转自:机器之心
作为 Python 语言的一个扩展程序库,Numpy 支持大量的维度数组与矩阵运算,为 Python 社区带来了很多帮助。借助于 Numpy,数据科学家、机器学习实践者和统计学家能够以一种简单高效的方式处理大量的矩阵数据。那么 Numpy 速度还能提升吗?本文介绍了如何利用 CuPy 库来加速 Numpy 运算速度。就其自身来说,Numpy 的速度已经较 Python 有了很大的提升。当你发现 Python 代码运行较慢,尤其出现大量的 for-loops 循环时,通常可以将数据处理移入 Numpy 并实现其向量化最高速度处理。但有一点,上述 Numpy 加速只是在 CPU 上实现的。由于消费级 CPU 通常只有 8 个核心或更少,所以并行处理数量以及可以实现的加速是有限的。何为 CuPy?

CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。CuPy 接口是 Numpy 的一个镜像,并且在大多情况下,它可以直接替换 Numpy 使用。只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。CuPy 支持 Numpy 的大多数数组运算,包括索引、广播、数组数学以及各种矩阵变换。如果遇到一些不支持的特殊情况,用户也可以编写自定义 Python 代码,这些代码会利用到 CUDA 和 GPU 加速。整个过程只需要 C++格式的一小段代码,然后 CuPy 就可以自动进行 GPU 转换,这与使用 Cython 非常相似。在开始使用 CuPy 之前,用户可以通过 pip 安装 CuPy 库:pip install cupy
使用 CuPy 在 GPU 上运行
- 32 GB of DDR4 3000MHz RAM
CuPy 安装之后,用户可以像导入 Numpy 一样导入 CuPy:import numpy as np
import cupy as cp
import time
在接下来的编码中,Numpy 和 CuPy 之间的切换就像用 CuPy 的 cp 替换 Numpy 的 np 一样简单。如下代码为 Numpy 和 CuPy 创建了一个具有 10 亿 1』s 的 3D 数组。为了测量创建数组的速度,用户可以使用 Python 的原生 time 库:### Numpy and CPU
s = time.time()
*x_cpu = np.ones((1000,1000,1000))*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu = cp.ones((1000,1000,1000))*
e = time.time()
print(e - s)
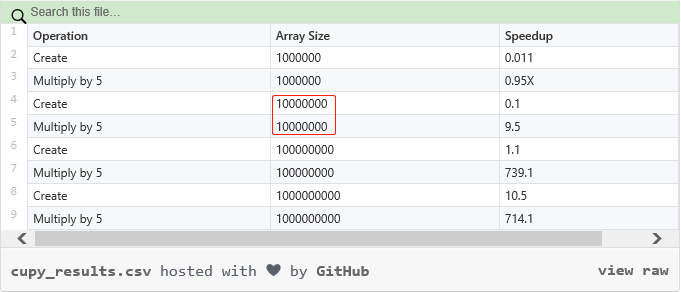
令人难以置信的是,即使以上只是创建了一个数组,CuPy 的速度依然快得多。Numpy 创建一个具有 10 亿 1』s 的数组用了 1.68 秒,而 CuPy 仅用了 0.16 秒,实现了 10.5 倍的加速。比如在数组中做一些数学运算。这次将整个数组乘以 5,并再次检查 Numpy 和 CuPy 的速度。### Numpy and CPU
s = time.time()
*x_cpu *= 5*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5*
e = time.time()
print(e - s)
果不其然,CuPy 再次胜过 Numpy。Numpy 用了 0.507 秒,而 CuPy 仅用了 0.000710 秒,速度整整提升了 714.1 倍。
### Numpy and CPU
s = time.time()
*x_cpu *= 5
x_cpu *= x_cpu
x_cpu += x_cpu*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5
x_gpu *= x_gpu
x_gpu += x_gpu*
e = time.time()
print(e - s)
结果显示,Numpy 在 CPU 上执行整个运算过程用了 1.49 秒,而 CuPy 在 GPU 上仅用了 0.0922 秒,速度提升了 16.16 倍。数组大小(数据点)达到 1000 万,运算速度大幅度提升使用 CuPy 能够在 GPU 上实现 Numpy 和矩阵运算的多倍加速。值得注意的是,用户所能实现的加速高度依赖于自身正在处理的数组大小。下表显示了不同数组大小(数据点)的加速差异:数据点一旦达到 1000 万,速度将会猛然提升;超过 1 亿,速度提升极为明显。Numpy 在数据点低于 1000 万时实际运行更快。此外,GPU 内存越大,处理的数据也就更多。所以用户应当注意,GPU 内存是否足以应对 CuPy 所需要处理的数据。原文链接:https://towardsdatascience.com/heres-how-to-use-cupy-to-make-numpy-700x-faster-4b920dda1f56
往期精彩:
TransUNet:基于 Transformer 和 CNN 的混合编码网络
SETR:基于视觉 Transformer 的语义分割模型
ViT:视觉Transformer backbone网络ViT论文与代码详解
【原创首发】机器学习公式推导与代码实现30讲.pdf
【原创首发】深度学习语义分割理论与实战指南.pdf
求个在看