已识别卡片中的集合,将卡片对象数组传递给 SetEvaluator 类。
方法一:所有可能的组合
至少有两种方法可以评估卡的数组表示形式是否为有效集。第一种方法需要评估所有可能的三张牌组合。例如,当显示 12 张牌时,有 ₁₂C₃ =(12!)/(9!)(3!) = 660 种可能的三张牌组合。使用 Python 的 itertools 模块,可以按如下方式计算:
import itertoolsSET_combinations = list(combinations(cards: List[Card], 3))
请记住,对于每个属性,SET 中的三张卡片的变化必须相同或不同。如果三个卡片阵列彼此堆叠,则给定列/属性中的所有值必须显示全部相同的值或全部不同的值。
可以通过对该列中的所有值求和来检查此特性。如果所有三张卡片对于该属性具有相同的值,则根据定义,所得总和可被三整除。类似地,如果所有三个值都不同(即等于 1、2 和 3 的排列),则所得的总和 6 也可以被 3 整除。如果没有余数,这些值的任何其他总和都不能被3整除。
我们将这种方法应用于所有 660 种组合,保存了有效的组合。快看,我们有了我们的 SET!下面是一个简单演示此方法的代码片段(在可能的情况下不使用生成器尽早返回 False):
# Takes 3 card objects and returns Boolean: True if SET, False if not SETdef is_set(trio):count_sum = sum([card.count for card in trio])shape_sum = sum([card.shape for card in trio])shade_sum = sum([card.shade for card in trio])color_sum = sum([card.color for card in trio])set_values_mod3 = [count_sum % 3, shape_sum % 3, shade_sum % 3, color_sum % 3]return set_values_mod3 == [0, 0, 0, 0]
但是有一个更好的方法......
方法 2:验证 SET Key
请注意,对于一副牌中的任意两张牌,只有一张牌(并且只有一张牌)可以完成 SET,我们称这第三张卡为SET Key。方法 1 的一种更有效的替代方法是迭代地选择两张卡片,计算它们的 SET 密钥,并检查该密钥是否出现在剩余的卡片中。在 Python 中检查 Set() 结构的成员资格的平均时间复杂度为 O (1)。
这将算法的时间复杂度降低到 O( n²),因为它减少了需要评估的组合数量。考虑到只有少量 n 次输入的事实(在游戏中有12 张牌在场的 SET 有 96.77% 的机会,15 张牌有 99.96% 的机会,16 张牌有 99.9996% 的机会⁴),效率并不是最重要的。使用第一种方法,我在我的中端笔记本电脑上对程序计时,发现它在我的测试输入上平均运行 1.156 秒(渲染最终图像)和 1.089 秒(不渲染)。在一个案例中,程序在 1.146 秒内识别出七个独立的集合。
向用户显示 SETS
最后,我们跟随 piratefsh 和 Nicolas Hahn 的引导,通过在原始图像上用独特的颜色圈出各自 SET 的卡片,向用户展示 SET。我们将每张卡片的原始坐标列表存储为一个实例变量,该变量用于绘制彩色轮廓。
# Takes List[List[Card]] and original image. Draws colored bounding boxes around sets.def display_sets(sets, image, wait_key=True):for index, set_ in enumerate(sets):set_card_boxes = set_outline_colors.pop()for card in set_:card.boundary_count += 1expanded_coordinates = np.array(expand_coordinates(card.original_coord, card.boundary_count), dtype=np.int64)cv2.drawContours(image, [expanded_coordinates], 0, set_card_boxes, 20)
属于多个 SET 的卡片需要多个轮廓。为了避免在彼此之上绘制轮廓,expanded_coordinates() 方法根据卡片出现的 SET 数量迭代扩展卡片的轮廓。这是使用 cv2.imshow() 的操作结果:



就是这样——一个使用 Python 和 OpenCV 的 SET 求解器!这个项目很好地介绍了 OpenCV 和计算机视觉基础知识。特别是,我们了解到:
图像处理、降噪和标准化技术,如高斯模糊、仿射变换和形态学运算。
Otsu 的自动二元阈值方法。
轮廓和 Canny 边缘检测。
OpenCV 库及其一些用途。
Piratefsh’s set-solver on Github was particularly informative. After finding that her approach to color identification very accurate, I ended up simply copying the method. Arnab Nandi’s card game identification project was also a useful starting point, and Nicolas Hahn’s set-solver also proved useful. Thank you Sherr, Arnab, and Nicolas, if you are reading this!
Here’s a basic explanation of contours and how they work in OpenCV. I initially implement the program with Canny Edge Detection, but subsequently removed it because it did not improve card identification accuracy for test cases.
You can find a more detailed description of morphological transformations on the OpenCV site here.
Some interesting probabilities related to the game SET.
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~