
联邦学习|微众银行首席AI官杨强:联邦学习理论基础、四大应用场景与微众的AI全布局

作者 | 李雷
内容来源|雷锋网

1
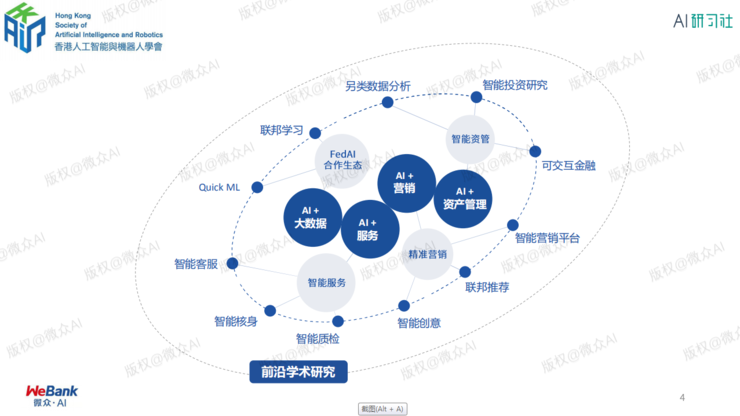
金融小数据与隐私保护的双重挑战

2
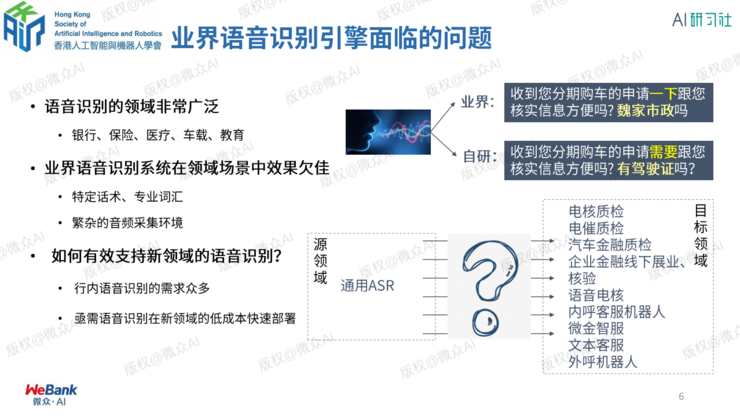
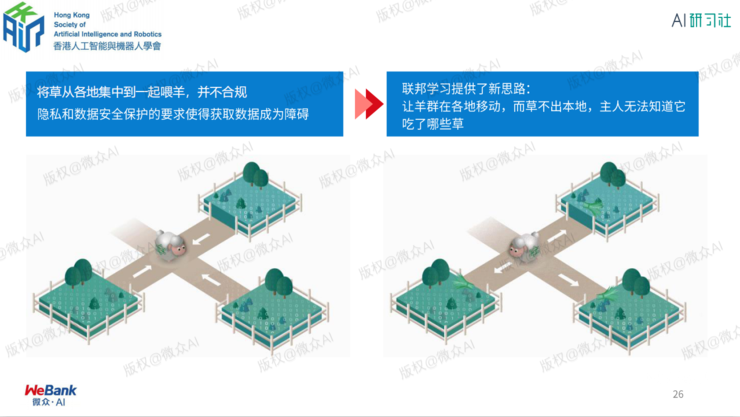
何为联邦学习?
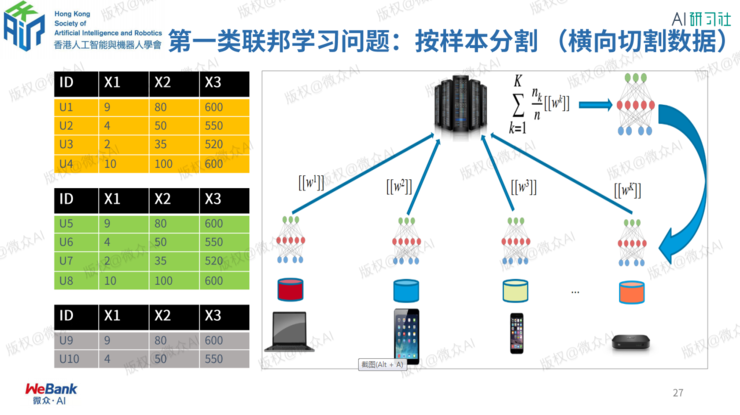

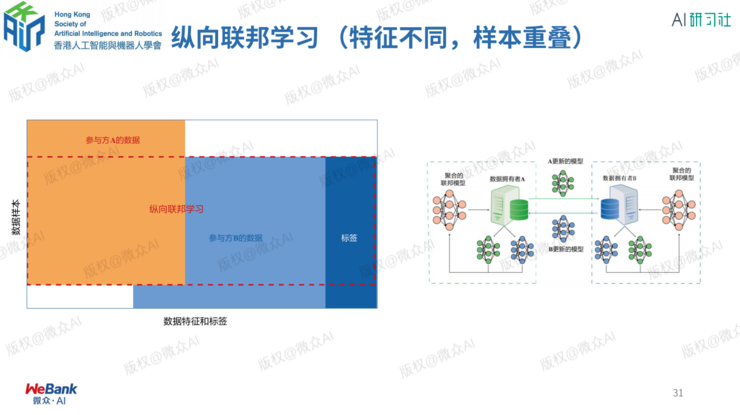

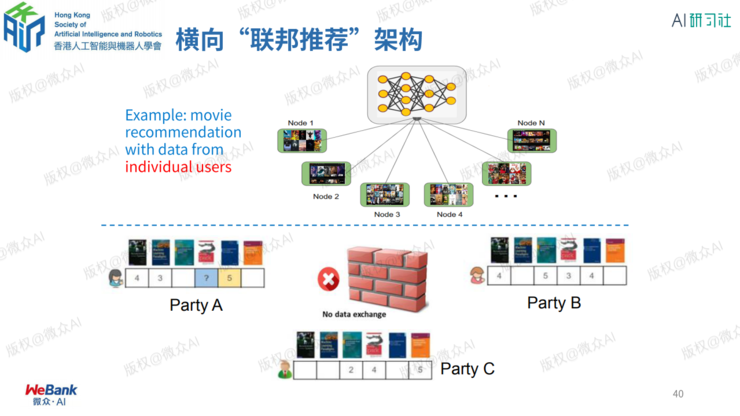
3
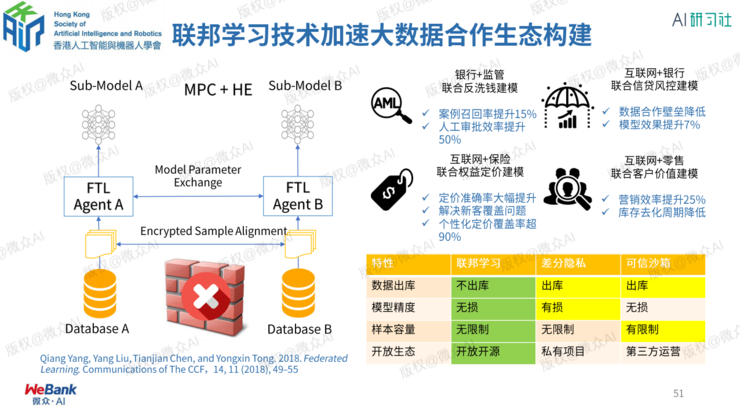
联邦学习应用案例
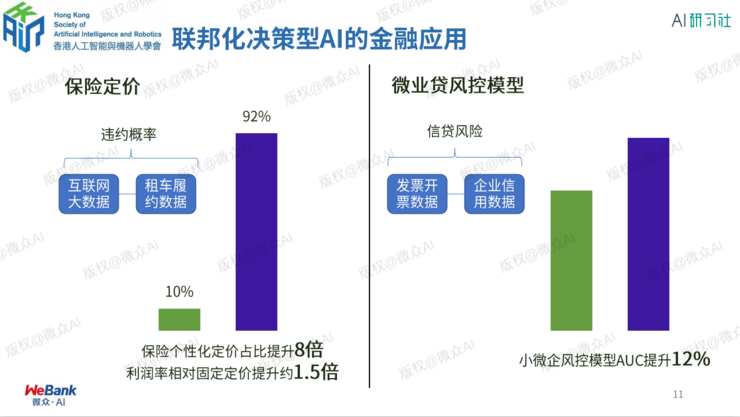
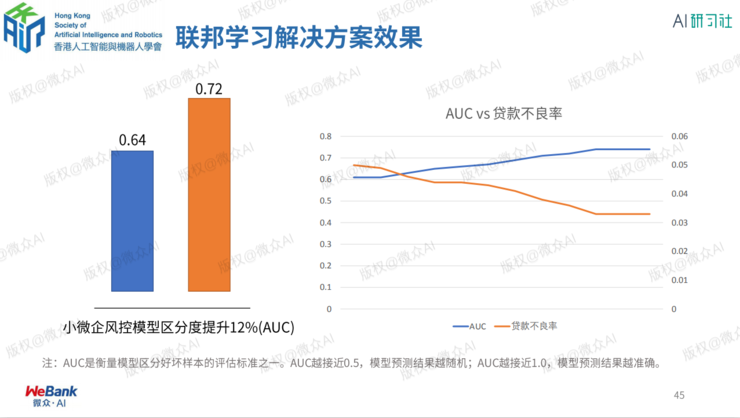
小微企业信贷风控
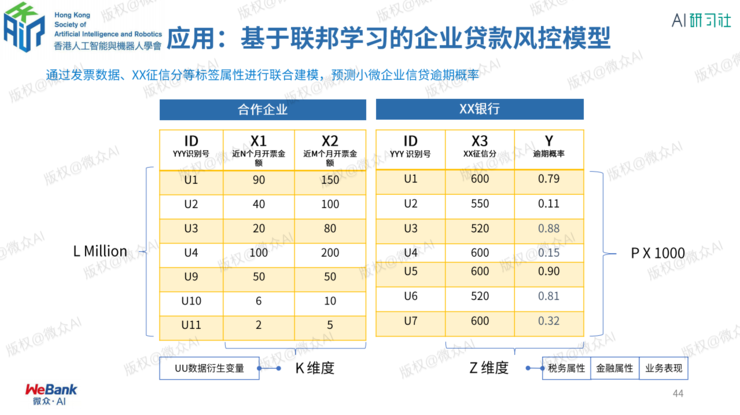
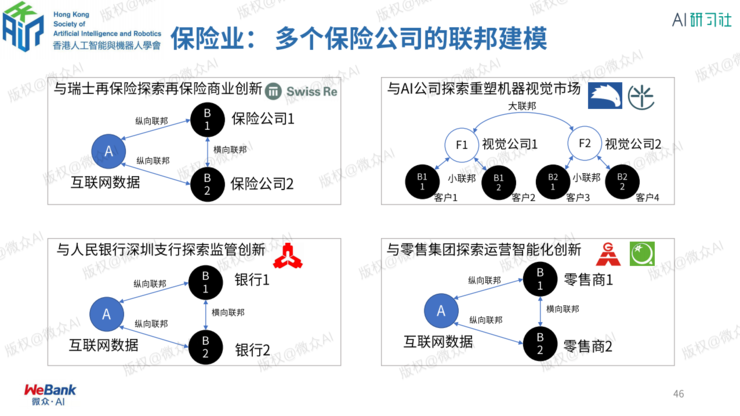
保险联邦建模
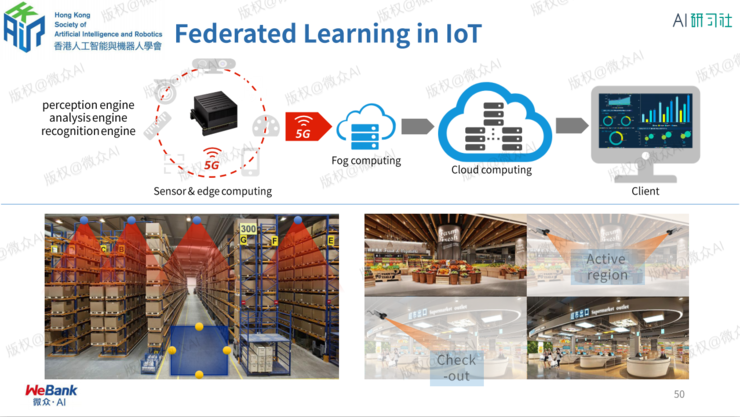
计算机视觉

医学应用
我是做金融科技领域的数据挖掘和应用工作,主要聚焦于联邦学习在金融科技领域的创新和应用,即如何利用联邦学习框架解决好金融科技领域的营销和风控两大重要主题的系列问题。
我创建了一个联邦学习群,大家相互学习和交流,争取早日把这个技术在工业界上落地开花结果。可以添加我的微信,备注:姓名-FL,一起探索。
评论