
用Python分析18万条《八佰》影评,看看观众怎么说?
大邓和他的Python
共 7879字,需浏览 16分钟
· 2020-09-19

数据获取
def parse_page(html):
try:
data = json.loads(html)['cmts'] # 将str转换为json
#print(data)
comments = []
for item in data:
comment = {
'id': item['id'],
'nickName': item['nickName'],
'cityName': item['cityName'] if 'cityName' in item else '', # 处理cityName不存在的情况
'content': item['content'].replace('\n', ' ', 10), # 处理评论内容换行的情况
'score': item['score'],
'startTime': item['startTime']
}
comments.append(comment)
return comments
except Exception as e:
pass
数据清洗
读取影评数据
import pandas as pd
import numpy as np
data=[]
with open('comments.txt', 'r',encoding='utf-8-sig') as f_input:
for line in f_input:
data.append(list(line.strip().split(',')))
data
转为DataFrame并添加列名
df = pd.DataFrame(data).iloc[:, 0:6]
df.columns = ['观众ID','观众昵称','城市','评论内容','评分','评论时间']
删除重复记录和缺失值
df = df.drop_duplicates()
df = df.dropna()
预览并保存
df.sample(5)
df.to_csv("八佰.csv",index=False,encoding="utf_8_sig")

数据可视化
导入相关库
import jieba
import re
import matplotlib.pyplot as plt
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import stylecloud
from IPython.display import Image
整体评论词云
data = pd.read_csv("八佰.csv")
data['评论内容'] = data['评论内容'].astype('str')
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['', '']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['电影', '中国','一部']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 绘制词云图
text1 = get_cut_words(content_series=data['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=500,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-square',
size=653,
#palette='matplotlib.Inferno_9',
output_name='./1.png')
Image(filename='./1.png')

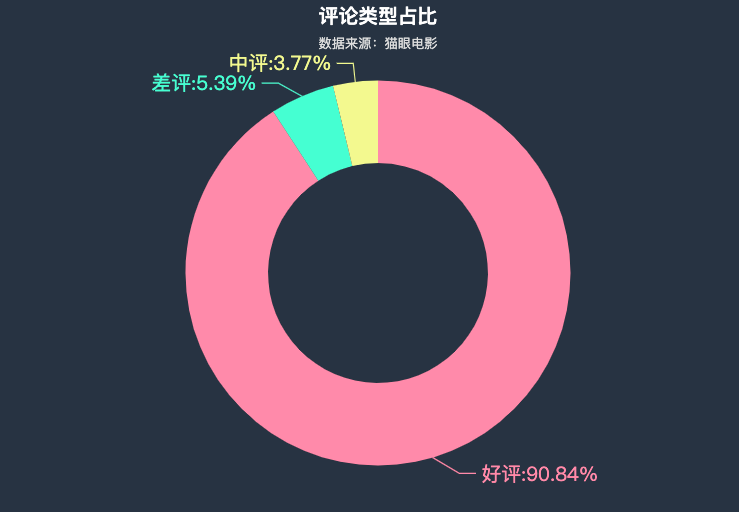
评论类型分布
data['评论类型'] = pd.cut(data['评分'],[0,3,4,6],labels=['差评','中评','好评'],right=False)
df1 = data.groupby('评论类型')['评论内容'].count()
df1 = df1.sort_values(ascending=False)
regions = df1.index.to_list()
values = df1.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add("", zip(regions,values),radius=["40%", "70%"])
.set_global_opts(title_opts=opts.TitleOpts(title="评论类型占比",subtitle="数据来源:猫眼电影",pos_top="0.5%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18))
)
c.render_notebook()
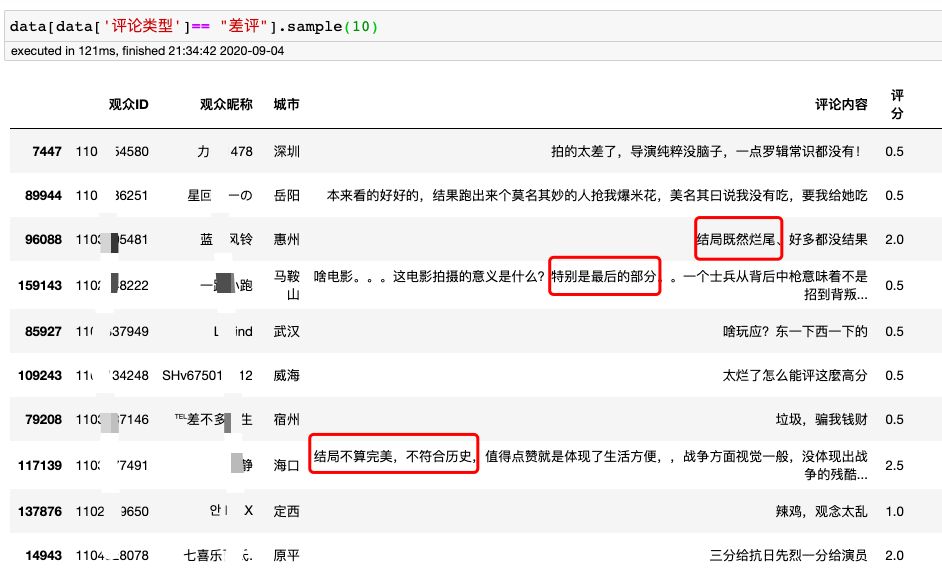
差评抽样
评论数据量TOP10城市
df2 = data.groupby('城市')['评分'].count() #按菜系分组,对评分求平均
df2 = df2.sort_values(ascending=False)[:10]
# print(df2)
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
bar.add_xaxis(df2.index.to_list())
bar.add_yaxis("",df2.to_list()) #X轴与y轴调换顺序
bar.set_global_opts(title_opts=opts.TitleOpts(title="城市影评数量TOP10",subtitle="数据来源:猫眼电影",pos_top="2%",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
bar.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='top'))
bar.render_notebook()

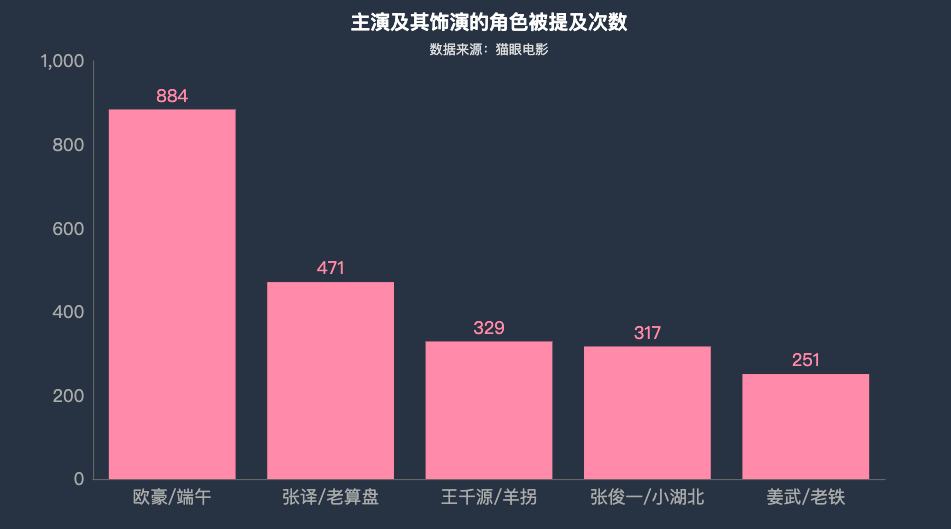
相关演员提及
result = []
for i in data['评论内容']:
result.append(re.split('[::,,.。!!~·`\;;……、]',i))
def actor_comment(data,result):
actors = pd.DataFrame(np.zeros(5 * len(data)).reshape(len(data),5),
columns = ['欧豪/端午','王千源/羊拐','姜武/老铁','张译/老算盘','张俊一/小湖北'])
for i in range(len(result)):
words = result[i]
for word in words:
if '端午' in word or '欧豪' in word:
actors.iloc[i]['欧豪/端午'] = 1
if '羊拐' in word or '王千源' in word:
actors.iloc[i]['王千源/羊拐'] = 1
if '老铁' in word or '姜武' in word:
actors.iloc[i]['姜武/老铁'] = 1
if '老算盘' in word or '张译' in word:
actors.iloc[i]['张译/老算盘'] = 1
if '小湖北' in word or '张俊一' in word:
actors.iloc[i]['张俊一/小湖北'] = 1
final_result = pd.concat([data,actors],axis = 1)
return final_result
df3 = actor_comment(data,result)
df3.sample(5)
df4 = df3.iloc[:,7:].sum().reset_index().sort_values(0,ascending = False)
df4.columns = ['角色','次数']
df4['占比'] = df4['次数'] / df4['次数'].sum()
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add_xaxis(df4['角色'].to_list())
.add_yaxis("",df4['次数'].to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="主演及其饰演的角色被提及次数",subtitle="数据来源:猫眼电影",pos_top="2%",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='top'))
)
c.render_notebook()
关于端午的评论
ouhao = df3.loc[df3['欧豪/端午'] == 1,]
text = get_cut_words(content_series=ouhao['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text), max_words=500,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-camera',
#palette='matplotlib.Inferno_9',
size=653,
output_name='./ouhao.png')
Image(filename='./ouhao.png')

关于老算盘的评论
zhangyi = df3.loc[df3['张译/老算盘'] == 1,]
text = get_cut_words(content_series=zhangyi['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text), max_words=500,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-video',
#palette='matplotlib.Inferno_9',
size=653,
output_name='./zhangyi.png')
Image(filename='./zhangyi.png')

关于羊拐的评论
wangqianyuan = df3.loc[df3['王千源/羊拐'] == 1,]
text = get_cut_words(content_series=wangqianyuan['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text), max_words=500,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-thumbs-up',
#palette='matplotlib.Inferno_9',
size=653,
output_name='./wangqianyuan.png')
Image(filename='./wangqianyuan.png')

近期文章
Python网络爬虫与文本数据分析 rpy2库 | 在jupyter中调用R语言代码 tidytext | 耳目一新的R-style文本分析库 reticulate包 | 在Rmarkdown中调用Python代码 plydata库 | 数据操作管道操作符>> plotnine: Python版的ggplot2作图库 七夕礼物 | 全网最火的钉子绕线图制作教程 读完本文你就了解什么是文本分析 文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用 plotnine: Python版的ggplot2作图库 小案例: Pandas的apply方法 stylecloud:简洁易用的词云库 用Python绘制近20年地方财政收入变迁史视频 Wow~70G上市公司定期报告数据集 漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
评论
英伟达Blackwell平台网络配置分析
本文来自“英伟达Blachwell平台网络配置详解”。GTC大会英伟达展示了全新的 Blackwell 平台系列产品,包括 HGX B100 服务器、NVLINK Switch、GB200Superchip Computer Node、Quantum X800 交换机和 CX8 网卡(InfiniB
架构师技术联盟
0
人工智能周刊#18:微软发布手机端大模型、Llama 3 中文模型列表、苹果开源新项目、
主打尊重隐私的搜索引擎 duckduckgo,也推出了 ai chat 服务,可以使用 chatgpt 或者 claude机器学习周刊:关注 Python、机器学习、深度学习、大模型等硬核技术本期目录:1、Qwen1.5-110B:Qwen1.5 系列的首个千亿参数开源模型2、苹果开源
机器学习算法与Python实战
0
谷歌员工爆料 Python 基础团队原地解散
转自 | 机器之心编辑 | 蛋酱什么?谷歌解雇了整个 Python 基础团队?「当与你直接共事的每个人,包括你的主管,都被裁员 —— 哦,是职位被削减,而你被要求安排他们的替代者入职,这些人被告知在不同的国家担任同样的职位,但他们并不为此感到高兴,这是很艰难的一天。」发布这一动态的 Tho
机器学习算法与Python实战
0
五一抢票难,Github上这几个Python项目,你可以试试
又到五一长假啦(虽然其实就放了1天),大家是打算家里蹲or出去玩,又或者是在公司加班呢...今天给大家介绍三个和12306相关的项目,看看你是否用得上。/01/ py12306py12306购票助手,顾名思义,12306买票的~需要在python 3.6以上版本运行程序。1. 安装依赖gi
Crossin的编程教室
0
谷歌员工爆料Python基础团队原地解散
机器之心报道编辑:蛋酱什么?谷歌解雇了整个 Python 基础团队?「当与你直接共事的每个人,包括你的主管,都被裁员 —— 哦,是职位被削减,而你被要求安排他们的替代者入职,这些人被告知在不同的国家担任同样的职位,但他们并不为此感到高兴,这是很艰难的一天。」发布这一动态的 Thomas Wouter
机器学习初学者
0
Python加速运行技巧
Python 是一种脚本语言,相比 C/C++ 这样的编译语言,在效率和性能方面存在一些不足。但是,有很多时候,Python 的效率并没有想象中的那么夸张。本文对一些 Python 代码加速运行的技巧进行整理。 0. 代码优化原则 本文会介绍不少的 Python 代码加速运行的技巧。在深入代码优化细
机器学习算法与Python实战
0
为什么我们公司还在用 Python 开发项目?
作者:哇哒嘻哇https://www.zhihu.com/question/278798145/answer/3416549119最近几年里,经常看到某些曾重度使用 Python 的大公司迁移成其它语言技术栈,但是,那些小公司/小团队的情况如何呢?一直很想了解那些仍在坚持使用 Python,且支撑业
机器学习算法与Python实战
0
用 Shader 实现旗帜飘扬动画效果
我觉得对于刚入门 3D 编程的朋友来说,如果能够完成代码创建模型数据->创建材质->编写Shader动画这一系列,想必会有满满的成就感。今天就用 Cocos Creator 的 utils.MeshUtils.createMesh 接口,带大家感受一下这个流程。这个流程不仅可以用于新手学
COCOS
2