
更准更快的微博 Spammer 水军账号检测模型,支持 API 调用
欢迎关注公众号「月小水长」,唯一笔者是 BuyiXiao,又名小布衣、肖不已。
BuyiXiao,何许人也?本衡州一乡野村夫,身高八尺不足,年方二十有余;弱冠之年曾求学于潭州,为谋生计,背井离乡,远赴京畿,我本南人,不习北土,兼有故友,威逼利诱,急于星火,遂下岭南,打工未半,中道创业,所为何业?赛博朋克,智能硬件;假工程师之名,行农民工之实,满腹经纶,无用书生,善于自黑,贻笑大方。
笔者水平有限,可能暂时无法将非常干货的教程讲的不拖泥带水又不哗众取宠,公众号文章诸多遗漏或不妥之处,可以加月小水长微信「2391527690」备注「学校专业/研究方向/工作岗位」进行交流。
另外,文末点下「赞」和「在看」,这样每次新文章推送,就会第一时间出现在你的订阅号列表里。
去年底分享过一个工作:微博水军账号 spammer 检测模型上线
当时耗费数周,手动标注了数 K 条微博账号数据集,正负样本 1:1,构建识别模型,准确度在 85% 左右。
只要输入一个微博用户的 uid,就能自动抓取账号信息并且进行 spammer 属性判别。
近来得空,升级了下模型,主要是对数据集进行了再次标注,尽可能保证训练数据的噪声尽可能低。
同时新加了一些识别特征,比如同时抓取账号发布过的微博文本信息,账号的多(3)层深度关系网络等等,精确度上升到了 95% 左右。
但是这带来了一个新问题,由于新加的判别特征抓取特别耗时,一个账号的判别耗时指数上升。
原来是秒级,到 95% 左右的精度,抓取一个账号的所有特征耗时来到了百秒级;
这种速度是显然难以接受的,于是我做了一个折中的处理,微博文本信息只抓第一页的微博,深度关系网络只抓第一层,且限制 10 个节点。
这样一来,虽然精度有所下降,来到了 88% 左右,但是识别速度大大提升,耗时仅在数秒左右。
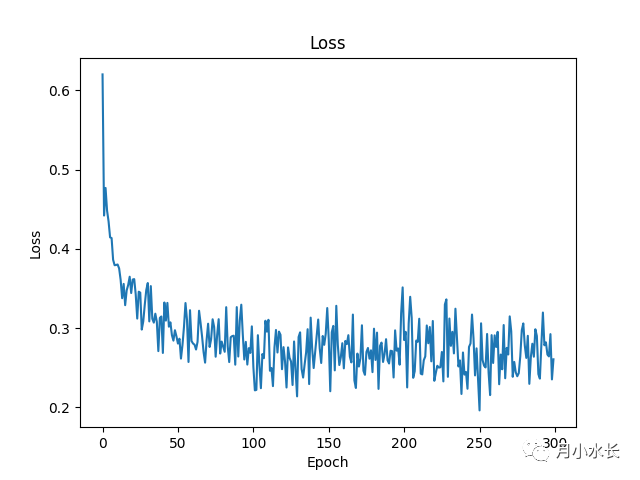
以下是最终模型的一次训练过程中的 ACC、Loss 和 F1 曲线。


新版模型在线地址如下:
https://weibo-crawl-visual.buyixiao.xyz/weibo-spammer-evaluator
同时新增了 API 接口调用,接口地址是:
https://api.buyixiao.xyz/weibo/spammer-account-evaluate
使用 Python 调用该接口的 demo 代码如下:
test_token = "在此处填入在模型在线地址申请的 token"
def test_spammer_evaluate(user_id):
resp = requests.get(url=f'https://api.buyixiao.xyz/weibo/spammer-account-evaluate', params={
'user_id': user_id,
'token': test_token
})
print(resp.url)
print(resp.json())
test_spammer_evaluate(user_id="2557129567")
接口限速 1 request/per second,超速会返回 429 错误,其他参数错误会在返回结果中提示,一次成功的响应如下:
{
"code": 0,
"data": {
"confidenceLevel": 1,
"isSpammer": false
},
"msg": "suc"
}
isSpammer 取值 True or False,表示是否是机器人水军账号,confidenceLevel 可信度介于 0-1 之间。
点击阅读原文直达新版模型地址~