
不会真有人觉得聊天机器人难吧(二)

引言
本文介绍传统的检索排名技术实现。教你如何实现输入一个问句,快速查询到最相关的文档。
单词权重
假设你有很多文档(称为语料库,corpus),你想实现输入一个问句,快速查询到最相关的文档。
首先是要让计算器理解文档和问句,这里需要的是进行分词,得到问句或每个文档的单词列表,然后去掉重复的单词就可以得到单词词典。
根据单词词典利用下面介绍的TF-IDF算法可以得到每个问句或文档的向量表示,接着可以利用余弦相似度计算问句和所有文档的相似度,根据相似度排名可以找到最相似的文档。 该方法可以参考TF-IDF文本表示。但是本文介绍的是另一种方法,通过计算问句和每篇文档的相关度得分,根据得分就可以得到相似文档排名。
不管是哪种方法都需要计算单词的权重,所谓权重可以认为是某个单词对该篇文章主题的贡献度。比如谈论体育的文章里面,多次出现了“篮球”和“的”。“的”出现的次数很有可能是超过“篮球”出现的次数,我们不能说“的”比“篮球”对于该主题来说更重要。因此除了频次还有其他指标需要考虑。
常用方法的是和它的变体BM25。
TF-IDF
词频(term frequence) 反映了单词的频率,单词在某篇文章中出现的越多,越可能由它反映文章的内容。通常会对词频取对数,因为某个单词出现了100次,并不见得它对文章的贡献有100倍那么重要。因为是无意义的,因此我们加了一个:
词频有很多种计算方法,还有一种方法是用单词在文章中出现的次数,除以文章中单词的总数,这种方法其实更符合词频的字面意思。但是上面的方法也不错。
文档频率(document frequence) 反映了出现单词的文档的数量。基于常理,我们知道只在一小部分文档中出现的单词通常更助于这些文档的区分度。而在整个集合中的文档都出现的单词通常是没什么帮助的,比如“的”、“呢”这些词。
逆文档频率(inverse document frequency) 单词权重被定义为:
其中是集合中文档的总数;是单词出现的文档数量;
从公式可以看出,某个单词出现的文档数量越小,它的权重就越大;如果它在所有文档中都出现,那么,表示权重最低。
就是用词频乘以逆文档频率,表示单词在文档中的权重:
下面我们重点介绍它的变体——BM25。
BM25
一个的变体是BM25,它增加了两个参数:和。其中用来平衡和;控制文档长度的重要性。给定计算文档的BM25得分公式如下:
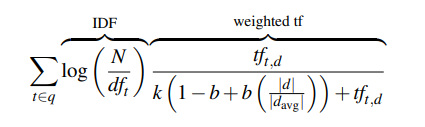
其中是文档长度;是文档集合中平均文档长度。
假设,那么加权的就是,其中是用来控制的增速的,假设某篇文章单词出现200次,它能带来的相关性是出现100次的两倍吗?
假设出现了100次,那么该篇文章肯定是与有关的,如果再出现更多的次数带来权重也不应该增加这种相关性了。使用就能避免它的无限增大,相当于达到某个阈值就饱和了。

上图是不同的值得到的曲线,越大,曲线越缓和。当时,BM25就没有计算,只是使用了。

引入的目的是考虑文档长度,如果某篇文章很短,出现了某个单词1次,和某篇文章特别长,但是也只出现了2次。我们就想让文章的长度来控制的取值,如果文章很长,那么就取大一点,得到的就小一点;反之文章很短,那么就设小一点。如何才能知道文章是短是长呢?这里的做法就是用它的长度和平均长度作比较,如果大于平均,那么就是相对较长。
而引入就是为了控制文章长度的重要性,的取值范围是。若,那么完全不考虑文章长度;若,如果文章较长,那么就增大;如果文章较短,那么就减少。下图是和相关的图形:
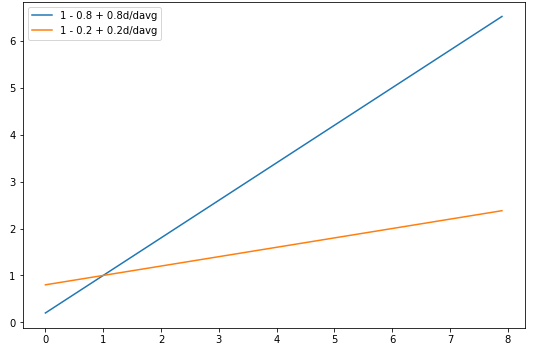
从中可以看出,越大,对文章长度的惩罚也越大。
常用的取值。
关于也有一种变体叫作概率IDF(probabilistic IDF),它的公式为
这样得到的对出现在较多文档中的单词来说是急剧下降的,但是它可能得到负值,Lucene的实现是在最后加,防止出现负值:
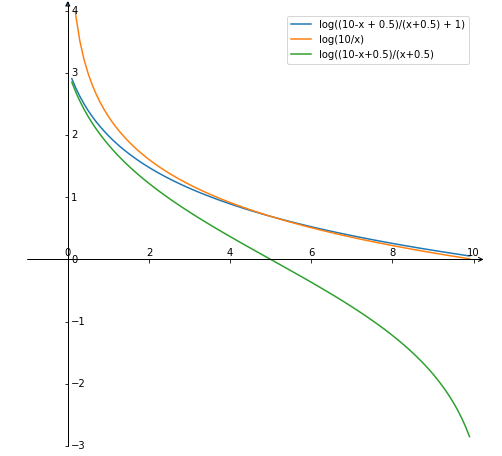
假设,代表的取值,上图是原始的与它两种变体的图形。可以看到,Lucene的实现的图形和传统的图形类似。
代码实现
def get_score(self, word, doc_id, doc_freq):
'''
计算bm25
:param word:
:param doc_id: 文档在语料库中的id
:param doc_freq: 出现单词word的文档数量
:return:
'''
tf = self.idx[word][doc_id]
if not tf:
return 0
tf = self._compute_weighted_tf(tf, self.dl[doc_id], self.dl.get_avg_len())
idf = self._compute_probabilistic_idf(doc_freq)
return tf * idf
def _compute_weighted_tf(self, tf, doc_len, avg_doc_len):
return tf * (self.k + 1) / (self.k * (1 - self.b + self.b * doc_len / avg_doc_len) + tf)
def _compute_probabilistic_idf(self, df):
return math.log((len(self.dl) + 1) / (df + 0.5))
def get_scores(self, query):
query = self.tokenize(query) if self.tokenize else query
scores = np.zeros(len(self.dl))
for word in query:
# 利用倒排索引,提升查询效率,我们可以不需要计算不出现查询单词的文档
if word in self.idx:
for doc_id in self.idx[word].keys():
scores[doc_id] += self.get_score(word, doc_id, len(self.idx[word]))
return scores
倒排索引
为了计算相似度,我们需要高效的找到包含查询中单词的文档集合。
通常解决这个问题的方法是使用倒排索引(inverted index)。
在倒排索引中,给定一个查询词,可以很快找到包含该查询词的文档列表。
倒排索引包含两部分,一个字典和ID列表。字典中包含了所有的单词,每个单词指向一个出现该单词的文档ID列表。其中还可以词频或甚至是单词在文档中出现的位置信息。

比如上面就是一个简单的倒排索引,基于下面这4个简单的文档集合实现。其中包含了单词的总数,以及每个文档中该单词出现的次数。这样可以很方便地计算。

代码实现
import collections
class Dictionary(dict):
'''
倒排索引用到的数据结构
word -> postings(doc_id->word_count)
'''
def __missing__(self, key):
# Python中如果字典找不到key这个键,那么会调用该方法,我们在该方法中返回一个defaultdict
# 可以避免很多if else
postings = collections.defaultdict(int)
self[key] = postings
return postings
class InvertedIndex:
def __init__(self):
self.dictionary = Dictionary()
def add(self, doc_id, doc):
for word in doc:
postings = self.dictionary[word]
postings[doc_id] += 1
def __contains__(self, word):
return word in self.dictionary
def __getitem__(self, word):
return self.dictionary[word]
def __len__(self):
'''
:return: 语料库中的单词数量
'''
return len(self.dictionary)
def get_doc_frequency(self, word):
'''
得到单词出现的文档数量
:param word:
:return:
'''
return len(self.dictionary[word])
评估IR系统
我们评估排序的IR系统表现通过精确率(precision)和召回率(recall)指标。
精确率表示返回的文档中属于相关文档的比例;
召回率表示返回相关的文档占总相关文档数的比例;
是返回的文档数;
是返回的文档中相关文档的数量;
是返回的文档中不相关文档的数量;
是所有文档中相关文档的数据;
假设有50篇相关文档,你的查询算法返回了10篇,其中9篇是相关的,1篇是不相关的。
那么准确率就是,召回率是
测试
数据使用的是网上找到的医疗问答数据,它是长这个样子的:

比如,我们查询“医生,我肛门处非常痒怎么办”相关的相似问题。
def main():
data_path = './data/questions.csv'
df = pd.read_csv(data_path, usecols=['content'])
corpus = df['content'].tolist()
# 传入语料库,和分词方法
bm25 = OkapiBM25(corpus, tokenize=jieba.lcut)
query = "医生,我肛门处非常痒怎么办"
result = bm25.get_top_k(query, corpus=corpus, k=5)
for q in result:
print(q)
打印的结果如下:
肛门处有湿疹,非常痒,怎么办
痔疮,肛门处很痒,大便有点疼痔疮,肛门处很痒,大便有点疼
肛门非常痒怎么办肛门很痒之前只是有意无意的感觉,可是现在特别痒有的地方用手碰还刺痛,严重痒时像被蚊子哎,特别是晚上,我该怎么办啊!
我有轻微的内痔,肛门处总是很痒怎么办啊?
我肛门痒,该怎么办
这是返回最相似的5个问句,是不是像那么回事。
完整代码
完整代码:https://github.com/nlp-greyfoss/nlp-algorithms/tree/main/bm25
最后一句:BUG,走你!


没有人比我更懂Redis(一)
没有人比我更懂Redis(二)
不会真有人角色聊天机器人难吧(一)
自然语言处理入门之分词
入门人工智能必备的线性代数基础
1.看到这里了就点个在看支持下吧,你的在看是我创作的动力。
2.关注公众号,每天为您分享原创或精选文章!
3.特殊阶段,带好口罩,做好个人防护。