
干货 | 广告系统架构解密

从技术角度来说,广告业务涉及到 AI算法、大数据处理、检索引擎、高性能和高可用的工程架构 等多个方向,同样有着不错的技术吸引力。
我从去年开始接触广告业务,到现在差不多一年时间了。这篇文章将结合我的个人经验,同时参考业界的优秀案例,阐述下广告系统的架构实践方案,希望让大家有所收获。内容包括以下3部分:
广告业务简介 面临的技术挑战 广告系统架构详解
01 广告业务简介
广告,可以说无处不在。微信、抖音、B站、百度、淘宝等等,这些占据用户时间最长的 APP, 到处都能看到广告的影子。
我们每天随处可见的广告,它背后的业务逻辑到底是什么样的呢?在分享广告系统的架构之前,先给大家快速普及下业务知识。
1. 广告业务的核心点是平衡
为什么说广告业务的核心点是「平衡」?可以从广告的标准定义来理解。
广告被定义为:广告主以付费方式通过互联网平台向用户传播商品或者服务信息的手段。这个定义中涉及到 广告主、平台、用户 3个主体,但是这3个主体的利益关注点各不相同。
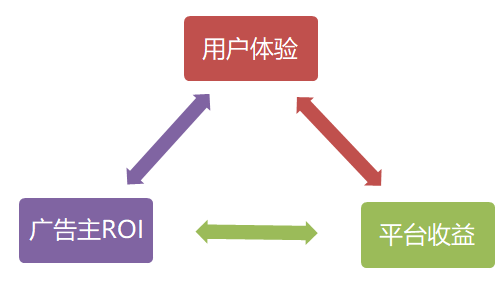
图1:广告业务的三角平衡
广告主:关注ROI,花了钱是否能带来预期收益
平台:拥有流量,关注收益能否最大化
用户:关注体验,广告是否足够精准?是否影响到了正常功能的使用?
有时候这三者的利益是冲突的,比如平台增加了广告位数量,收益肯定增加,但用户体验可能变差,因此广告业务最终要寻找的是三方的平衡。
站在平台的角度来看广告业务,它在保证用户体验的同时,要兼顾绝大部分广告主的ROI(确保他们是可以赚到钱的),在此基础上再考虑将平台的收入最大化,这样才是一个健康的广告生态。
广告业务发展了几十年,广告费用的结算方式也诞生了很多种,我们最常见的有以下几种:
CPT:按时间计费,独占性包时段包位置 CPM:按照每千次曝光计费 CPC:按照点击计费 CPA:按照行为计费(比如下载、注册等)
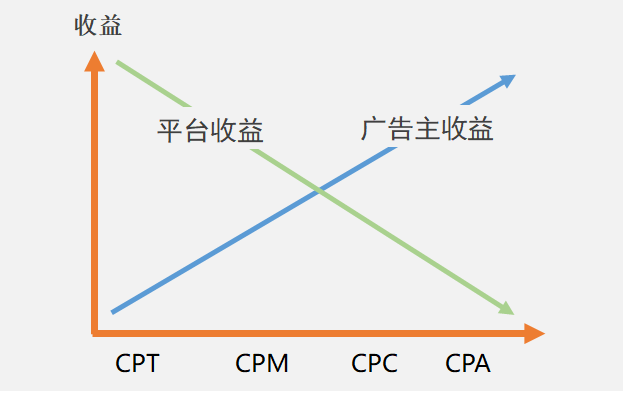
图2:广告费用的结算方式演进
之所以有不同的结算方式,其实也是随着广告市场的发展逐渐衍生出来的,最开始流量稀缺,平台占优势,再到今天逐渐成了买方市场,广告主作为需求方的谈判权变大。

3. 广告的核心业务流程
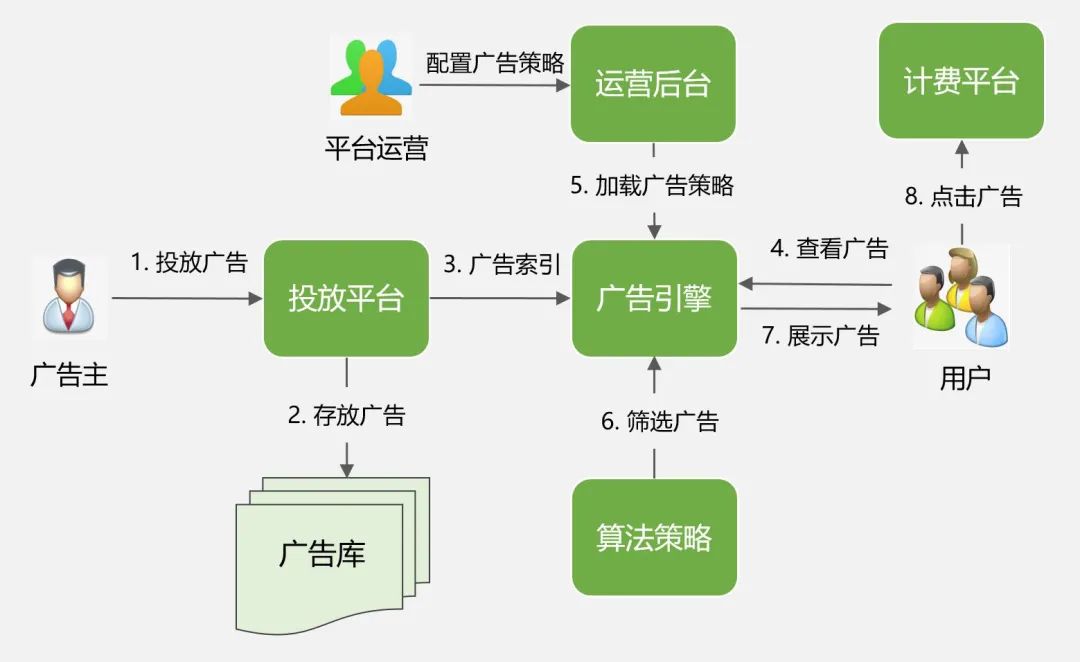
图3:广告的核心业务流程
广告主先通过投放平台发布广告,可设置一系列的定向条件,比如投放城市、投放时间段、人群标签、出价等。
投放动作完成后,广告会被存放到广告库、同时进入索引库,以便能被广告检索引擎召回。
C端请求过来后,广告引擎会完成召回、算法策略、竞价排序等一系列的逻辑,最终筛选出Top N个广告,实现广告的千人千面。
用户点击广告后,会触发广告扣费流程,这时候平台才算真正获得收益。
1、高并发:广告引擎和C端流量对接,请求量大(平峰往往有上万QPS),要求实时响应,必须在几十毫秒内返回结果。
2、业务逻辑复杂:一次广告请求,涉及到多路召回、算法模型打分、竞价排序等复杂的业务流程,策略多,执行链路长。
3、稳定性要求高:广告系统直接跟收入挂钩,广告引擎以及计费平台等核心系统的稳定性要求很高,可用性至少要做到3个9。
4、大数据存储和计算:随业务发展,推广数量以及扣费订单数量很容易达到千万甚至上亿规模,另外收入报表的聚合维度多,单报表可能达到百亿级别的记录数。
5、账务的准确性:广告扣费属于金融性质的操作,需要做到不丢失、不重复,否则会损害某一方的利益。另外,如果收入数据不准确,还可能影响到业务决策。
了解了广告业务的目标和技术挑战后,接下来详细介绍下广告系统的整体架构和技术方案。
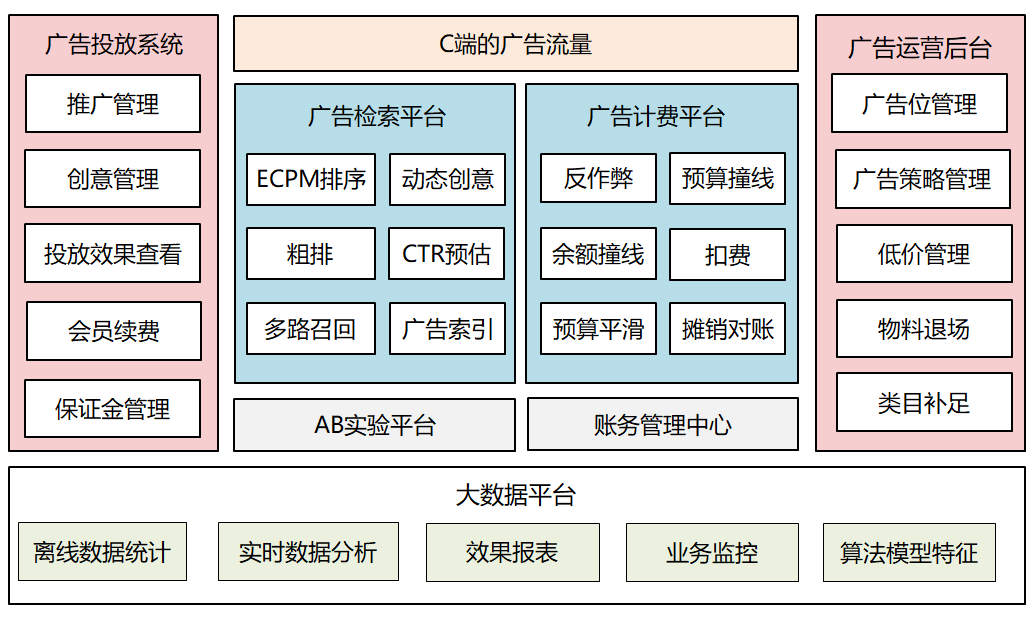
图4:广告系统的整体架构
上面是我们公司目前的广告系统架构图,这个架构适用于广告业务初期,针对的是「自营型的竞价网络和站内流量」,不涉及联盟广告。
广告投放系统:供广告主使用,核心功能包括会员续费、广告库管理、设定推广条件、设置广告出价、查看投放效果等。
广告运营后台:供平台的产品运营使用,核心功能包括广告位管理、广告策略管理、以及各种运营工具。
广告检索平台:承接C端的高并发请求,负责从海量广告库中筛选出几个或者几十个广告,实时性要求高,这个平台通常由多个微服务组成。
AB实验平台:广告业务的稳定器,任何广告策略上的调整均可以通过此平台进行灰度实验,观察收入指标的变化。
广告计费平台:面向C端,负责实时扣费,和收入直接挂钩,可用性要求高。
账务管理中心:广告业务中的财务系统,统管金额相关的业务,包括充值、冻结、扣费等。
大数据平台:整个广告系统的底盘,需要聚合各种异构数据源,完成离线和实时数据分析和统计,产出业务报表,生产模型特征等。
1. 广告数据的存储
广告系统要存储的数据多种多样,特点各不相同,采用的是多模的数据存储方式。
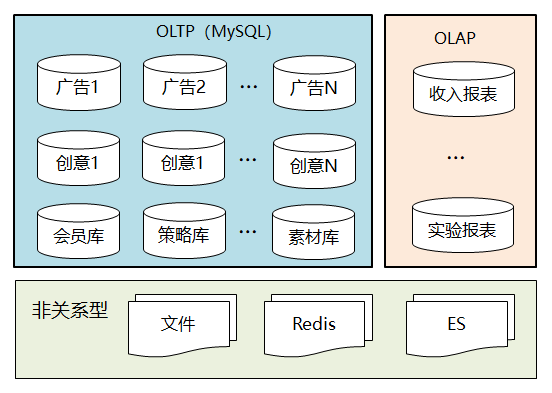
图5:广告数据的多模存储
OLTP场景,包括广告库、创意库、会员库、广告产品库、广告策略库等,这些都存储在MySQL中,数据规模较大的广告库和创意库,按照广告主ID Hash做分库分表。 OLAP场景,涉及到非常多的报表,聚合维度多,单表的记录数可能达到百亿级别,底层采用HDFS和HBase存储。
面向广告检索场景的索引数据,包括正排索引和倒排索引,采用Redis和ES来存储。
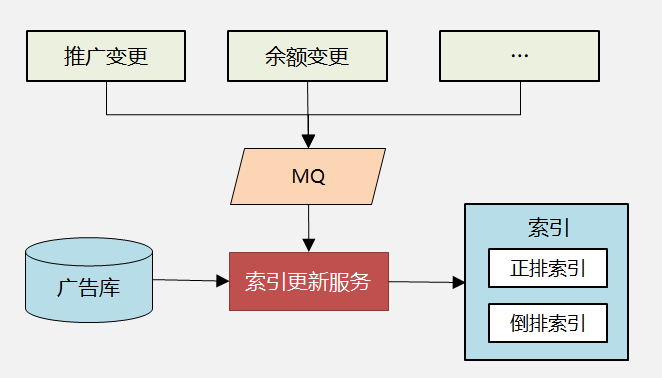
图6:广告索引的更新流程
索引更新服务,有几个要点说明下:
各个业务系统在推广、余额等信息变更时,发MQ消息,索引更新服务订阅MQ来感知变化,完成增量同步。
变更的消息体中,不传递实际变更的字段,仅通知有变化的广告ID,索引更新服务实时读取最新数据完成更新,这样可以有效的解决消息乱序引起的数据不一致问题。
当更新索引的并发达到一定量级后,可通过合并相同广告的变更、或者将倒排和正排更新分离的方式来提升整体的更新速度。
2. 广告检索平台的整体流程
广告检索平台负责承接C端的流量请求,从海量广告库中筛选出最合适的前N个广告,并在几十毫秒内返回结果,它是一个多级筛选和排序的过程。
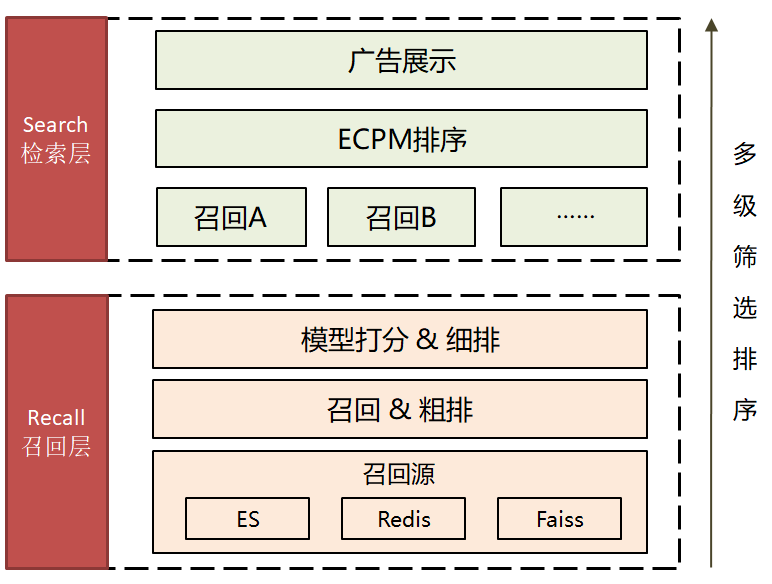
Recall层侧重算法模型,Search层侧重业务。从下到上,计算复杂度逐层增加,候选集逐层减少。(说明:搜索广告场景和推荐广告场景在某些子模块上存在差异,但整体流程基本一致,这里不作展开)
性能设计是检索平台的重点,通常有以下手段:
做好服务分层,各层均可水平扩展。
采用Redis缓存,避免高并发请求直接打到数据库,缓存可按业务规划多套,进行分流。
采用多线程并行化某些子流程,比如多路召回逻辑、多模型打分逻辑。
热点数据进行本地缓存,比如广告位的配置信息以及策略配置信息,在服务启动时就可以预加载到本地,然后定时进行同步。
非核心流程设置超时熔断走降级逻辑,比如溢价策略(不溢价只是少赚了,不影响广告召回)。
和主流程无关的逻辑异步执行,比如扣费信息缓存、召回结果缓存等。
精简RPC返回结果或者Redis缓存对象的结构,去掉不必要的字段,减少IO数据包大小。
GC优化,包括JVM堆内存的设置、垃圾收集器的选择、GC频次优化和GC耗时优化。
3. 计费平台的技术方案
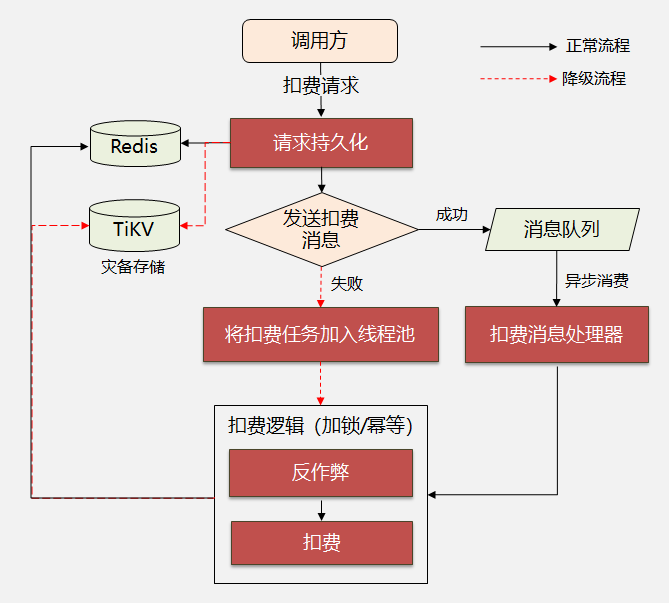
首先,整个扣费流程做了异步化处理,当收到实时扣费请求后,系统先将扣费时用到的信息缓存到Redis,然后发送MQ消息,这两步完成后扣费动作就算结束了。
这样做的好处是:能确保扣费接口的性能,同时利用MQ的可靠性投递和重试机制确保整个扣费流程的最终一致性。
为了提高可用性,针对Redis和MQ不可用的情况均采用了降级方案。Redis不可用时,切换到TiKV进行持久化;MQ投递失败时,改成线程池异步处理。
另外,每次有效点击都需要生成1条扣费订单,面临大数据量的存储问题。目前我们采用的是MySQL分库分表,后期会考虑使用HBase等分布式存储。另外,订单和账务系统之间的数据一致性,采用大数据平台做天级别的增量抽取,通过Hive任务完成对账和监控。
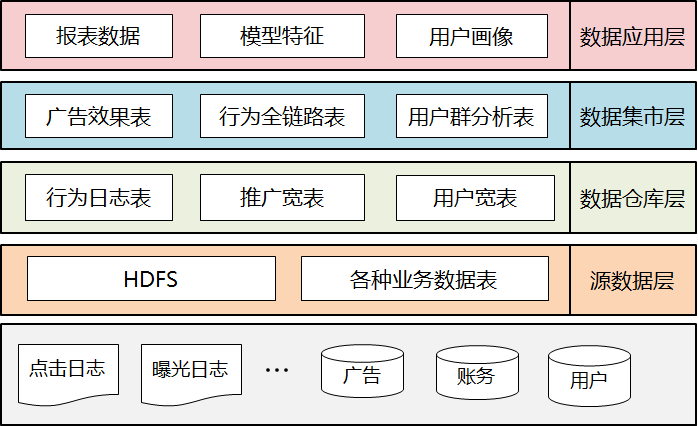
图9:广告数据仓库的分层结构
源数据层:对应各种源数据,包括HDFS中实时采集的前后端日志,增量或者全量同步的MySQL业务数据表。
数据仓库层:包含维度表和事实表,通常是对源数据进行清洗后的数据宽表,比如行为日志表、推广宽表、用户宽表等。
数据集市层:对数据进行轻粒度的汇总表,比如广告效果表、用户行为的全链路表、用户群分析表等。
数据应用层:上层应用场景直接使用的数据表,包括多维分析生成的各种收入报表、Spark任务产出的算法模型特征和画像数据等。
写在最后
END
有热门推荐?
1. Docker 被禁?还有千千万万个 Docker 站起来!!
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
