
Promethues 的 Agent 模式:高效转发云原生指标
Bartek Plotka 是红帽的首席软件工程师,从 2019 年开始担任 Prometheus 项目的维护者,也是 CNCF Thanos 项目的共同作者之一,同时还担任 CNCF 大使以及 CNCF 可观察性 TAG 的技术领导者。他在业余和 O’Reilly 出版了《Efficient Go》一书。

社区提供了包罗万象的 Exporter,例如容器、eBPF、我的世界甚至还有针对园艺的健康监测; 现在多数 CNCF 项目都会提供基于 HTTP/HTTPS 的 /metrics端点,让 Prometheus 可以读取指标数据。这原本是 Google 内部秘而不宣的一个概念,Prometheus 项目将其公诸于世; 可观察性的范式发生了变化。 从一开始 SRE 和开发者就非常依赖指标数据,对软件的韧性、排障能力以及数据驱动的决策过程产生了很好的推动作用
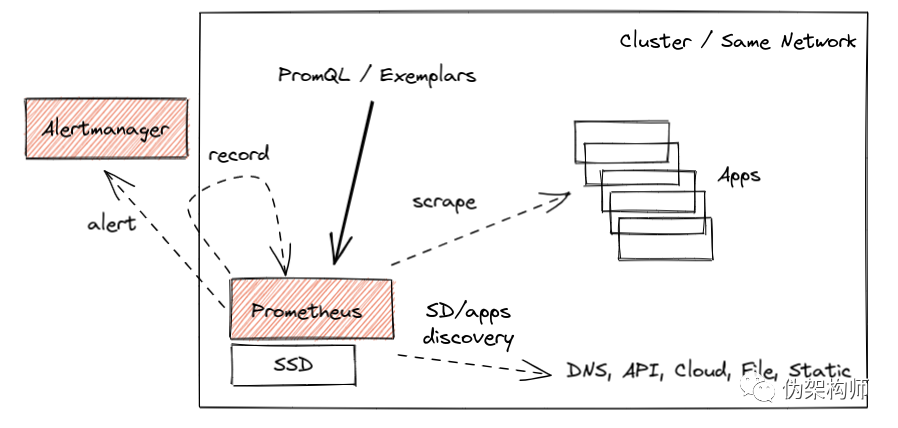
Serverless 应用以及类似的短寿命容器经常会让我们将远端推送方式当做救命稻草。这种情况下我们希望把细碎的事件和指标能够聚合到一个较长存活期的时间序列里。我们对这一主题也进行了讨论,欢迎加入,一起完善这个方案。
联邦:这是第一种用于聚合目的的方案。这种方案里,全局级的 Prometheus 服务器或从基层 Prometheus 中抓取指标的子集。这种级联方式里,联邦节点暴露的指标中包含了原始采样的时间戳,因此降低了跨网络抓取的风险,但是如果网络间的时延达到分钟级,可能就无法在不损失数据的情况下完成数据联合了。 Prometheus 远程读取:从远端 Prometheus 服务器的数据库中绕过 PromQL,直接提取原始数据。可以在全局一级部署 Prometheus 或者 Thanos 方案,用抓取自多个站点的远程数据来执行 PromQL 查询。这种方式很强大——数据存储在“本地”,还可以按需访问。不幸的是,这种方式也有缺点,如果没有 Query Pushdown,一个简单的查询可能就要拉取上 GB 的压缩数据。类似地,如果网络失联,服务就不可用了,另外有些集群只允许 Egress,禁止 Ingress 最后一种就是远程写入:这似乎是目前最流行的选择。Agent 模式也是聚焦于远程写入的,因此我们要详细描述一下这个模式
但是 Bartek 你刚刚说过,从应用推送指标不是个好主意!
Katacoda 教程:远程写入
Prometheus 的 Agent 模式
--enable-feature=agent 来启动启动 Prometheus。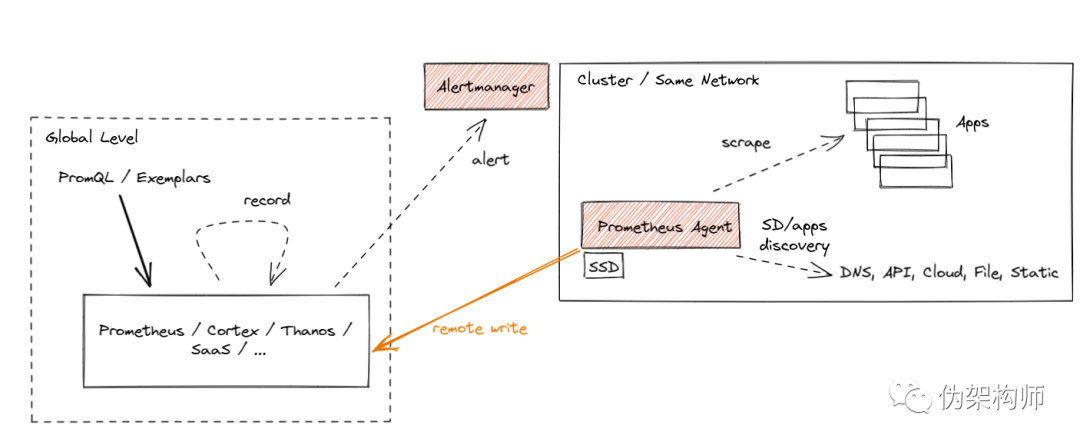
Agent 模式是针对特定使用场景的,标准模式的 Promethues Server 更稳定、更易维护,仍是缺省建议;Agent 模式的远端存储引入了更高的复杂性,还需谨慎使用。
指标接收端的弹性伸缩
Agent 模式得到了大规模验证
main 分支。--help 参数)内容中会看到类似内容:usage: prometheus [ ]
The Prometheus monitoring server
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
(... other flags)
--storage.tsdb.path="data/"
Base path for metrics storage. Use with server mode only.
--storage.agent.path="data-agent/"
Base path for metrics storage. Use with agent mode only.
(... other flags)
--enable-feature= ... Comma separated feature names to enable. Valid options: agent, exemplar-storage, expand-external-labels, memory-snapshot-on-shutdown, promql-at-modifier, promql-negative-offset, remote-write-receiver,
extra-scrape-metrics, new-service-discovery-manager. See https://prometheus.io/docs/prometheus/latest/feature_flags/ for more details.
--enable-feature=agent 参数的启用的。这种模式下能够使用同样的指标抓取配置以及远程写入能力。Agent 模式下,Web UI 的查询功能是被禁用的,只能用于展示构建信息、配置内容、抓取指标和服务发现信息。在 Katacoda 上尝试 Prometheus Agent

评论