成为一个合格的架构师,一定会面临以下九大场景,80个架构问题。
(1)要考虑业务的需求与特点,初期往往“快速实现”更重要,此时系统的特点是请求量小,数据量小,服务器资源也非常有限;(2)这个阶段最重要的选型依据是:合伙人熟悉什么技术栈,使用什么技术栈;(4)这个阶段研发主要在写CURD业务逻辑,引入DAO和ORM能极大提高工程效率;PHP体系(Linux,Apache,MySQL,PHP)Java体系(Linux,Tomcat,MySQL,Java)主要评估网络带宽、CPU、内存容量、磁盘容量、磁盘IO等资源指标,系统层面主要看吞吐量指标。创业初期,系统层面存在瓶颈的时候,优化原则是什么?(2)用“钱”和“资源”快速解决系统问题,而不是过早的系统重构;(3)将ALL in one架构升级为伪分布式架构,是此阶段的最佳实践;伪分布式的本质是单机变多机,但又不是真正的高可用,其核心是垂直拆分:画外音:有哪些常见的负载均衡方法?如何保证反向代理高可用?(1)有反向代理技术之前,单体架构要解决扩展性问题,可使用DNS轮询架构;(2)有反向代理技术之后,初期可以使用反向代理解决扩展性问题;(4)多级反向代理,引入LVS&F5进一步扩充性能;Session,是接入层架构非常关注的问题,如何保证Session一致性?CDN,是接入层不得不谈的问题,CDN架构有哪些要了解?画外音:有没有综合方案,系统性解决负载均衡 + 高可用 + 可扩展 + 解耦合等一系列问题?
在互联网公司发展早期,为了产品快速迭代,最常使用的架构是什么?如果此时业务发展很快,系统成了瓶颈,架构优化的方向是什么?
用最短时间,以对代码最小的冲击,极速扩充系统性能。早期系统容易“白屏”,如何快速的提升用户体验,消除白屏?动静分离,是“静态页面与动态页面,分开不同的系统访问”的架构设计方法。如果静态页面访问这么快,动态页面访问这么慢,能否将“原本需要动态生成的页面,提前生成静态页面”?可以,这是“页面静态化”技术,能够100倍提升访问速度。读写分离,使用数据库分组架构,一主多从,主从同步,读写分离。画外音:读写分离,水平切分都是使用数据库集群,有什么异同?后台运营系统,复杂的SQL语句对数据库性能影响较大,怎么办?画外音:前后端分离,前台后台分离,是一回事么?如何快速实施前台与后台分离?
(4)按接口划分服务(需要轻量级进程等语言层面支持);不要以为,引入一个RPC框架就是“微服务架构”了,微服务架构要解决很多问题。至少要解决高可用,无限性能扩展,负载均衡等众多架构基础问题。每一层解决高可用问题的方案不一样,涉及虚IP,反向代理,集群,连接池,数据库分组,缓存冗余,故障转移等诸多技术。每一层解决高可用问题的方案不一样,涉及Scale up,Scale out,DNS轮询,反向代理,连接池,水平切分等诸多技术。哪一个组件,和高可用,无限性能扩展,负载均衡相关?
一个数据库分组集群,主从同步,读写分离,能不能在主库和从库建立不同的索引?写库高可用,两个写库相互同步数据,自增ID可能冲突导致数据不一致,有什么优化方案?(1)为每个写库指定不同的初始值,相同的增长步长;(3)一个写库提供服务,一个写库作为高可用影子主;(3)在从库有可能读到旧数据时,选择性读主(非常帅气的方案);底层表结构变更,水平扩展分库个数发生变化,底层存储引擎升级,数据库如何平滑过度?
【第六章:缓存架构】
绝大部分情况,还是应该使用缓存服务,缓存的使用,有什么注意点?(2)如果缓存挂掉,可能导致雪崩,此时要做高可用缓存,或者水平切分;(3)调用方不宜再单独使用缓存存储服务底层的数据,容易出现数据不一致,以及反向依赖;(4)不同服务,缓存实例要做垂直拆分,不宜共用缓存;Cache Aside Pattern的细节是什么?读缓存最佳实践是:先读缓存,命中则返回;未命中则读数据库,然后设置缓存。缓存的本质是“冗余了数据库中的数据”,可能存在什么问题?具体要怎么淘汰,保证缓存与数据库中数据的一致性呢?画外音:纯KV场景,为什么memcache会更快呢?
【第七章:架构解耦】
配置文件,是互联网架构中不可缺少的一环。依赖(调用)某个下游服务集群,将下游集群信息放在自身配置文件里是一种惯用做法,该做法可能导致什么问题?
(2)下游痛:不知道谁依赖于自己,难以实施服务治理,按调用方限流;除了配置中心,消息总线MQ也是互联网架构中的常见解耦利器。上游实时关注执行结果时,通常不使用MQ,而使用RPC调用。(3)上游关注结果,但执行时间很长,例如跨公网调用第三方服务;(2)第二步,个性数据访问,自己家的数据自己管理;画外音:数据库耦合,当数据库成为瓶颈时,增加数据库实例也难以拆分扩容,非常头疼。(2)杜绝底层switch case不同业务类型的业务逻辑代码;(3)个性化代码上浮,公共代码下沉,是更古不变的架构解耦准则;画外音:架构复杂时,微服务是好事,但拆分不彻底反而会有坑。
【第八章:架构分层】
上述复用和封装,在系统架构上的呈现,就是“分层”。每次都要连接数据库获取数据,编码非常低效,有什么痛点?(4)通过游标遍历结果集,拿到每一行,分析行数据,拿到每一列;(3)不同垂直业务之间有需要共性业务,代码要冗余很多次;PC/H5/APP多端业务,编码非常低效,有什么痛点?(1)大部分业务逻辑相同,只有少量展现/交互不一样;(4)PC/H5/APP多端相同的逻辑存在大量代码拷贝;大数据量,高并发量的微服务架构,编码非常低效,有什么痛点?(3)有时候要多个库拿数据,然后到内存排序,例如跨库分页需求;可以看到,架构分层,对研发效率的提升,与复杂性的屏蔽,至关重要。负载均衡、数据收集、服务发现、调用链跟踪。这些非业务的功能,一般是谁实现的呢?
(1)互联网公司一般会有一个“架构部”,研发框架、组件、工具与技术平台;(2)业务研发部门直接使用相关框架、组件、工具与技术平台,享受各种“黑科技”带来的便利;框架、组件、工具与技术平台的使用与推广,往往会遇到以下一些问题:(1)业务研发团队,需要花大量时间去学习、使用基础框架与各类工具;(2)架构部,对于“黑科技”不同语言客户端的支持,往往要开发C-client,Python-client,go-client,Java-client多语言版本;(3)架构部,“黑科技” client要维护m个版本, server要维护n个版本,兼容性要测试m*n个版本;(4)每次“黑科技”的升级,都需要推动上下游进行升级,这个周期往往是以季度、半年、又甚至更久,整体效率极低;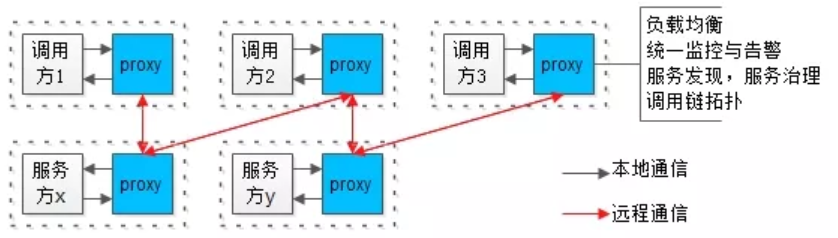
(1)一个进程实现业务逻辑(不管是调用方,还是服务提供方),biz,即上图白色方块;
(2)一个进程实现底层技术体系,proxy,即上图蓝色方块;画外音:负载均衡、监控告警、服务发现与治理、调用链…等诸多基础设施,都放到这一层实现。(1)biz和proxy共同诞生,共同消亡,互为本地部署,即上图虚线方框;(2)biz和proxy之间,为本地通讯,即上图黑色箭头;(3)所有biz之间的通讯,都通过proxy之间完成,proxy之间才存在远端连接,即上图红色箭头;这样就实现了“业务的归业务,技术的归技术”,实现了充分解耦,如果所有节点都实现了解耦,整个架构会演变为:
整个服务集群变成了网格状,这就是Service Mesh服务网格的由来。Service Mesh的行业开源最佳实践是什么?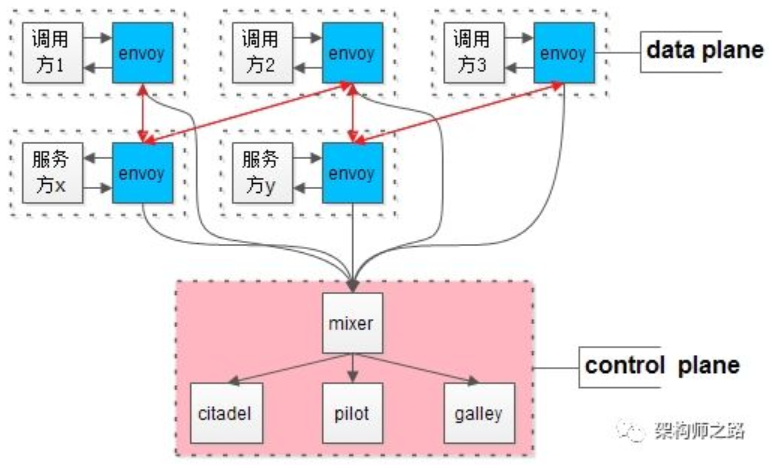
画外音:具体envoy,mixer,citadel,pilot和galley的职责与细节,见《大专栏》。前面所有章节讲的都是单机房架构,单机房架构的特点是什么?架构分层之间,是同连接,即:站点,服务,数据全部单元化,仅连接同机房。(2)如果不能“单元化”,跨机房的数据同步存在较大延时;站点,服务,数据做不到全量单元化,做不到“只”连接同机房,但可以“最小化”跨机房连接,整个架构,可以只有两个地方跨机房:机房区分主次,落地性强,对原有架构冲击较小,业务几乎不需要进行单元化改造。18次直播回看,以及《架构师训练营》,系统性的详聊了上面这80个问题,感兴趣的同学可以扫码看细节。18次直播精华回看,有哪些内容?
每次1-2小时不等,全部已放出。
第一阶:技术选型(5节,已放出)
第二阶:接入层架构(5节,已放出)
第三阶:极速性能优化(3节,已放出)
第四阶:微服务架构(7节,已放出)
第五阶:数据库架构(6节,已放出)
第六阶:缓存架构(7节,已放出)
第七阶:架构解耦(6节,已放出)
第八阶:架构分层(5节,已放出)
第九阶:架构进阶(6节,已放出)
把控住这些,应该能成为一名P8的架构师吧?
白嫖了这么多年,欢迎为情怀补票,希望大家有收获,早日成为P8P9架构师。

