
【工程化】前端工程实践之数据埋点分析系统(一)
本文首发于政采云前端团队博客:前端工程实践之数据埋点分析系统(一)
https://www.zoo.team/article/data-analysis-one

背景
随着公司业务的不断增长,平台业务的不断增加,场景复杂度也对应的有所增加。这对平台产品的用户体验,商业场景的深化运营,及过程中对平台用户的使用便捷性,都带来了不小的影响和挑战。为更精准的触达用户痛点,定位转化低点,提升业务赋能,基于数据分析的优化策略势在必行。
政采云前端团队(ZooTeam),从去年年底开始,主动主导推进公司业务层面的 Web 数据埋点及分析量化的能力建设(内部产品化命名“浑仪系统”)。希望基于我们过去一段时间的事件和经验,能为正有意实践此方向从 0 到 1 建设的小伙伴们,提供一些思路和帮助。
系统概览
数据埋点分析系统都做了些什么?采集了哪些数据?这些数据我们将如何运用和分析?最终又将如何展示呢?
首先我们看下系统结构。整个系统由以下 4 个部分组成,期望能提供一套完整的用户行为分析的解决方案:
埋点采集 JSSDK:收集用户行为数据,并进行上报; 数据处理服务:接收上报数据并存储;筛取所需数据,进行数据处理并透出; 数据可视化平台:汇总展示详细数据,支持自定义,打通业务; Chrome插件工具:在页面上直观展示坑位数据,提供场景更友好的数据可视化服务;
其基本协作流程是,用户进入平台任意一个已埋点的 Web 页面,进行的一系列(进入、点击、滚屏等)操作,都会由 JSSDK 进行分类并将数据上报至服务端进行存储,再由站点 / 插件发起查询,服务端将处理后的数据返回,再通过数据可视化平台进行透出展示。
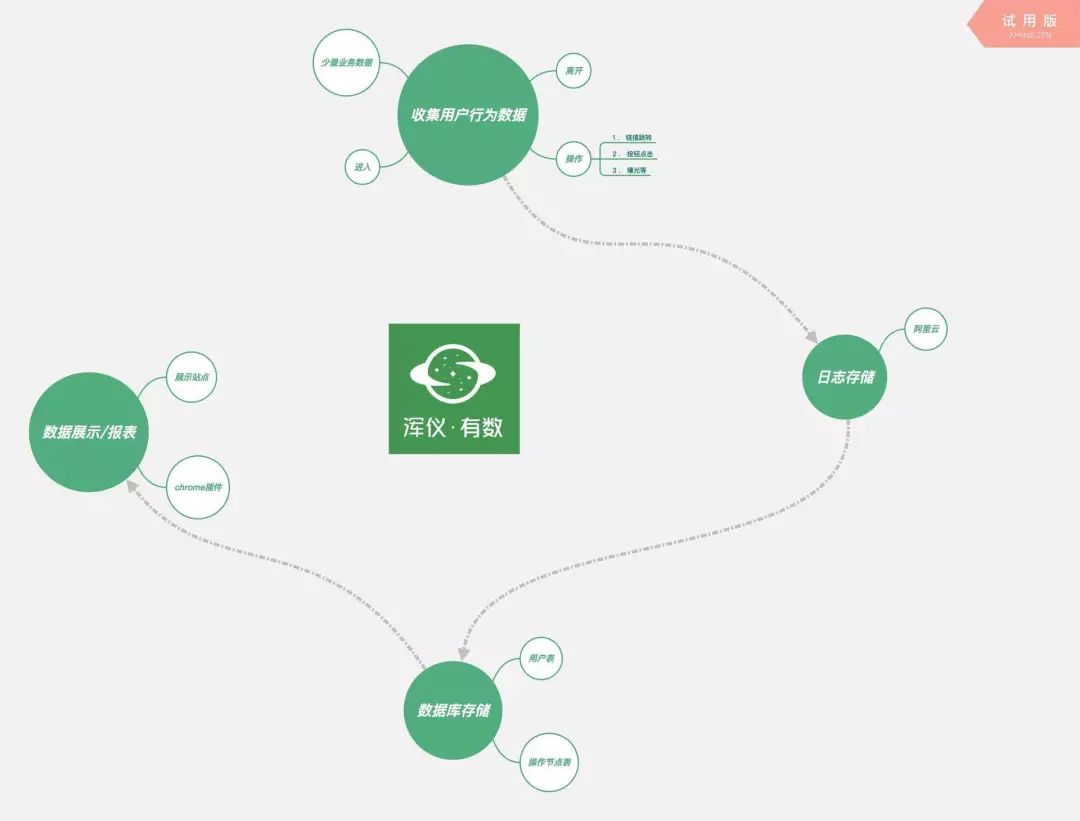
数据采集
数据采集一般分为以下三种:
无埋点(全埋点):零埋点成本,抓取用户行为全量数据,任何操作行为都会被上传。数据量大,“噪音”多; 可视化埋点:在页面中操作,选择埋点位置/模块,非开发人员也可以进行埋点; 侵入式埋点:埋点时需要将数据采集代码写入业务代码中,埋点成本较高,但准确度也更高;
由于对数据的准确度要求较高,同时希望前期只投入较少的开发资源就可以进行快速试错,并为了满足重点的用户行为数据的采集需求,因此,我们优先采用代码侵入式埋点方案。
//自动发送埋点方式,举例:
<button data-utm-click="${did}" data-utm-data="${业务数据}">
//手动发送埋点方式,举例:
const utmCnt = g_UTM.batchSend('触发类型(click/browse)等',[{
utmCD:['区块信息','位置信息'],
bdata:{key:'其他业务数据'}
},{
utmCD:['001','008'],
bdata:{key:'value'}
}
]);
围绕“事件“我们采集了:事件的类型、发生时间、页面位置等信息,组成事件唯一标识。
{
bdata: {}, //业务数据
createTime: "1571038815128", // 创建时间
evt: "browse", // 事件类型
ipAddr: 122.226.174.195, //ip地址
logType: 2, // 触发类型
lver: 1.1.0, //版本
mx: 0, // 页面位置坐标x
my: 0, // 页面位置坐标y
os: "Windows/7", // 操作系统
pre: "https://www.zcygov.cn/", // 来源地址
scr: "1920x1360", // 屏幕分辨率
url: "https://www.zcygov.cn/", // 页面地址
userId: "001", // 用户标识
utmCnt: "a0004.2ef5001f.0001.0001.d814bf60ee5511e99397b37fe9083257", // 触发位置
utmUrl: "a0004.2ef5001f.0001.0001", // 来源位置
uuid: "d7fd8de0-ee55-11e9-9397-b37fe9083257", // 浏览器唯一标识
}
上述一些收集的字段,会在下面案例中使用到。

数据展示
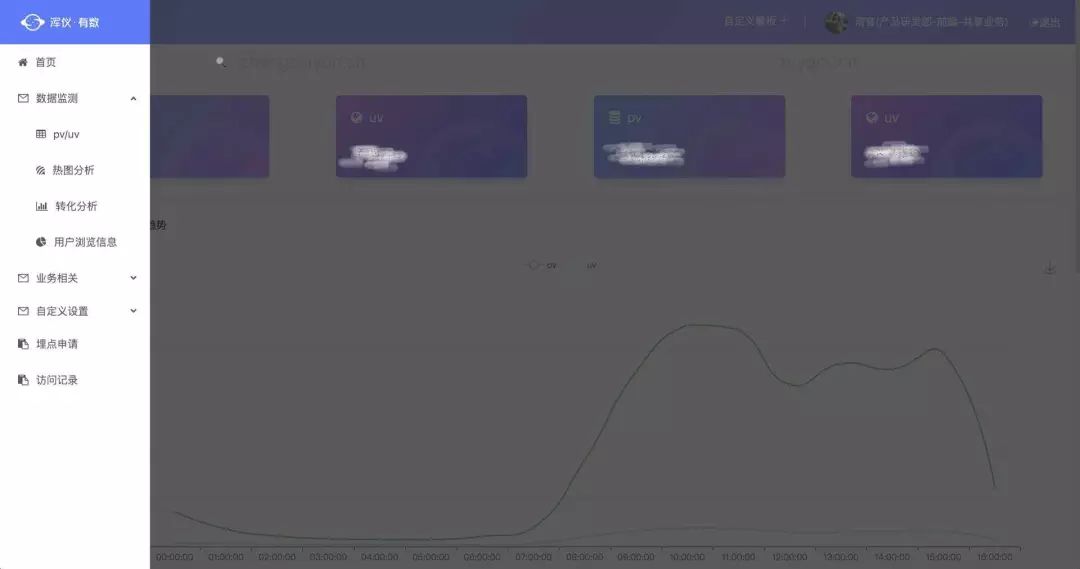
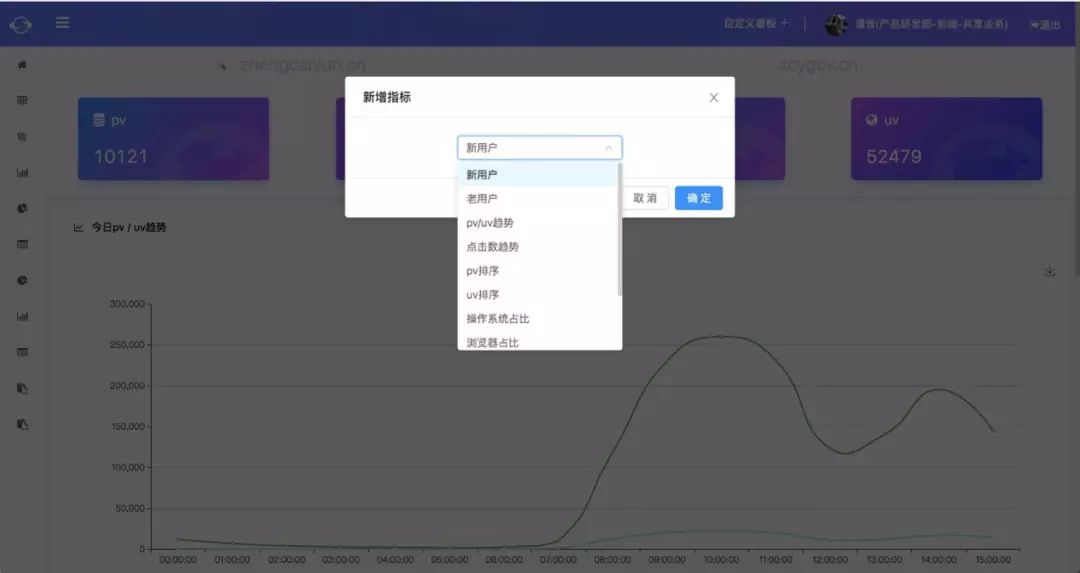
PV/UV 排序或趋势(PV:PageView,页面浏览次数,用户每打开一次记录一次,多次打开同一页面将累计多次;UV:UserView,浏览页面人数;下文中将直接用PV/UV;) 全站的PV/UV单日趋势图:分时段查看访问量的高峰和低谷; PV/UV排序:查看Top页面的PV/UV 按页面、时间区间查询PV/UV 漏斗分析:按流程排序每个阶段的人数,计算出转化率; 路径分析:查询各个页面的来源和去向; 热图分析 点击热图:按钮及链接点击的热图; 滚屏热图(即将上线):用户页面滚屏触达率; 用户画像(即将上线):针对重点用户的回访次数、浏览路径、用户身份、所在地、操作系统、浏览器等详细信息查询; 自定义看板:可选择首页看板的展示项;
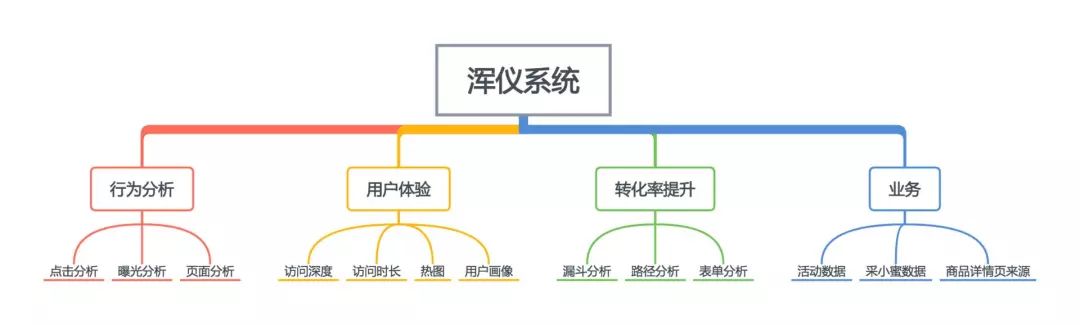
赋能业务
采集和分析哪些数据才是对业务有价值的,我们参考了许多业界成熟的用户行为分析解决方案,包括:
GrowingIO 神策数据 数极客
| 关键功能点 | 数极客 | 神策数据 | GrowingIO | 自研系统 |
|---|---|---|---|---|
| 表单分析 | 支持 | 支持 | 支持 | 不支持 |
| 页面分析 | 支持 | 支持 | 支持 | 支持 |
| 路径分析 | 支持 | 支持 | 支持 | 支持 |
| 漏斗分析 | 支持 | 支持 | 支持 | 支持 |
| 事件分析 | 支持 | 支持 | 支持 | 支持 |
| 事件分布分析 | 支持 | 支持 | 支持 | 支持 |
| 用户分群 | 支持 | 支持 | 支持 | 支持 |
| 行为预测 | 不支持 | 支持 | 不支持 | 不支持 |
| 用户行为序列 | 不支持 | 支持 | 不支持 | 不支持 |
| 热图 | 支持 | 支持 | 支持 | 支持 |
| 视频回放 | 支持 | 不支持 | 不支持 | 不支持 |
例如:常见的注册表单的转化,即 10 个用户进入注册页面但最后只有 7 个用户成功注册,这个功能可以有效发掘剩余 3 个注册失败的用户流失的点,找到他们是在填写哪个表单项前离开页面或是找到重填率最高的表单项进行优化。用户行为序列是从单一用户的角度去查看在我们站点上的行为轨迹,从而去分析重点用户的行为喜好。
基于公司当前的业务发展,除了上述基础功能模块外,系统中还会对应考虑一些定制化的业务能力模块。依据目前系统的能力类型,可分为用户行为分析、链路转化分析、用户体验分析等:
搜索流程埋点案例
那么在一个页面或者一个流程中我们可以采集到哪些有价值的数据呢?下面我们就以一个简单的流程为例来说明。
这里流程可以分为三步,首先,用户进入政采云电子卖场首页,并在搜索框中输入想要搜索的关键词,其次,点击搜索按钮后进入搜索结果页,最后,在结果页中找到了目标商品并点击进去了商品详情页查看。这是在一个电商平台中用户操作行为中较为常见的一种流程,也是一个关键流程。
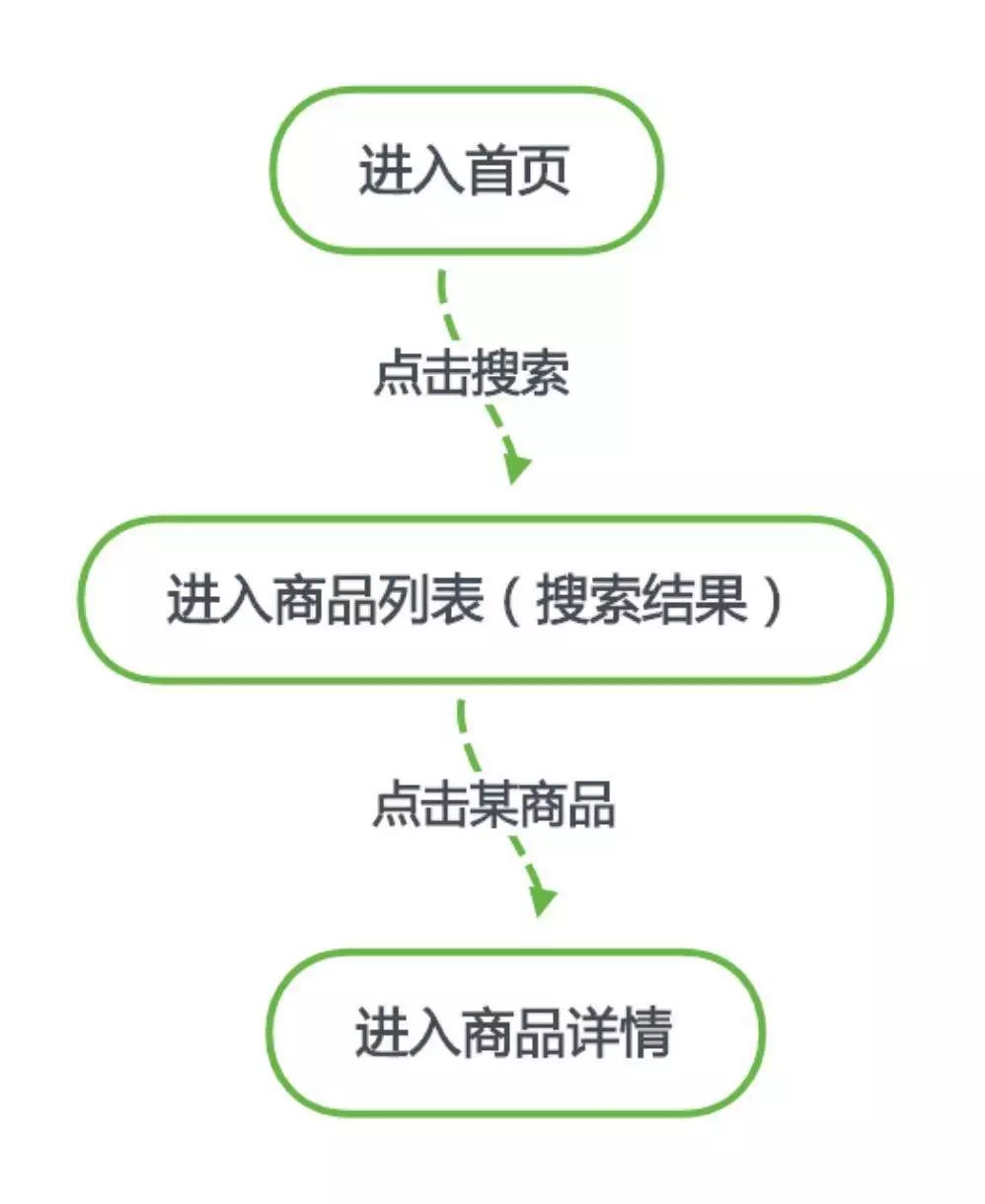
我们在上述的三个页面中会采集的数据有以下三种:
页面进入/离开自动埋点 按钮点击埋点 链接点击埋点
如上图所示,通过 Chrome 插件工具,可以在页面上直观的展示链接和按钮的点击次数(数据已脱敏)。
利用上面说到的三项埋点,我们在单个页面中可以得到用户行为相关的四种数据。
PV:通过计算日志中所有进入页面日志条数的总和我们可以得到 pv UV:以唯一 uuid 将 pv 进行过滤后可以得到 uv ; 按钮点击数:直接通过统计按钮点击事件上报的日志条数可以得到按钮的点击量; 链接点击数:与按钮点击有所不同,按钮点击是通过单独发送的点击事件上报来进行统计,而链接点击往往导致的是一次页面跳转,此处即为从电子卖场首页离开进入了搜索结果页,此时我们所统计的就是搜索结果页的页面进入事件中的 utmUrl(即来源按钮的唯一识别码)值,判断出该次搜索结果页的进入是来源于首页常见搜索关键词的点击,从而统计出该位置的的链接点击量。

再对这些数据进行加工,我们进一步可以得到:停留时长、转化率、热力图;
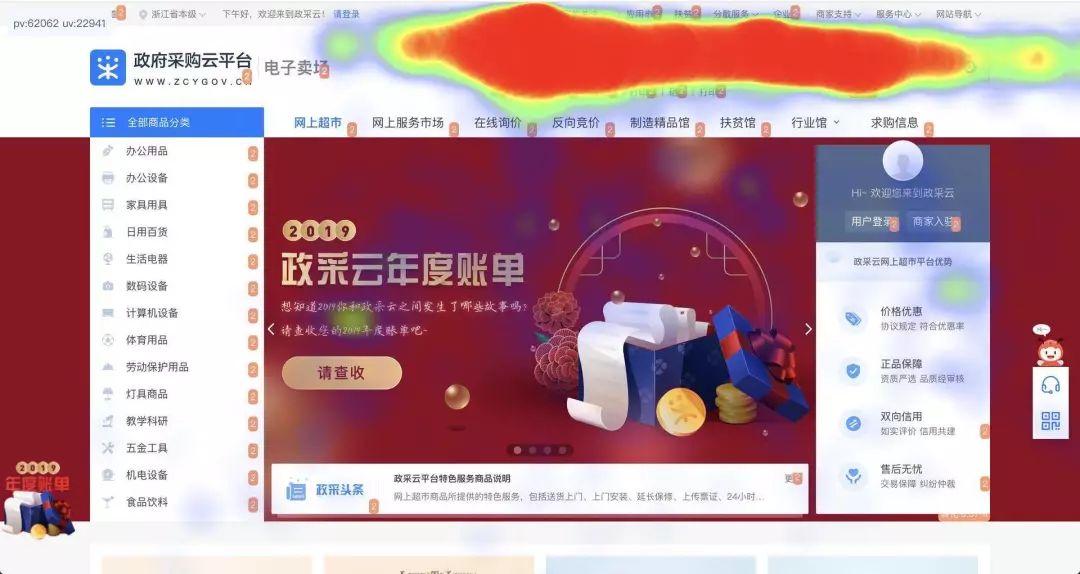
热力图:用于反映图中点的密集程度,在此处我们利用点击的坐标(点击的 x,y 坐标位置,再根据屏幕分辨率做一致性的换算)组合成点击热图,如下图所示(数据已脱敏)。
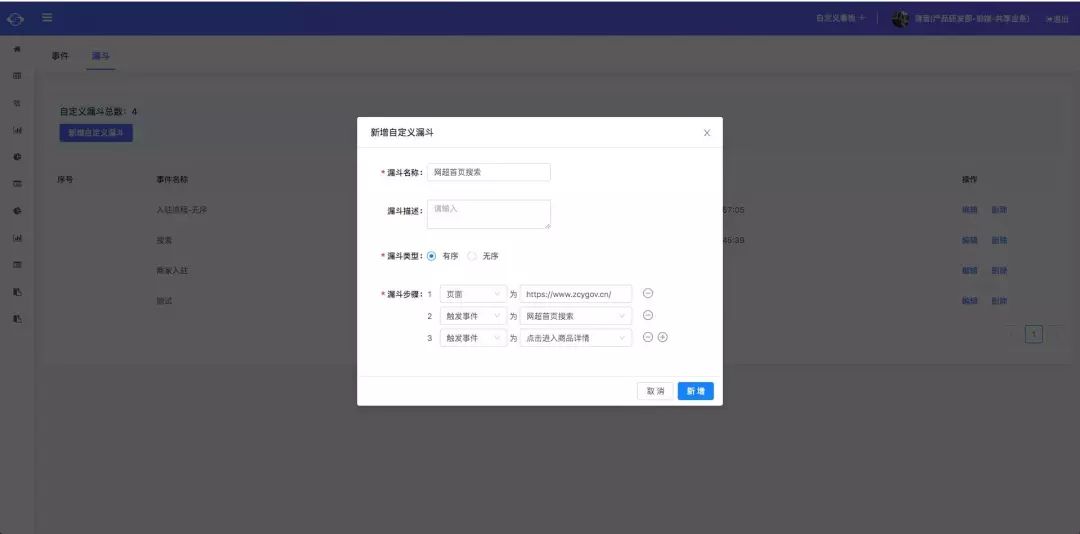
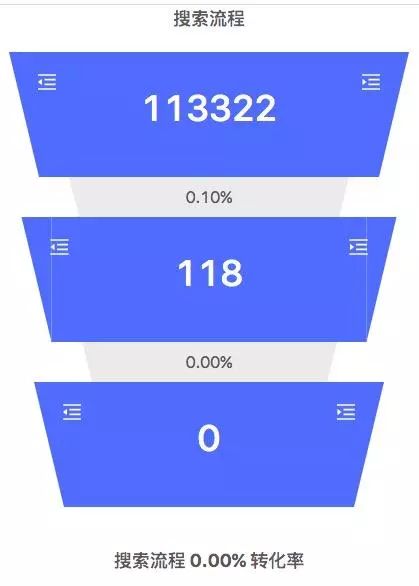
漏斗分析:由一个元事件/虚拟事件加一个或者多个筛选条件组成,表示一个转化流程中的一个关键性的步骤;在我们平台上创建一个漏斗主要有以下几步:

如下图所示,在这个漏斗中定义了三个事件。
总结
本文只是对通用类型的数据埋点与分析系统做了下初步的能力项介绍,后续我们将针对每个踩过的坑和做过的优化产出一系列的文章,希望各位能给予意见。
《如何高效完整的采集数据》 《埋点数据分析模型设计》 《Chrome 插件之数据可视化》
欢迎关注「前端杂货铺」,一个有温度且致力于前端分享的杂货铺
关注回复「加群」,可加入杂货铺一起交流学习成长