
Python 实现快递物流信息查询
大家后,我是一行

就一个问题,你的快递到了吗?没到,那快看下这篇分享
希望你拼命争取的,最后都能如你所愿。
一、分析网页
快递100网站可以很方便的查询快递的物流信息
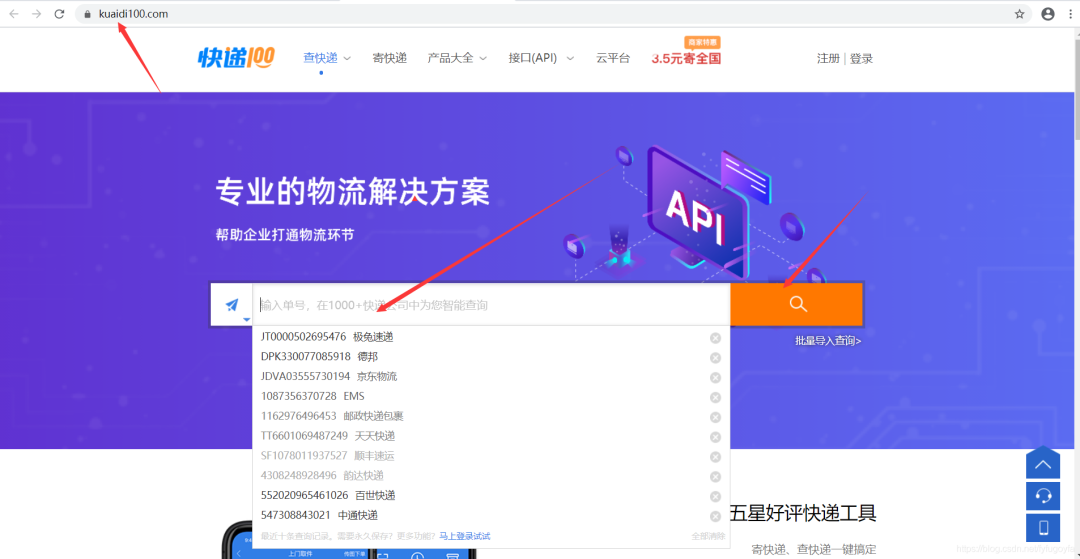
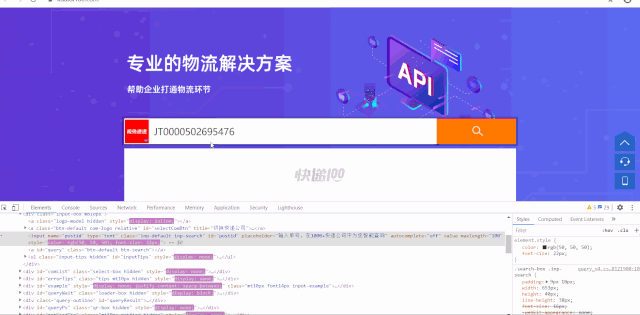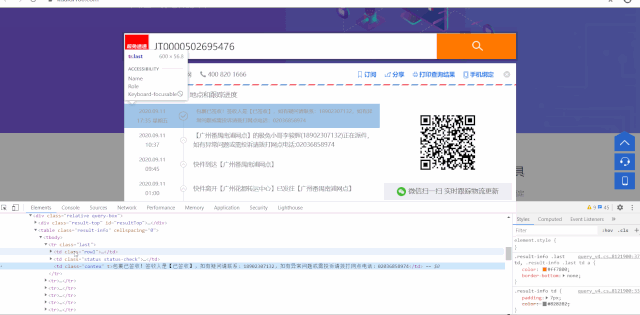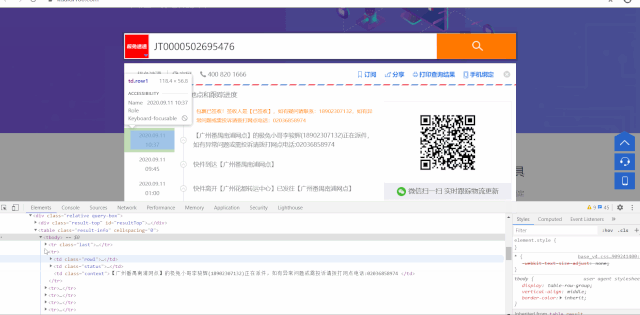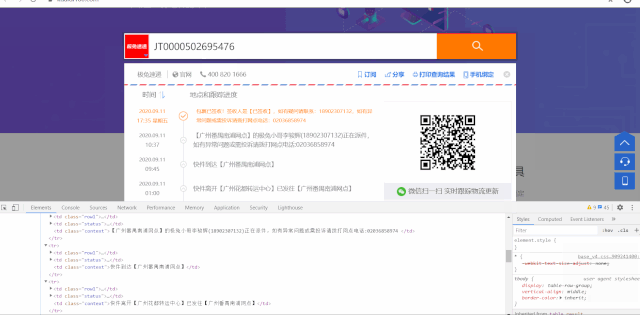
二、python代码实现
1. selenium爬虫实现查询
# 根据快递单号查询物流信息
def get_screenshot_and_info():
chrome_driver = r'D:\python\pycharm2020\chromedriver.exe' # chromedriver的路径
options = webdriver.ChromeOptions()
# 关闭左上方 Chrome 正受到自动测试软件的控制的提示
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option("excludeSwitches", ['enable-automation'])
# 开启浏览器对象
browser = webdriver.Chrome(options=options, executable_path=chrome_driver)
# 访问这个url
browser.get('https://www.kuaidi100.com/')
# 显示等待
wait = WebDriverWait(browser, 5)
wait.until(ec.presence_of_element_located((By.ID, 'menu-track')))
# 窗口最大化
browser.maximize_window()
browser.find_element_by_name('postid').send_keys(nums)
browser.find_element_by_id('query').click()
time.sleep(1)
browser.find_element_by_id('query').click()
time.sleep(2)
browser.execute_script("window.scrollBy(0, 488)")
# 截图
browser.get_screenshot_as_file(filename='info.png')
items = browser.find_elements_by_xpath('//table[@class="result-info"]/tbody/tr')
print('物流信息查询结果如下:\n')
for item in items:
time_ = item.find_element_by_xpath('.//td[1]').text.replace('\n', ' ')
contex = item.find_element_by_xpath('.//td[3]').text
print(f'时间:{time_}')
print(f'状态:{contex}\n')
browser.quit()
# 显示截图
src = cv.imread(filename='info.png')
src = cv.resize(src, None, fx=0.7, fy=0.7)
cv.imshow('result', src)
cv.waitKey(0)
运行效果如下:
2. requests爬虫实现查询
def query_info(i, j):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24',
"Referer": "https://www.kuaidi100.com/"
}
url = f'https://www.kuaidi100.com/query?type={j}&postid={i}&temp=0.53162373256954096&phone='
resp = requests.get(url, headers=headers)
# print(resp.text)
datas = json.loads(resp.text)['data']
# print(datas)
print('您的快递物流信息查询结果如下:\n')
for item in datas:
time_ = item['time']
info = item['context']
print(f'时间:{time_}')
print(f'物流状态:{info}' + '\n')
运行结果如下:
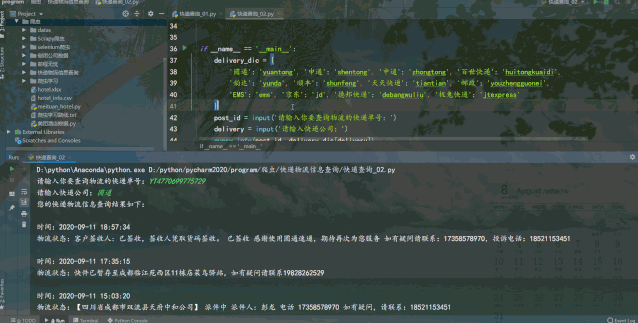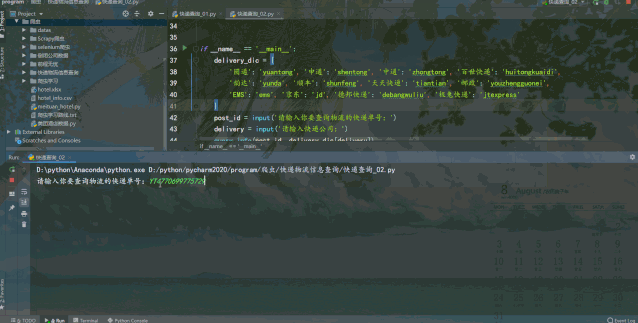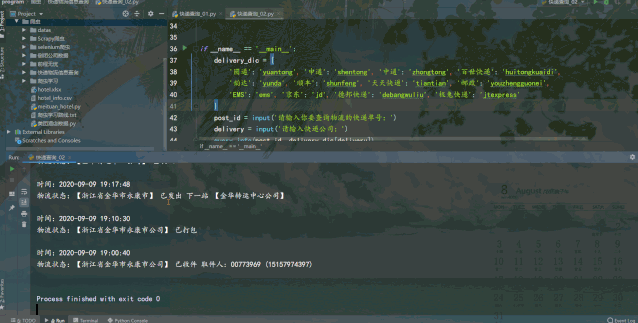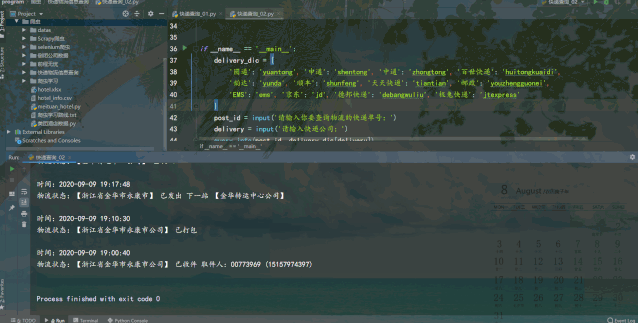
requests爬虫查询速度较快,但需要输入快递公司,便于构造接口url来请求查询。
结语
以上两种版本的完整代码可后台回复快递获得,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对小编的支持。

推荐阅读
(点击标题可跳转阅读)
点击阅读原文,积分可以免费换书
评论