
挑战英伟达H100霸权!IBM模拟人脑造神经网络芯片,效率提升14倍,破解AI模型耗电难题

新智元报道
新智元报道
编辑:Aeneas Lumina
【新智元导读】最近,IBM推出一款14nm模拟AI芯片,能效已达最先进GPU的14倍。英伟达的芯片垄断,或许有望被打破了?
最近,IBM推出一款全新的14nm模拟AI芯片,效率达到了最领先GPU的14倍,可以让H100物有所值。

论文地址:https://www.nature.com/articles/s41928-023-01010-1
目前,生成式AI发展道路上最大的拦路虎,就是它惊人的耗电量。AI所需的资源,是不可持续增长的。
而IBM,一直在研究重塑AI计算的方法。他们的一大成就,就是模拟内存计算/模拟人工智能方法,就可以借助神经网络在生物大脑中运行的关键特征,来减少能耗。
这种方法,可以最大限度地减少我们在计算上花费的时间和精力。
英伟达的垄断,要被颠覆了?

IBM AI未来的最新蓝图:模拟AI芯片能效高出14倍
根据外媒Insider的报道,半导体研究公司SemiAnalysis的首席分析师Dylan Patel分析,ChatGPT每天的运行成本超过了70万美元。
ChatGPT需要大量算力,才能根据用户的提示生成回答。绝大部分成本,都是在昂贵的服务器上产生的。
在往后,训练模型和运行基础设施的成本只会越来越飙升。

IBM在Nature上发文表示,这款全新芯片能够通过削减能耗,来缓解构建和运营Midjourney或GPT-4等生成式AI企业的压力。
这些模拟芯片与数字芯片有不同的构建方式,数字芯片可以操作模拟信号,理解0到1之间的渐变,但只适用于不同的二进制信号。
模拟内存计算/模拟AI
而IBM的全新方法,就是模拟内存计算,或简称模拟AI。它借助神经网络在生物大脑中运行的关键特征,来减轻了能耗。
在人类和其他动物的大脑中,突触的强度(或「权重」)决定了神经元之间的交流。
对于模拟AI系统,IBM将这些突触权重存储在纳米级电阻存储器器件(如相变存储器PCM)的电导值中,并利用电路定律,减少在存储器和处理器之间不断发送数据的需求,执行乘法累加(MAC)运算——DNN中的主要运算。
现在为很多生成式AI平台提供动力的,是英伟达的H100和A100。
然而,如果IBM对芯片原型进行迭代,并且成功推向了大众市场,这种新型芯片就很有可能取代英伟达,成为全新的支柱。
这款14nm模拟AI芯片,可以为每个组件编码3500万个相变存储设备,可以模拟多达1700万个参数。
并且,这款芯片模仿了人脑的运作方式,由微芯片直接在内存中执行计算。
这款芯片的系统能够实现高效的语音识别和转录,准确性接近了数字硬件设施。
而这款芯片大约达到了14倍,而之前的模拟表明,这种硬件的能效甚至达到了当今最领先GPU的40倍到140倍。
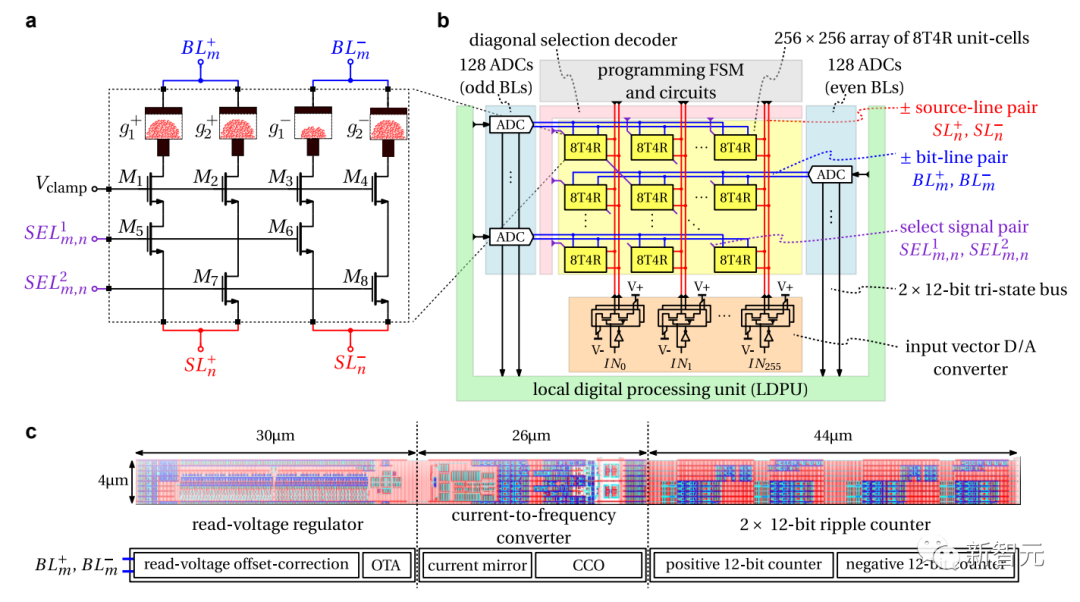
PCM交叉开关阵列、编程与数字信号处理
这场生成式AI革命,才刚刚开始。而深度神经网络(DNN)彻底改变了AI领域,随着基础模型和生成式AI的发展而日益突出。
然而,在传统的数学计算架构上运行这些模型,会限制它们的性能和能源效率。
虽然在开发用于AI推理的硬件方面,也取得了不少进展,但其中许多架构,在物理上拆分了内存和处理单元。
这就意味着,AI模型通常存储在离散的内存位置,要完成计算任务,就需要在内存和处理单元之间不断打乱数据。这个过程会大大减慢计算速度,限制可实现的最大能效。
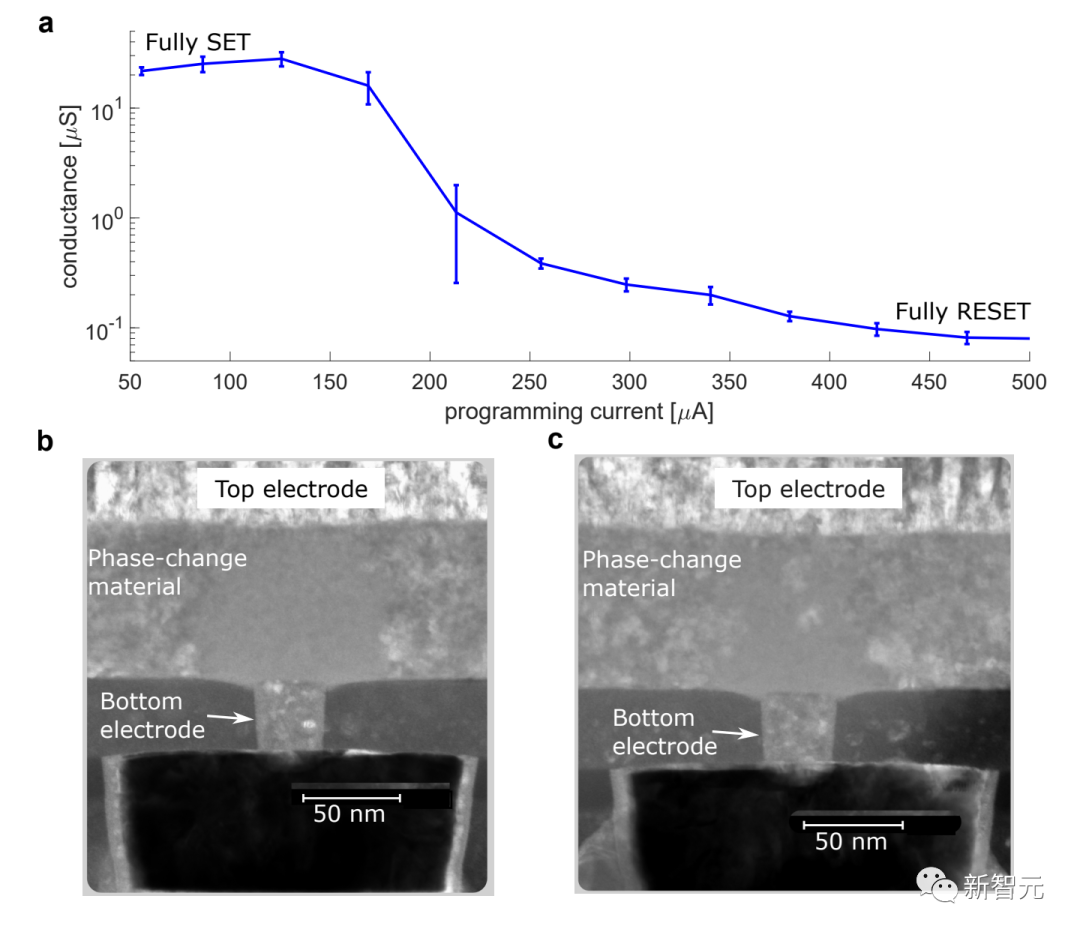
PCM设备的性能特点、使用相位配置和导纳来存储模拟式的突触权重
IBM的基于相变存储器(PCM)的人工智能加速芯片,摆脱了这种限制。
相变存储器(PCM)可以实现计算存储融合,在存储器内直接进行矩阵向量乘法,避免了数据传输的问题。
同时,IBM的模拟AI芯片通过硬件级的计算存储融合,实现了高效的人工智能推理加速,是这一领域的重要进展。
模拟AI的两大关键挑战
为了将模拟AI的概念变为现实,需要克服两个关键挑战:
1. 存储器阵列的计算精度必须与现有数字系统相当
2. 存储器阵列能与其他数字计算单元以及模拟人工智能芯片上的数字通信结构无缝对接
IBM在Albany Nano的技术中心制造了着这种基于相变内存的人工智能加速芯片。
该芯片由64个模拟内存计算内核组成,每个内核包含256×256的交叉条阵突触单元。
并且,每个芯片中都集成了紧凑的时基模数转换器,用于在模拟和数字世界之间进行转换。
而芯片中的轻量级数字处理单元,也可执行简单的非线性神经元激活函数和缩放操作。
每个核心可看作一个tile,可以进行与深度神经网络(DNN)模型的一个层(比如卷积层)相关的矩阵向量乘法及其他运算。
权重矩阵被编码成PCM器件的模拟电导值存于芯片上。
在芯片的核心阵列中间集成了一个全局数字处理单元,用来实现一些比矩阵向量乘法更复杂的运算,这对某些类型的神经网络(如LSTM)执行是关键的。
芯片上在所有核心以及全局数字处理单元之间集成了数字通信通路,用于核心之间以及核心与全局单元之间的数据传输。
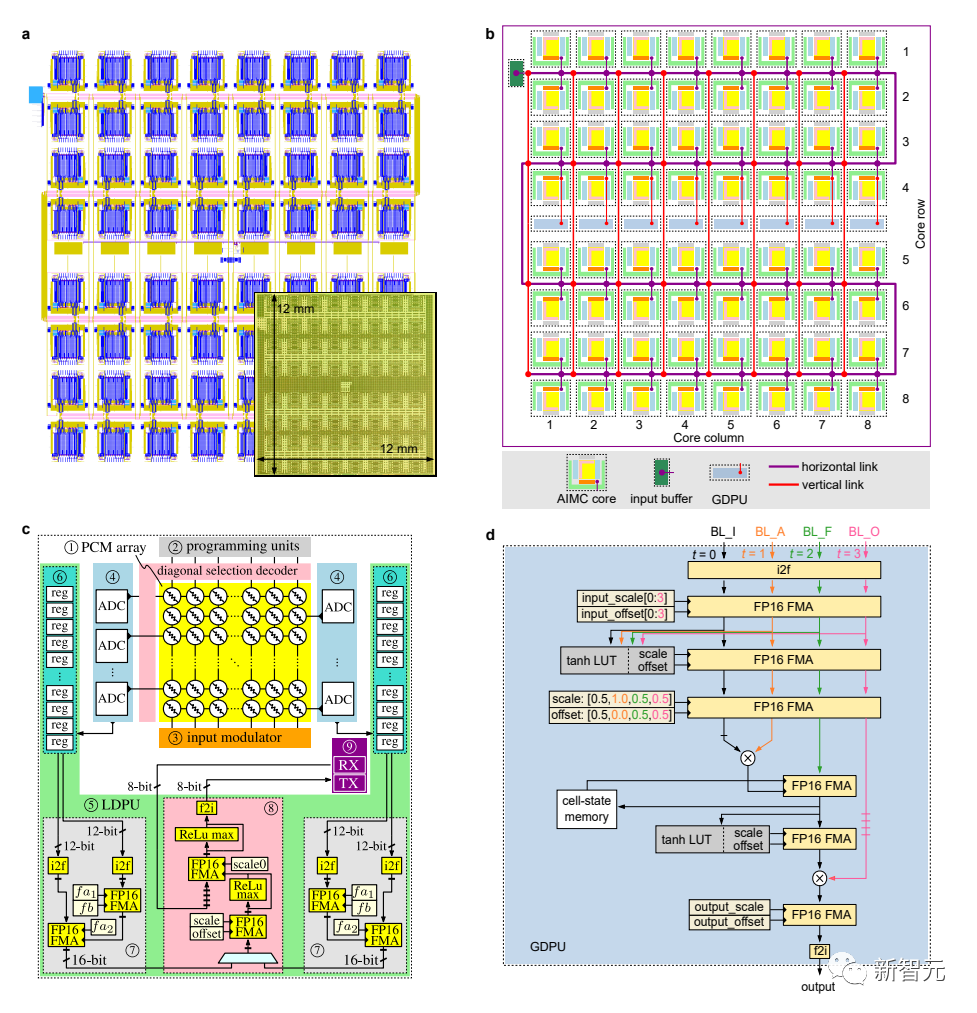
a:电子设计自动化快照和芯片显微图,可以看到64个核心和5616个pad
b:芯片不同组件的示意图,包括64个核心、8个全局数字处理单元和核心间的数据链路
c:单个基于PCM的内存计算核心的结构
d:全局数字处理单元的结构,用于LSTM相关计算
利用该芯片,IBM对模拟内存计算的计算精度进行了全面的研究,并在CIFAR-10图像数据集上获得了92.81%的精确度。
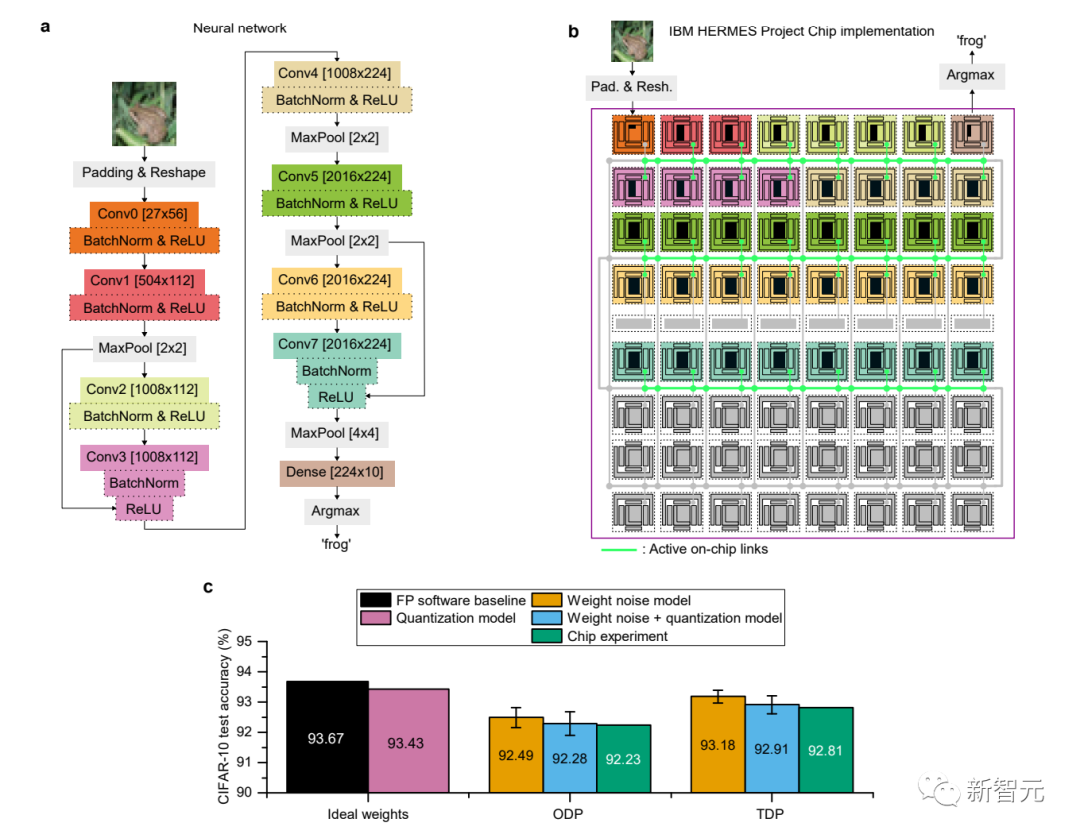
a:用于CIFAR-10的ResNet-9网络结构
b:将该网络映射到芯片上的方式
c:硬件实现的CIFAR-10测试精度
这是目前所报道的使用类似技术的芯片中精度最高的。
IBM还将模拟内存计算与多个数字处理单元和数字通信结构无缝结合。
该芯片8位输入输出矩阵乘法的单位面积吞吐量为400 GOPS/mm2,比以前基于电阻式存储器的多核内存计算芯片高出15倍以上,同时实现了相当的能效。
而在字符预测任务和图像标注生成任务中,IBM通过在硬件上测量的结果与其他方法的比较,展示了相关任务在模拟AI芯片上运行的网络结构、权重编程以及测量结果的信息。
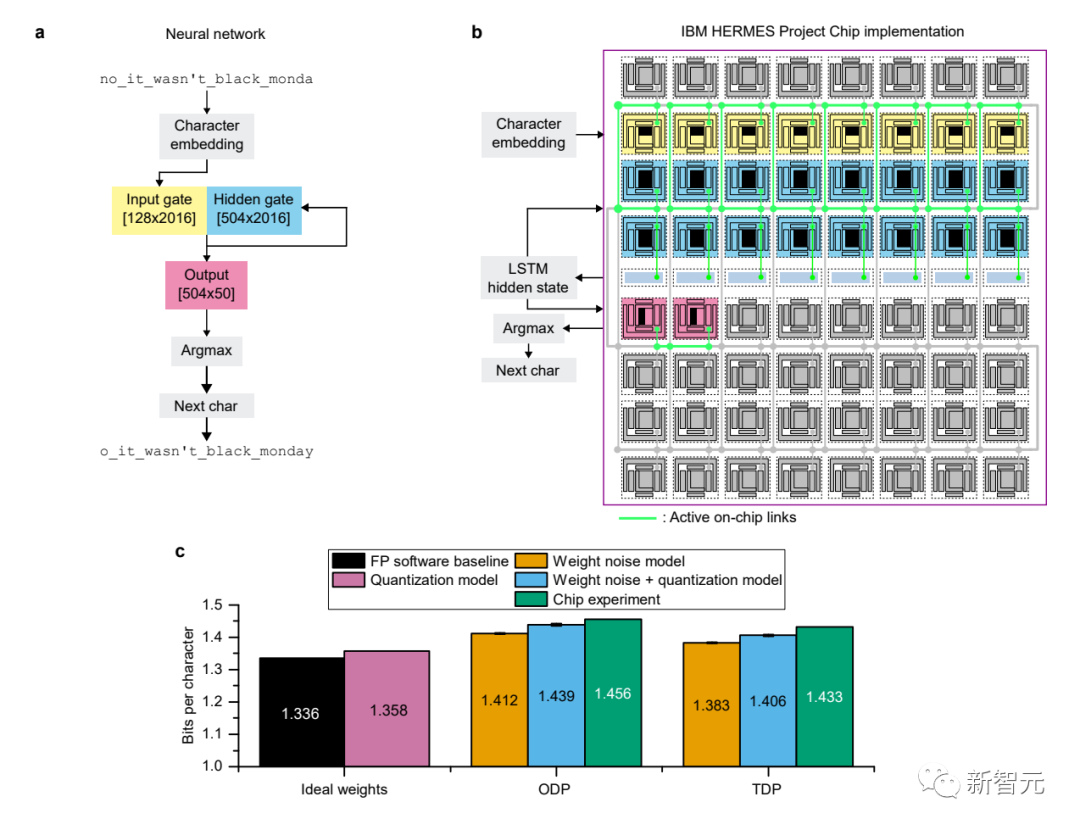
用于字符预测的LSTM测量结果
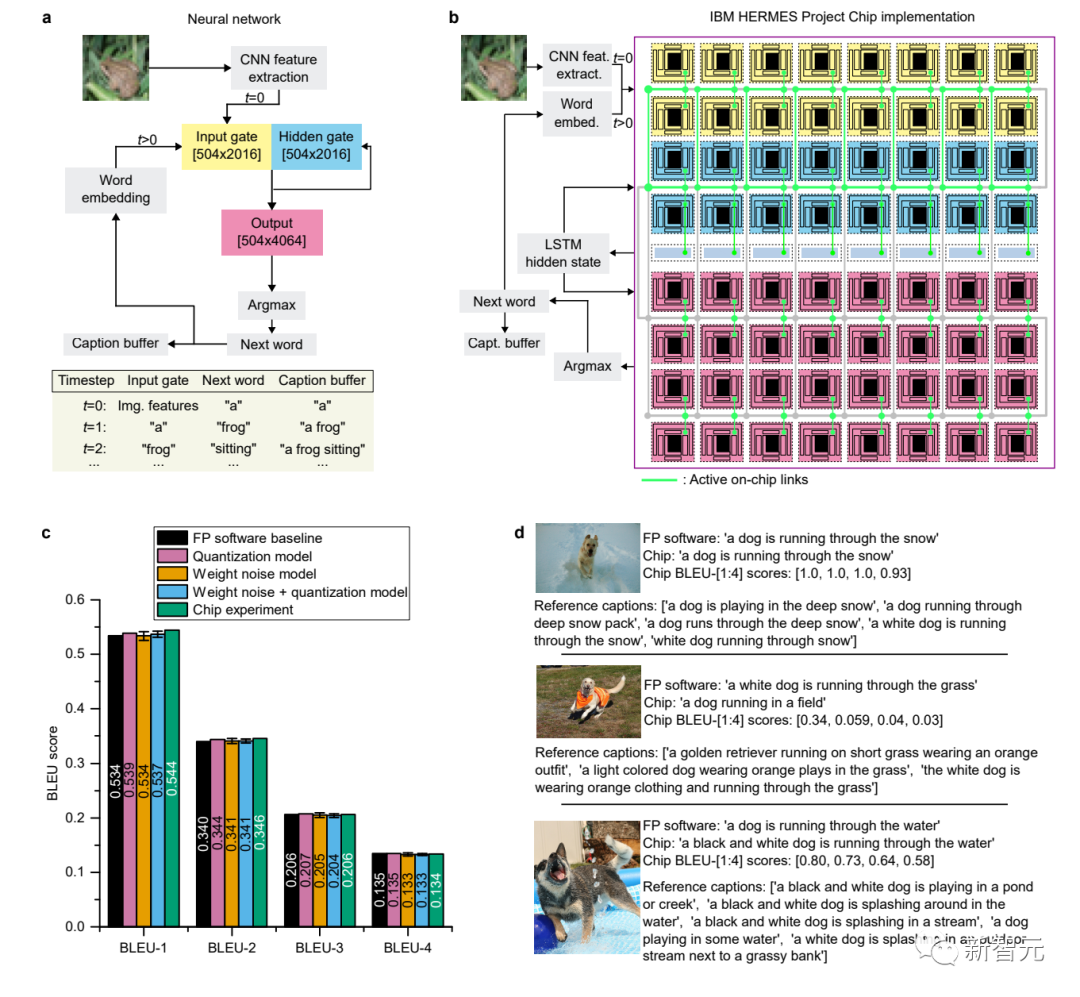
用于图像标注生成的LSTM网络测量结果
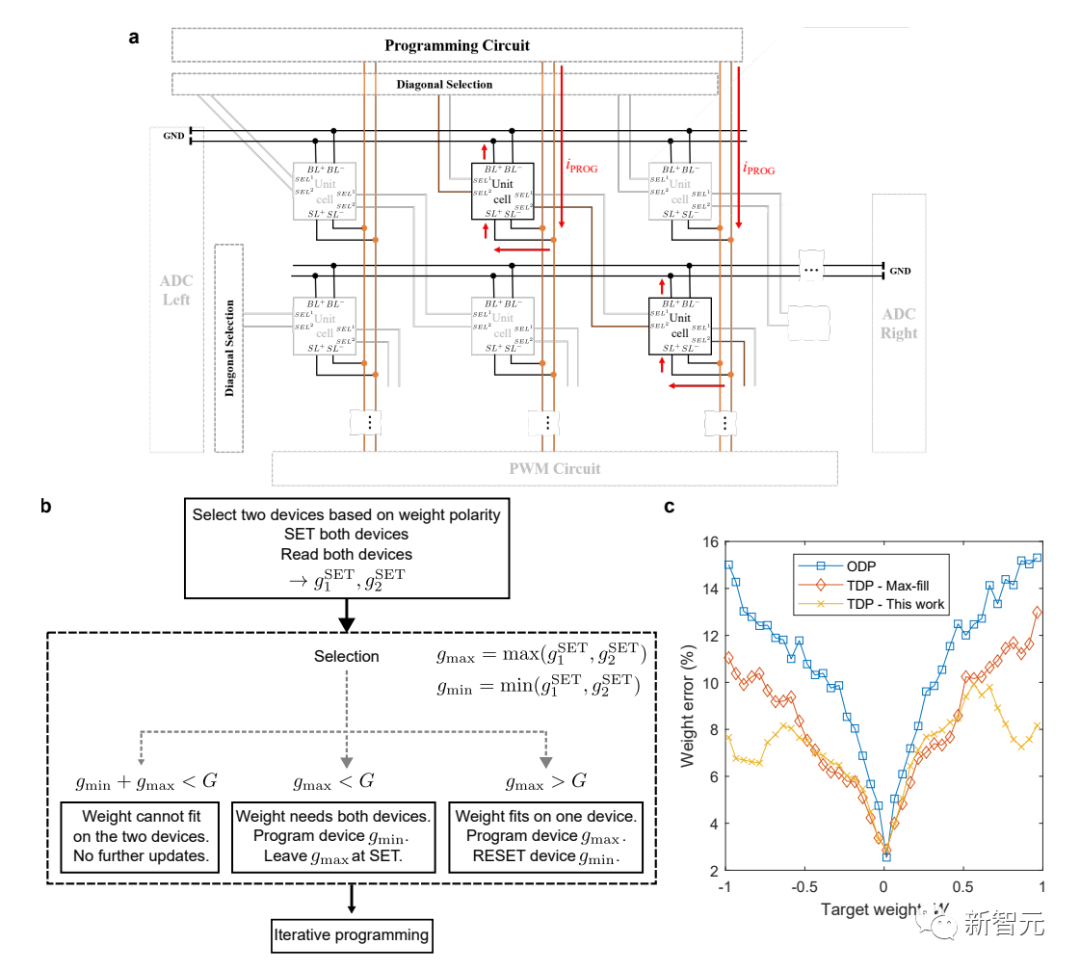
权重编程过程
英伟达的护城河深不见底?
英伟达的垄断,有这么容易打破吗?
Naveen Rao是一名神经科学出身的科技企业家,他曾试图与全球领先的人工智能制造商英伟达竞争。
「每个人都是基于英伟达进行开发的。」Rao说,「如果你想推出新的硬件,你就得赶上去和英伟达竞争。」
Rao在英特尔收购的一家初创企业中致力开发旨在取代英伟达GPU的芯片,但在离开英特尔后,他在自己领导的软件初创公司MosaicML里使用了英伟达的芯片。
Rao表示,英伟达不仅在芯片上与其他产品拉开了巨大的差距,还通过创建一个大型的AI程序员社区,实现了芯片之外的差异化——
AI程序员一直在使用该公司的技术进行创新。

十多年来,英伟达在生产能够执行复杂AI任务(如图像、面部和语音识别)以及为ChatGPT等聊天机器人生成文本的芯片方面,建立了几乎无法撼动的领先地位。
这家曾经的行业新贵之所以能够取得AI芯片制造的主导地位,是因为它很早就认识到了AI发展的趋势,为这些任务专门定制了芯片,并开发了促进AI开发的关键软件。
从那时起,英伟达的联合创始人兼CEO黄仁勋,就在不断地提高英伟达标准。

这使得英伟达成为了人工智能开发的一站式供应商。
据研究公司Omdia调查,虽然谷歌、亚马逊、Meta、IBM和其他公司也生产人工智能芯片,但到目前,英伟达占人工智能芯片销售额的70%以上。
今年6月,英伟达的市值已突破1万亿美元,成为全球市值最高的芯片制造商。
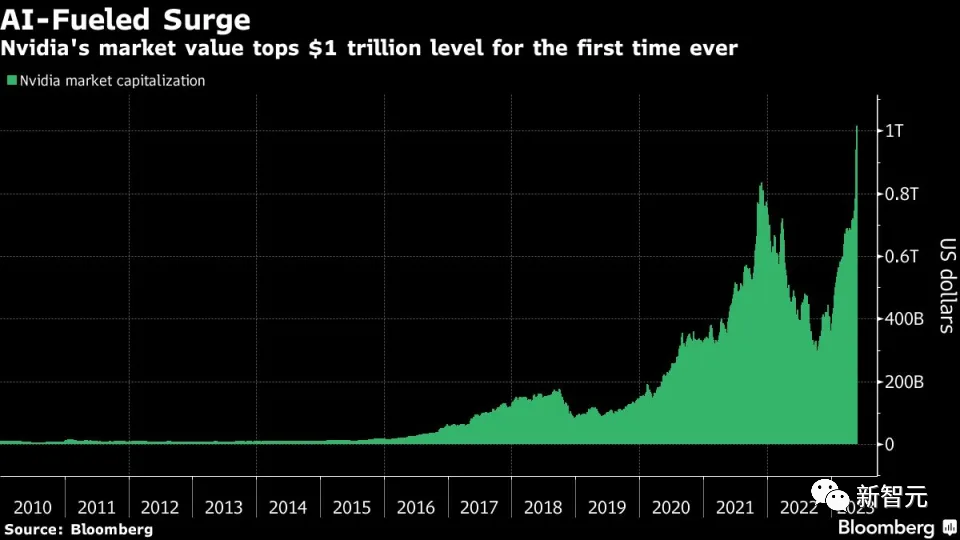
FuturumGroup分析师表示:「客户会等18个月才购买英伟达系统,而不是从初创企业或其他竞争对手那里购买现成的芯片。这太不可思议了。」
英伟达,重塑计算方式
1993年,黄仁勋联合创立了英伟达,主要的业务是制造在电子游戏中渲染图像的芯片。当时的标准微处理器擅长按顺序执行复杂的计算,但英伟达生产的GPU可以同时处理多个简单任务。
2006年,黄仁勋进一步推进了这一进程。他发布了名为CUDA的软件技术,该技术可帮助GPU为新任务编程,使GPU从单一用途的芯片转变为更通用的芯片,能承担物理和化学模拟等领域的其他工作。
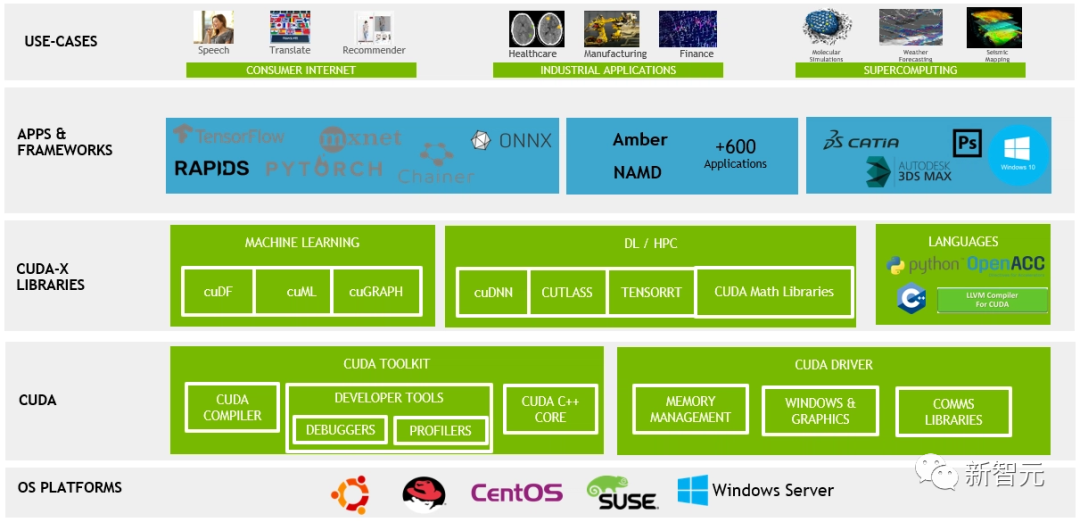
2012年,研究人员利用GPU在识别图像中的猫等任务中实现了与人类相似的准确度,这是一项重大突破,也是根据文本提示生成图像等最新发展的先驱。
而据该英伟达估计,这项工作在十年间耗资超过300亿美元,使英伟达不再仅仅是一个零部件供应商。除了与顶尖科学家和初创企业合作,公司还组建了一支团队,直接参与人工智能活动,如创建和训练语言模型。
此外,从业者的需要导致英伟达开发了CUDA以外的多层关键软件,其中也包括数百条预构建代码的库。
在硬件方面,英伟达因每两三年就能持续提供更快的芯片而赢得声誉。2017年英伟达开始调整GPU以处理特定的AI计算。
去年9月,英伟达宣布生产名为H100的新型芯片,并对其进行了改进,以处理所谓的Transformer运算。这种运算被证明是ChatGPT等服务的基础,黄仁勋称之为生成式人工智能的「iPhone时刻」。

如今,除非有其他厂家的产品能和英伟达的GPU形成正面竞争,才有可能打破目前英伟达对AI算力的垄断格局。
IBM的模拟AI芯片,有这个可能吗?
参考资料:
https://research.ibm.com/blog/analog-ai-chip-inference



评论