
数据仓库体系建模实施及注意事项小总结
什么是数仓
从字面上来看,数据仓库就是一个存放数据的仓库,它里面存放了各种各样的数据,而这些数据需要按照一些结构、规则来组织和存放。这里我们会遇到一个问题就是同样是存放数据的仓库,那数据库和数据仓库是一样的吗?
数据库 VS 数据仓库
数据库就是我们常用的关系型数据库(MySQL、Oracle、PostgreSQL...),还有什么非关系型数据库,它主要存放业务数据,那数据仓库有有些什么数据呢?说到他们的区别,我们一般会提到OLTP和OLAP。
OLTP:on-line transaction processing,联机事务处理,主要是业务数据,需要考虑高并发、考虑事务
OLAP:On-Line Analytical Processing,联机分析处理,重点主要是面向分析,会产生大量的查询,一般很少涉及增删改
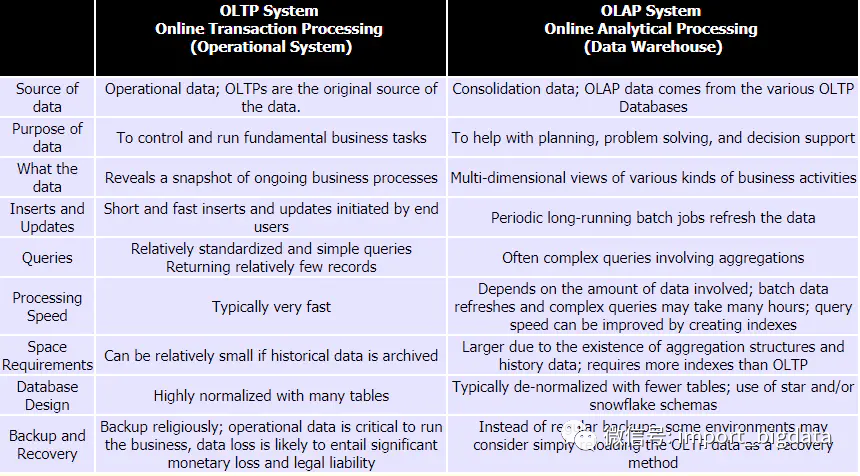
他们的区别,面试时也会提到,主要从几个点谈谈就行。
数据仓库其实是一套体系,他不是一门什么技术,而是整合了很多已有的技术,来更好地组织和管理数据。传统数仓的话,主要是基于关系型数据库,后面还有一些分布式的数据库像Greenplum,还有很多公司会提供基于硬件的一整套解决方案。在传统数仓开发时,由于硬件的性能有限,所以有很多的要求,而随着硬件价格的下降、云服务器的广泛使用,还有大数据技术的成熟发展,数仓的很多场景都变了,有些规则都不需要去严格遵守了,这样也可以剩下很多的成本。
再往前几年,数仓这个东西是有点儿神秘的,感觉很高大上,而现在,起码在互联网公司来说,谁都知道数仓,谁都知道数据平台,谁都可以来说两句,已经大众化了。记得以前面数仓的话,总有几个必备的面试题:
什么是数仓?
数仓的几个特点是什么?
什么是OLAP?什么是OLTP?区别是什么?
拉链表是什么?怎么实现拉链表?
同步又哪几种方式?
为什么要做增量?怎么做增量?
什么是ETL?
就目前互联网数仓这一岗位,感觉更加偏重业务+建模思想,面试不太好考察这些内容的,去年招聘的时候,就是问些基本问题,聊聊以往主要的工作内容,还会问问SQL题,真的想了解下建模的话,还是找本书借鉴性的看看,还是很有益处的。
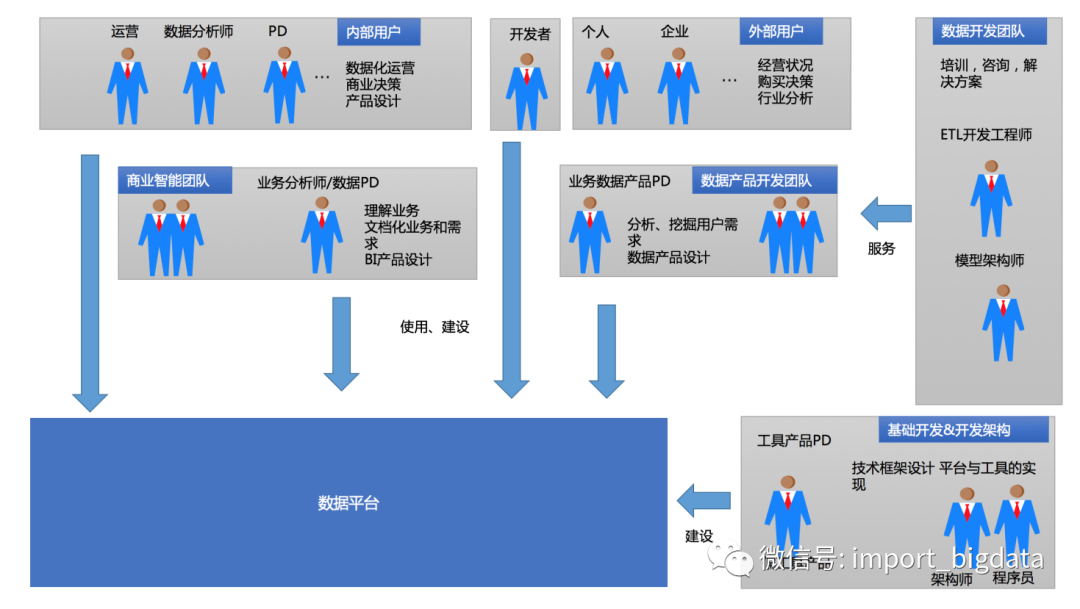
传统数仓与互联网数仓
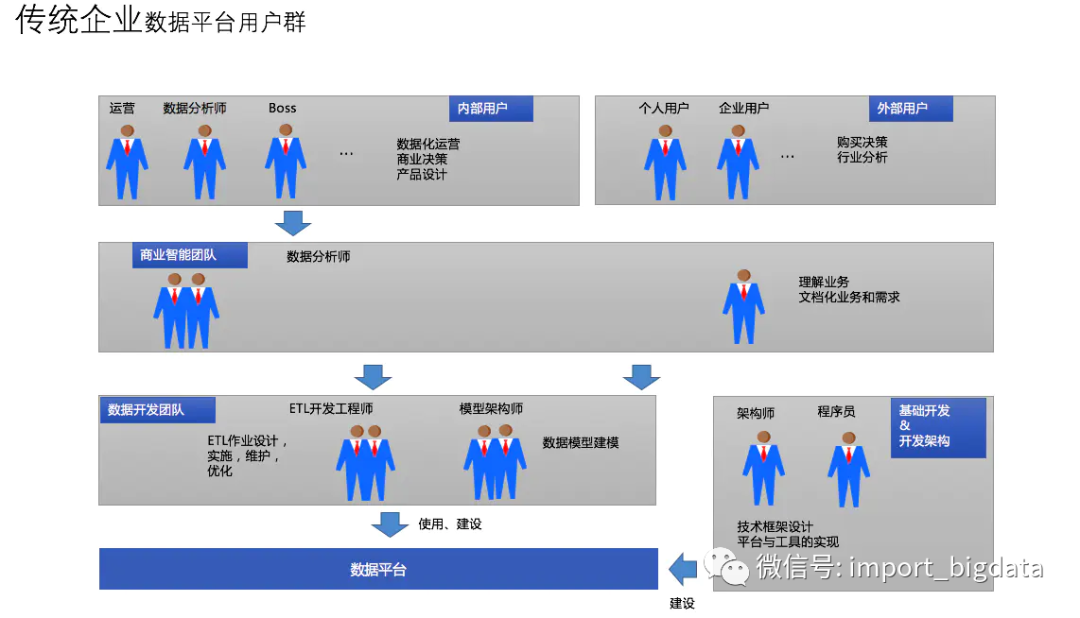
在传统数据平台要背后有一个完整数据仓库团队去服务业务方,业务方嗷嗷待哺的等待被动方式去满足。中低层数据基本不会对业务方开放,所以不管数据模型采用何种建模方式,主要满足当时数据架构规划即可。
互联网业务的快速发展使得大家已经从经营、分析的诉求重点转为数据化的精细运营上,如何做好精细化运营问题上来,当资源不够时用户就叫喊,甚至有的业务方会挽起袖子来自己参与到从数据整理、加工、分析阶段。
此时呢,原有建设数据平台的多个角色(数据开发、模型设计)可能转为对其它非专业使用数据方,做培训、咨询与落地,写更加适合当前企业数据应用的一些方案与开发些数据产品等。
在互联网数据平台由于数据平台变为自由开放,大家使用数据的人也参与到数据的体系建设时,基本会因为不专业性,导致数据质量问题、重复对分数据浪费存储与资源、口径多样化、编码不统一、命名问题等等原因。数据质量逐渐变成一个特别突出的问题。
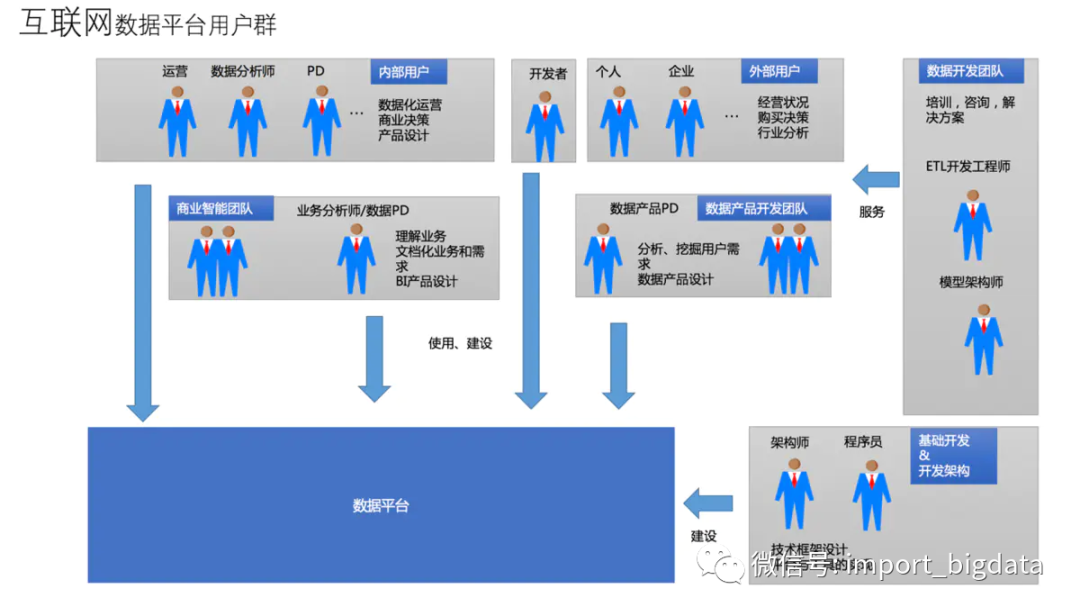
数仓架构
现在说数仓,更多的会和数据平台或者基础架构搭上,已经融合到整个基础设施的搭建上。这里呢,我们不说Hadoop各种组件之间的配合,我们就简单说下数仓的分层架构。
说到数仓建模,就得提下经典的2套理论:
范式建模
Inmon提出的集线器的自上而下(EDW-DM)的数据仓库架构。
维度建模
Kimball提出的总线式的自下而上(DM-DW)的数据仓库架构。
数仓的建模或者分层,其实都是为了更好的去组织、管理、维护数据,实际开发时会整合2种方式去使用,当然,还有些其他的,像Data Vault模型、Anchor模型,暂时还没有应用过,就不说了。
维度建模,一般都会提到星型模型、雪花模型,星型模型做OLAP分析很方便。
数仓分层
简单点儿,直接ODS+DM就可以了,将所有数据同步过来,然后直接开发些应用层的报表,这是最简单的了;当DM层的内容多了以后,想要重用,就会再拆分一个公共层出来,变成3层架构,最近看了本阿里的书,《大数据之路》,里面有很多数仓相关的内容,很不错,参考后,目前使用的分层模式如下:
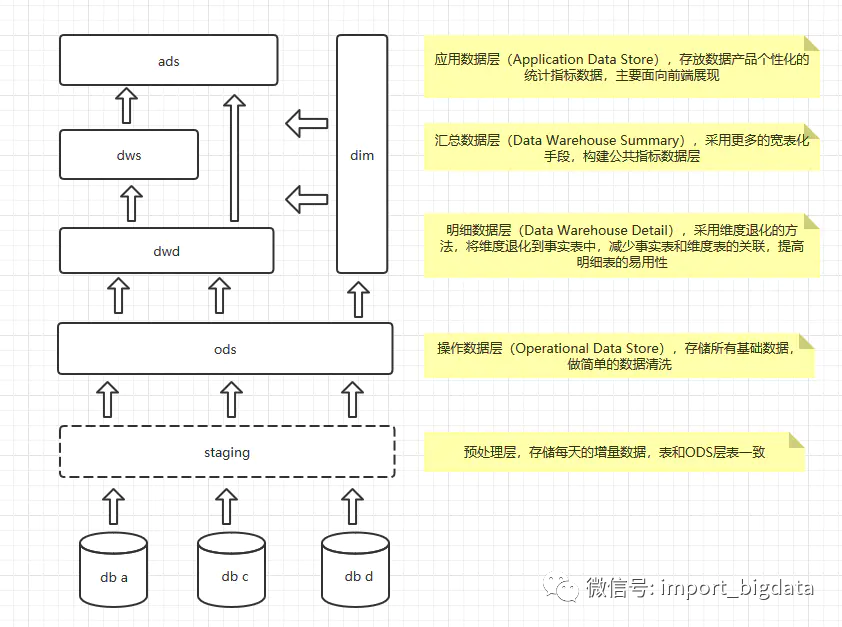
按照这种分层方式,我们的开发重心就在dwd层,就是明细数据层,这里主要是一些宽表,存储的还是明细数据;到了dws层,我们就会针对不同的维度,对数据进行聚合了,按道理说,dws层算是集市层,这里一般按照主题进行划分,属于维度建模的范畴;ads就是偏应用层,各种报表的输出了。
指标字典
前面我们说过,数仓是一套体系,一个建设过程,它整合了很多的方法论,并不是一门新的技术。这里我们说说数仓中的指标体系,指标也不是数仓或者数据平台中特有的, 很多场景都会有指标这个概念。
这里我们说的指标,其实就是KPI(Key Performance Indicator),关键绩效指标。
企业关键绩效指标(KPI:Key Performance Indicator)是通过对组织内部流程的输入端、输出端的关键参数进行设置、取样、计算、分析,衡量流程绩效的一种目标式量化管理指标,是把企业的战略目标分解为可操作的工作目标的工具,是企业绩效管理的基础。KPI可以使部门主管明确部门的主要责任,并以此为基础,明确部门人员的业绩衡量指标。
数据平台的作用是为分析、决策提供支持,来时刻关注企业的运营情况的。那我们怎样来看公司的运营情况呢?就是看KPI,公司层面有公司最关注的KPI,比如:日活、GMV、订单量等等;不同的部门又有不同的关注KPI,比如:新用户数、复够人数等等,有了KPI,我们就可以根据KPI来考察部门的表现,也就是绩效。这也是数字化转型嘛,所有的管理、绩效都数字化。
就数据平台来说,指标算是元数据的一种,指标的维护和管理是有套路的,下面就简单分享下关于指标的管理-指标字典。
指标字典
指标字典,其实就是对指标的管理,指标多了以后,为了共享和统一修改和维护,我们会在Excel中维护所有的指标。当然,Excel对于共享和版本控制也不是很方便,有条件的话,可以开发个简单的指标管理系统,再配合上血缘关系,就更方便追踪数据流转了。
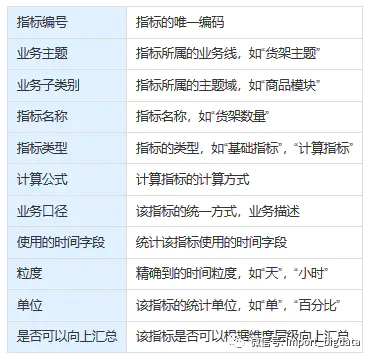
指标编码
为了方便查找和管理,我们会对指标定义一套编码
指标类型
基础指标:不能再进一步拆解的指标,可以直接计算出来的指标,如“订单数”、“交易额” 衍生指标:在基础指标的基础上,通过某个特殊维度计算出的指标,如“微信订单数”、“支付宝订单数” 计算指标:通过若干个基础指标计算得来的指标,在业务角度无法再拆解的指标,如“售罄率”、“复购率”
业务口径
指标最重要的就是,明确指标的统计口径,就是这个指标是怎么算出来的,口径统一了,才不会产生歧义
指标模板
除了上面,我们说到的几点,还有一些基本的,像“指标名称”、计算公式,就组成了指标的模板
以前的话,我们还会有责任部门,就是说这个指标是哪个部门负责维护的,这个KPI是哪个部门来关注和承担。说到指标,就离不开维度,我们后面会说说维度的故事。
指标的梳理和管理
一开始指标的梳理是很麻烦的,因为要统一一个口径,需要和不同的部门去沟通协调;还有可能会有各种各样的指标出现,需要去判断是否真的需要这个指标,是否可以用其他指标来替代;指标与指标之间的关系也需要理清楚。
而且第一版指标梳理好之后,需要进行推广和维护,不断地迭代,持续推动,让公司所有部门都统一站在一个视角关注问题。
最重要的维度之日期维度
日期维度是我们最常用的维度,平台初始,最先初始化的可能就是日期维度,这里我们就简单介绍下日期维度。
什么是日期维度
我们日常生活,数据的产生都和日期有关,每一分、每一秒都会产生数据,数据分析也离不开日期。
日期维度就是一张固化的日历,一年365天,每一天都有,我们打开电脑中的日历:
这里面有的,我们都可以固化下来,像周几、农历、年、月、日、节假日,我们都可以固化下来,方面我们分析的时候使用。
日期维度的结构
日期维度可以尽可能多的包含日期详细信息,这样在分析的时候可以直接使用,还要结合公司的一些特殊情况,像一些特殊展示的日期格式。
基本的年季度月周日信息
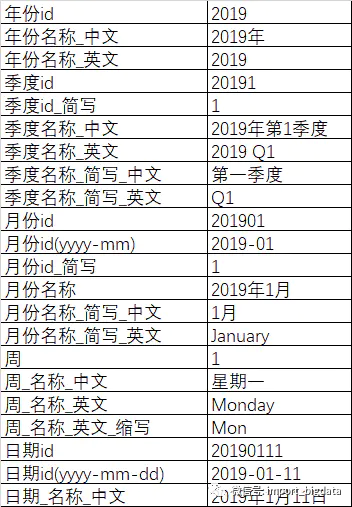
拓展信息
除了上面的基本的日期,平时用的还有有些拓展信息
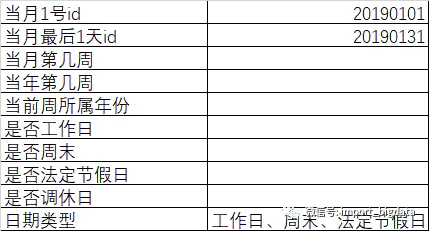
可能还有些农历信息、农历年份等,公司自定义周的开始日期、结束日期等,和日期相关的所有内容都可以加进来进行维护。
维度初始化
数据初始化,我们可以使用Java、Python或者SQL,通过常用的日期函数基本可以满足我们的数据需求,用SQL初始化,需要使用有循环控制语句的,如:MySQL、PG都行,Hive的话要结合Shell或者Python来使用。
一般不需要初始化太多年的数据,只要覆盖公司业务数据就好了,还有节假日信息每年都需要结合国务院发布的信息就行维护。
关于小时
平时我们还会分析小时数据,一般不会把他放在日期表中,而是会单独放在一张小时维度表里,需要的时候一起使用就行了。
命名规范
话说,没有规矩不成方圆。在搭建数据平台的时候,在数据组内部,一定要先制定好各种规范,越早越好,并且不断的监督大家是否按照约定执行。一旦让大家自由发挥,后期想要统一或者重构,会浪费很大的人力成本和时间成本,记住,这都是坑。
这里以我目前公司的一些经验,分享下。
关于项目
常规来说,数仓的建设是按照数仓分层模型开发的。也有会按照业务线来分层,在各自业务线下重新分层,单独开发的。我这里使用的是阿里云的MaxCompute,这是阿里提供的数据平台,一整套开发环境,用起来还是很方便的,省去了自建平台的麻烦。MaxCompute里面有一个项目的概念,一开始本来打算直接根据分层模型的设计来创建项目,但是由于某种原因,改成了按照业务线来创建项目。对于这个项目名,一定要想好,不管根据什么来设计,都需要想清楚,想明白,定了以后就不要再改了,也没法改。
关于词根
我忘记是不是叫“词根”了,先写着,后面找本书确认下。词根属于数仓建设中的规范,属于元数据管理的范畴。哦,现在都把这个划到数据治理的一部分。
正常来说,完整的数仓建设是包含数据治理的,只是现在谈到数仓偏向于数据建模,而谈到数据治理,更多的是关于数据规范、数据管理。
接着说我们的主角-词根。
我们学习英语的时候应该有了解过词根这个东西,它就是最细粒度的最简单的一个词语,我们主要用来规范中文和英文的映射关系。我们公司一部分业务是关于货架的,英文名是:rack,rack就是一个词根,那我们就在所有的表、字段等用到的地方都叫rack,不要叫成别的什么。这就是词根的作用,用来统一命名,表达同一个含义。指标体系中有很多“率”的指标,都可以拆解成XXX+率,率可以叫rate,那我们所有的指标都叫做XXX+rate。词根可以用来统一表名、字段名、主题域名等等。
表名
表名需要见名知意,通过表名就可以知道它是哪个业务域,干嘛用的,什么粒度的数据。
常规表
常规表是我们需要固化的表,是正式使用的表,是目前一段时间内需要去维护去完善的表。规范:分层前缀[dwd|dws|ads|bi]业务域主题域XXX粒度 业务域、主题域我们都可以用词根的方式枚举清楚,不断完善,粒度也是同样的,主要的是时间粒度、日、月、年、周等,使用词根定义好简称。
中间表
中间表一般出现在Job中,是Job中临时存储的中间数据的表,中间表的作用域只限于当前Job执行过程中,Job一旦执行完成,该中间表的使命就完成了,是可以删除的(按照自己公司的场景自由选择,以前公司会保留几天的中间表数据,用来排查问题)。规范:mid_tablename [0~9|dim] table_name是我们任务中目标表的名字,通常来说一个任务只有一个目标表。这里加上表名,是为了防止自由发挥的时候表名冲突,而末尾大家可以选择自由发挥,起一些有意义的名字,或者简单粗暴,使用数字代替,各有优劣吧,谨慎选择。通常会遇到需要补全维度的表,这里我喜欢使用dim结尾。
中间表在创建时,请加上 ,如果要保留历史的中间表,可以加上日期或者时间戳
drop table if exists table_name;
create table_name as xxx;
临时表
临时表是临时测试的表,是临时使用一次的表,就是暂时保存下数据看看,后续一般不再使用的表,是可以随时删除的表。规范:tmp_xxx 只要加上tmp开头即可,其他名字随意, 注意tmp开头的表不要用来实际使用,只是测试验证而已。
维度表
维度表是基于底层数据,抽象出来的描述类的表。维度表可以自动从底层表抽象出来,也可以手工来维护。规范:dim_xxx 维度表,统一以dim开头,后面加上,对该指标的描述,可以自由发挥。
手工表
手工表是手工维护的表,手工初始化一次之后,一般不会自动改变,后面变更,也是手工来维护。一般来说,手工的数据粒度是偏细的,所以,暂时我们统一放在dwd层,后面如果有目标值或者其他类型手工数据,再根据实际情况分层。规范:dwd _ 业务域manual xxx 手工表,增加特殊的主题域,manual,表示手工维护表
指标
指标的命名也参考词根,避免出现同一个指标,10个人有10个命名方法。
具体操作结合公司实际情况,规范及早制定。
数据治理
广义数据仓库的建设包含很多的解决方案,其中就包含数据治理,数据治理也是贯穿整个项目始终的,是一件长久的事情。现在很多人都把数据仓库简单的理解成数据建模了。
数据治理包含很多的事情,我也没做过,所以在网上找些资料分享下。
为什么要做数据治理
随着数据量越来越大,数据成为一种资产,我们需要更好地管理这些数据,更好地体现数据的价值,这就需要数据治理。其实在搭建数据平台的时候,我们遇到的一系列问题都可以通过数据治理来解决:
数据质量越来越差,问题发现严重滞后
缺少数据标准,各个部门标准不统一
数据变更对下游的影响不清晰,无法确认影响范围
数据治理(Data Governance),是一套持续改善管理机制,通常包括了数据架构组织、数据模型、政策及体系制定、技术工具、数据标准、数据质量、影响度分析、作业流程、监督及考核流程等内容。
简单来说就是有很多流程和标准,像“元数据管理”、“主数据管理”、“数据质量”都包含其中。
通过数据治理来解决我们使用数据的过程中遇到的问题。
这部分内容你可以参考:《所谓数据治理》
关于增量
很多初学者或者没有做个ETL这件事儿的同学对这个增量是有误解的,尤其是在和业务开发同学对接的时候,他们对这个增量的理解也是有偏差的。
先来说说他们以为的增量是什么。他们以为“增量,就是按照时间增量去拿就好了,增量同步,你就把增量后的数据给我好了,不要总是全量同步。” 按道理说,这么做思路是对的,但是不严谨,而且会出错,下面我们就一步一步看看。
1.什么是增量
增量是相对于全量来说的,它们都是处于“同步数据”这个场景下的,比如说业务系统的数据同步到数仓,数仓的数据同步给业务系统,都会使用同步的方式,这都是相对于我们开发来说的,从数据库级也是可以同步的,这里我们就不介绍了。
全量同步,就是说把数据全部同步过去,100条就同步100条,1万条就同步1万条,1亿条就同步1亿条,大家也应该会发现这种方式存在的问题,在数据量小的时候,全量同步简单方便易执行,而当数据量大了以后,尤其是历史数据不会经常变化的时候,全量同步就会浪费大量的资源和时间,严重影响同步效率。
--全量同步一般先delete,然后insert
delete from tmp_a;
insert into tmp_a xxx;
-- 或者直接 insert overwrite
insert overwrite table tmp_a xxx;
SQL语法可能不太一样,差不多就是这个意思,哈哈
记住一定要删除或者覆盖插入,不然数据可就越来越多了。
选择增量同步的几个场景:
数据量很大,而且历史数据不会频繁变化
只需要增量数据
使用增量同步,对表有一些要求,比如,需要有create_time,update_time字段 create_time表示记录创建时间,update_time表示记录更新时间,增量的话,只需要把变化的数据拿过来就行了(使用update_time),注意:这里还需要有一个主键,主键是用来覆盖数据的。
这里和不同的业务场景有关系,有的记录创建后不会再更新,类似于流水数据,这种数据直接增量拿过来就好,可以不进行删除操作;但是有的数据是会更新的,当已经同步过来的数据发生了变化,数仓侧也是需要同步发生变化的。
2. 怎么做增量
增量同步也是要做一次初始化的,初始化是全量来的。
假设我们有这样一张表:
create table tmp_a(
id bigint,
create_time datetime,
update_time datetime
);
一般离线场景下,都会选择在业务量最少的时候去做同步操作,而这个时间大部分都是在半夜凌晨的时候,所以大部分同步都是从0点以后开始,同步昨天的数据,也就是常说的T+1了。
假设3月1号创建了如下4条记录,数仓会在2号凌晨进行同步

2号的时候,新增了1条记录,并且有一条记录更新了,按照增量规则,我们会拿到两条记录

拿到增量数据之后,我们需要将增量的数据合并到我们数仓的表中
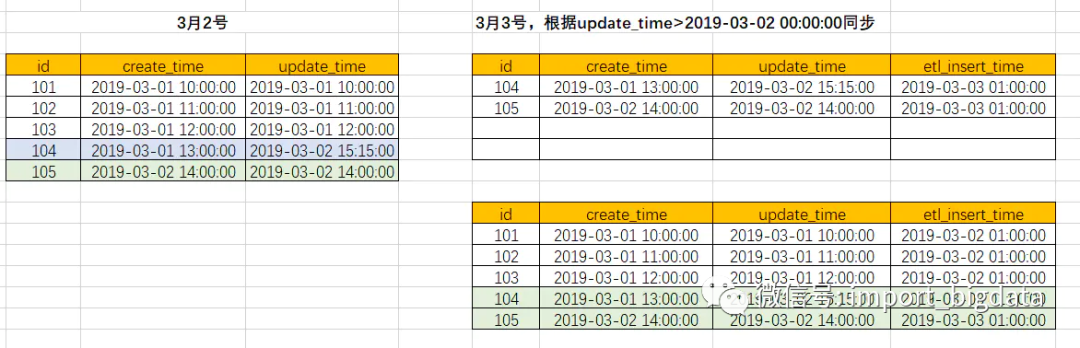
新增的数据,可以直接插入,但是更新的数据,我们需要把原纪录更新掉,或者先删除再插入,以前我们还会记录一个数据插入的状态,如果是更新的,就记一个“update”,如果是插入的就记一个“insert”,到了这里,应该知道为啥需要有主键了吧,如果没有主键,你咋知道这条记录到底变没变过。
使用增量,一般需要两套表,一套表用来存增量数据,一套用来存完整的全量数据。
3. etl_insert_time
不管是增量还是全量,我都比较喜欢加一个时间戳字段,用来标识记录的插入时间,这个尤其是在对比增量数据的时候,排查数据问题很有用。
4. 我们公司的同步机制
我们呢,一创业公司,数据量不算多,使用的都是阿里云的工具,一开始为了方便,所有的数据,都是全量来的,刚看了眼数据量又10几T吧,其中很多是历史数据。
虽然我们是全量来的,但是为了捕捉记录数据的变化,用的是pt(分区)的方式,每天都是一个全量快照,这也是现在存储便宜的一种处理方法,简单粗暴。我刚来的时候,就提过搞成增量,被拒绝了,后来也没有人来搞这个,表太多了,修改起来成本太高。
5. 基于Hive的增量
Hive现在也算是标配了,上面说的增量方案,可能还是基于关系型数据库的,在Hive上,由于运算能力更强大,可以不考虑数据量的问题,所以衍生出来几种方案。主要原因还是Hive上对于delete操作的支持问题,尽量不要有delete。
排序(row_number)
我们依然每天获取增量数据,然后将增量数据插入到每个分区中,每个分区都是当天的增量数据,当然数据变化的话,同一个主键的记录会出现在多个分区中,所以如果我们要获取最新的完整版数据,可以使用row_number根据主键和时间排序,获取最新版本的全量数据
full join
使用full join的方式,将增量数据和历史全量数据,进行关联,然后取出最新完整版数据
left join + union all
这个和full join的方式类似,感觉这个更美观严谨一些,以前在GP上面做增量也用的这种方式。
6. 拉链表
说到增量,也需要提一下拉链表,拉链表以前用的多一些,感觉在互联网公司用的很少,基本都使用分区的方式处理掉了。拉链表其实就是记录数据的每一次变化,处理起来稍微有点儿麻烦,这个以前好像写过,等我找找贴过来。
上下游约定
由于数仓的特性和定位,它就需要强依赖上游的业务系统,当然也会有一些下游系统,所以定好上下游的规范,变更的通知机制是非常有必要的。
感觉好像写过上下游的事情,刚才没找到,这里就再重新写写。
上游
这里说的主要是基于小公司,类似我目前所在的创业公司为例,像发展成熟的大公司,各种流程规定、容错监控类的机制都很完善,对于这些场景,我说的可能就不适用了。
对于数仓来说,最重要的就是数据了,数仓中的数据,主要来源是业务系统,就是公司各种业务数据,所以数仓需要不断的将业务系统数据同步到自身平台来,所以一旦上游业务系统发生变化,数仓也要同步变化,不然,这种同步操作很可能失败。
表结构变更
上游的表结构经常会发生变化,新增字段、修改字段、删除字段(除非真的不用这个字段了,通常会选择标识为弃用)。表结构最好要维护清楚,表名、字段名、字段类型、字段描述,都整理清楚,不使用的字段要么删除,要么备注好,当业务频繁发生变化或者迭代优化的时候,很容易出现,我写了半天的代码,最后发现表用的不对,字段用的不对,这就尴尬了。
对于这种变化,人工处理的话,就是手动在数仓对应的表中增加、修改字段,然后修改同步任务;这个最好可以搞成自动化的,比如,自动监控上游表结构的变更,变化后,自动去修改数仓中的表结构,自动修改同步任务。
枚举值
业务系统中会有很多的常量,用来标识一些状态或者类型,这种值经常会新增,数仓中会对这些值做些处理,比如转换成维度,会翻译成对应的中文,而实际上这种映射关系,我们是不知道的,只有业务开发才知道,所以最好可以让他们维护一张枚举值表,我们去同步这张表。
create_time & update_time
正常来说,create_time,当这条记录插入后,就不会再变了,但是某种情况下,哈哈,开发同学会去更新它;update_time,当这条记录变化后,这个时间也要变,有的开发同学不去更新它......
所以在做增量操作的时候,一定和开发说好这两个字段的定义和使用场景。
is_delete & is_valid
有些场景下,我们需要删除某些数据,一般不会物理删除,会通过一个字段来做逻辑删除,请和开发同学沟通好,使用固定的一个字段,并确认该字段双方的理解是一致的,不然后面又很多坑。
下游
说完了上游,我们说说下游,对于数仓来说,一般的邮件、报表、可视化平台都是下游,所以当我们在数仓中进行某些重构、优化操作的时候,也需要通知他们。
主要就是对数仓模型做好维护,表的使用场景、字段描述等。
对上游的要求,自己也要做好,因为自己也是上游。
任务注释
这一篇说说注释,注释总是让人又爱又恨。
没有注释,谁知道你这些代码是用来干嘛的,从代码角度来看,你想做的是A,而实际上需求确是B,具体干啥得靠猜;代码有注释,也不一定就可以高枕无忧,注释可能是最初版的需求,改了几版后,代码早就变了,注释没有变,注释和代码不匹配,谁知道该以哪个为准啊。
我们的数仓都是基于阿里云的,使用了它的DataWorks作为离线工具,所有的代码都在这上面,所以这里简单介绍下,在阿里云上的任务,几点注释规范。
-- @name p_dwd_rack_machine
-- @description 货架宽表
-- @target rack.dwd_rack_machine
-- @source owo_ods.kylin__machine_release_his
-- @source owo_ods.kylin__machine_device_his
-- @author yuguiyang 2017-12-25
-- @modify
@name:任务的名字,我们的任务名一般都是以 p_目标表名,后来阿里的DataWorks升级后,推荐是任务名和表名保持一致。
@description:任务描述,该任务的主要内容 @target:目标表名,一般一个任务只输出一个目标表
@source:来源表,就是任务中使用的底层表,这里也可以省略,从血缘关系中可以直接看到,而且很容易漏更新
@author:创建者,和创建日期, @modify:内容变更记录,变更人,变更日期,变更原因 ,这个从版本控制中也可以找到,但是这些这里更直观一些。