
学习率调度器和自适应优化器简史,及2021年最佳实践建议

极市导读
本文讨论了学习率调度器和优化器的历史,引出现在实践者最熟悉的两种技术:周期学习率(cyclic learning rates)和Adam优化器,并且介绍了两种技术之间该如何选择。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
很久很久以前,在 Adam 和 Adagrad 发布之前,几乎所有神经网络的训练方式都是一样的 —— 使用一个固定的学习率和随机梯度下降(优化器)。
深度学习革命带来了一股新技术和新 idea 的旋风。在模型优化领域,最具影响力的两个新 idea 是学习率调度器(随时间修改学习率超参数,而不是保持不变)和自适应优化器(利用模型自身的反馈逼近梯度)。
在本文中,我们将讨论学习率调度器和优化器的历史,引出当今实践者最熟悉的两种技术: 周期学习率(cyclic learning rates)和 Adam 优化器。因为(原因我们后面会讨论)不可能同时使用这两种技术,所以我们还将讨论这两种技术之间的权衡: 例如,你应该选择哪种技术,以及什么时候选择。
第一个流行的学习率调度器: ReduceLROnPlateau
所有优化器都有一个学习率超参数,这是影响模型性能的最重要的超参数之一。
在最简单的情况下,学习率是固定的。然而,较早前发现的经验是,选择一个较大的初始学习率,然后随着时间的推移缩小它,会更好的收敛,得到性能更高的模型。这就是所谓的_退火(annealing)或_衰减(decay)。
在模型训练的早期阶段,模型还在向梯度空间大步迈进,较大的学习率有助于模型更快地找到所需的粗略值。
在模型训练的后期,情况恰恰相反。这个模型已经有了大致正确的梯度; 它只是需要一点额外的推力来找到性能的最后几个百分点。大的梯度不再合适,因为它会“超过(overshoot)”最优点。这样模型不会收敛于全局最低成本,而是会在附近跳来跳去:
这一发现使得第一个著名的学习率调度器 ReduceLROnPlateau (Pytorch 中的 torch.optim.lr_scheduler.ReduceLROnPlateau)流行开来。ReduceLROnPlateau 需要一个步长(step_size),一个耐心值(patience)和一个冷却期(cooldown)作为输入。在完成每一批次训练之后,检查模型性能是否有所提高。如果达到了耐心值批次时模型性能一直没有提高,那么学习率就会降低(通常是10倍)。在冷却期之后,这个过程再次重复,直到最后一批训练完成。
这种技术在几乎所有场景中都能提高一两个百分点的性能。因此,直到2015年,早期停止(EarlyStopping),ReduceLROnPlateau,和随机梯度下降(stochastic gradient descent)的组合都是最先进或接近最先进的。
自适应优化器
2015年论文 《Adam: A Method For Stochastic Optimization》 发布,介绍了第一个获得广泛关注的自适应优化器 Adam (PyTorch 中的 torch.optimi.Adam)。
自适应优化器避免使用单独的学习率调度器,而是选择将学习率优化直接嵌入到优化器本身。实际上,Adam 更进一步,根据每个权重来管理学习率。换句话说,它给了模型中的每个自由变量自己的学习率。Adam 实际分配给这个学习率的值是优化器本身的实现细节,而不是你可以直接操作的东西。
与 ReduceLROnPlateau 相比,Adam 有两个引人注目的优势。
第一,模型性能。这是一个更好的优化器,句号。简单地说,它训练出了更高性能的模型。
第二,Adam 几乎没有参数。Adam 确实有一个学习率超参数,但是该算法的自适应特性使其非常鲁棒 —— 除非默认学习率偏离了一个数量级,否则改变它并不会对性能产生太大影响。
Adam 并不是第一个自适应优化器(这个荣誉属于2011年发布的 Adagrad),但它是第一个足够鲁棒、足够快、适用于通用用途的自适应优化器。发布后,Adam 立即取代了 SGD 加上 ReduceLROnPlateau,成为大多数应用的最佳设置。之后还有一些改进的变种(如 Adamw) ,但是在通用用途上,这些都没法取代原版 Adam。
因为 Adam 在内部管理学习率,所以它与大多数学习率调度器不兼容。任何比简单的学习率预热(warmup)和/或衰减(decay)更复杂的操作都会使 Adam 优化器在管理其内部学习率 时“终结”学习率调度程序,导致模型收敛恶化。
这使得 Adam 与我们将在后两节中介绍的两种技术 —— 余弦退火(cosine annealing)和单周期学习(one-cycle learning)完全不兼容,这两种学习率调度器都可以对学习率做一些棘手而有趣的事情。在本文的最后一节,我们将讨论 Adam 和这两种技术中更现代的单周期学习之间的权衡。
余弦退火热重启(Cosine annealed warm restart)
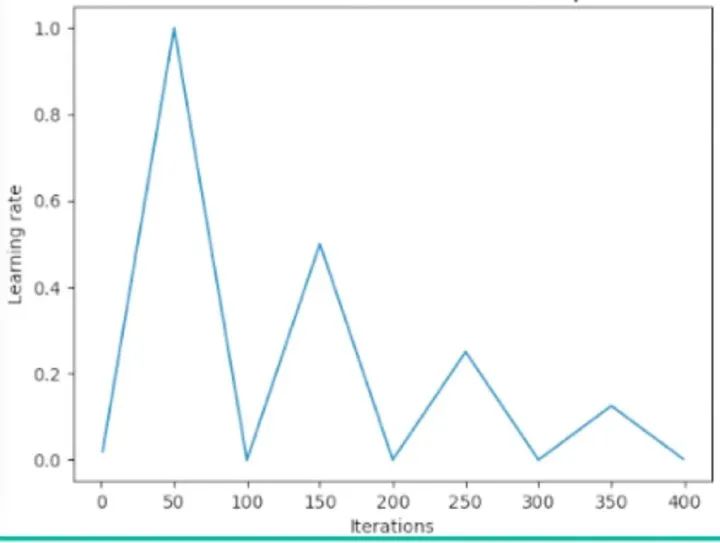
2017年的论文 《SGDR: Stochastic Gradient Descent with Warm Restarts》 带火了热重启的 idea。一个包含热重启的学习率调度器偶尔重新提高学习率。下面一个简单的线性例子展示了这是如何做到的:
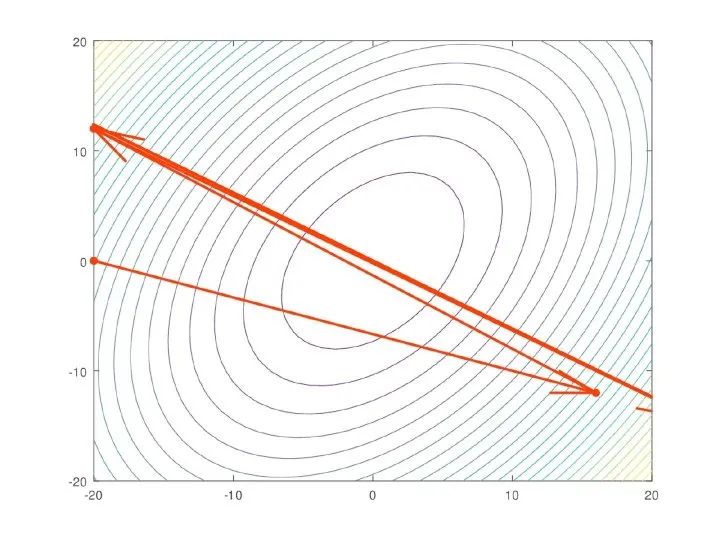
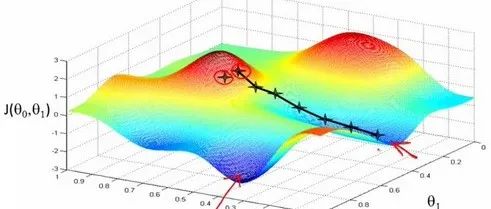
热重启通常会导致模型发生发散(diverge)。这是故意的。结果表明,增加一些可控的发散使得模型可以绕开任务的成本平面的局部极小值工作,让模型可以找到一个更好的全局最小值。这类似于发现一个山谷,然后爬上附近的小山,再发现一个更深的山谷。下面是视觉上的理解:
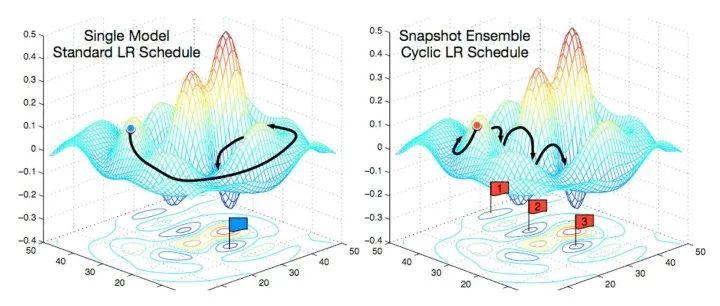
这两个学习者都收敛到同一个全局最小值。然而,在左边,学习者慢慢地沿着一条低梯度的路径移动。在右边,学习者落入一系列的局部极小值(山谷) ,然后利用热重启来爬过他们(山)。在这个过程中,它会更快地找到相同的全局最小值,因为它所走的路径总体上有一个更高的梯度。
fast.ai 普及了一个同时使用热重启和余弦退火的学习率调度器:
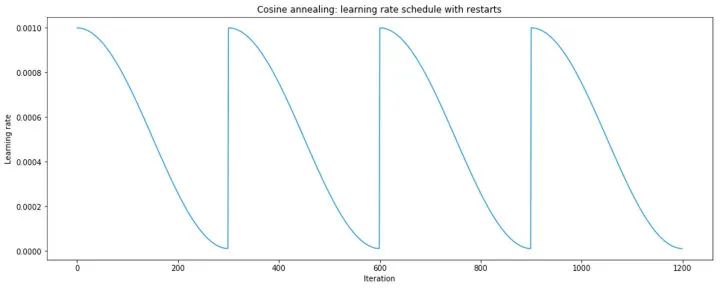
余弦退火比线性退火具有更好的收敛行为,原因尚未完全清楚。
这个学习率调度器是 fastai 框架几年来使用的默认调度器。它首先在 PyTorch 0.3.1版本中提供(torch.optim.lr_scheduler.CosineAnnealingLR),于2018年2月发布。
单周期学习率调度器(One-cycle learning rate schedulers)
fast.ai 不再推荐余弦退火,因为它不再是最高性能的通用学习率调度器。现在,这个荣誉属于单周期学习率调度器。
单周期学习速率调度器在2017年的论文 《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》 中被引入。论文使用了以下的学习率策略(既适用于学习率,也适用于动量):
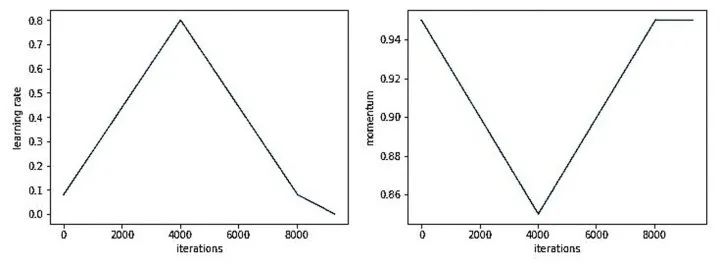
最理想的情况是,学习率和动量应该设置为一个正好使网络在其峰值开始发散的值。剩下的训练计划包括预热(warm-up)、冷却(cool-down)和微调(fine-tuning)期。注意,在微调期间,学习率下降到初始值的十分之一。
当学习率非常高时,动量是反向的,这就是为什么动量在优化器中以和学习率相反的方式退火。
单周期学习率调度器或多或少地使用了余弦退火热重启学习率调度器所使用的机制,只是形式因素不同。
在 fastai 中,实现稍微改了一下,再次从线性退火切换到余弦退火:
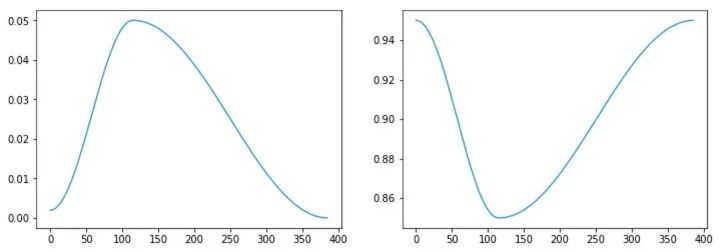
fastai 建议使用单周期加上 SGD,而不是 Adam,因为经过一些调优(正确获得最大学习率尤其重要) ,它可以在短很多的时间内训练好性能大致相同或稍微差一点的模型。这个现象被上面提到的单周期论文作者 Leslie Smith 称之为 超收敛(superconvergence)。例如,论文展示了 CIFAR10 上的以下表现:
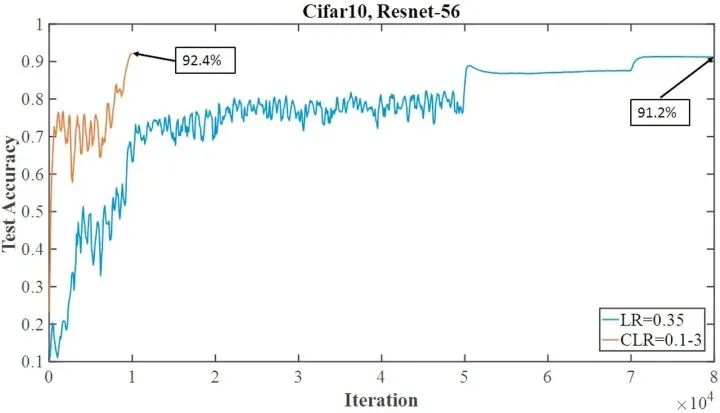
虽然你不该指望实际实践中结果也这么引人注目,超收敛确实已经在广泛的数据集和问题领域上证明过自己了。
2019年8月在 PyTorch 实现了单周期学习率调度器(torch.optim.lr_scheduler.OneCycleLR)。
2021年的观点
尽管 fast.ai 大力倡导,目前大多数从业者仍然使用 Adam 优化器作为默认设置。
例如,如果浏览最近的 Kaggle 竞赛的启动程序内核,你将看到 Adam 的使用占据了主导地位。正如我上面解释的,在很大程度上因为 Adam 基本上没有参数,所以它对模型更改的鲁棒性要比 OneCycleLR 强得多。开发更加容易了,因为必须要调的超参数少了一组。在实际应用中,这些优点似乎比 OneCycleLR 的计算优势超收敛更为重要。
然而,一旦你进入了一个中型模型训练项目的后期优化阶段,尝试从 Adam 转移到 OneCycleLR 是非常值得的。想象一下,如果你的模型能够在 25% 的时间内达到 98% 的性能,你的算法工程师生活将会轻松多少!
如何你有足够时间调优,超收敛是一个非常有吸引力的性质。这就是为什么很多 PyTorch 的快速深度学习训练指南把 OneCycleLR 作为他们的顶级 PyTorch 训练技巧之一。
原文:https://spell.ml/blog/lr-schedulers-and-adaptive-optimizers-YHmwMhAAACYADm6F
推荐阅读
2020-10-06
2020-01-01

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
