
NAS-ViT | 超低FLOPs与Params实现50FPS的CPU推理,精度却超越ResNet50!!!


设计精确、高效的
Vision Transformers一直依赖都是一项重要而富有挑战性的任务。Supernet-based one-shot神经体系结构搜索(NAS)可以实现快速的体系结构优化,并在CNN上取得了最新的结果。然而,直接应用NAS来优化ViT会带来比较差的性能,甚至比单独训练ViT更差。在这项工作中,作者观察到性能较差是由于梯度冲突所导致的:不同Sub-Networks的梯度与SuperNet的梯度冲突在ViTs中比在CNN中更严重,这导致训练的早期饱和和较差的收敛。为了缓解这个问题,本文提出了一系列的技术,包括
梯度投影算法、Switchable scaling layer以及简化的数据增强和正则化训练配置。该技术显著提高了所有Sub-Networks的收敛性和性能。作者将其设计的
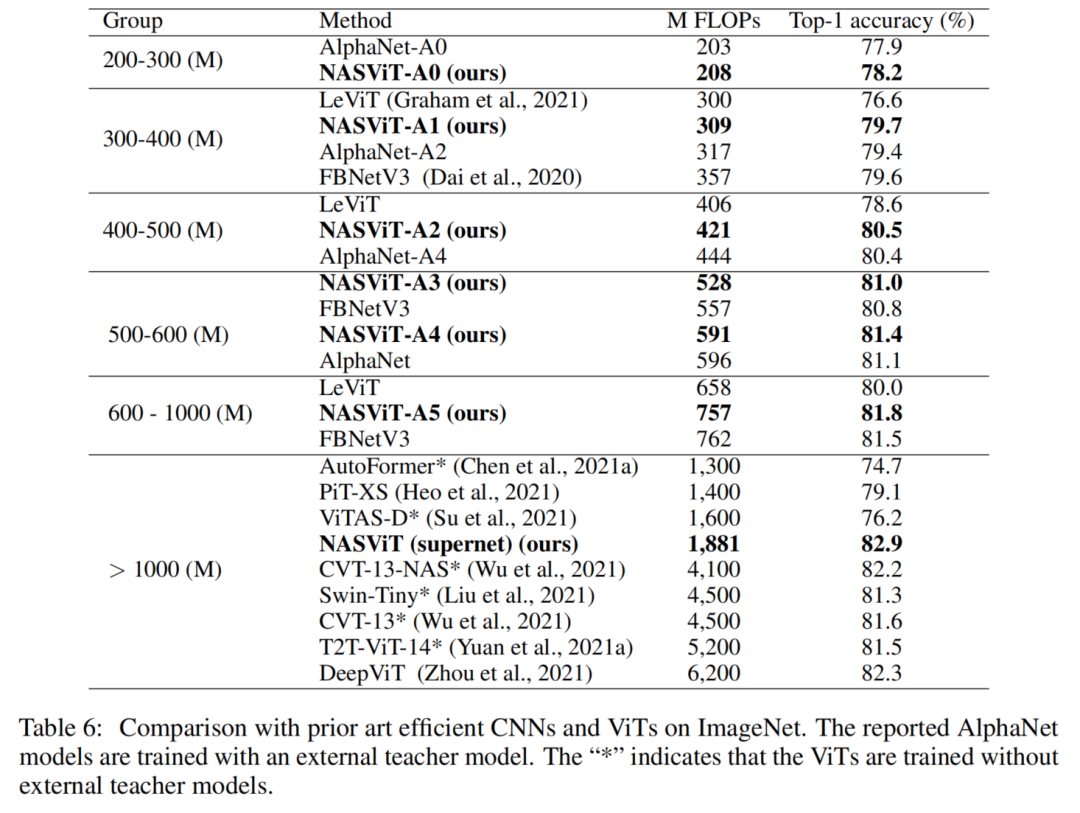
Hybrid ViT模型家族,称为NASViT,在ImageNet上在200M到800M FLOPs情况下分别达到了78.2%和81.8%的Top-1精度,并优于所有现有的CNN和ViT,包括AlphaNet和LeViT。当应用到下游任务语义分割时,NASViTs在Cityscape和ADE20K数据集上的表现也优于以前的Backbone,在5G FLOPs的情况,mIoU分别实现了73.2%和37.9%。
1事出缘由
在中小型网络架构上,ViT的性能仍低于CNN,特别是与经过神经架构搜索(NAS)高度优化的CNN架构,如AlphaNet, FBNetV3等相比。
例如,最初的DeiT-Tiny在1.2G FLOPs情况下,只能达到72.2%的Top-1准确率。最近提出的LeViT取得了重大进展,使用卷积/Transformer混合架构,在305M FLOPs情况下实现了76.6%的Top-1准确率,但是训练时间却延长了3倍。相比之下,AlphaNet只有203M FLOPs,却达到77.8%的Top-1准确率。
针对以上比较大的精确度差距作者提出了一个自然的问题:构建大型和动态感受野的Transformer Block对小型模型有益吗?
为了回答上述问题,在这项工作中,作者的目标是开发一个具有200-800M FLOPs的高效ViT家族。一种自然的方法是利用NAS,NNS已经实现了最先进的(SOTA)精度-效率权衡。最近提出的基于SuperNet的NAS(如BigNAS和AlphaNet)构建了一个包含架构搜索空间中所有Sub-Networks的权重共享图。利用具有位置知识蒸馏(KD)的Sandwich Sampling Rule,同时对每个小批量的SuperNet和Sub-Networks进行优化,从而提高训练的收敛性。
为了利用基于SuperNet的NAS,首先修改LeViT模型,构建ViT的架构搜索空间,然后联合优化AlphaNet之后的模型架构和参数。然而,作者发现直接应用AlphaNet在ViT搜索空间上的表现较差,甚至比单独训练ViT更差。
为了理解性能不佳的根本原因,作者检查了SuperNet训练过程,并观察到在Sandwich Sampling Rule过程中SuperNet的梯度和Sub-Networks不同,并相互冲突,这会使得ViT的训练损失饱和更快,进而导致收敛不理想。
为了缓解梯度冲突的问题,作者提出了三种不同的技术来改进SuperNet训练。
首先,在将不同
Sub-Networks的梯度叠加在一起之前,优先训练Sub-Networks,因为主要目的是建立高效的Sub-Networks。该部分主要是使用投影梯度算法来实现并,该方法去除了SuperNet梯度中与Sub-Networks梯度冲突的影响。其次,为了缓解不同
Sub-Networks之间的梯度冲突,作者建议在每个Transformer层中增加Switchable scaling layer。不同比例层的权值在不同的Transformer Block之间不共享,这样便可以减少Sub-Networks之间的梯度冲突。最后,建议使用弱数据增强方案,并在训练过程中的正则化操作,以降低优化难度,从而减少梯度冲突。
2本文方法
本文的目标是在200M-800M的FLOPs范围内设计高效的中小型ViTs。而本文构建的搜索空间是受到最近提出的LeViT的启发。
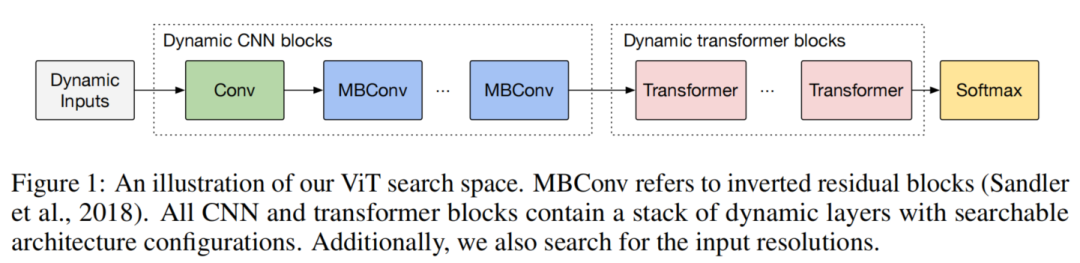
LeViT是利用卷积和Transformer的混合搭建的高效模型。在LeViT中,引入卷积来处理高分辨率输入,而利用Transformer对低分辨率特征进行全局信息的提取。
搜索空间
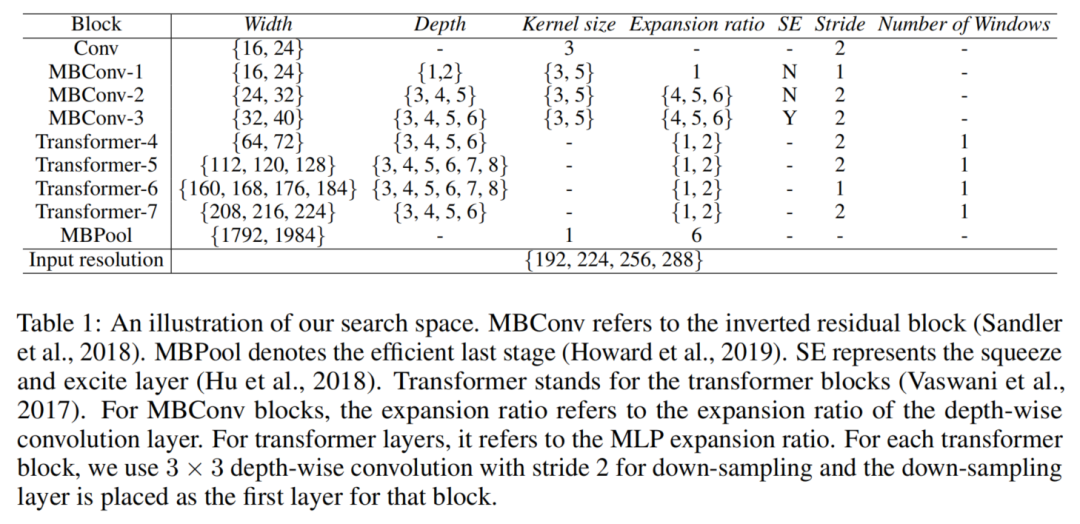
在表1中总结了搜索空间的详细搜索维度。
对于每个CNN Block,遵循AlphaNet中的设计,搜索最优通道宽度、块深度、扩展比和核大小;
对于每个Transformer Block,搜索Window的最佳数量、隐藏特征尺寸(表1中的宽度)、深度和MLP扩展比。与CNN Block相比,Transformer Block的一个特殊搜索维度是Window k的个数。当Window k的个数大于1时,类似Swin Transformer,将输入Token划分为k组。然后,分别计算每组的自注意力权值,以减少计算成本(标准全局自注意力是k=1的特例)。
在这项工作中,只搜索第1个Transformer Block的窗口数,因为经过4次降采样后,其他Transformer Block的输入分辨率已经很小了。与AlphaNet的搜索范围相似,本文的搜索空间中最小的Sub-Networks有190M FLOPs,最大的Sub-Networks有1881190M FLOPs。
组件1:高效的Transformer层
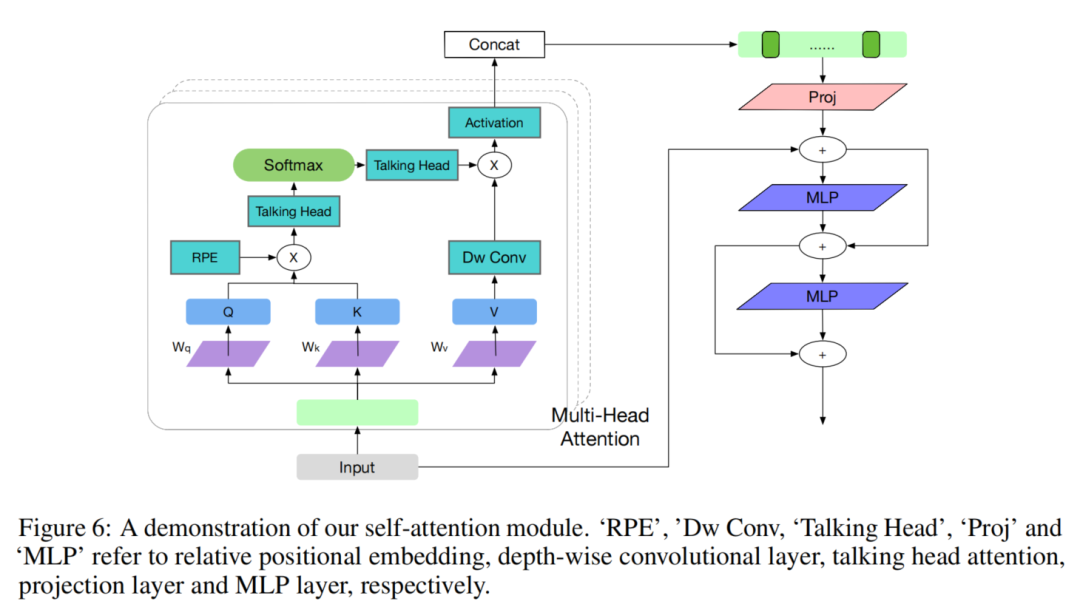
近期研究者开发了很多标准自注意力的多种变体,也有着不同的关注点(效率、收敛性、长期依赖性等);如LeVit, Swin-Transformer和VOLO;
本文开发了一个全新的Transformer层,以提高视觉任务的效率和有效性。Transformer层如图所示。为了提高ViT模型的学习能力,在自注意力模块中加入了Talking head layer和Depth-wise Convolution。
另外,继LeViT之后,对V矩阵的维数进行展开比为4的扩展,并在投影矩阵之后引入激活函数。在Swin Transformer之后,使用相对位置嵌入来表示注意力分数。为了提高效率,将MLP的扩展比降低到{1,2},并增加一个额外的MLP层,以保持模型在MacaronNet之后的复杂性。
组件2:Positional information
Transformer结构中的位置嵌入是位置相关的可训练参数。最近的研究提出了绝对位置嵌入、相对位置嵌入或额外的Depth-wise Convolution层来增强局部信息。
本文引入2个额外的Depth-wise Convolution层到一个具有相对位置嵌入的MHSA。对于相对位置嵌入,直接遵循NLP中的实现。对于Depth-wise Convolution,在MLP层中增加一个Depth-wise Convolution层,在V矩阵的线性变换后再增加一个Depth-wise Convolution层。
组件3:Expansion Ratio
在自注意力设计空间中,研究者们探索了拓宽通道是否能有良好的表现。LeViT提出将V的尺寸扩大,这里遵循LeViT的设计,将V的尺寸扩大了4倍。
研究人员已经探索了应该在一个自注意力块中使用多少层MLP。这里采用为每个自注意力块增加一个MLP层的策略,但为了提高效率,将MLP的扩展比降低到{1,2}。如图6所示,在第1个MLP层之后添加了一个额外的MLP层。
组件4:Normalization Layers and activation
许多最近的工作应用了额外的batch normalization layers、layer normalization layers或激活函数到网络。考虑到layer normalization layers的计算成本,NASViT不引入任何新的normalization layers。
组件5:Talking-head attention and number of heads
现有的大多数ViT将Head的尺寸设置为24/32。然而,对于通道较少的模型,Head尺寸越大,Head数量就越少。
这里设置较小的Head尺寸(如8、16),使Head的数量更大,并进一步引入Talking-Head Attention,以提高不同Head的容量。Talking-Head Attention在所有Talking-Head之间引入2个额外的线性变换,一个在softmax之前,另一个在softmax之后。
组件6:Classification head
由于使用了Depth-wise Convolution和下采样,为了简单起见,去掉了分类Token。LeViT和DeiT使用2个Head进行知识蒸馏和监督标签,而使用一个Head进行所有训练,并将单层全连接层Head替换为MobilenetV3 Head,以减少计算成本。
组件7:Scaling Factor
为了训练非常深的Transformer模型,Touvron等人在模型中引入了额外的可学习的、初始化为的通道比例因子。
在模型中,每个MLP和Multi-Head Attention(MHA)层的输出中引入通道比例因子。
Naive supernet-based NAS fails to find accurate ViTs
SuperNet的训练严格遵循AlphaNet中的最佳做法。在ImageNet上为SuperNet进行360个Epoch的训练。在每个训练步骤中,采用Sandwich Sampling Rule,对4个Sub-Networks进行采样:最小的Sub-Networks、SuperNet(又称最大的Sub-Networks)和2个随机的Sub-Networks。
所有Sub-Networks都由基于α-散度KD的SuperNet监督;此外,由于候选网络包含Transformer Block,因此选择通过用Adam替换SGD优化器,并利用外部预训练的教师模型来获得最佳准确性,从而进一步纳入来自LeViT的最佳训练配置。
具体来说,使用预训练的老师来监督SuperNet,并限制所有其他Sub-Networks向SuperNet学习。
在这项工作中,使用ImageNet上具有83.3% Top-1准确率的EfficientNet-B5作为老师来训练ViT SuperNet。
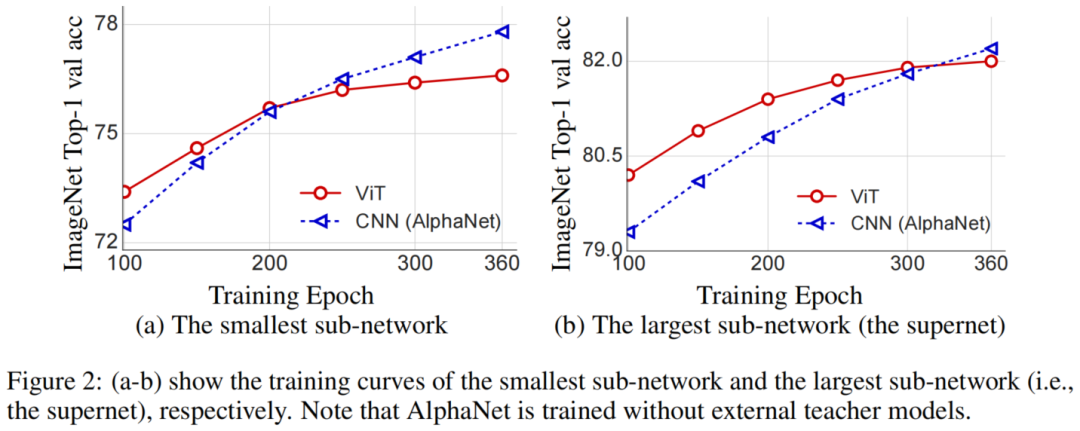
图2中绘制了最小Sub-Networks和最大Sub-Networks的训练曲线。可以看出在搜索空间中,最小的Sub-Networks和最大的Sub-Networks的收敛性都不如CNN。具体来说,最小的和最大的Sub-Networks的验证精度都在250 epoch左右达到饱和状态,最终的精度远低于CNN。为了了解较差的模型性能,从以下3个方向研究ViT SuperNet训练的潜在问题。
1、是搜索空间设计得不好吗?
为了验证,作者从搜索空间中随机选取4个Sub-Networks,计算成本从190M-591M FLOPs。然后,用相同的数据增强和正则化从0开始训练这些网络。

从表2中可以看出,从0训练的Sub-Networks优于从SuperNet采样的Sub-Networks。需要注意的是,从以前的工作中,通过利用位置知识蒸馏和权重共享,SuperNet通常比从0训练学习的Sub-Networks更准确。
在表2中的观察表明,糟糕的表现不是来自搜索空间,而是来自对SuperNet训练的干扰。
2、训练配置是否适合ViTs?
与AlphaNet相比,最近的生活方法,例如DeiT和LeViT,建议使用更强的数据增强方案(例如,CutMix、Mixup、Randaugment、Random Erasing和Stronger Regularization(例如,large weight decay、large drop path probability)进行训练。
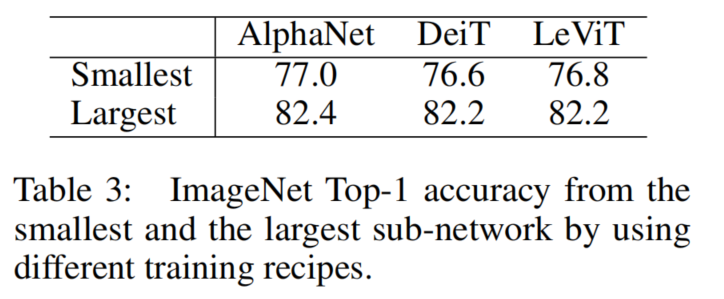
从表3中可以看出,与基于AlphaNet的训练结果相比,基于DeiT-或基于Levit的训练配置产生了更差的准确性。
3、SuperNet的训练过早饱和是因为梯度冲突吗?
与标准的单网络训练相比,SuperNet训练的一个主要区别是在每一步都对多个网络进行采样和训练。作者这里假设,由于网络的异质性和复杂结构,SuperNet和Sub-Networks的训练损失可能产生冲突梯度,而冲突梯度可能导致收敛缓慢和性能不佳。
为了验证这一假设,计算了来自SuperNet的梯度和来自Sub-Networks的平均梯度之间的余弦相似度。负余弦相似度表示SuperNet和Sub-Networks产生冲突梯度,并倾向于向相反方向更新模型参数。为了定量地检验梯度冲突问题,遍历整个ImageNet训练集,并在每一层上计算所有训练图像之间的SuperNet和Sub-Networks梯度之间的负余弦相似度的百分比。梯度计算采用与SuperNet训练阶段相同的数据增强和正则化方法。对于AlphaNet,使用它的官方代码来训练模型。

如表4所示,与CNN相比,ViT SuperNet存在更严重的梯度冲突。根据多任务学习中已有的研究,较大的梯度冲突比甚至对于二元分类问题也可能导致精度显著下降。假设ViT SuperNet络性能较差的主要原因是SuperNet梯度和Sub-Networks梯度之间存在较大比例的分歧。
具有梯度冲突感知能力的SuperNet训练
作者从3个方面改进ViT SuperNet训练,解决SuperNet和Sub-Networks之间的梯度冲突问题:
通过将 SuperNet梯度投影到Sub-Networks梯度的法向量来手动解决梯度冲突;在搜索空间中引入 Switchable scaling layer,赋予Sub-Networks更大的优化自由度;减少数据增强和正则化,提供更容易的监督信号。
1、梯度投影优化Sub-Networks更新
第1个想法是,当来自SuperNet的梯度和来自Sub-Networks的梯度相互冲突时,就会专注于训练Sub-Networks。
由于对200M-800M FLOPs范围内的Sub-Networks感兴趣,建议在观察到梯度冲突时,优先考虑Sub-Networks的优化,而不是SuperNet。
设和分别表示SuperNet和Sub-Networks的梯度。为了确定Sub-Networks训练的优先级,在和的余弦相似度为负时,将投影到的正向量上,以避免梯度冲突。每次带投影的训练迭代时的总体累积梯度可以写成如下:
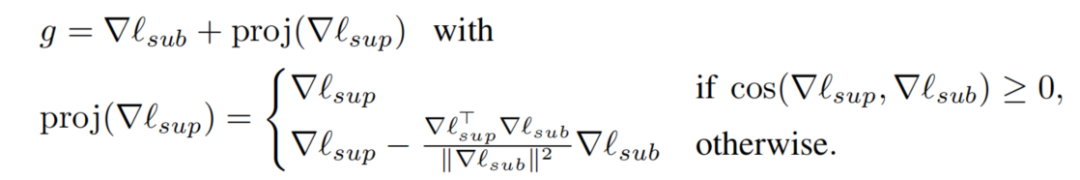
注意,如果,,这确保了梯度余弦相似度是非负的。
在Sandwich Sampling中,由于每次迭代都采样多个Sub-Networks,因此被计算为所有Sub-Networks的梯度之和。
虽然等式可以解决梯度冲突的问题,但是它可能也会导致缓慢的收敛,因为由此产生的梯度是有偏倚的。因此,作者还从搜索空间设计和训练策略细化的角度,提出了以下2种技术来减少梯度冲突。
2、Switchable scaling layer
基于Slimmable NN,引入了额外的Switchable scaling layer,以允许具有不同层宽度和深度的Sub-Networks重新缩放其特征。
具体来说,对于每个Transformer层,在自注意力(SA)和MLP的输出处分别引入了一个可切换的缩放层,如图3所示。假设是一个缩放层的输入特征,其中是特征维数(即在正向路径中被选择的通道的数量),是该层在一个Transformer搜索块中的索引。缩放层将转换为。这里的是可学习的参数,表示元素级的乘法。
对于每个Transformer块,[c,d]的每个不同配置将指定一组独立的Switchable scaling layer。根据CaiT将所有缩放因子初始化为一个很小的值(例如),以实现快速收敛和稳定的训练。从直观地看,Switchable scaling layer有效地提高了Sub-Networks的模型容量,并赋予了Sub-Networks更大的优化灵活性。
3、减少数据增强和正则化
此外,作者观察到,在存在更强的数据增强和更强的正则化的情况下,SuperNet和Sub-Networks,如large weight decay,更有可能相互冲突。因此,简化了AlphaNet训练方案并使用一个较弱的数据增强方案——随机增加增强转换的数量和大小设置为1,并删除正则化,如Drop连接,辍学和重量衰减,从训练;比较见表5。
此外,作者观察到,当存在更强的数据增强和更强的正则化时,SuperNet和Sub-Networks更有可能相互冲突,例如,large weight decay、 large DropConnect。因此,简化了AlphaNet的训练方案,并使用较弱的数据增强——RandAugment与augmentation transformations,并去除正则化,例如DropConnect,dropout和权重衰减。

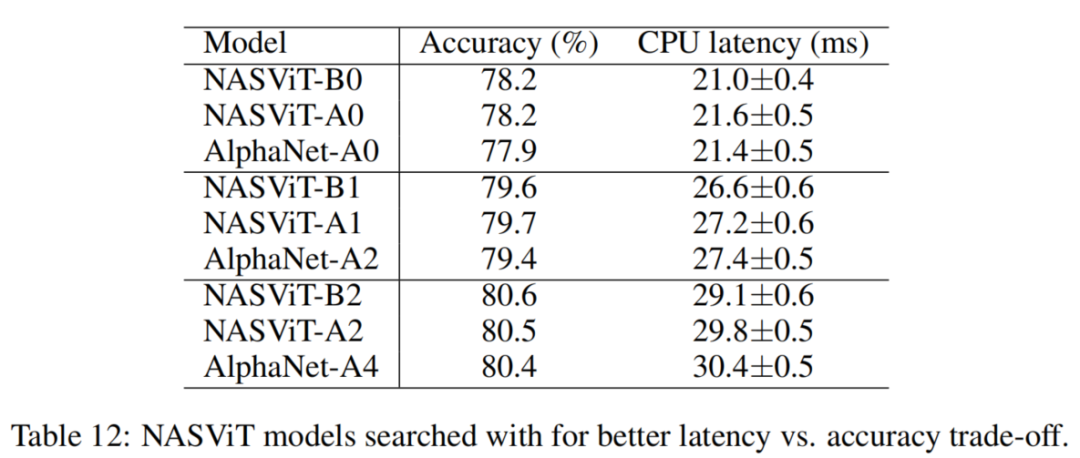
4、推理延迟
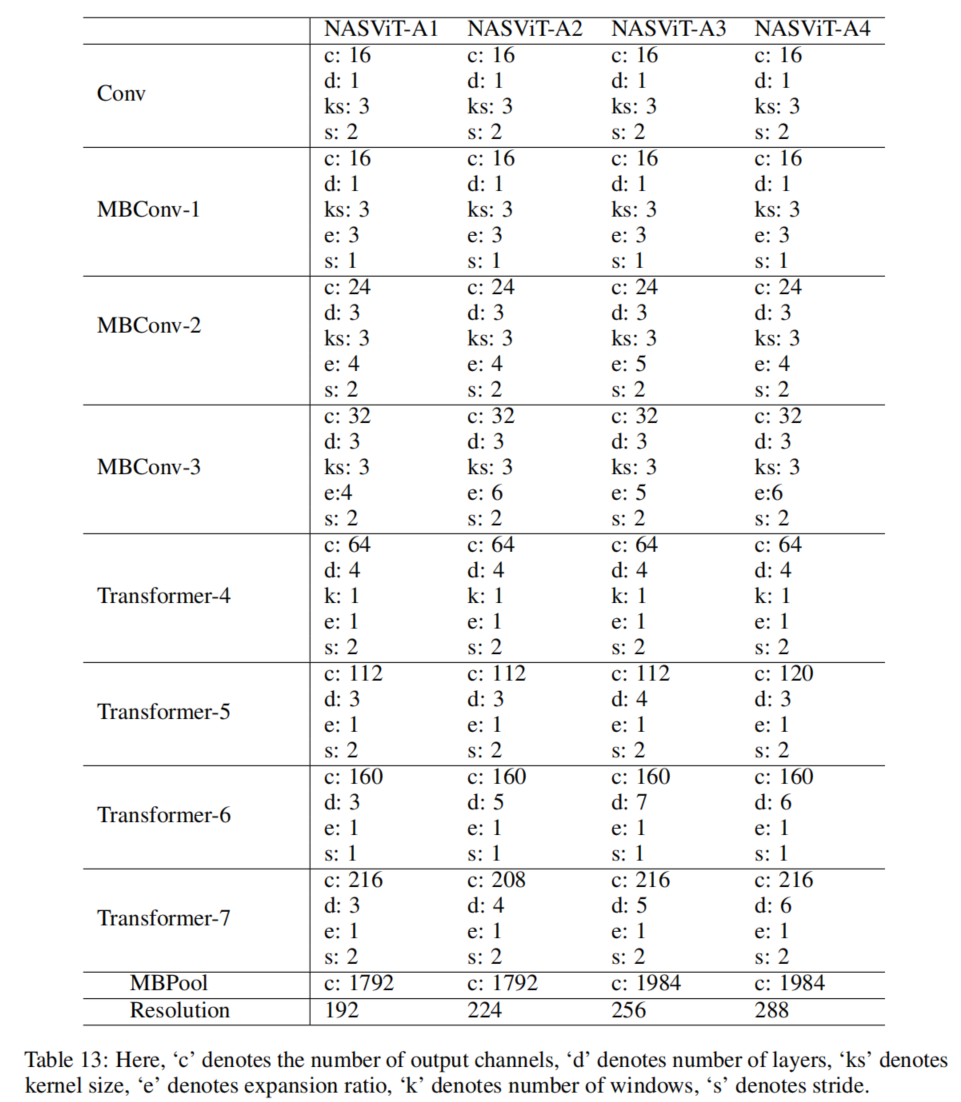
5、NASViT架构细节
3实验结果
4参考文献
[1].NASVIT:NEURAL ARCHITECTURE SEARCH FOR EFFICIENT VISION TRANSFORMERS WITH GRADIENT CONFLICT-AWARE SUPERNET TRAINING
5推荐阅读
超越 Swin、ConvNeXt | Facebook提出Neighborhood Attention Transformer
CVPR2022 Oral | CosFace、ArcFace的大统一升级,AdaFace解决低质量图像人脸识
CenterNet++ | CenterNet携手CornerNet终于杀回来了,实时高精度检测值得拥有!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
