| 导语 :你是否也曾被“快点儿吧,等到花都谢了”洗脑,为又爱又恨的欢乐豆决战到天亮,为何欢乐斗地主能风靡全国,经久不衰,还一直能平稳流畅运行?其背后究竟有哪些运维小妙招?可让整体研运效率显著提升,节省30%+人力成本?.....作者简介:Leehom,腾讯游戏专家开发工程师,负责腾讯欢乐游戏大规模分布式服务器架构。有十余年微服务架构经验,擅长分布式系统领域,有丰富的高性能高可用实践经验,目前正带领团队完成云原生技术栈的全面转型。基本信息:
客户名称:腾讯欢乐斗地主
行业:IT服务/软件 游戏行业
涉及产品:腾讯云 Prometheus 监控服务、Grafana 可视化服务、容器服务
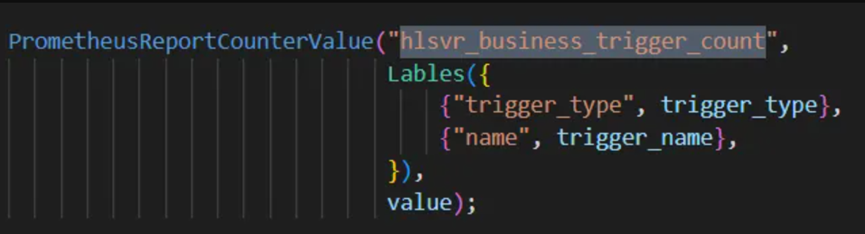
2008年,欢乐斗地主横空出世。是一款由腾讯公司-欢乐游戏工作室开发和运营的在线棋牌小游戏。在整个国内棋牌游戏领域,《欢乐斗地主》则一直是探索品类边界的领头羊,腾讯游戏家族里普及年龄最广的游戏产品。据 GameLook 了解,自 App Annie 在 2017 年公布全球手游 MAU 数据以来,《欢乐斗地主》一直是中国区全品类手游 MAU 年度前五。目前累计用户数已过亿,其活跃用户长期处于一个较高水平。后台采用分布式微服务架构,承载着数百万 DAU ,在这种大规模平台化的后台系统和复杂多样的业务架构下,给监控运维带来了极大的挑战。云原生经历了7年多的发展,已经进入了大规模实践阶段,应用极其广泛,互联网、金融、电信、汽车等各大行业均有其身影。近年来,也越来越多的腾讯业务走向云原生。腾讯欢乐斗地主也深入参与其中。欢乐斗地主业务全面上云后,服务全量部署于 腾讯云容器服务 TKE 之中。上云后,旧的监控方案已无法适用。众所周知,Prometheus 是容器场景的最佳监控工具。但是自建 Prometheus 对于目前项目运维人力,显得成本略高。同时也容易出现性能瓶颈。经过综合考虑,团队决定采用 腾讯云Prometheus 监控服务(TMP) 作为监控系统,抓取并存储指标。本文将分享监控体系实践的一些阶段性经验感悟。在复杂的游戏业务架构下,经过细致分析和基于云原生技术的持续重构演进,深度结合 K8s 以及 Prometheus 监控服务,最终实现游戏业务场景下架构平稳平滑运行。对于业务模块的可靠性、可观测性、可维护性大幅提高,整体研运效率提升十分明显,每月可有效节省超过30%的人力成本。基于统一规范上报的考虑,在代码框架层面直接收拢了上报的 metric 名,仅通过 label 进行指标的区分。例如:counter 类指标,metric 名统一叫做 hlsvr_business_trigger_count,只是 label 取值不同。目前框架二次封装的接口,根据以往经验,仅需设置两个 label 参数就够用。注1:该步骤是建立在团队习惯 all in one Dashboard 的基础上,可结合您的业务情况来做实践。
注2:对于一些需要更多 label 的业务场景,业务也可以上报,只是使用另外的接口,metric 名也可以自定义。通过 servicemonitor 配置采集的任务,根据业务需求,这里只配置一个涵盖所有服务的 servicemonitor。欢乐斗地主同时还使用云监控提供的Grafana 可视化服务展示监控数据,对于 Grafana Dashboard 的维护,我们有做过两种尝试:Grafana as code 的方式和直接页面维护的方式。Grafana as code 的维护方式,是通过 yaml 来做 Dashboard 的管理,将所有曲线和告警,都写到 yaml 中,然后使用 helm 去做部署。使用 yaml 可以和服务自身内容写在一起,部署服务 yaml 的时候一起部署 Dashboard,将内聚到服务本身的 yaml 之中。但从功能角度来看,有时候仅仅想微调监控模块,还需要去变更服务的 yaml,加上 helm 仓库管理操作比较复杂,存在误带出去非监控 yaml 变更的可能。所以综合考虑,建议将告警都写到一个 Grafana as code 的 yaml 文件之中,Dashboard 拆分成多个,但是 yaml 文件只需一份。这样在变更 Dashboard yaml 的时候,只会影响到一个 Dashboard。采用 Grafana as code 的配置方式,可以结合 git 和流水线,实现自动归档,也方便做一些基于 yaml 的批量修改。由于修改 yaml 来生成 Dashboard,调试期就比较不直观,无法所见即所得,因此还得同时支持页面手工调整,然后反向推送回 git 仓库,但这样一来操作就会显得有些繁琐(改 yaml -- 提交 git -- helm 部署 -- 页面观察 -- 手工调整到理想效果 -- 反向推送回仓库)。相对地,直接在 Grafana 页面上进行维护的方式,显得十分直观,所见即所得,直接页面改完保存即可。但如果想做批量的修改,可以导出 Json model 批量处理 Json 。由于我们使用了统一 Dashboard(见下文),不需要创建和维护过多的 Dashboard,因此对批量维护的诉求不高,考虑到操作的简便性,目前采用的是直接在 Grafana 页面上进行维护的方式。由于 metric 名已被固定,就可以制作一个统一的 Dashboard 来覆盖所有服务,将服务名做成一个下拉框即可选择要观测的目标服务。上线一个新的服务,直接复用上述 Dashboard 即可。目前欢乐斗地主项目只会在一些特殊情况(例如使用了更多的维度、自定义 metric 名,或者相关指标本身非常重要,希望独立呈现)时,才创建维护额外专属的 Dashboard。根据欢乐斗地主业务情况,我们做了一个统一监控 Dashboard,通过 Explore 目标曲线以获取到相关的 PromQL 语句,再基于 Panel Library 去创建监控用的 Panel。对于有些需要单独呈现的告警,也可以单独创建维护,可不放在统一监控 Dashboard 中。1)使用统一的 metric 名来做上报,方便统一和维护 Dashboard。
2)使用一个全局 servicemonitor 来作为抓取任务。
3)直接通过 Grafana 页面手工维护 Dashboard。
4)对于指标查看,一个统一查看 Dashboard + 一些专属查看 Dashboard。
5)对于指标监控,一个统一监控 Dashboard + 一些专属监控 Dashboard。使用了基于 label 的数据结构设计,很方便做维度聚合,这点相对于没有维度聚合的监控系统来讲,有点领先一代的真香味儿了!Prometheus 设计了 PromQL 语句作为查询接口,接口的表达能力非常强大。通过PromQL可以实现对监控数据的查询、聚合。同时 PromQL也被应用于数据可视化(如Grafana)以及告警当中。上述两个 Prometheus 的亮点,再对比 SQL 类存储的典型能力,会发现有些神似的东西(索引 + group by -- label,sql语句 -- promQL 语句)。
小编参阅了 Prometheus 核心开发者 Fabian Reinartz 写的 《Write a time series database from scratch》,又简单看了一些其他时序数据库的资料,发现其中最核心的设计思想,其实不是什么新花招,都是些历久弥新的老方法。1)缓存:通过缓存来做访问加速,可以有多级缓存。
2)顺序写盘 + 合并写入:提高磁盘吞吐。
3)SSD:提高 IO 性能。
4)索引:提高读性能,可以有多级索引、倒排索引。
5)mmap:使用操作系统自己的内存管理。
6)有序化处理:方便做交集、查找、索引。
7)压缩:降低磁盘空间开销。
8)备份:提高可用性。
9)sharding:提高伸缩性。
10)WAL:write ahead log,辅助内存数据的可靠落地、延迟落地。2.3 为什么选择腾讯云 Prometheus 监控服务
对于欢乐斗地主项目而言,Prometheus 监控服务天然集成 Grafana,腾讯云容器服务(TKE)高度集成,符合项目构建环境,能基本满足欢乐斗地主项目需求。而且 TMP 又是基于开源 Prometheus 构建的高可用、全托管的服务,我们还要啥自行车呢?欢乐斗地主使用腾讯云 Prometheus 监控服务作为主要的监控系统,还算能迎刃而解的,总体上没有遇到过太棘手的问题,小编在这里总结了几个小坑,让你可以在监控过程中少走弯路。1)为每个服务单独配置了一个 servicemonitor,导致 Prometheus CPU过高。
2)使用 Grafana 做 Dashboard,对上千取值的 label 做 repeated panel,查看对应项出现卡顿。
3)误用 url 作为 label,而 url 中包含了可变参数,导致高基数。
第 2 点和第 3 点其实比较显然,我们的解决办法是避开高基数问题,修改业务的 API 调用代码。近年来,越来越多开发者选择大规模使用 腾讯云容器服务 TKE 来部署、管理服务。在用户购买 TKE 服务之后,监控其 K8s 环境成为了必须,而 Prometheus 因其强大的指标采集能力、活跃的生态和灵活的 PromSQL 成为了不少研发和运维人员监控 K8s 的第一选择。Prometheus + Grafana 已经成为云原生时代的可观测性事实标准。2022年4月,腾讯云容器服务联合腾讯云 Prometheus 监控服务,推出升级托管 Prometheus 监控,全面支持开源 Prometheus 和开源 Grafana 能力,同时还结合云监控告警和 Prometheus Alertmanager 能力。实现了云原生 K8s 体系下 metric 可观测闭环。https://cloud.tencent.com/product/tkehttps://cloud.tencent.com/product/tmphttps://cloud.tencent.com/product/tcmg