
为了实现零丢包,数据中心网络到底有多拼?
数智时代的最大特点,就是AI人工智能的广泛应用。
进入21世纪以来,移动通信、光通信、云计算、大数据等ICT技术蓬勃发展,推动了企业的数字化转型。数据,变成了企业最核心的资产。
企业将这些数据资产全部存储并运行在数据中心之上。随着数字化的不断深入,数据规模变得越来越庞大。

2025年新增的数据量将达到180ZB
(数据来源:华为GIV)
传统的软件算法,根本无法处理如此海量的数据(更何况,其中95%以上都是语音、视频等非机构化数据)。于是,我们找来了能力更强的帮手,那就是——AI(人工智能)。
AI可以完成海量无效数据的筛选和有用信息的自动重组,从而大幅提升数据价值的挖掘效率,帮助用户更高效地进行决策。
然而,想要利用好这个神器,我们需要三大要素的支持,那就是算法、算力和数据。
AI算法强不强,训练是关键。深度学习的算法训练,离不开海量的样本数据,以及高性能的计算能力。
在存储能力方面,从HDD(机械硬盘)到SSD(高速闪存盘),再到SCM(存储级内存),介质时延降低了100倍以上,可以满足高性能数据实时存取需求。
在计算能力方面,从CPU到GPU,再到专用的AI芯片,处理数据的能力也提升了100倍以上。
那么,这是否意味着数据中心能够完全满足AI规模应用的要求呢?
别急着说是,我们不能忘了一个重要的性能制约因素,那就是——网络通信能力。

事实上,网络通信能力确实拖了存储能力和计算能力的后腿。数据显示,在存储介质和计算处理器演进之后,网络通信时延已经成为了数据中心性能提升的瓶颈。通信时延在整个存储E2E(端到端)时延中占比,已经从10%跃迁到60%以上。
也就是说,宝贵的存储介质有一半以上的时间是在等待通信空闲;而昂贵的处理器,也有一半时间在等待通信同步。
网络通信能力,已经在数据中心形成了木桶效应,变成了木桶的短板。
█ 数据中心通信网络,到底出了什么问题?
上世纪70年代,TCP/IP和以太网技术相继诞生。
它们成本低廉、结构简单,为互联网的早期发展做出了巨大贡献。
但是,随着网络规模的急剧膨胀,传统TCP/IP和以太网技术已经跟不上时代的步伐,它们落后的架构设计,反而制约了互联网的进一步发展。
2010年后,数据中心的业务类型逐渐聚焦为三种,分别是高性能计算业务(HPC),存储业务和一般业务。
这三种业务,对于网络有不同的诉求。比如HPC业务的多节点进程间通信,对于时延要求非常高;而存储业务,对通信可靠性的要求非常高,网络需要实现绝对的0丢包;一般业务的规模巨大,扩展性强,要求网络低成本易扩展。
传统以太网可以适用于一般业务,但是无法应对高性能计算和存储业务。于是,业界发展出了Infiniband(直译为“无限带宽”技术,缩写为IB)网络,应对有低时延要求的网络IPC通信;发展出了FC(Fibre Channel,光纤通道)网络,提供高可靠0丢包的存储网络。

IB专网和FC专网的性能很强,但是价格昂贵,是以太网的数倍。而且,两种专网需要专人运维,会带来更高的维护成本。
是不是有办法,将三种网络的优势进行结合呢?有没有一种网络,可以同时实现高吞吐、低时延和0丢包?
这里,我先卖个关子,不揭晓答案。我们回过头来,看看TCP/IP协议栈的痛点。
传统的TCP/IP协议栈,实在是太老了。它的很多致命问题,都是与生俱来的。比如说它的时延,还有它对CPU的占用。
为了解决问题,专家们提出了一种新型的通信机制——RDMA(Remote Direct Memory Access,远程直接数据存取),用于取代TCP/IP。

RDMA相当于是一个快速通道技术,在数据传输时延和CPU占用率方面远远强于TCP/IP,逐渐成为主流的网络通信协议栈。
RDMA有两类网络承载方案,分别是专用InfiniBand和传统以太网络。

InfiniBand是一种封闭架构,交换机是特定厂家提供的专用产品,采用私有协议,无法兼容现网,加上对运维的要求过于复杂,并不是用户的合适选择。
除了InfiniBand之外,那就只剩下传统以太网了。
那比较尴尬的是,RDMA对丢包率的要求极高。0.1%的丢包率,将导致RDMA吞吐率急剧下降。2%的丢包率,将使得RDMA的吞吐率下降为0。
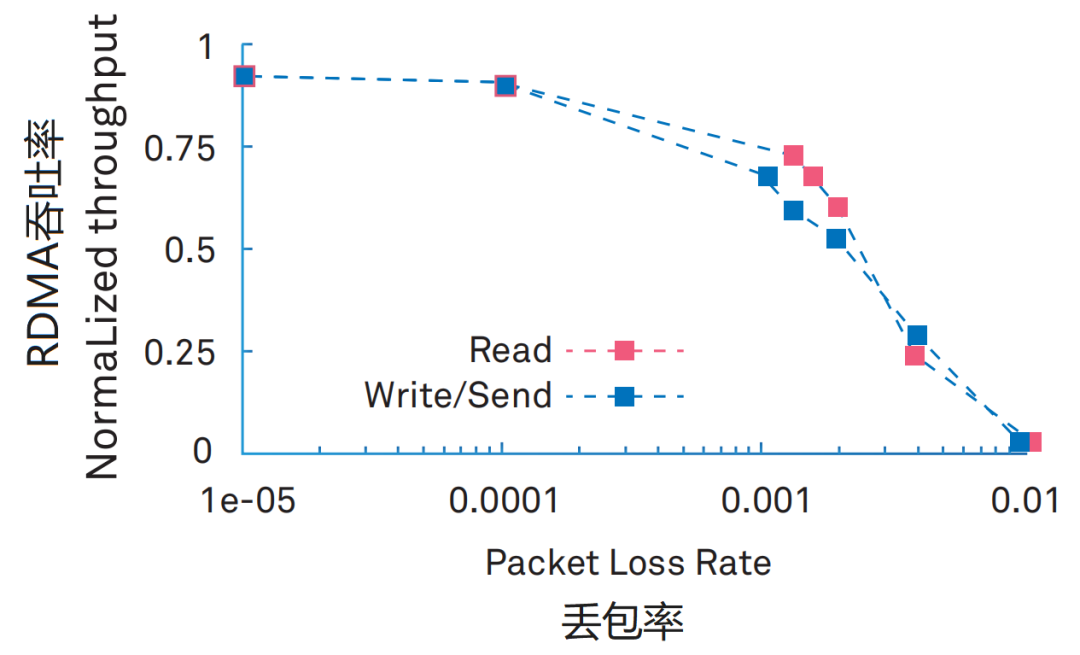
而传统以太网,工作机制是“尽力而为”,丢包是家常便饭。
又回到了前面那个问题:我们究竟有没有0丢包、高吞吐的新型开放以太网,用于支撑低延时RDMA的高效运行呢?
Duang!答案揭晓——
办法当然是有的,那就是来自华为的超融合数据中心网络智能无损技术。
█ 华为的零丢包秘技
华为的智能无损技术到底有何神通,可以解决困扰传统以太网已久的丢包问题?
其实,想要实现零丢包,首先要搞清楚网络为什么会产生丢包。
网络丢包的基本原因其实很简单,就是发生了溢出——网络流量超过了数据中心交换机的处理和缓存能力。
应对溢出,业界通用的做法,就是控制发送端的发送速度,从而避免超过交换机处理能力的拥塞形成。
具体来说,就是在交换机端口设置报文缓存队列,一旦队列长度超过某一个阈值(拥塞水线),对拥塞报文进行拥塞标记,流目的端向源端发送降速信号,即显式拥塞通知ECN(Explicit Congestion Notification)。
源端收到通知,从而降低发送速度,规避拥塞。
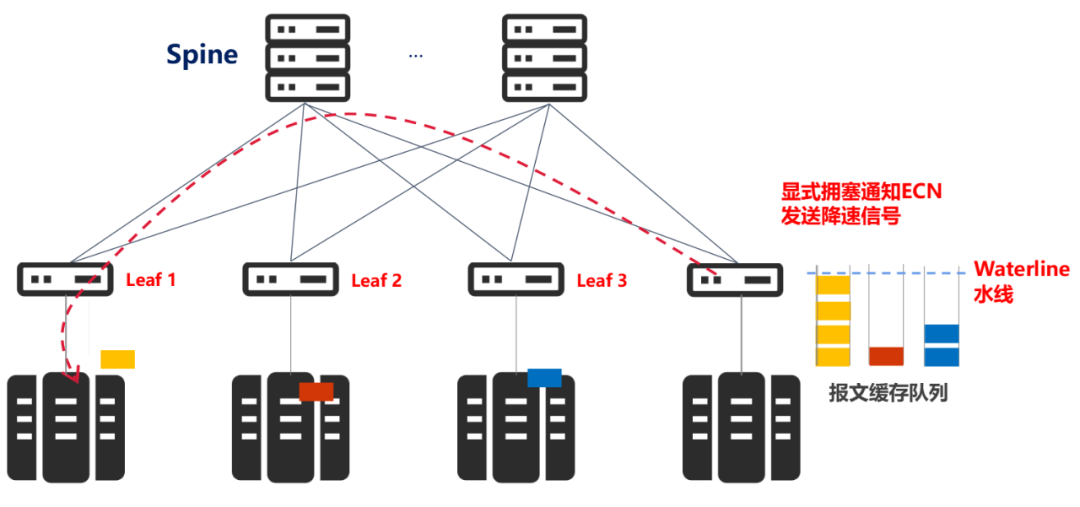
我们可以看出,这个阈值的设置非常关键。它决定了对报文进行拥塞标记的时机,是网络中是否会发生拥塞的决定性因素。
阈值的设置,是一门非常深的学问。
如果设置太保守,就会降速太多,影响系统吞吐能力。如果设置太激进,则无法达到无损的效果。
更关键的是,网络的业务类型是多样且变化的,有时候需要高吞吐,有时候又需要低时延。即便是有经验的专家,好不容易花了几天的时间,设置好了最佳水线位置,结果它又变了,咋整?
于是,华为想到了最适合干这个活的角色,那就是——AI。
早在2012年,华为为了应对未来数据洪水挑战,投入了数十个科学家,启动新一代无损网络的研究。
经过多年的潜心钻研和探索,他们搞出了独具创新的iLossless智能无损算法方案。这是一个通过人工智能实现网络拥塞调度和网络自优化的AI算法。
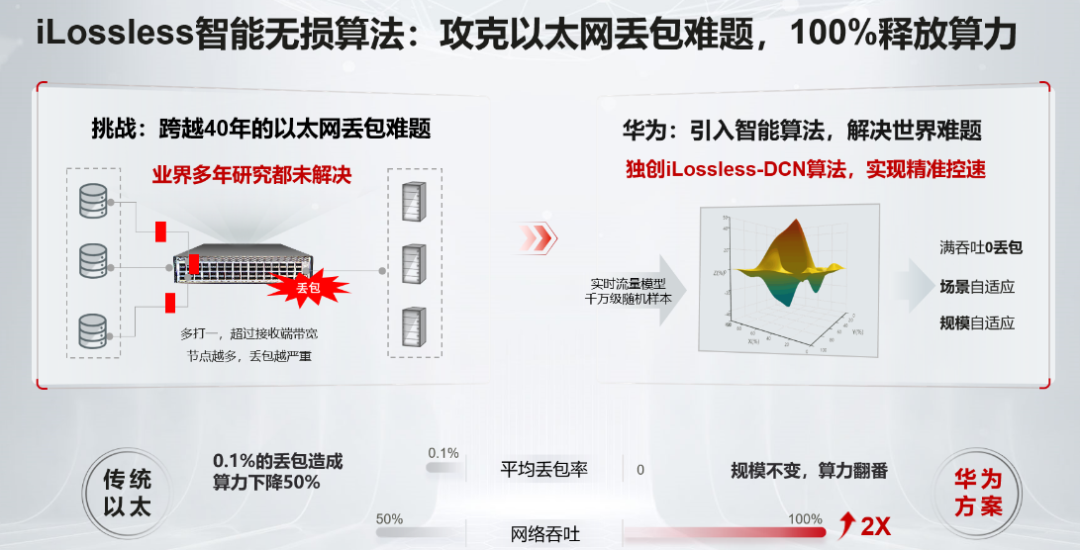
华为iLossless智能无损算法以Automatic ECN为核心,并首次在超高速数据中心交换机引入深度强化学习DRL(Deep Reinforcement Learning)。
对比传统静态阈值配置僵化,无法动态适应网络变化的缺点,Automatic ECN为以太网的流量调度提供了智能预测能力,可以根据当前流量状态精准预测下一刻的拥塞状态,提前做好预留和准备。
基于iLossless智能无损算法,华为发布了超融合数据中心网络CloudFabric 3.0解决方案,引领智能无损进入1.0时代。
2022年,华为超融合数据中心网络继续探索,提出了更强大的智能无损网算一体技术和创新直连拓扑架构,可实现270k大规模算力枢纽网络(组网规模4倍于业界,可助力构建E级和10E级大型和超大型算力枢纽),时延在智能无损1.0的基础上,可进一步降低25%。

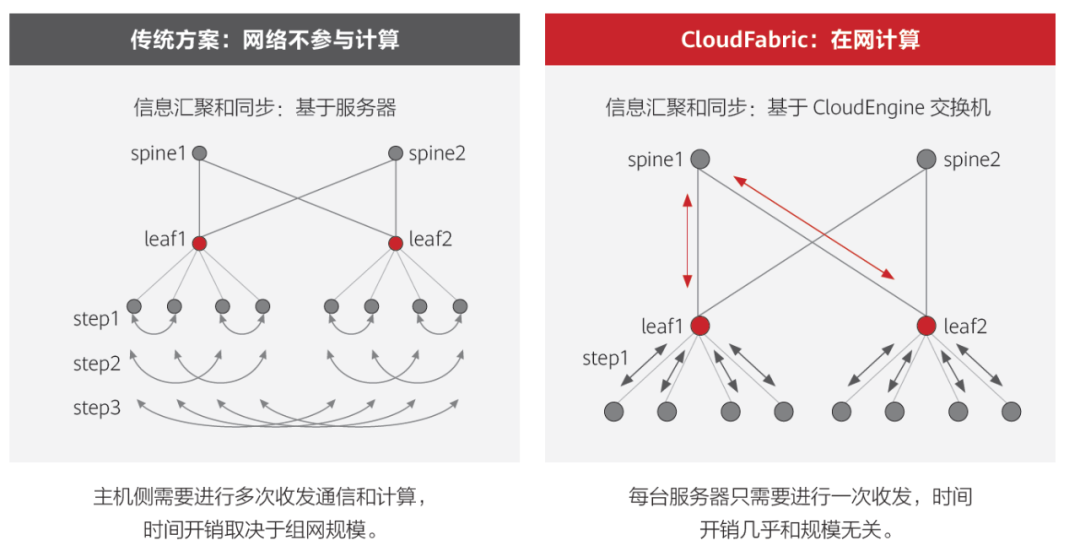
华为的智能无损2.0,基于在网计算(In-network computing)和拓扑感知(Topology-Aware Computing)实现网络和计算协同。一方面,网络参与计算信息的汇聚和同步,减少计算信息同步的次数;另一方面,通过调度确保计算节点就近完成计算任务,减少通信跳数,进一步降低应用时延。
以MPI_allreduce为例,相比传统网络仅做数据转发不参与计算过程,华为超融合数据中心网络可有效降低时延,提升计算效率27%。
华为超融合数据中心网络解决方案,为数据中心构建了统一融合网络,取代了此前的三种不同类型网络(LAN、SAN、IPC),大幅减少了网络建设成本和运维成本,总成本TCO下降了53%。AI业务的运行效率,则提升了30%以上。
█ 智能无损技术的积累沉淀
近年来,华为围绕智能无损网络和iLossless智能无损算法,接连发布了多个产品和解决方案。
2018年10月,华为就发布了AI Fabric极速以太网解决方案,帮助客户构建与传统以太网兼容的RDMA网络,引领数据中心网络进入极速无损的高性能时代。
2019年1月,华为又发布了业界首款面向AI时代的数据中心交换机CloudEngine 16800,承载了iLossLess智能无损交换算法,实现流量模型自适应自优化,从而在零丢包的基础上,获得更低时延和更高吞吐的网络性能。

2021年6月,华为发布全无损以太存储网络解决方案(NoF+)。该方案基于OceanStor Dorado全闪存存储系统和CloudEngine数据中心存储网络交换机构建,可实现存储场景端到端数据加速,充分释放全闪存性能潜力。
除了自身积极进行技术研究和产品化之外,华为还积极推动相关技术标准的成熟。
2021年8月,华为发布的智能无损技术论文《ACC: Automatic ECN Tuning for High-Speed Datacenter Networks》(高性能数据中心网络中的ECN动态调优)入选全球网络通信顶级会议ACM SIGCOMM 2021,得到业界专家的一致认可,具有世界级技术影响力。
在华为主导下,IEEE 802成立了Nendica(“Network Enhancements for the Next Decade” Industry Connections Activity)工作组,联合业界共同探讨以太网技术标准发展的新方向,为智能无损网络技术发展提供了理论研究的开放土壤。
█ 智能无损技术的落地实践
经过实际项目验证并获得客户认可的技术,才是可靠的技术。
华为的超融合数据中心网络CloudFabric 3.0解决方案,已经在金融、政府、超算中心、智算中心等客户广泛应用。包括中国银行、云南农信、华夏银行、湖北移动、中科院高能物理研究所、武汉人工智能计算中心、鹏城实验室等在内的众多高端用户,都是华为智能无损技术的使用者。
中国银行联合华为打造的新一代智能无损存储网络“RoCE-SAN”,结合中行具体的应用场景,实现了智能缓存管理、逐流精准控速、故障高可用秒级切换的技术创新突破,满足金融级高可用存储网络要求。
中科院高能物理研究所通过与华为的联合创新,采用零丢包以太网技术,构建了由数万颗CPU核构成的跨地域的高性能计算环境,很好地满足了高能物理领域对算力的需求。
某互联网巨头布局无人驾驶,无人驾驶技能的训练涉及到大量的AI计算:1天采集的数据,需要几百的GPU服务器7天才能训练完,严重影响无人驾驶的上市时间。通过华为的智能无损技术,最终使得整体训练的时长缩短40%,加速无人驾驶的商用进程。
除了丰富的行业落地案例,华为智能无损技术还获得了大量的行业奖项:
2018年6月,日本Interop展Best of Show Award金奖
2020年12月,中国银行业金融科技应用成果大赛“最佳解决方案奖”
2021年4月,日本Interop展Best of Show Award 2020银奖
2021年5月,2021数博会领先科技成果奖之“黑科技”类别
2021年10月,高性能计算领域 “融合架构创新奖”
2022年3月,中国通信学会科学技术奖特等奖
……
这些来自专业领域的认可,更加证明了华为基于智能无损技术的超融合数据中心网络解决方案,在领导力和先进性方面居于行业领先地位。
█ 结语
从逻辑上来看,华为基于智能无损技术的超融合数据中心网络解决方案,是将AI技术在数据中心进行落地,用AI赋能数据中心,再用数据中心,去支撑AI应用。这是一种非常有趣的良性循环,引领了整个ICT行业的智能化潮流。
这个方案是为算力时代量身定制的,可以很好地满足算力时代计算、存储、业务等多种场景数据流通的需要。
放眼未来,AI与数据中心的深度融合,将完美支撑企业数字化转型所需的算力需求,加速数据存储和处理过程,帮助企业快速决策,加快迈入数智时代。


课程:《计算机系统原理入门》
讲师介绍:极客编程
极客编程站长,自由职业者。数据库管理系统、文件处理、自动投注系统等各行各业工具插件作者。
课程介绍:《计算机原理》能让你拥有一个扎实的计算机基础,对计算机架构、操作系统、编程语言、计算机网络有一个本质上的认识,做到以不变应万变,并且可以独立开发模仿一些常用的软件工具、网站以及安卓程序,解决日常生活遇到的各种计算机问题。
课程特点:
1. 课程形式灵活,有视频、有文字、有理论、也有实战;
2. 整门课程系统性强,带您全方位了解计算机原理;
3. 趣味性强,学习不枯燥、不乏味;
学习方式:扫码 ↓ 购买立即开始学习~
