
大神 | EfficientNet模型的完整细节
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者 | Vardan Agarwal
来自 | AI公园 编译 | ronghuaiyang
本文仅作学术交流,如有侵权,请联系后台删除。
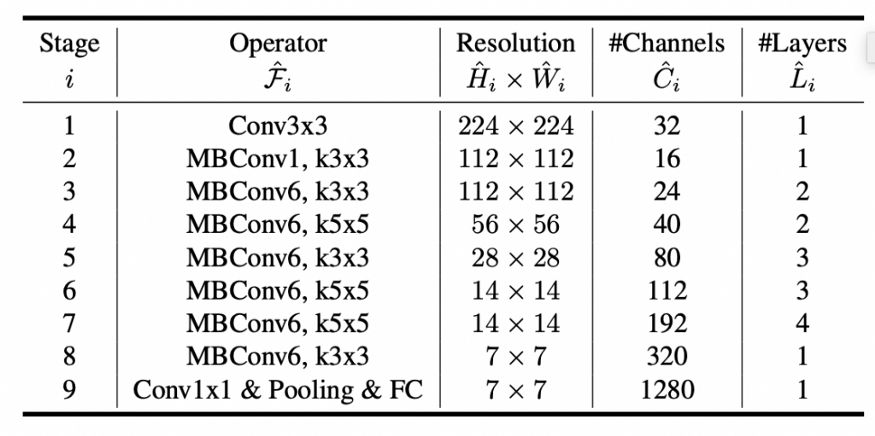
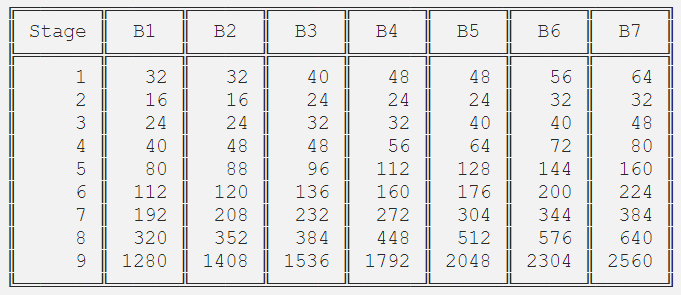
本文介绍了一种高效的网络模型EfficientNet,并分析了 EfficientNet B0 至B7的网络结构之间的差异。
我在一个Kaggle竞赛中翻阅notebooks,发现几乎每个人都在使用EfficientNet 作为他们的主干,而我之前从未听说过这个。
谷歌AI在这篇文章中:https://arxiv.org/abs/1905.11946介绍了它,他们试图提出一种更高效的方法,就像它的名字所建议的那样,同时改善了最新的结果。一般来说,模型设计得太宽,太深,或者分辨率太高。刚开始的时候,增加这些特性是有用的,但很快就会饱和,然后模型的参数会很多,因而效率不高。在EfficientNet中,这些特性是按更有原则的方式扩展的,也就是说,一切都是逐渐增加的。
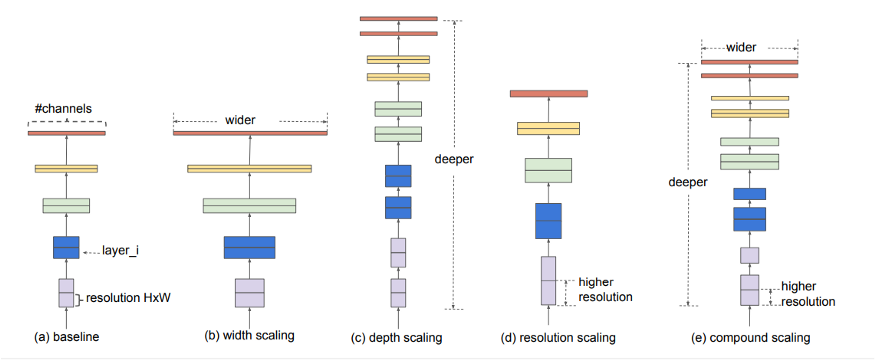
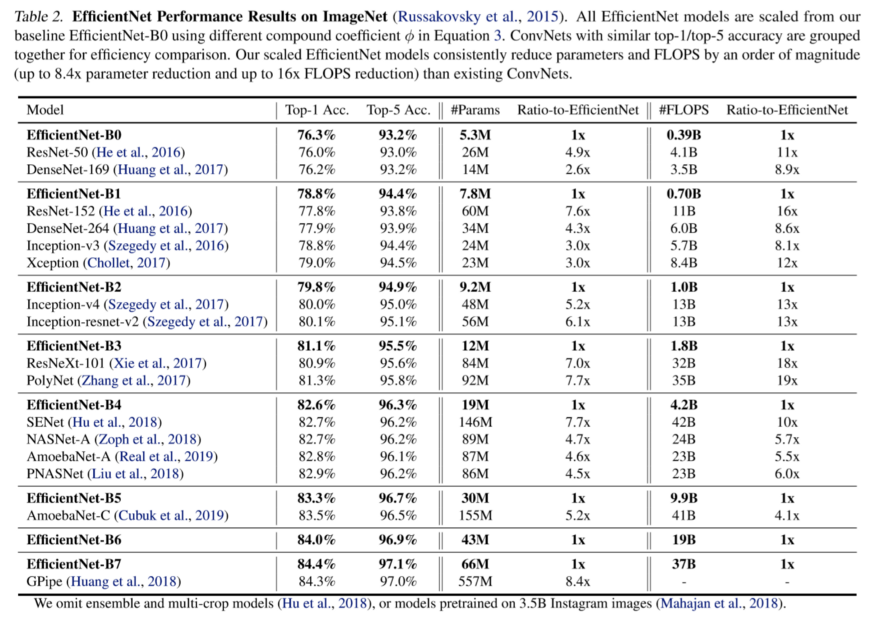
不明白发生了什么?不要担心,一旦看到了架构,你就会明白了。但首先,让我们看看他们得到了什么结果。
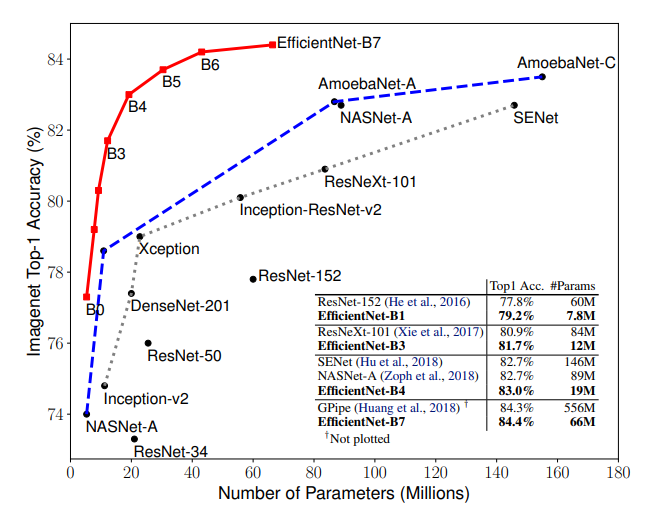
由于参数的数目相当少,这个模型族是非常高效的,也提供更好的结果。现在我们知道了为什么这些可能会成为标准的预训练模型,但是缺少了一些东西。
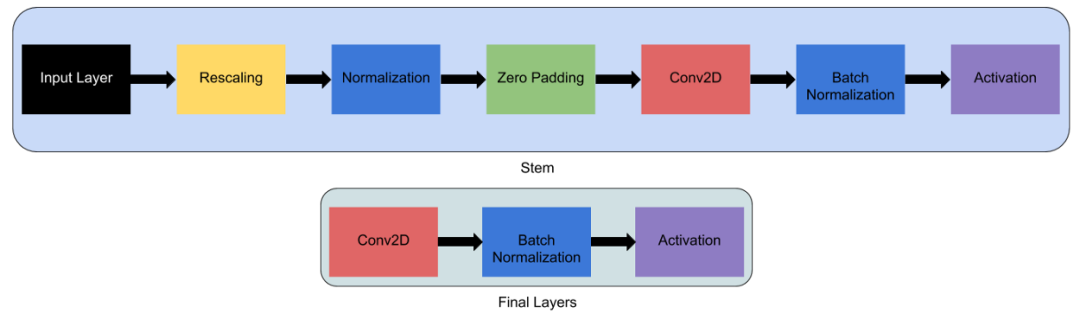
!pip install tf-nightly-gpu
import tensorflow as tf
IMG_SHAPE = (224, 224, 3)
model0 = tf.keras.applications.EfficientNetB0(input_shape=IMG_SHAPE, include_top=False, weights="imagenet")
tf.keras.utils.plot_model(model0) # to draw and visualize
model0.summary() # to see the list of layers and parameters
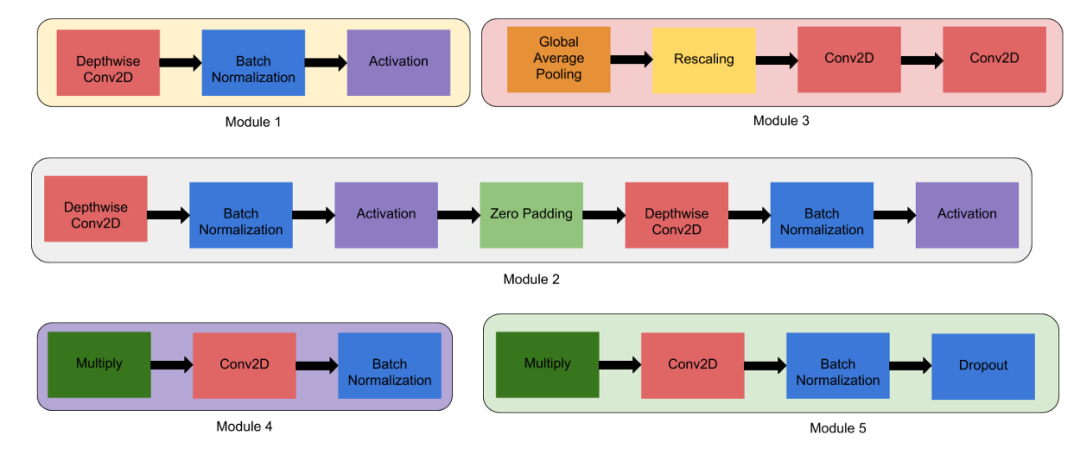
模块1 — 这是子block的起点。 模块2 — 此模块用于除第一个模块外的所有7个主要模块的第一个子block的起点。 模块3 — 它作为跳跃连接到所有的子block。 模块4 — 用于将跳跃连接合并到第一个子block中。 模块5 — 每个子block都以跳跃连接的方式连接到之前的子block,并使用此模块进行组合。
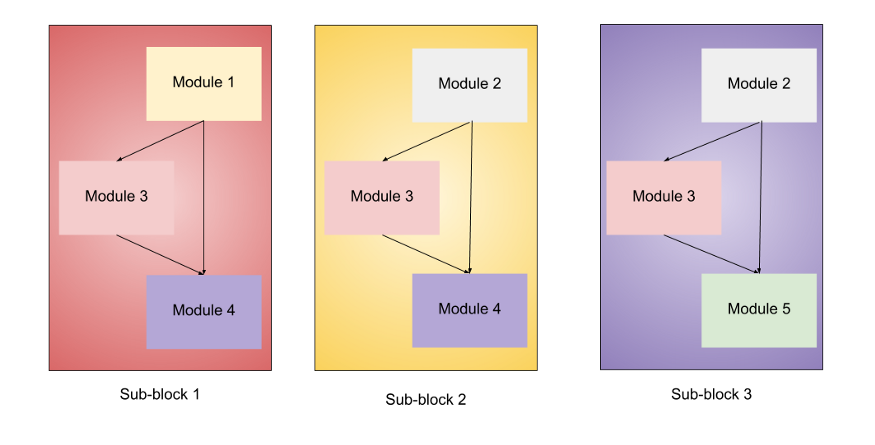
子block1 — 它仅用于第一个block中的第一个子block。
子block2 — 它用作所有其他block中的第一个子block。 子block3 — 用于所有block中除第一个外的任何子block。
EfficientNet-B0
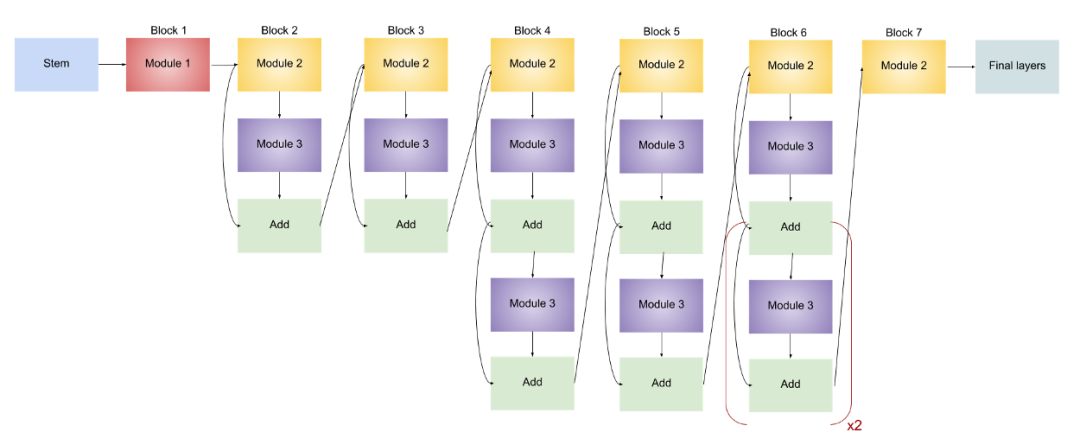
EfficientNet-B1
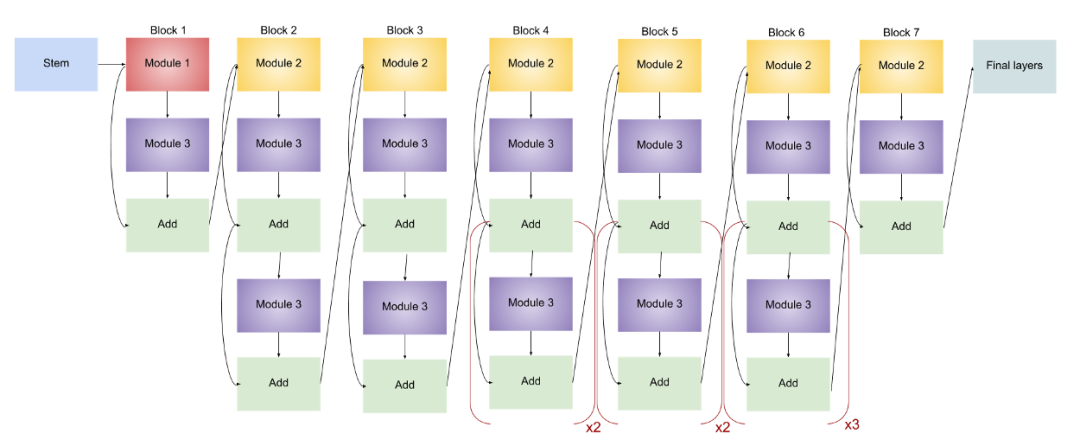
EfficientNet-B2
EfficientNet-B3
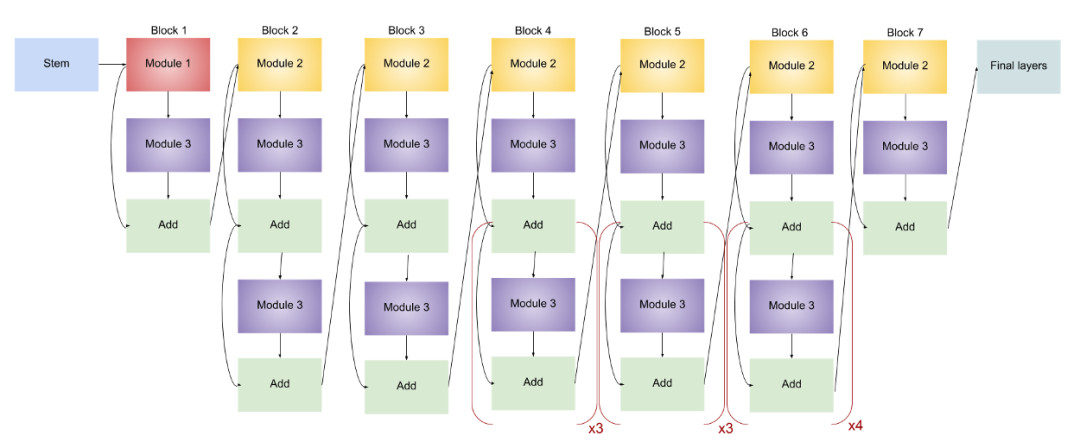
EfficientNet-B4
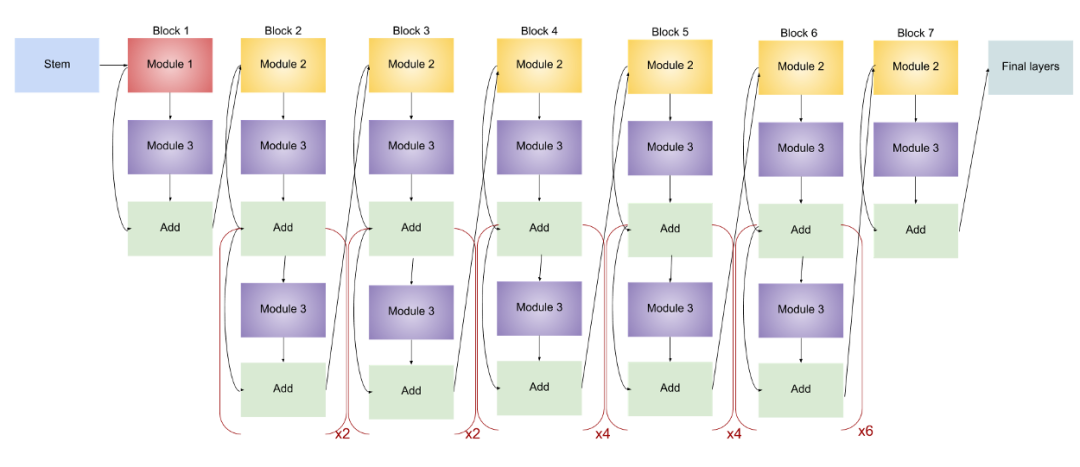
EfficientNet-B5
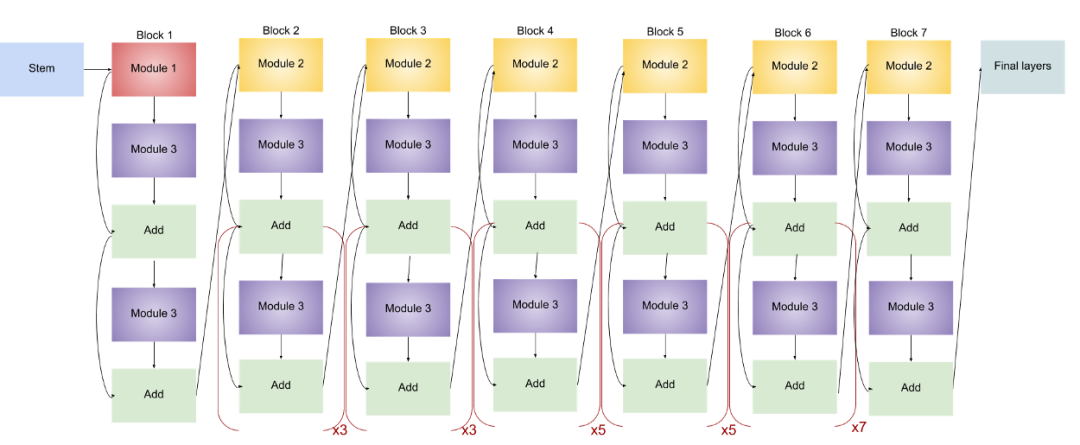
EfficientNet-B6
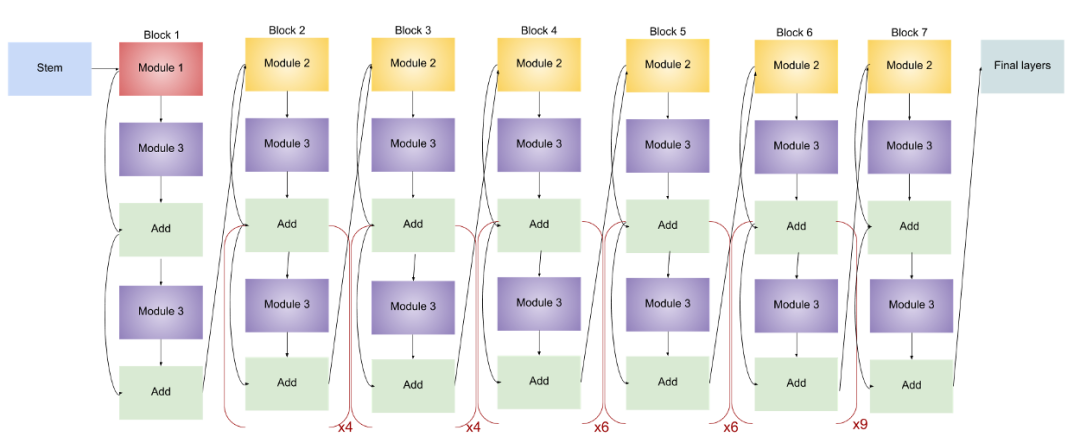
EfficientNet-B7
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~