
铺天盖地云原生,什么才是真正的云原生数据仓库?

点击可观看精彩演讲视频
一、云原生数据仓库的背景与定义
今天的主要内容首先是简单介绍云原生数据仓库的背景,定义云原生数据仓库,然后是讲常见的云原生数据仓库的架构,包括架构的演进及应用场景。
1. 数据平台的技术变革历程
从大数据或数据分析的角度看,数据平台的发展经历过四个阶段,最早期的阶段是最传统的关系型数据库阶段,当时关系型数据库刚刚兴起,做信息化等早期的一些系统。后来在1990年左右,出现很多数据仓库。在2000年左右出现了大数据相关的一些系统,包括现在大家比较熟悉的Hadoop,当年我们做的Greenplum等。2015年之后,随着云的发展,出现了新一代的云原生数据仓库,我们称为智能数据云平台的阶段。每个阶段关注的点其实不太一样,环境、应用出现变化的时候,里面的技术架构也出现了一些大的变革,之后会详细介绍。
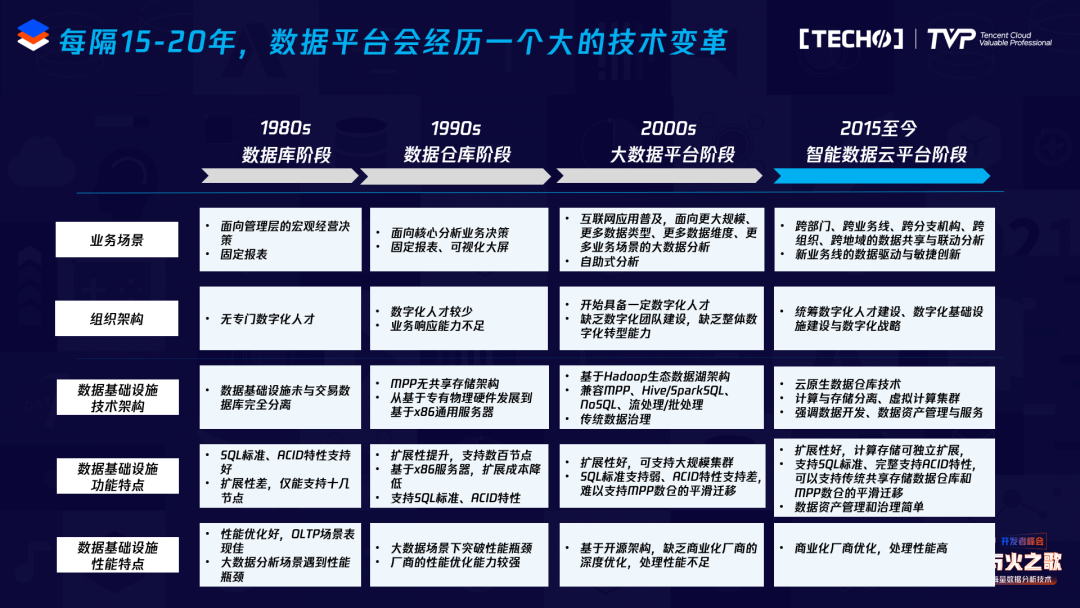
这几个阶段的技术有很大的区别,我主要集中于分析型数据库来介绍。现在很多用户做交易、分析,如果数据量不是特别大,用一个简单的交易型数据库就可以,比如传统的Oracle、DB2等。最早期这些基本都是共享存储的系统,共享存储的架构的可扩展性不好,只能到十几个节点,性能相对来说比较差。
后面在八十年代,当时Teradata做MPP的一体机,相当于软硬一体,后面出现的MPP基本都是基于普通的X86服务器的,架构变化不大,基本是一种无共享的架构,节点之间通过万兆网络连接。这一代的特点也很明显,它易于使用,性能也较好,但有一个较大的缺点:计算和存储是耦合的,如果要做扩容,计算和存储必须都得扩,它的可扩展性受到一定的限制,一般只能到上百个节点或者几百个节点,基本做不到再往上扩。
后面出现了Hadoop,当年我做的HAWQ其实是一个SQL-on-Hadoop引擎,其实有很多都可以叫SQL-on-Hadoop引擎,比如Hive、SparkSQL等等。但现在也在演化。SQL-on-Hadoop引擎有好处,它的集群规模可以做得很大,但也有一些缺点,比如SQL-on-Hadoop计算和存储不是完全分离的。在逻辑上它是分离的,计算是计算层,存储是HDFS,但是物理上大家在部署的时候基本还是把计算和存储部署在一起。Hadoop很大的一个缺点是它的并发性不是很好,比如Hive等等,并发高之后导致性能上不去,很难支持非常高并发的场景,性能角度来看比MPP还是差一些。
再之后,在2015年左右出现了云原生架构,随着云的发展,存储在云上转向对象存储,相对HDFS来说对象存储会便宜一些,但性能较差。在云上如果自己再搭建一个HDFS,运维成本较高,所以大家在做云原生架构的时候,存储基本就用云上的对象存储,在私有环境底下当然没关系,在物理机上可以用其他的存储;在公有云上,上面的计算完全是分隔的,这样就可以做到计算、存储可独立扩容。
2. 云原生 ✕ 数据库 = 云原生数据库
现在说云原生的概念,比如CNCF的概念,一般都是偏应用视角的定义。我之前在的EMC是提云原生概念最早的公司,主要是从敏捷开发,DevOps等方面来简化应用的开发,部署和运维等等。云原生火了之后,大家抽象出了很多特性。云原生系统的本质特性主要指在各种不同云环境下可以做到架构上弹性可扩展、松散耦合、易于管理、易于升级、易于运维、易于交付等等。从云原生数据库系统来说,要做一个云原生数据库系统是非常复杂的,要实现大规模计算、存储、事务管理等等,大的集群架构不像只是在容器里面跑一个小的应用。云原生数据库或者云原生数据仓库还没有一个非常好的定义。
我根据多年经验结合现在云原生的一些系统,梳理出了一个简单的定义。我认为云原生数据库是在公有云、私有云和混合云等新型动态环境中,基于存储与计算分离架构的、存储和计算可以独立弹性扩展的、松散耦合的数据库系统。因为数据库并不只是一个云原生的应用程序,它有数据库的特性,不能因为云原生、存储计算分离,就把很多特性都扔了,还是必须保证性能、可扩展性、一致性,包括符合SQL的标准、容错、易于管理和多云支持。多云也是很重要的,这是防止厂商lock in的一种方式。
3. 云原生数据库的特点
简单说说云原生数据库的一些特点,现在很多都说自己是云原生数据库,但其实不是,比如把Oracle直接放到云上的虚拟机跑一下,它是不是就叫云原生?不是,因为它满足不了很多特点。我觉得有几大特点能把云原生数据库区分开。第一个是从数据库用户的角度来看,计算和存储是分离的,有人说Oracle是不是也是计算与存储分离?我底下是EMC的存储,上面是Oracle的数据库,是不是也是存算分离?其实这个不算,因为Oracle整个的软件层次,内部的存储是它自己的软件实现的,EMC只是硬件的支持。
我们一般说云原生数据库基本上是分布式的,如果是分析型的,基本上是分布式的存储,比如底下文件系统或者是对象存储,或者是分布式文件系统,又或者是其他自研的一些分布式存储等等,这是从计算存储分离的架构区分开的,这样存储、计算都可以独立扩容,缺计算的时候可以扩计算,缺存储的时候可以扩存储,节省成本。
存算分离的另一个好处是:一个查询用10个节点需要跑一个小时,如果线型可扩展、加速比做得很好,100个节点可能只需要跑6分钟,就能把这个查询跑出来;但是在云上往往是按照计算使用量和存储使用量来计费的,相当于用同样的成本得到了更加好的用户体验。如果存算是绑定的,要起100个节点一直放着,很痛苦,整个机器都一会儿停一会儿启,数据还要持久化,这不太现实,所以这是存算分离包括松散耦合等带来的很大好处。
在同样的计算环境下还应该保持高性能,因为存算分离后有很多优化工作需要做,比如存储分离之后需不需要使用一些缓存来加速?大家如果用过对象存储都知道它很慢,对象存储的设计是为了放一些小的文件、图片等,并不是为了数据库的工作负载。所以为了达到很好的性能,要做很大的优化,不能把性能给丢了。
高可扩展性可以保证这个系统,数据量越来越大,应用越来越多,可以很容易做到扩展,但是传统的MPP集群就做不到这一点,云原生数据库则可以保证。
大家做交易型数据库都说一致性是必须的,但是做分析型数据库一致性是不是必须的呢?现在一致性的观点是肯定需要事务处理,很多早期的Hadoop上的分析型系统不支持事务,但后来都支持了,为什么?很多应用场景其实还需要更新,比如拉链表等等,在增删改查的时候既能保证好事务,又能保证好分析的性能不变。一致性的要求也是云原生数据库的一个特点。
在出错的环境下可以不中断、易于管理,也是云原生数据库一个很大的特点。传统数据库的管理非常复杂的,而在云上非常简单。
最后一点是多云支持,站在最终用户的角度,他希望只需要一个数据库,因为数据库的黏性非常强,数据量进来之后再转移相对比较麻烦,所以很多客户对多云的要求非常多。
从这些特点很容易判断出一个声称是云原生数据库的数据库是否名副其实,如果只是把Oracle或者MySQL简单搬到虚拟机环境下,它不能称为云原生数据库。
二、云原生数据仓库架构
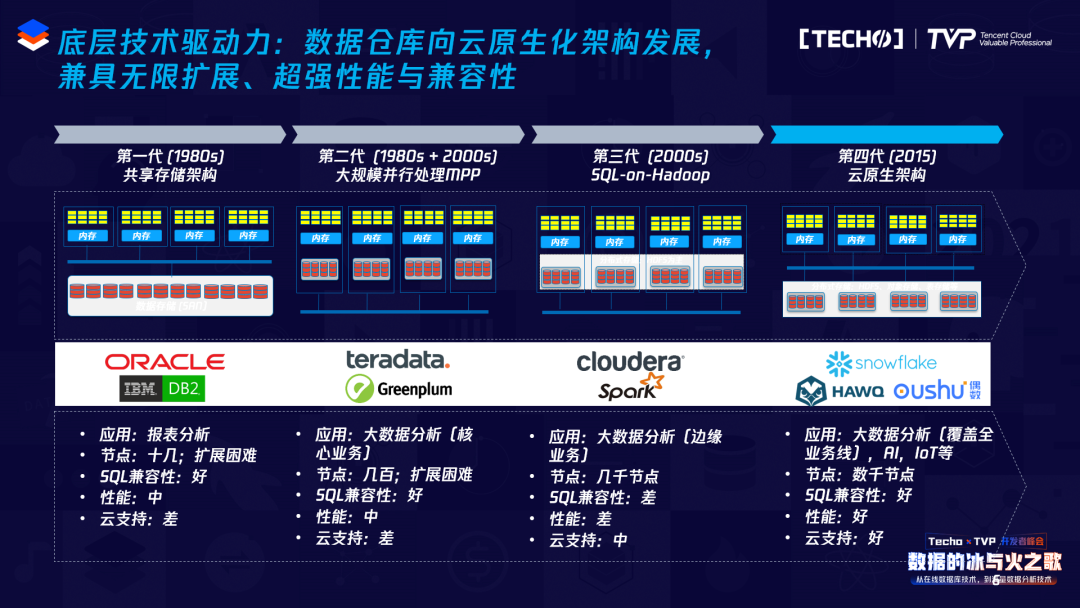
我以几个实际的大数据相关的云原生数据库架构举例来说明。Snowflake前段时间刚上市,估值很高,巴菲特也投了这个公司,业界一片看好,收入规模涨得很快。下图是它的架构,在这里面有三层,最上面一层是Cloud services,做查询解析、优化、元数据管理,包括安全控制等等,如果你了解分布式,这里指的是他们的主节点/控制节点做的一些事情。
中间这一层叫查询计算层,计算层很有意思,这是这一代数据库的特点,它的计算层可以分成多个小的集群,这是非常好的资源隔离方式,计算和存储分离,就等于可以动态地起很多小的集群,不同的用户可以使用不同的集群,类似于多租户的概念,这样就带来了高并发等好处。底下存储层,Snowflake用的是对象存储,其实他们在创业初期的时候想尝试开发一套自己的存储,但后来失败了,为什么?因为存储还是很复杂的,想开发一套好的存储需要好几年,使用了现在的S3,当然也踩了很多坑。
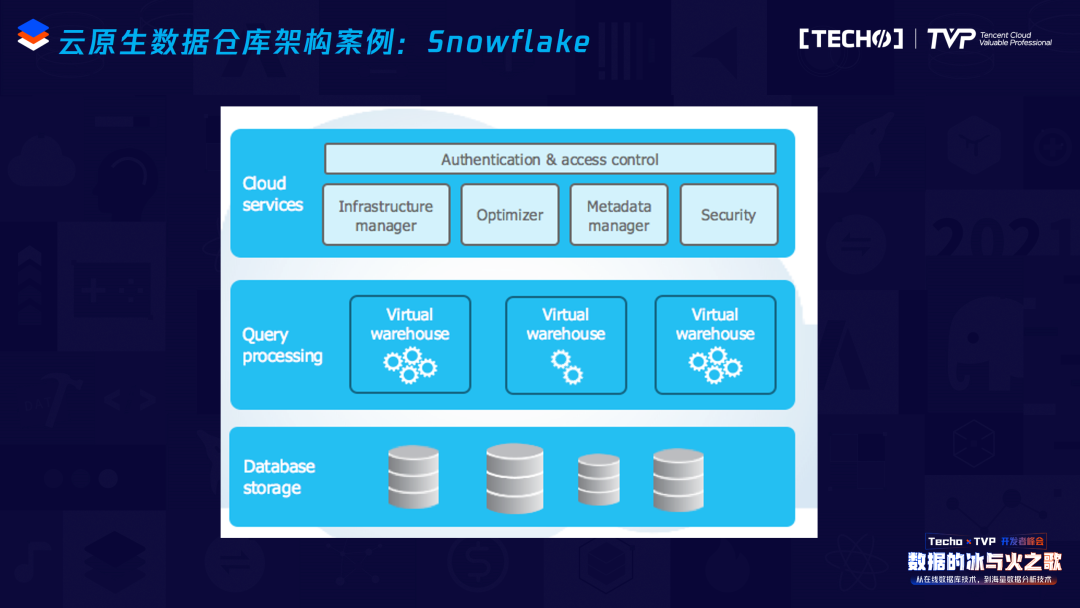
另外一个例子是现在我们在做的OushuDB。
OushuDB是一个云原生的数据仓库,是这种存储与计算分离、松散耦合的架构。大家可以看到架构方面跟Snowflake有一点点相像,左上边这一块蓝色的部分是主节点做的事情,多个主节点可以管理着独立的元数据,管理资源,做查询的解析、查询的优化等等;右上边那一块是计算,我们叫虚拟计算集群,用户可以动态起一些虚拟计算集群。在云的支持方面,我们不仅支持公有云,也支持私有云,还支持物理机的部署。
在存储支持方面,OushuDB支持多种存储,包括对象存储、HDFS等。在公有云上我们推荐用对象存储,比较简单,不需要独立存储的部署;在物理集群上,我们建议部署HDFS。随着各种各样的混合工作负载越来越多,我们研发了Magma分布式表存储,我们这种新的存储支持混合工作负载,支持高并发、小查询、带索引等等,这些工作负载在对象存储上比较难实现,支持可插拔存储是我们相对Snowflake更好的地方。
另外一部分是我们极速的数据分析能力,大家知道Greenplum性能包括HAWQ性能是很好的,而现在OushuDB的版本里,新一代的执行器性能无论是单表性能还是非常复杂的查询,已经可以比Greenplum快5-10倍,这非常难,但我们做到了。而且完全兼容SQL的标准,如果以前你用了Teradata、Oracle、DB2、Greenplum或者其它数据仓库,应用可以非常容易地迁移到我们新一代的数据库里。
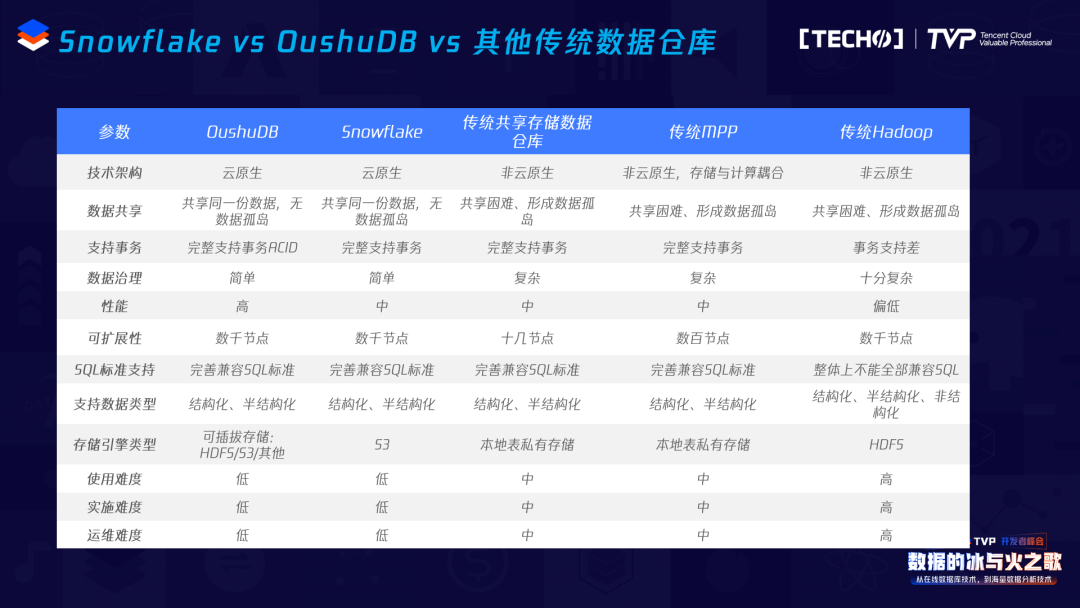
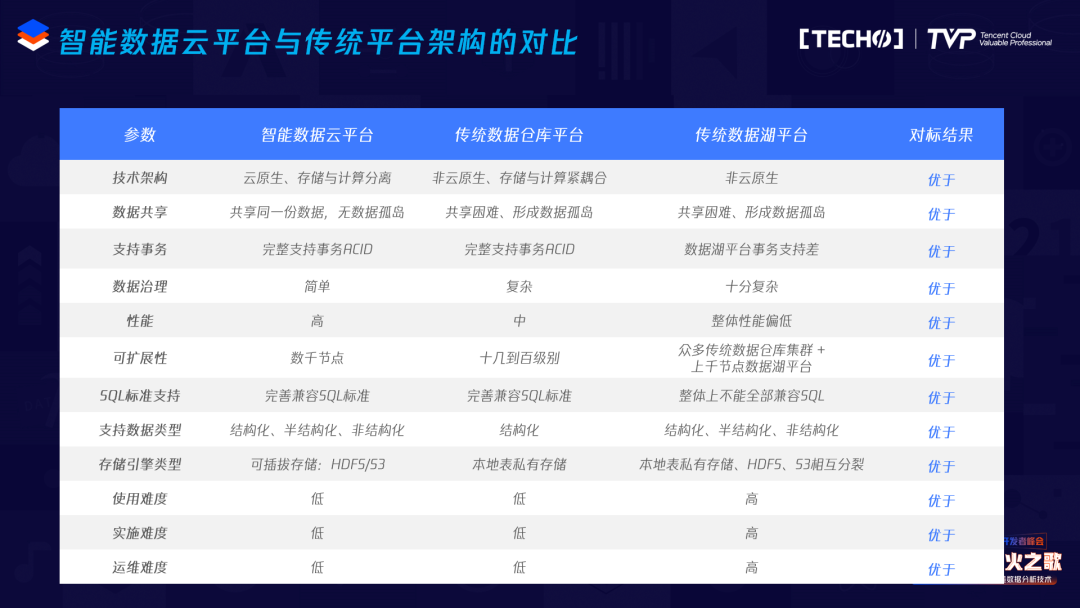
这是几大类产品简单的对比,比较客观,左边两个是新一代的架构,其他的是一些传统的共享存储架构系统,类似于Oracle这种数据库、数仓的一些系统。第二种是传统MPP,类似于Greenplum,Vertica等系统,第三种是Hadoop相关的一些系统。
从数据共享角度来看,比如新一代的云原生架构可以共享同一份数据,不需要因为集群的规模导致要分割很多种小的存储集群,相当于用一个大的存储集群就搞定了。存储是统一的,只需要存一份数据,不会形成数据孤岛。
在事务方面完全支持事务的ACID,所有的特性包括索引等等都可以支持。数据治理方面其实比较简单,性能、可扩展性、SQL标准支持、支持数据类型,包括结构化、半结构化。存储引擎的选择,有的云原生数据库可以支持多种,有的云原生数据库只能支持一种,其它的基本上都是绑死的,比如Oracle不能选别的,Greenplum只能选私有的存储,Hadoop基本上是HDFS。使用难度来看,新一代云原生架构继承了传统数据库Oracle,MPP数据库等的特征,完全兼容SQL包括存储过程、自定义函数等等,运维和实施难度较简单。
三、数据平台架构演进
前面主要说了从架构角度来看云原生数据仓库或者云原生数据库跟传统数据库的一些区别,真正做一个数据分析的应用场景,并不单纯是一个数据库,它是很多系统组合的结果,需要一个好的数据架构。我们从这个角度来看数据架构演进的路线。
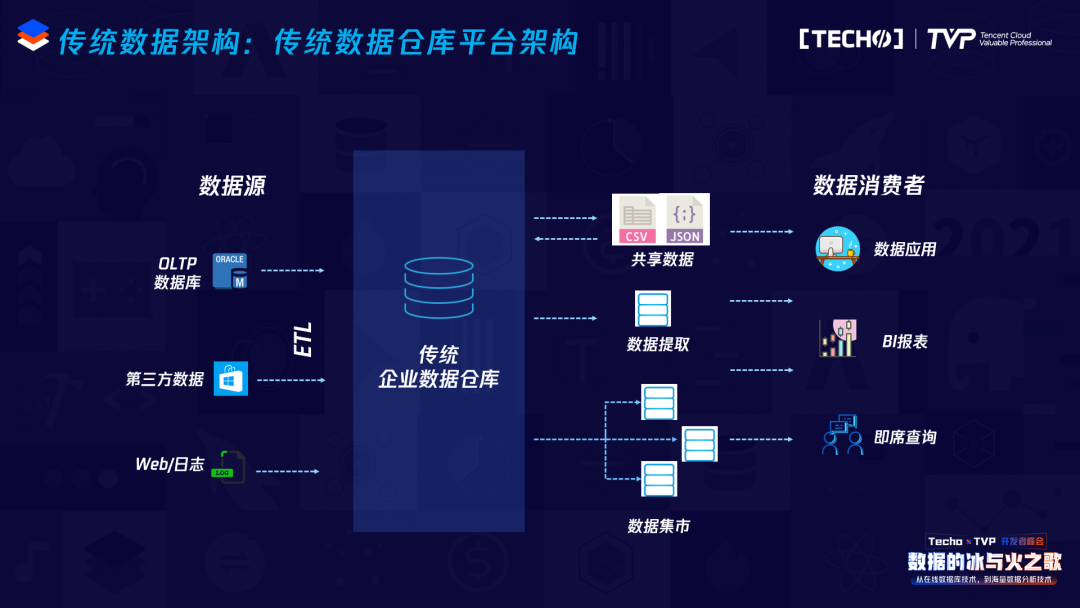
这是最传统的数据架构,在2000年之前比较流行,大家都叫传统数据仓库平台架构,这个架构非常简单,有数据源,进行ETL,到传统的数据仓库,上面有多个数据集市,再上面有报表等应用,这是最传统、最经典的数据仓库的架构。
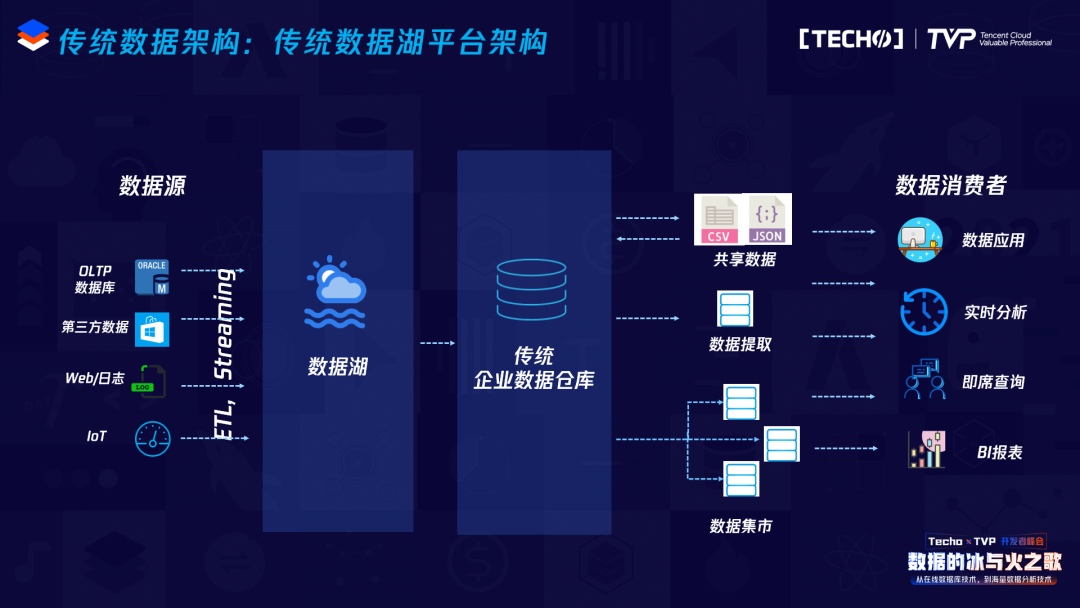
后面等Hadoop出来后,大家开始构建数据湖,很多人对数据湖这个概念的理解不是很一样,那数据湖到底是什么?数据湖解决了什么问题?以前传统数仓的模式,数据从数据源、从ETL加载过来,到数据仓库,再到数据集市,再到应用。数据仓库有着非常好、非常严格的建模方式,比如在金融里有FSDM,还有维度建模等各种各样建模的方法,使得很多数据大家用起来不爽——为什么做一件事情我不能拿到所有的数据,拿到数据还要经过这么长时间才能用,用起来也不是那么灵活,开发一个创新场景比较慢。
引入数据湖的概念,就是把所有的数据,无论结构化、非结构化,都扔进来,没有经过严格的数据建模等等过程,原始数据放在这儿,大家可以去用,用完之后如果形成了一些好的模型,可以转到数据仓库里。数据湖出现之后,大家形成的架构上基本上是这样一种架构:有数据湖,有数据仓库,上面还有数据集市,现在大部分的架构都是这样,当然包含一些流处理等,流数据由不同的组件实现。
在新一代云原生的架构底下,数据架构变得简单了。底下的对象存储或是其他存储是共享的,数据进来之后可以不加整理直接放到存储中(数据湖中),想做处理的时候,可以直接使用,经过加工之后形成仓库里建模好的数据,再到集市,整个的加工处理都在一套平台里,不同的计算场景可以使用不同的计算集群。这种架构我们称之为最新的数据云平台架构。“湖仓一体”基本上也是这个概念,湖和仓可以统一在一套系统中,可以做数据加工、数据资产管理、数据治理、数据科学、机器学习、建模等等,可以非常好地解决传统的需要多个集群、多个系统之间做数据倒腾等各种复杂的事情。
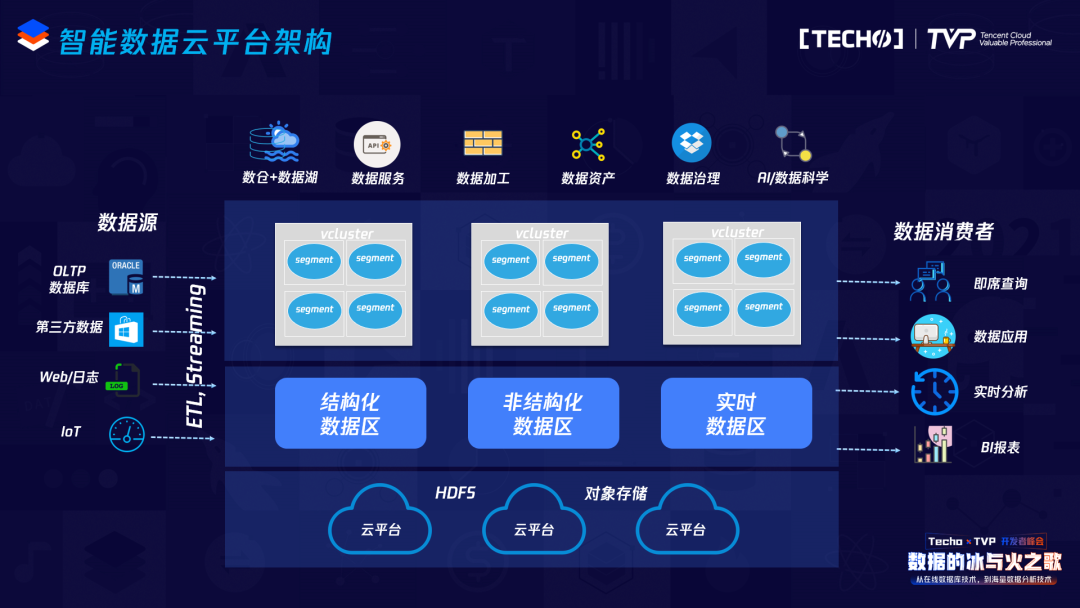
更具体一点,这个架构里其实有非常多的组件,在公有云上可以用对象存储,在物理机上部署的话,还可以使用HDFS。数据可以分为不同的区域,计算可以使用多个集群,比如在做ETL的时候用一个集群,那边要做即席查询,可以使用另外一个计算集群,不同的计算集群做不同的事情,但是数据是共享的,实现了一个完美的架构。
四、云原生数据仓库的应用
最后,我们再来讲一个云原生数据仓库在国有银行的一个应用案例。国内的大行资产规模在世界上非常领先,因此数据量非常巨大,有几十个PB。传统的MPP数据仓库和Hadoop都很难解决高并发,数据孤岛等问题。另外,银行的要求非常高,包括稳定性、功能支持的完备性等等,因此跟互联网公司有一些区别,在互联网公司能凑合用人肉运维使用的系统在银行一般很难用得起来。现在行里大约有好几十个数据仓库集群,云原生架构可以很好地解决数据孤岛等问题,现在我们正在慢慢地将它迁移到新一代云原生架构里。
讲师简介

常雷
偶数科技创始人、CEO,腾讯云TVP
偶数科技创始人、CEO,腾讯云TVP,Apache HAWQ数据库顶级项目创始人,曾任EMC高级研究员、EMC/Pivotal研发部总监,长期专注于AI和大数据领域,曾在国内外顶级数据管理期刊和会议(如SIGMOD等)发表数篇论文,拥有多项国际专利。常雷博士是中国计算机学会数据库专委,中国大数据产业生态联盟专家和中国人工智能百人专家。2017年入选美国著名商业杂志《快公司》“中国商业最具创意人物100”榜单。他于2008年博士毕业于北京大学计算机系。
点击观看峰会的精彩总结视频👆
6月5日,Techo TVP 开发者峰会 ServerlessDays China 2021,即将重磅来袭!
扫码立即参会赢好礼👇

