
干货帖 | TDSQL-A核心架构揭秘
一、TDSQL-A场景定位

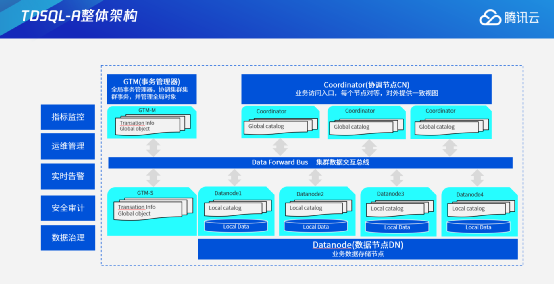
二、TDSQL-A核心技术架构
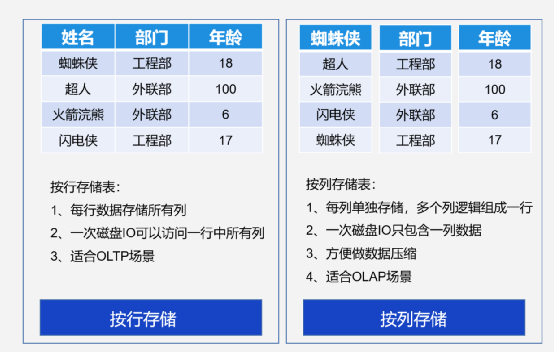
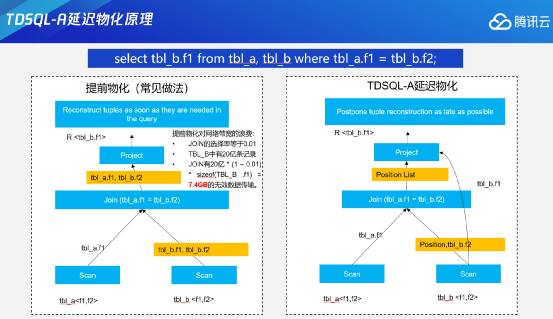
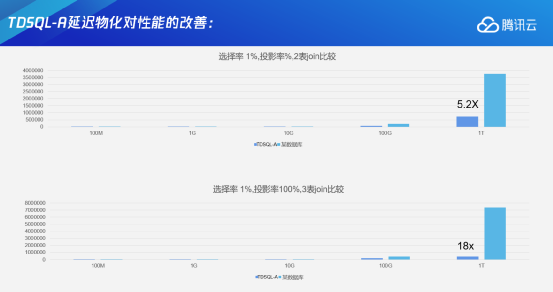
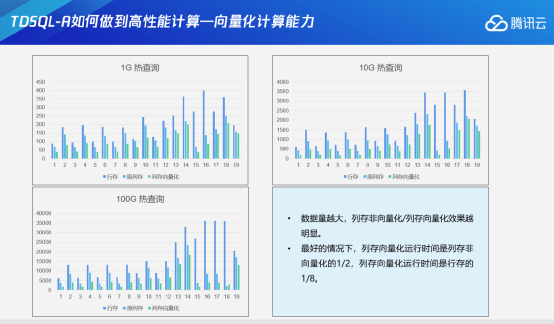
这里举一个例子,一个场景中有两张表——tbl_a和tbl_b,两张表上都有f1和f2两列,分布列都是f1。按照tbl_a的f1列与tbl_b的非分布列f2来进行关联——此时左边是提前物化的计算方法, Project需要返回tbl_b的f1,进行Join关联的时候需要tbl_b的f2,所以在对tbl_b进行Scan的时候,就会把tbl_b的f1和f2都物化出来。所谓的物化,是把两个列在文件里面读出来,在内存里形成一个虚拟的记录元组,然后往上传输。实际上可以看一下,在最上层往里面投数据的时候,只投影了tbl_b的f1。在这个过程中,如果中间Join关联的过滤比例很高,比如说只有1%是满足要求的,这里面有很多tbl_b的f1列数据是没有必要传输进来的。
TDSQL-A延迟物化技术就是针对刚才的问题提出的优化方案。TDSQL-A延迟物化查询计划会在下层进行Scan的时候,针对Join中不需要的目标列只往上层传递物理元组的位置信息到上层节点。只有等上层节点完成Join关联后,才会去把满足条件的记录的位置信息记录下来,在投影阶段再到下层拉取需要的数据信息,进而透到外面。
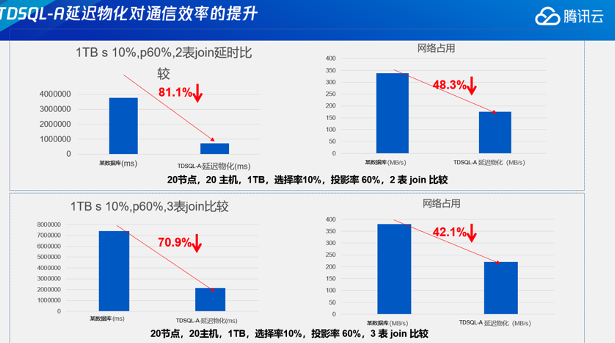
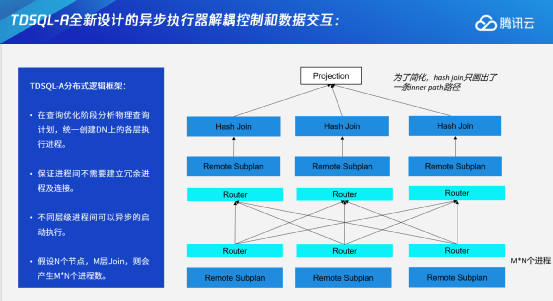
为了解决上连接数过高的问题,TDSQL-A全新设计了异步执行器。TDSQL-A的执行器是全新自研设计的执行器,主要有两个特点:第一个是异步执行;第二个是控制逻辑和数据传输逻辑分离。
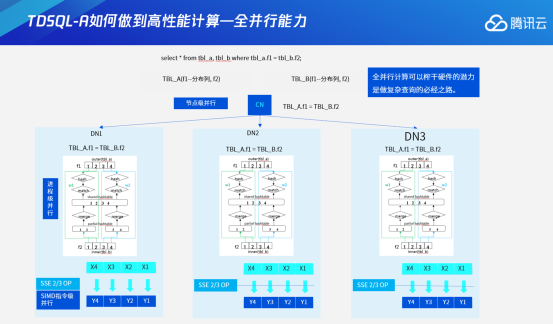
具体来说,系统在查询优化阶段的时候会生成统一的执行计划、统一执行需要的资源,这是TDSQL-A的控制逻辑。同时系统把整个网络通信进行了抽象,抽象成下面蓝色的Router——Router主要是负责机群内部的数据查收。不同的进程之间,比如两层Join或者三层Join,不同层级的进程之间是完全异步执行的,并通过推送数据的方式来完成数据交互。假设有N个节点,有M层join,则一共有M×N个进程。
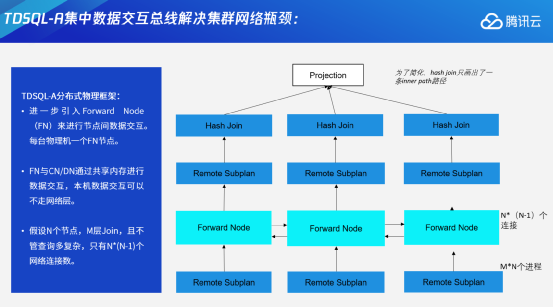
在对执行器进行异步化和控制数据分层的基础上,TDSQL-A又对数据交互逻辑进行完整实现,这就是数据交互总线(Forward Node)。它主要是负责节点间的数据交互。可以认为它是我们集群的逻辑网卡。
三、结语


久等了,全新TDSQL-A,来了!

14亿人的大项目,拿下!