
数据湖专场 | 三级加速,打造高性能云原生数据湖
日前,腾讯云专家工程师严俊明老师,在云+社区技术沙龙「云原生」专场,分享了基于腾讯云对象存储 COS 的云原生数据湖最新技术突破,包括云原生数据湖业务场景以及技术架构。
下面,让我们一起回顾下严老师的精彩演讲内容。
1
大数据存储云原生趋势解析
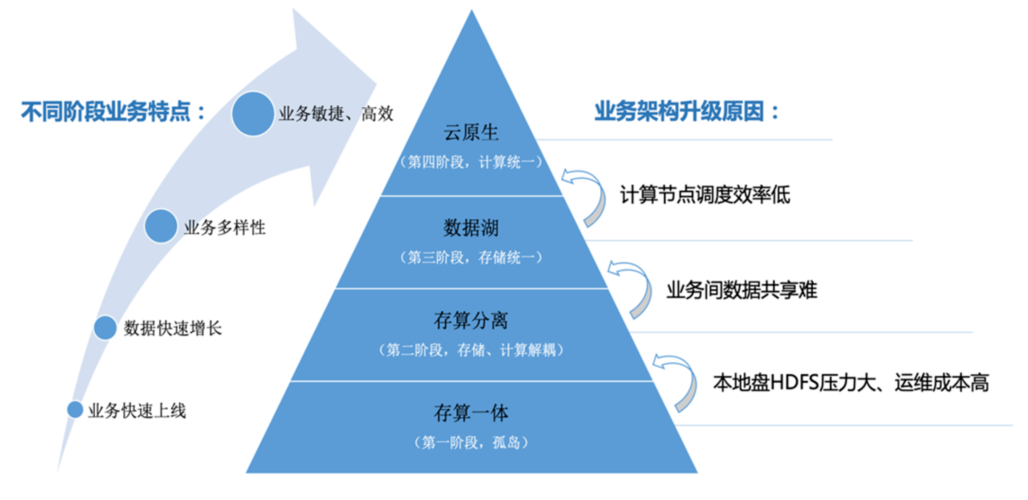
2
腾讯云对象存储架构及数据湖场景挑战
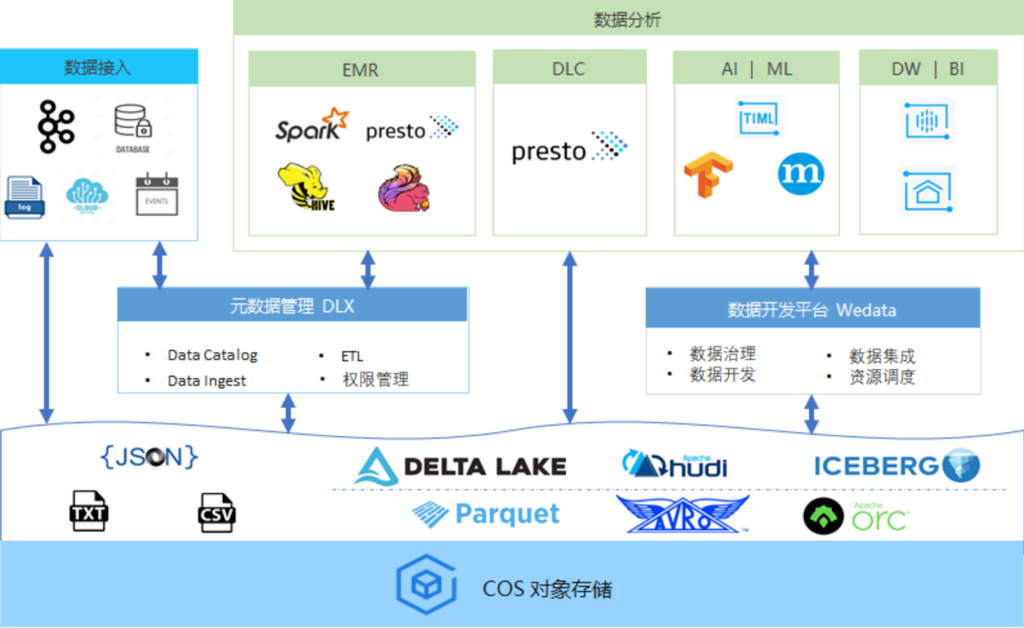
对象存储 COS 是腾讯云提供的一种存储海量文件的分布式存储服务,具有高扩展性、低成本、高可靠、高可用、EB级扩展能力。通过控制台、API、SDK 和工具等多样化方式,用户可简单、快速地接入 COS,进行多格式文件的上传、下载和管理,实现海量数据存储和管理。
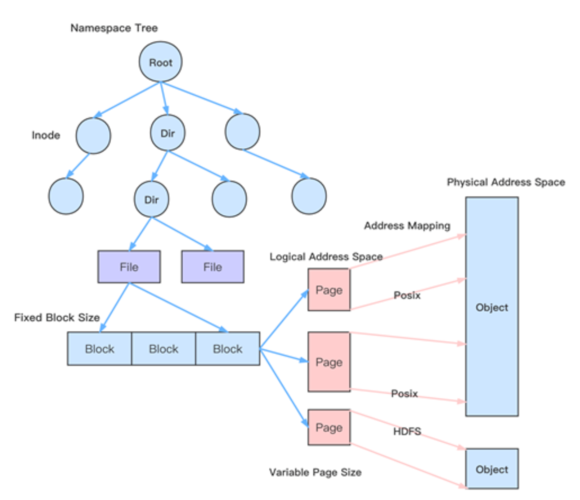
元数据延时高
元数据非原子性
带宽需求大、成本高
3
腾讯云对象存储数据湖三级加速
元数据加速技术(用户侧)
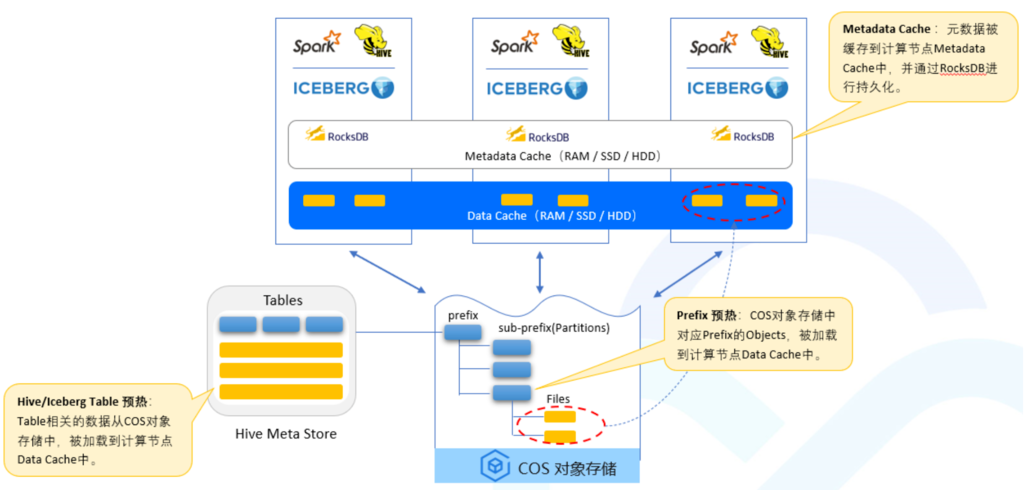
缓存加速技术
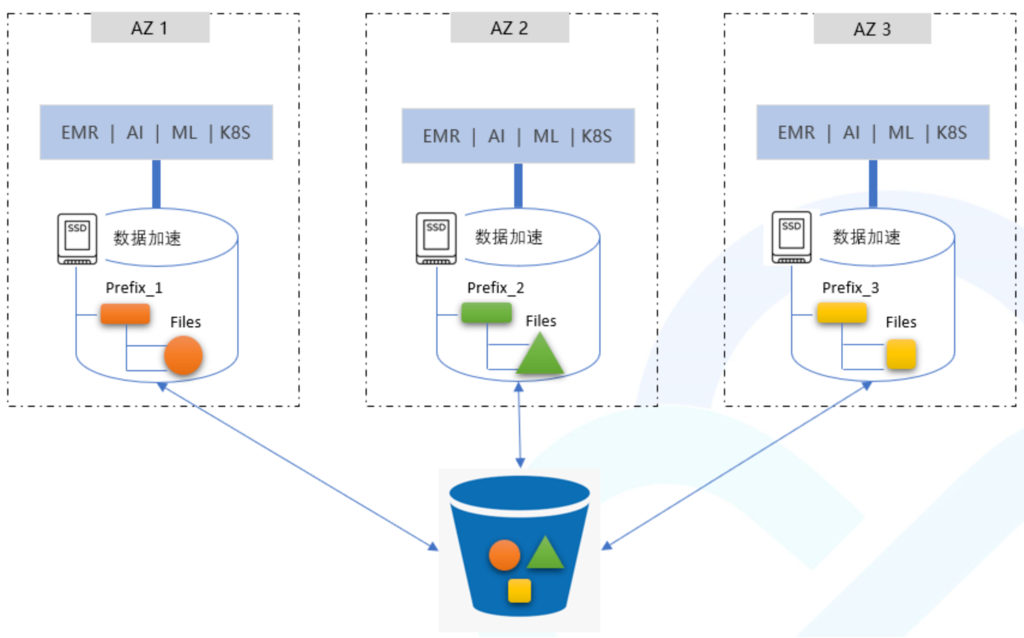
AZ数据加速技术——COS加速器(存储端)
AZ Locality
专有加速域名访问资源;
缓存数据强一致;
可以加速Bucket,或者prefix;
同一个Bucket,支持多个加速器
支持存量Bucket,随时Enable/Disable;
如果miss cache,从COS回源
4
EMR On COS 存算分离实践分享
Hive On COS 存算分离优化实践
Spark On COS 存算分离优化实践
评论