
巨头们的618学术之战丨618 专题

作者 | 青暮
每年618,不仅是巨头们比拼商业与工程能力的修罗场,也是学术之争的竞技舞台。
1
康帅博你走开

1
康帅博你走开
一年一度的“618”剁手节要来了!一时间,康帅博、七匹狠、雷碧、大白免、白事可乐、老于妈......等品牌,纷纷发来贺电。
某些商家在商品名字上下功夫造假,虽然手段低级,但着实有效!例如有位大哥在某影星直播间买的X.O洋酒,一看扫码价是1888(折后价19.8),以为是奢侈品,就送领导了。据说酒是上午送的,人是晚上走的…..现在广撒简历找工作。
不怪那位小伙伴,现在奢侈品着实真假难辨。买到假的奢侈品,除了浪费时间和金钱,更是令人感觉侮辱性极强。
据阿里安全团队介绍,他们还见过噪声扰动、图形模糊、商标伪造、局部涂抹等很多日常干扰AI进行商标识别的手法。
为了解决这一问题,阿里收集了百万级别的奢侈品商标数据,基于这些数据,升级为了新的AI打假系统:
“1秒钟就可识别20个假冒商标,比人类眨眼速度快10倍。”
对此,阿里安全团队AI打假模型采用的是弹性、高效的网络结构——Brand Net。
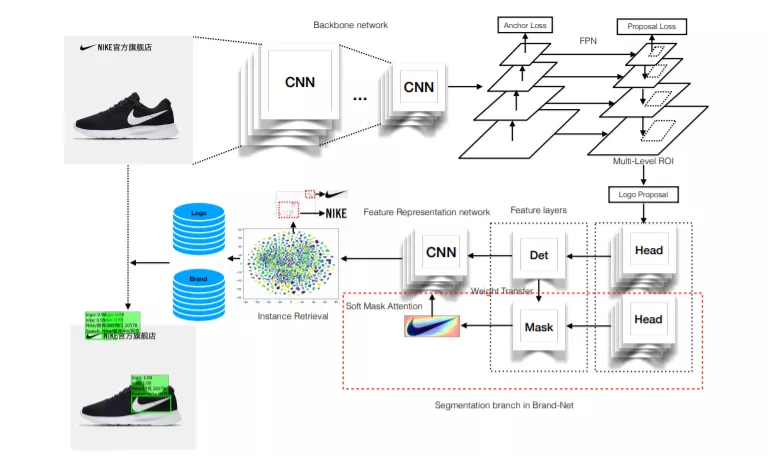
Brand Net的核心技术是目标检测,比如对于一张有四双不同牌子的运动鞋的图片,目标检测可以对每双鞋子加上方框标记,并指出这是什么牌子的鞋。
而典型的目标检测网络主要分为两个阶段,第一阶段先粗略地识别出可能存在目标的区域,第二阶段再进行物体的分类和加边框。
阿里安全在Brand Net里对第一阶段进行了改善,从而能够轻松应对目标比例变化很大的场景。你也知道,很多鞋子的logo有时很低调(小),有时又很高调(大)。
对于一些在边框中占比很小的,以及存在形变的logo,阿里安全通过将边框映射为分割掩码,也就是像素级的边界标记,来改善这一问题。
假货层出不穷,很多新品牌也随时存在被假冒的可能。为了应对这种情况,重新训练模型自然是不现实的,阿里安全为此还融入了特征表示和实例检索技术,从而能够在新商标加入时弹性扩展。
高弹性模型结合高质量数据集,让线上图片的识别准确率,达到了95%,并能有效应对小目标识别、商标遮挡、形变等问题。
“AI打假师”的价值不仅在于识别假货,还在于能够线下协助执法部门治理假货。过去一年中,打假特战队使用技术协助警方全链条打击的LV等奢侈品包包假货特大案就多达6起,捣毁生产窝点10余个,抓获犯罪嫌疑人150余名。
2
要血拼不要说明书
2
要血拼不要说明书

AI打假能让我们放心购物,但在这个眼花缭乱的商品时代,只有“真”是不足以抓住消费者注意力的。而太过详细的文字介绍就像说明书一样无趣,还费时间,可能这里读多几秒,那边秒杀就错过啦。
相比之下,有吸引力的图片配上适当的文字描述,有时更能激发想象体验的真实感。例如,对于紧凑型冰箱要强调节省空间,而对于环保型冰箱则要突出节能。
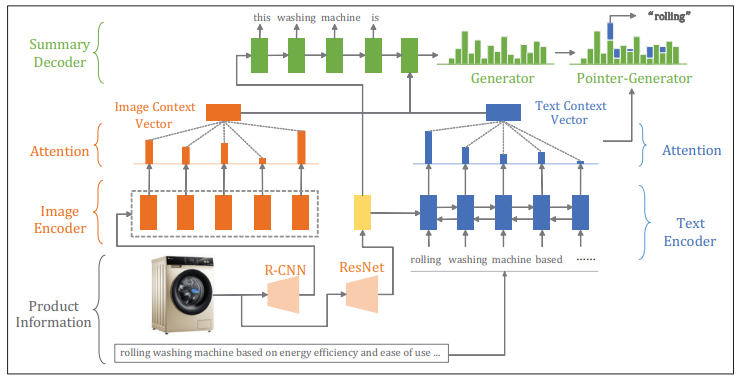
京东AI研究院就据此需求提出了一种电商商品的多模态摘要模型,就是基于一个商品的“说明书”信息,来生成简单扼要又富有吸引力的两句话介绍。所谓多模态,就是指它能整合并理解两个模态(比如文字和图像)以上的信息。

相关论文已经发表于AI顶会AAAI 2020上。

研究人员在实验中构建了一个中文商品摘要数据集,包含约 140 万个“商品 - 摘要”对,涵盖家电、服饰和箱包品类。
实验结果表明,模型在自动评价和人工评价指标上表现都很不错。
论文采用的模型简单来说就是,将商品图片和说明文字一股脑输入神经网络,编码为向量,然后再解码成商品,这个“向量”可以理解为AI模型对图片、文字等不同模态信息的统一翻译。
当然,不会那么极致粗暴和端到端,这里面还涉及到了将图像和文字转换为上下文向量的过程,这些向量标记了在生成摘要里的某一个词的时候,这个词应该参考的部分图像和文字。这种机制很像人类的注意力过程,在AI领域里这也被称作注意力机制。
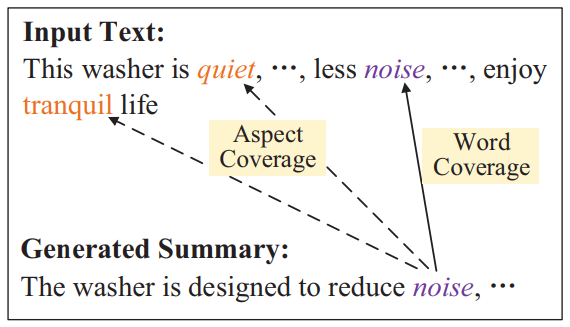
此外,研究人员还要考虑如何消除冗余信息,比如在洗衣机的文字说明中,“noise”、“quiet”和“tranquil”均在描述“运行声音”这一商品要素,如果仅对“noise”进行去冗余,难以保证“quiet”和“tranquil”不出现摘要中。本文提出的模型通过商品要素维度的去冗余,可以避免“noise”、“quiet”和“tranquil”同时出现在摘要中。
其实,很多实践已经表明,AI生成内容在生成效率、曝光点击率、订单转化率等方面都有优于人工创作营销的表现。
3
虚拟世界更需要一见钟情
3
虚拟世界更需要一见钟情

如果对现实世界的购物狂欢不感兴趣,虚拟世界618也给你准备了贴心服务。毕竟虚拟商品一般不可退货,一见钟情非常重要,也省时间。
在网易热门游戏《遇见逆水寒》中,网易伏羲就采用了强化学习来推荐游戏中的商品,并提高了用户活跃度。
相关研究成果发表在了AAAI 2020的一篇论文中。

我们都知道击败围棋世界冠军的AlphaGo采用了强化学习,但它也能用来推荐商品吗?
强化学习本身是通用的范式,就像AlphaGo之父David Silver以及强化学习大神Richard Sutton近期的观点性论文中提到的:只用强化学习就足以实现通用人工智能。
因此,尽管在推荐系统中应用强化学习是比较新颖的尝试,但从概念或者理论上并不存在绝对的局限性。
强化学习的模型一般会设置奖励机制和环境,比如在马里奥游戏里,环境就是游戏里的砖块、怪物、机关等等,奖励就是吃到蘑菇、踩扁怪物、走到目标地点后有加分。

而在推荐系统里,环境的构成比较不一样,是人类用户,或者说用户的行为构成了环境。至于推荐系统本身,就相当于强化学习中的智能体,可以想象成一个机器人。这个机器人每天要应对海量的用户行为反馈,煞是辛苦。
基于深度学习的强化学习以数据饥渴着称,并且在学习过程中容易不稳定。在将强化学习应用到推荐系统中时,要面对三个挑战:
1、巨大的状态和动作空间;
2、高变化环境;
3、推荐中的非特定奖励设置;
具体来说,首先,在工业环境中,用户特征的维度非常大,物品通常用高维的物品特征(动作空间)来表示。直接采用参数很少的无模型强化学习方法,效果非常有限。
其次,用户的反馈奖励通常是稀疏的(例如,只有0.2% 的转化率)和不平衡的(例如,最终交易价格变化也很大)。另一方面,用户的随机页面跳转使得预期奖励的计算变得困难。
最后,具体的奖励方案设置存在很大的不确定性,通常具有不同奖励设置的强化学习算法同时在线是很常见的。高变化环境和奖励不确定使得采用有模型强化学习非常困难,因为有模型强化学习的奖励通常和环境高度相关。
针对上述三个难点,研究人员将环境和价值函数(即奖励)独立开来,提出了新颖的解决方案。
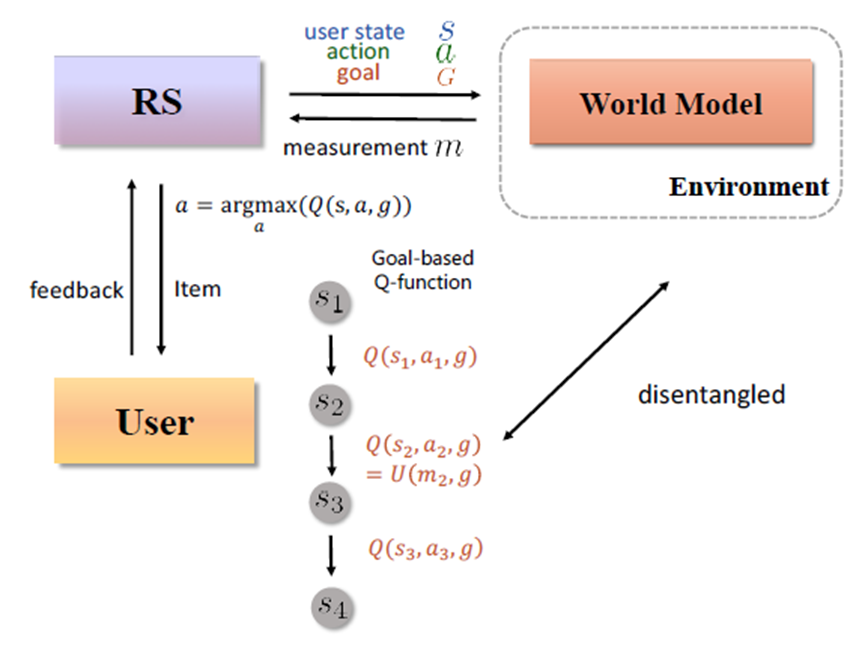
首先,基于世界模型来处理大量状态和动作空间,并以重建用户长期轨迹来应对稀疏问题。比如对于每个用户,用于训练的交互轨迹数量限制为 30,以模拟实际应用程序的数据稀疏性。世界模型是自监督的、高容量的、与环境奖励无关,只预测环境动态。
其次,采用无模型的通用价值函数,这意味着价值函数可以从其他目标产生的经验中学习,并推广到用户可能拥有的任何目标。对于高维环境,将动作维度增加到10000,状态维度扩大到30000。对于高方差环境,将奖励信号延迟 3 步,并添加随机趋势噪声。
网易伏羲表示,这是第一次尝试从基于目标的强化学习的角度思考多步推荐系统问题,并指出论文提出的模型——GoalRec 是一个专门设计的统一解决方案,而不是现有开发技术的简单组合。
4
冰山一角
4
冰山一角
以上列举的几项技术当然只是冰山一角,像618、双11等购物狂欢节都是应对大流量场景考验的绝佳试验场,人工智能在此大数据场景下有着天然的优势。
面对黄河濒临决堤般的压力,逼着大厂们钻研出了宛如城市级基础建设般的技术配套,酝酿出液冷数据中心、云计算、认知智能引擎等中心化设施,以及物流机器人、运维机器人、工业视觉AI等线下可靠助手,还有面向每一位用户的直播实时翻译、虚拟主播、语音机器人、OCR识别等线上AI服务员,覆盖了生产制造、用户触达、供应链、客户服务、物流配送等环节。
为了每年度上演不止一次的“线上春运”大戏,大厂们可谓是不遗余力。

下一个“华为”,会不会是“荣耀”?

任天堂发硬件,网易出风头,2021 E3游戏展大汇总!