漫话:如何给女朋友解释为什么计算机从0开始计数,而不是从1开始?

导读:为什么计算机从0开始计数,而不是从1开始?
作者 / 来源:漫话编程(ID:mhcoding)




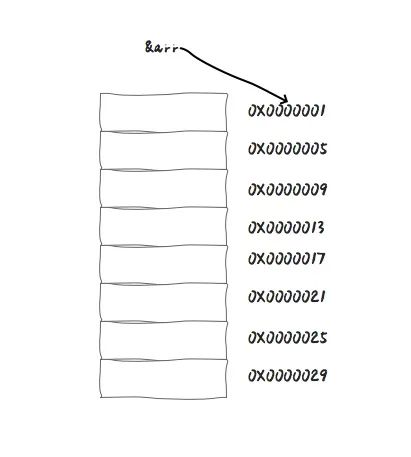
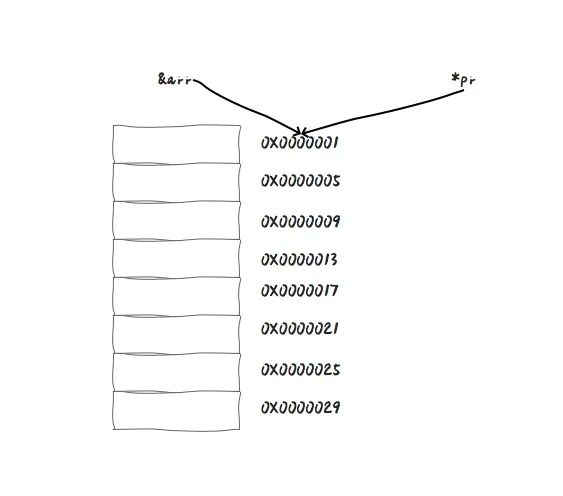
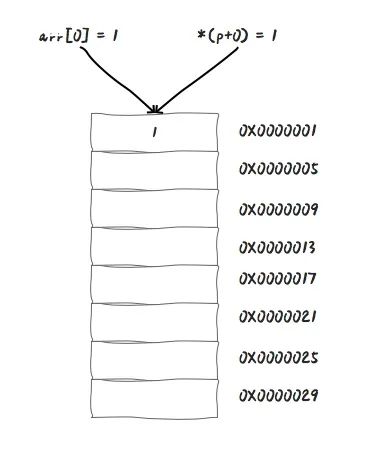
for (int i=0; i<10; i++){
}















关于作者:漫话编程,是一个通过漫画+音频的形式讲解枯燥的编程知识的公众号。致力于让编程变得更有乐趣。

干货直达👇
评论
 下载APP
下载APP导读:为什么计算机从0开始计数,而不是从1开始?
作者 / 来源:漫话编程(ID:mhcoding)
for (int i=0; i<10; i++){
}关于作者:漫话编程,是一个通过漫画+音频的形式讲解枯燥的编程知识的公众号。致力于让编程变得更有乐趣。
干货直达👇