
数据仓库模型全景

数据仓库模型构建
一、数据仓库构建需要考虑的问题
与数据库的单表基于ER模型构建思路不同,其面向特定业务分析的特性,决定了它的构建需要整合多套数据输入系统,并输出多业务条线的、集成的数据服务能力,需要考虑更全面的因素,包括:
业务需求:从了解业务需求着手分析业务特点和业务期望;
系统架构:从系统架构和数据分布、数据特性等角度,分析系统架构设计上是否有问题;
逻辑设计:从数据模型逻辑设计出发是否设计合理,是否符合数据库开发和设计规范等;
物理设计:从库表类型、库表分区、索引、主键设计等维度,主要针对性能,可扩展性进行物理模型设计审查
二、什么是数仓的数据模型
数据仓库模型构建的宗旨能够直观地表达业务逻辑,能够使用实体、属性及其关系对企业运营和逻辑规则进行统一的定义、编码和命名,是业务人员和开发人员之间沟通的一套语言,数据仓库数据模型的作用:
统一企业的数据视图;
定义业务部门对于数据信息的需求;
构建数据仓库原子层的基础;
支持数据仓库的发展规划;
初始化业务数据的归属;
常用数据模型的是关系模型和维度模型,关系模型从全企业的高度设计一个3NF模型的方法,用实体加关系描述的数据模型描述企业业务架构,在范式理论上符合3NF,其站在企业角度进行面向主题的抽象,而不是针对某个具体业务流程的,它更多是面向数据的整合和一致性治理;
维度建模以分析决策的需求为出发点构建模型,直接面向业务,典型的代表是我们比较熟知的星形模型,以及在一些特殊场景下适用的雪花模型,大多数据仓库均会采用维度模型建模;
维度建模中的事实表客观反应整个业务的流程,比如一次购买行为我们就可以理解为是一个事实,订单表就是一个事实表,你可以理解他就是在现实中发生的一次操作型事件,我们每完成一个订单,就会在订单中增加一条记录,订单表存放一些维度表中的主键集合,这些ID分别能对应到维度表中的一条记录,用户表、商家表、时间表这些都属于维度表,这些表都有一个唯一的主键,然后在表中存放了详细的数据信息:
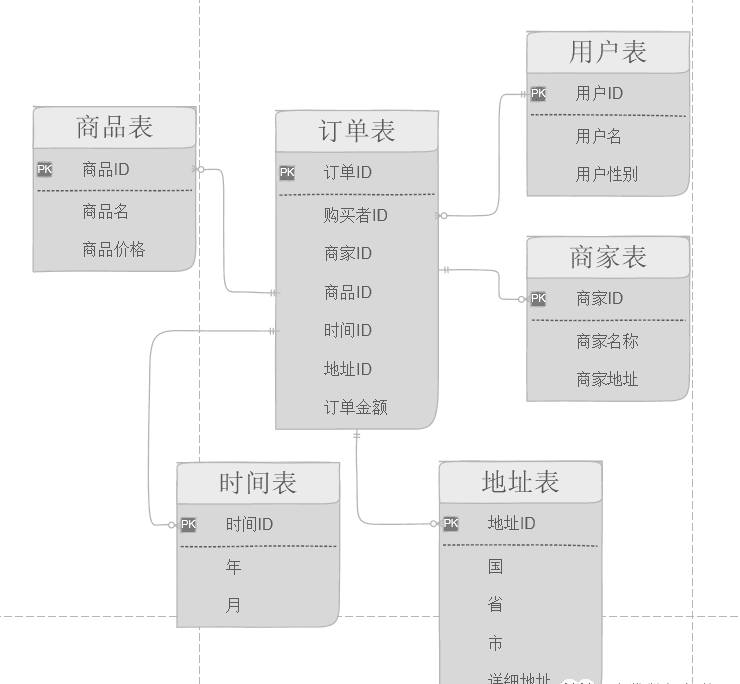
如果是采用ER模型,需要设计出一个大宽表,将订单-商家-地址-时间等信息囊括在内,比较直观、细粒度,但也存在设计冗余,如果数据量很大,对于查询和检索将是一个灾难;
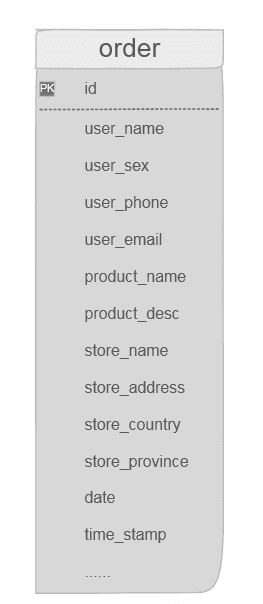
三、如何构建数仓的数据模型
概念模型设计(业务模型):界定系统边界;确定主要的主题域及其内容;逻辑模型设计:维度建模方法(事实表、维度表);以星型和雪花型来组织数据;物理模型设计:将数据仓库的逻辑模型物理化到数据库的过程;
1、概念模型设计
数据仓库中数据模型设计顺序如上,数据仓库是为了辅助决策的,与业务流程(Business Process)息息相关,数据模型的首要任务便是选择业务流程,为数据仓库的建立提供指导方向,这样才能反过来为业务提供更好的决策数据支撑,让数据仓库价值的最大化,对于每个业务流程,都需要进行独立的数据建模,将业务系统中的 ER 模型转化为数据仓库中的维度数据模型,以便更好的查询与分析。
2、逻辑模型设计
事实表一般由两部分组成,维度(Dimension)和度量(Measurement),事实表可以通俗的理解为「什么人在什么时间做了什么事」的事实记录或者场景上下文,拥有最大的数据量,它是业务流程的核心体现,比如电商场景中的订单表,其主键为一个联合主键,由各个维度的外键组成,外键不能为空值,事实表一般不包含非数字类型字段,虽然数据量大,但占用的空间并不大,保证更高的查询效率。
维度表用于对事实表的补充说明,描述和还原事实发生时的场景,如电商订单中定义用户、商品、地址、时间、促销5个维度,通过这5个维度还原订单发生时的场景,什么人在什么时间在什么地方购买了什么商品,以及购买该商品的促销方式。对于每一个维度而言,都有若干个属性来描述,比如用户有性别、年龄、所在地等信息。这些维度的属性就是之后数据统计的依据,比如我们可以统计不同性别,不同年龄,不同地区在订单中的差异,从向用户制定更精细的营销策略。
在关系型数据库三范式(3NF)设计极力避免数据的冗余,达到数据的高度一致性,但在数据仓库中3NF并不是最佳实践,反而让系统复杂不已,不利于理解和维护,所以在维度建模中,维度表一般采取反范式的设计,在一张维度表中扁平化存储维度的属性,尽量避免使用外键。
3、物理模型设计
在完成数据仓库的概念模型和逻辑模型设计之后,物理模型设计就是落地实施环节,根据数据的粒度和对于业务支撑能力将数据进行分层存储,数据分层存储简化了数据清洗的过程,每一层的逻辑变得更加简单和易于理解,当发生错误或规则变化时,只需要进行局部调整;
ODS层:全称是Operational Data Store,又叫数据准备层,数据来源层,主要用于原始数据在数据仓库的落地,这些数据逻辑关系都与原始数据保持一致,在源数据装入这一层时,要进行诸如业务字段提取或去掉不用字段,脏数据处理等等。可以理解为是关系层的基础数据;
DIM层:Dimension层,主要存放公共的信息数据,如国家代码和国家名,地理位置等信息就存在DIM层表中,对外开放,用于DWD,DWS和APP层的数据维度关联。
DWD层:全称是Data Warehouse Detail,用于源系统数据在数据仓库中的永久存储,用以支撑DWS层和DM层无法覆盖的需求,该层的数据模型主要解决一些数据质量问题和数据的完整度问题,比如商场的会员信息来与不同表,某些会员的的和数据可能不完整等等问题;
DWS层:全称是Data Warehouse Service,主要包含两类汇总表:一是细粒度宽表,二是粗粒度汇总表,按照商场订单例子,包含基于订单、会员、商品、店铺等实体的细粒度宽表和基于维度组合(会员日进场汇总、会员消费汇总、商场销售日汇总、店铺销售日汇总等)的粗粒度汇总表。这层是对外开放的,用以支撑绝大部分的业务需求,汇总层是为了简化源系统复杂的逻辑关系以及质量问题等,这层是的业务结构容易理解,dws层的汇总数据目标是能满足80%的业务计算。
其上根据业务需求可以继续构建ADS层(Application Data Store)和面向指标和报表的高度汇总层。
案例解读:
招标采购业务的数据仓库模型构建
按照数据仓库的构建思路,顺序是概念模型-->逻辑模型-->物理模型,最重要和复杂度较高的是概念模型的设计,需要结合业务,并根据业务特性设计事实表、维度表、顶层数据汇总表;
一、概念模型设计
概念模型需要结合生产系统的ER关系模型,梳理业务逻辑,当前生产交易系统使用的是ORACLE数据库,将数据分成多个库:业务库(包含招标采购项目流程)、主体+组织库(招标人、投标人、评标专家、代理机构)、财务库(标书费、平台服务费、招标保证金、CA办理费用等),项目表即是一个招标流程表,该表会记录关于招标过程中的,招标、投标、开标、评标、定标相关的数据:
招标:招标流程是招标人发起的,招标人将招标过程委托给代理机构,代理机构会发布招标公告,投标人在报名、响应阶段产生数据,响应后需要付投标保证金;
投标:投标人给代理机构缴纳标书费并下载招标文件,开标之前需要响应,并缴纳投标保证金;发售招标文件和投标人购买标书后,如果投标人对招标文件提出质疑,或招标人要修改招标文件,此时要在规定时间内发布一个澄清公告。
开标:开标一般是线下进行,代理机构把投标人召集到开标室,公开宣读投标人关于投标人报价、工期、质量、工程项目经理等投标人有实质要求的内容,此阶段拆封投标文件,解密电子的投标文件;
评标:评标一般是线下进行,代理机构把监督人、投标人、专家召集到评标室,专家对投标人资质及投标书打分,分为技术、商务、报价分;
定标:专家对投标人综合打分后,做一个总体排名,排名第1即为中标候选人,评标结束后需要发布预中标公告,将前3名公布,公告期间接受社会监督,期间产生的疑问、质疑需要代理机构/招标人澄清,澄清伴随着澄清公告,若质疑生效则可能废标和流标(评标成本高,一般不废标);
合同:若预中标发布后,质疑期间对于预中标候选人无影响,在预中标发布xxx天后,招标人需要同中标候选人签订合同,同时招标人需要退还其他没有中标单位的保证金;
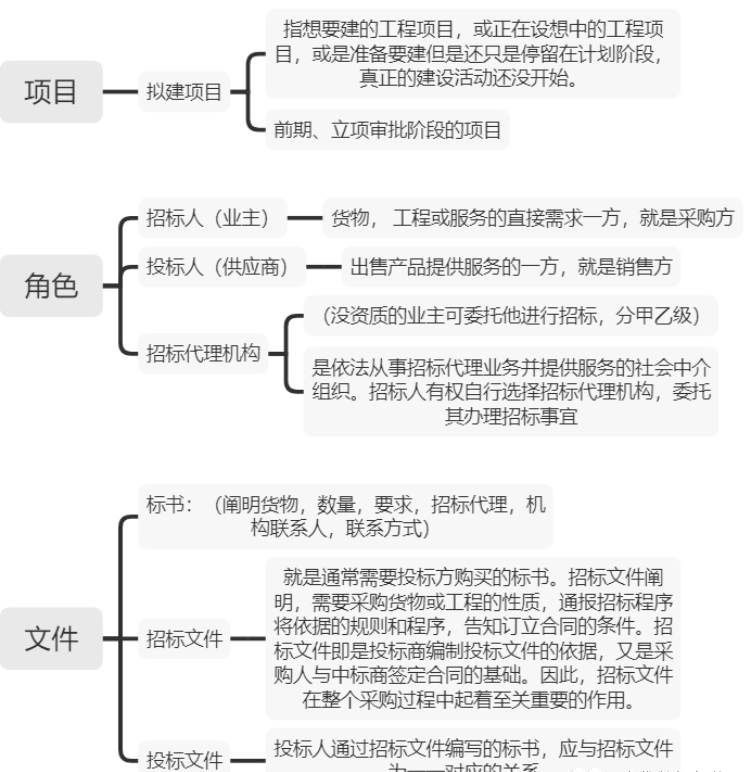
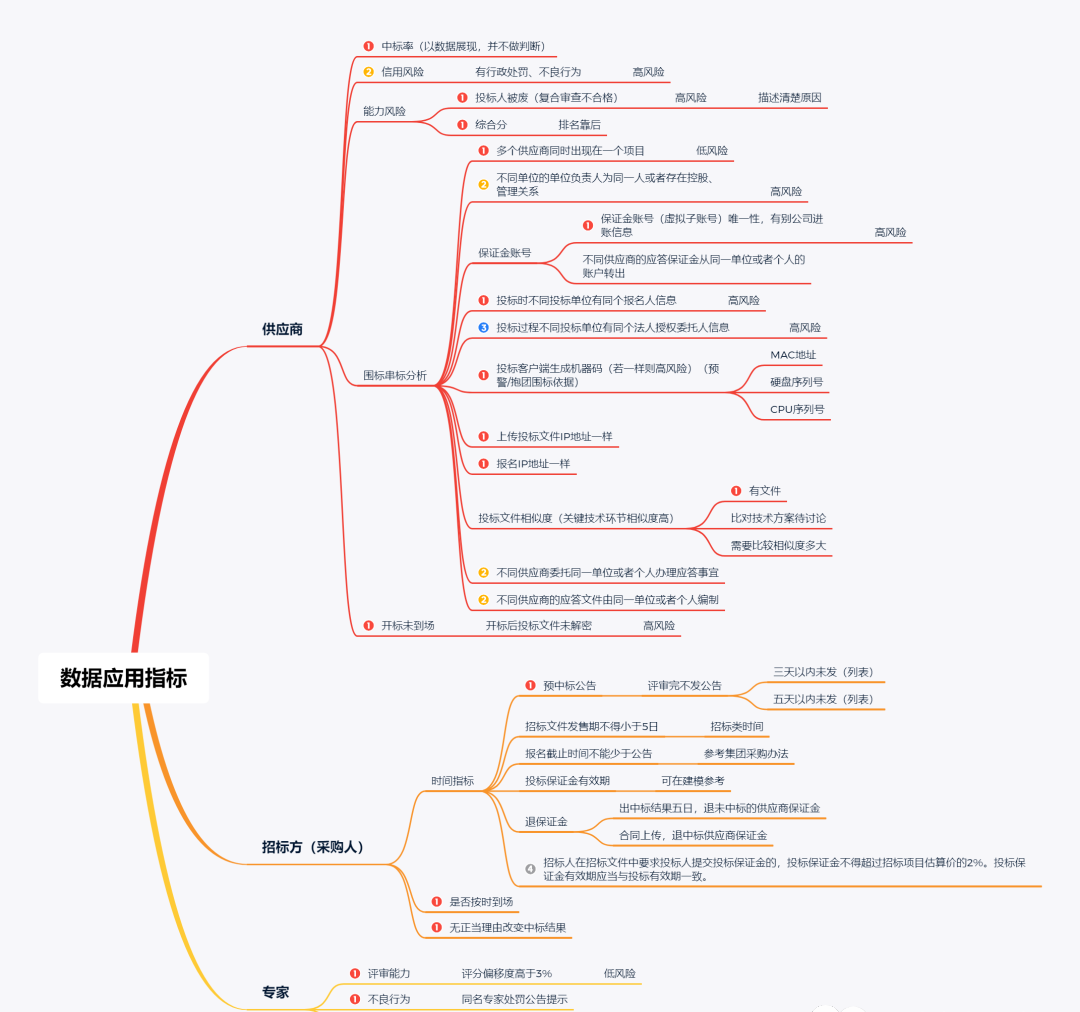
对于整个流程的梳理和业务了解后,客户更加关注流程的监管预警,以此为准整理一些监管维度:
二、逻辑模型设计
逻辑模型采用上一篇博文提及的维度建模模型,雪花模型,项目ID、投标人ID、招标人ID、代理机构ID、专家ID分别是整个招、投、开、评、定标流程的主要参与主体,数据抽取工具使用kettle:
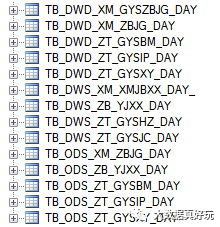
数据表命名规范:tb_模型层次_主题域_业务域_汇总粒度
kettle命名规范:kt_模型层次_主题域_业务域_汇总粒度
三、物理模型设计
构建ODS-->DWD-->DWS-->ADS的分层模型,这里ODS只抽取oracle库中源数据,不做任何清洗和变动,DWD层开始做数据的清洗和数据工程,DWS作轻度汇总,ADS面向应用查询提供更上层的汇总;以项目和供应商的汇总维度为例,项目流程是模型设计主体,供应商是类似维度表的数据,两者结合能够得到业务需要的一些投/中标相关的汇总维度(比如中标率排行、某个项目的投标人的注册金额相关统计、某投标人参与投标相关统计等):
在项目流程表中(定标流程),将招标人的编号设计在内,定标流程的统计项从该类ADS汇总维度出结果:

数据仓库的产品
前面讲了数据仓库的价值、构建思路、实例,完成数据仓库的概念、逻辑、物理模型设计后,数仓的产品选型也是需要考虑的部分,根据数据存储量、查询效率、并发能力可以选用MPP数仓和基于Hadoop的分布式数仓等。
一、MPP还是Hadoop
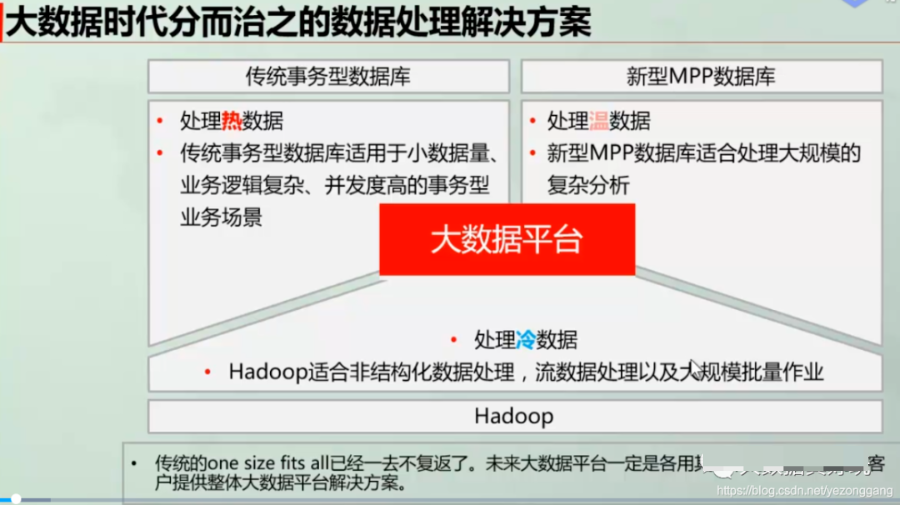
这里继续用之前用到的图讲解,数据仓库的特性是处理温数据和冷数据,面向业务分析提供偏于离线分析能力,因此一般选用Hadoop+MPP数仓结合的解决方法,Hive能够提供大批量历史数据的存储计算能力,Hbase能够提供半结构化文档的快速检索能力,MPP能够提供强大高压缩比基础上的快速查询能力;
二、MPP数仓特性
在MPP解决方案中目前我已接触过的是vertica和GP,在teradata实习期间没有用到td数仓;

数仓的特性是大批量的查询和索引,少量的改查工作,MPP (Massively Parallel Processing),即大规模并行处理数据库的一般特性:
① 列式存储意味着高压缩比、高IO能力、快速查询能力、智能索引(数据写入时);
② shared nothing意味着节点的相互独立、数据的冗余备份;
③ 分布式存储/计算、存储/计算的高扩展性、高安全;
MPP的架构分为3种,GP是master/slave模式,具备统一的查询入口(master),vertica是无中心架构,所有节点都提供查询服务,gbase是存储/管理双中心架构;
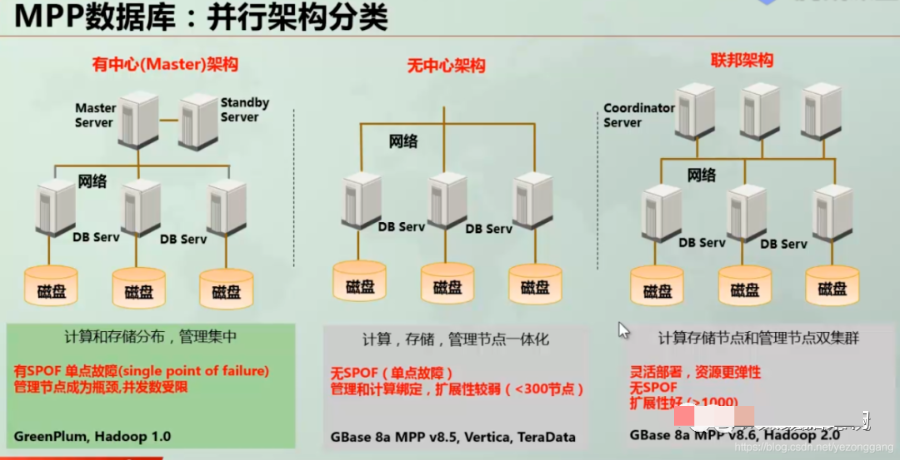
shared nothing 模式:x86机器构建计算/存储的高扩展集群,数据拆分多份并备份。shared disk 模式:专用小型机,存储1份数据。