
学习网络爬虫有多难?
点击上方蓝字关注我们


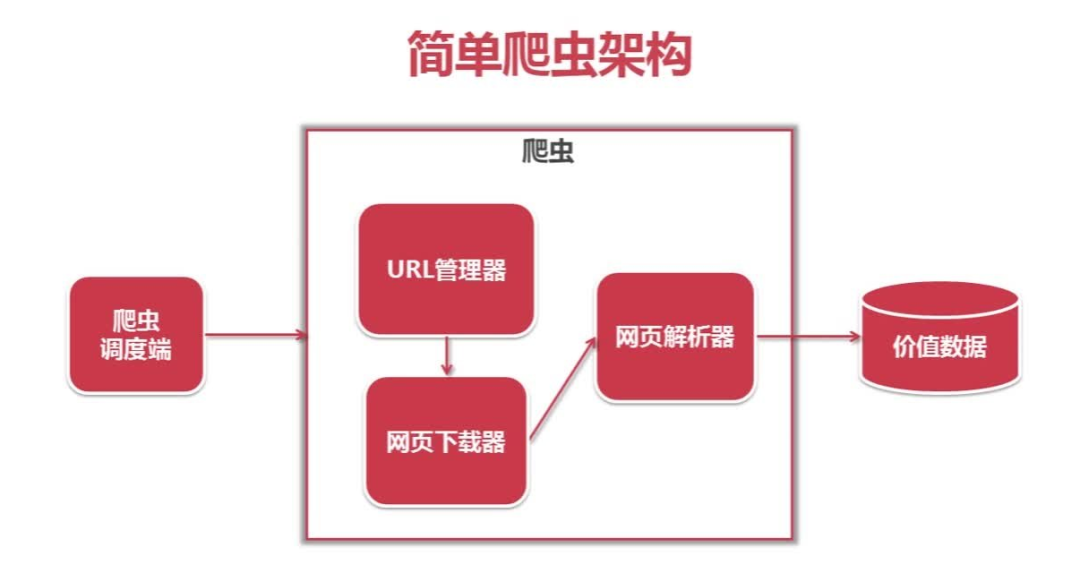
学习爬虫,我们首先要了解什么是爬虫以及它的工作流程,知己知彼,方能百战百胜嘛。
爬虫基础知识点
1、请求与响应
2、爬虫与反爬虫
3、开发工具
4、Urllib库使用详解与项目实战
5、requests库安装使用与项目实战
爬虫进阶
1、爬虫框架实现
2、破解反爬技术
3、代理池实现
4、模拟登陆
5、pyspider框架
爬虫高级部分
1、APP的抓取
2、Scrapy框架
3、分布式爬虫实战
4、分布式爬虫部署
可见在学习python网络爬虫的道路上任重而道远。不过也没有你想的那么复杂,因为直面爬虫的道路上我会和你一起!
文末福利:

扫码二维码
获取更多精彩
python学前班


扫码回复‘爬虫’分享给你最新爬虫教程!

点个在看你最好看

评论