
Transformer在图像复原领域的降维打击!ETH提出SwinIR:各项任务全面领先

极市导读
鲜少有工作将transformer用于图像复原方向,而ETH的学者近日提出基于Swin Transformer的一种强基线模型SwinIR用于图像复原,该工作在经典图像超分、真实场景图像超分、图像降噪与JPEG压缩伪影移除都取得了显著优于已有方案的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

原文链接:https://arxiv.org/abs/2108.10257
code:https://github.com/JingyunLiang/SwinIR(未开源)
期待已久的SwinIR终于刊出来了,它是ETH团队在Transformer+low-level方面的最新力作,大幅超越了之前华为诺亚提出的IPT。从某种程度上来看,这篇文章没有什么创新点,只是将微软的Swin Transformer在low-level任务上进行了应用。Whatever,无论是经典图像超分(即退化方式为bicubic),还是真实场景图像超分,亦或图像降噪与JPEG压缩伪影移除,所提SwinIR均取得了显著优于已有方案的性能。笔者这里尤其期待SwinIR在真实场景图像超分方面的应用与效果,期待作者尽快开源。
摘要
图像复原(存在已久的low-level视觉问题)旨在根据低质图像(比如,下采样的、带噪的、压缩的图像)复原高质量图像。现有优异图像复原方案往往采用CNN,鲜少有Transformer(已在high-level视觉任务中取得骄人成绩)类方案在该类问题中进行探索尝试。
本文基于Swin Transformer提出一种强基线模型SwinIR用于图像复原。SwinIR包含三部分:浅层特征提取、深层特征提取以及高质量图像重建。具体而言,深层特征提取由多个RSTB(Residual Swin Transformer Blocks)构成,每个RSTB由多个Swin Transformer层与残差连接构成。
相比CNN方案,Swin具有以下几个优势:
基于内容交互的图像内容与注意力权值可以视作空域可变卷积; RSTB中的移位窗口机制可以进行长距离依赖建模; 更优的性能、更少的参数(可参见下图:SwinIR具有更少的参数量、更优的性能)。
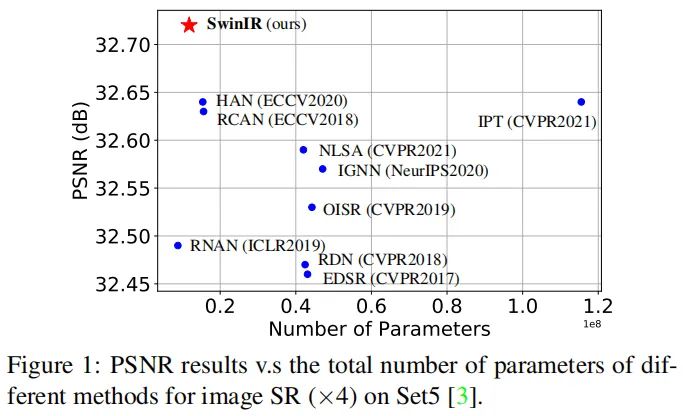
我们在三个极具代表性的任务(图像超分、图像降噪以及JPEG压缩伪影移除)上进行了实验。实验结果表明:所提SwinIR能够以0.14~0.45dB优于其他SOTA方案,同时参数量降低高达67%。
方法简介
网络结构
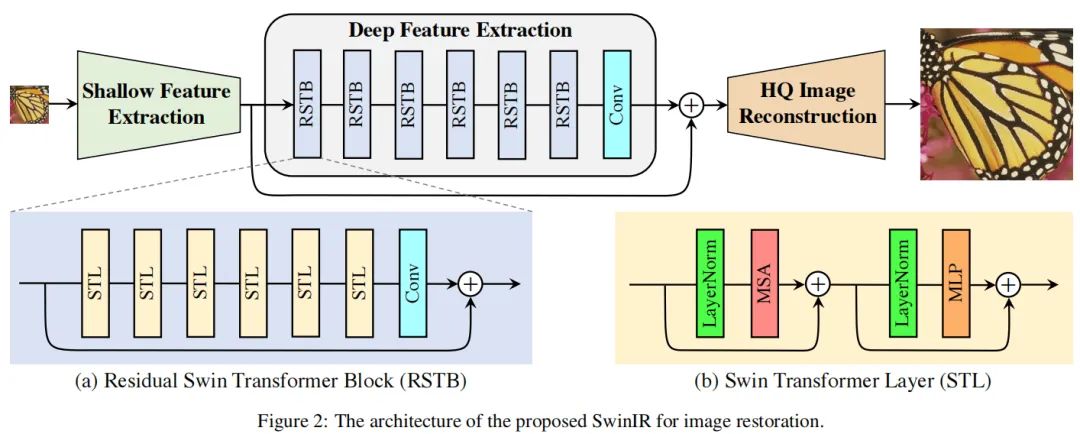
上图给出了本文所提SwinIR网络架构示意图,很明显,它由三个部分构成:浅层特征提取、深层特征提取以及高质量图像重建模块。对于不同任务而言,所提方案的区别主要在于重建模块。
浅层及深层特征提取
给定低质输入,我们采用卷积提取浅层特征:
已有研究[ConvStem]表明: 卷积善于进行早期视觉处理,同时有助于稳化训练并取得更优结果。此外,卷积还提供了一种将输入图像映射到更高维特征空间的简单方案。然后,我们对提取深层特征:
注:表示深层特征提取模块,它由K个RSTB与一个卷积构成。更具体来说,中间特征以及深层特征的计算可以描述如下:
注:这里的卷积操作可以将卷积操作的归纳偏置引入到SwinIR中,同时为浅层特征与深层特征的聚合奠定更好的基础。
图像重建
以图像超分为例,我们通过聚合浅层与深层特征进行高质量图像重建:
注:表示重建模块。由于浅层特征主要包含低频信息,而深层特征聚焦于重建遗失的高频信息,SwinIR采用了长距离跳过连接将两者聚合进行最终的重建。
对于超分而言,重建模块由卷积与PixelShuffle构成;对于不需要上采样的任务(如降噪、JPEG压缩伪影移除),重建模块仅由卷积构成。此外,我们采用残差学习机制重建LQ与HR之间的残差,即:
损失函数
对于图像超分,我们采用损失进行优化:
对于经典与轻量图像超分,我们近采用上述损失;对于真实世界图像超分,我们采用损失、GAN损失以及感知损失的组合以提升视觉质量。对于图像降噪与JPEG压缩伪影任务,我们采用Charbonnier损失:
残差Swin Transformer模块

上图a给出了RSTB的结构示意图,它包含多个STL、一个卷积以及残差连接。对于第个RSTB,输入特征表示为,我们首先通过L个Swin Transformer层提取中间特征:
然后,我们在残差连接之前添加一个卷积层。RSTB的输出可以描述如下:
这种设计思路有这样两个优势:
1) 尽管Transformer可以视作空间可变卷积的变种,但空间不变卷积有助于提升SwinIR的平移不变形;
2) 残差连接为不同模块到重建模块提供了等效连接,促进了不同层级特征的聚合。
Swin Transformer层
Swin Transformer Layer(STL)基于原始Transformer中的标准多头自注意力演变而来,主要区别体现在于局部注意力与移位窗口机制。前述图b给出了STL结构示意图。假设输入尺寸为,首先,将输入拆分为局部窗口并reshape为;然后,在每个窗口计算标准自注意力。对于局部窗口特征,query、key以及value计算如下:
基于上述信息,注意力矩阵的计算公式如下:
其中,B表示可学习相对位置编码。接下来,我们采用包含两个全连接层与GELU激活的MLP进行特征变换。因此,整个过程可以描述如下:
然而,当不同层的窗口划分固定时,不同局部窗口之间不存在新交互。因此,窗口划分与窗口移位用于进行跨窗口信息交互。更多关于SwinTransformer的介绍
可参见:zzk:图解Swin Transformer,https://zhuanlan.zhihu.com/p/367111046
实验
主要结果
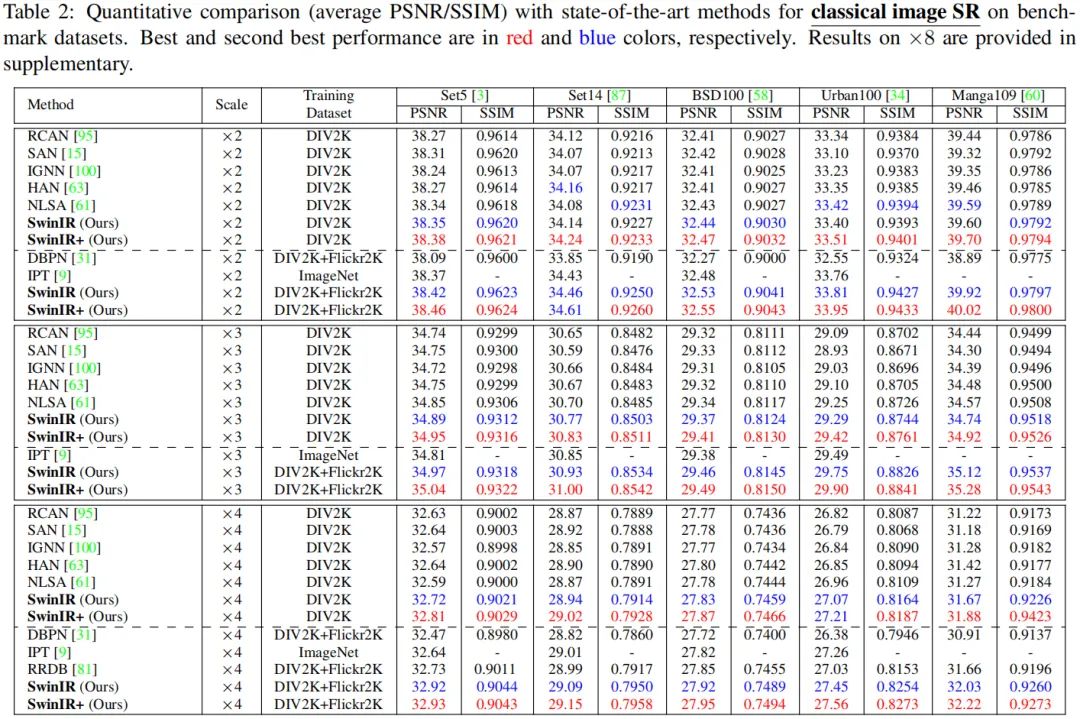
经典图像超分
上表给出了经典图像超分方面的性能对比,从中可以看到:
1) 当在DIV2K数据集上训练时,在五个基准数据集上,Swin取得了所有尺度最佳性能;PSNR增益最高甚至可达0.26dB。
2) 当在DIV2K+Flickr2K数据集上训练时,SwinIR的性能得到了进一步提升,超越了ImageNet数据集上训练的IPT;
3) 值得注意的是,SwinIR的参数量远小于IPT(11.8M vs 115.5M),甚至比CNN方案的参数量(15.4~44.3M)还少;
4) 在推理速度方面,当输入为时,RCAN、IPT以及SwinIR速度分别为0.2s、4.5s以及1.1s;

上图给出了SwinIR与其他超分方案的视觉效果对比,可以看到:SwinIR可以复原高频细节,具有更锐利而自然的边缘;相反,CNN方案生成结果往往具有模糊结果,甚至不正确的纹理。
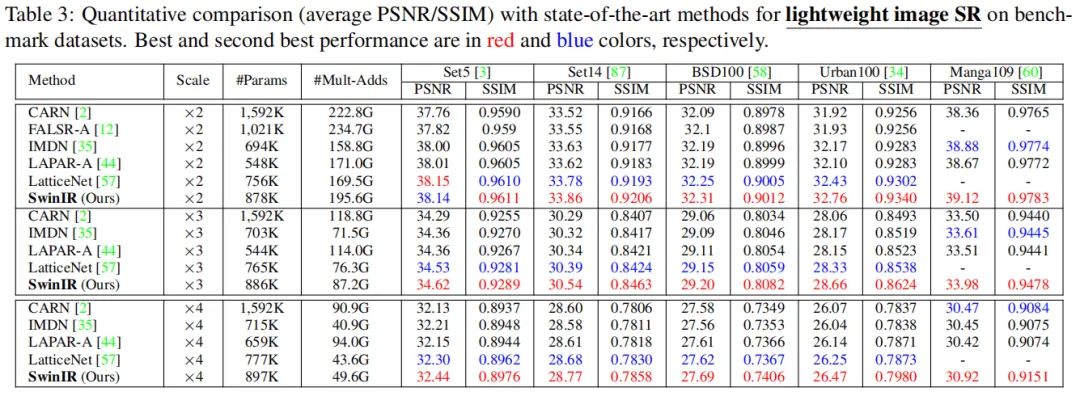
轻量图像超分
上图对比了不同轻量型方案的性能对比,从中可以看到:SwinIR显著优于其他方案(PSNR指标最高超出0.53dB),同时具有相近的参数量与计算量。

真实世界图像超分
图像超分的终极目标是真实场景实用。我们以BSRGAN为基础进行SwinIR训练,视觉效果对比见上图。从图示效果可以看到:SwinIR生成了视觉效果更佳(更清晰、边缘更锐利)的图像,而其他方案则存在伪影问题。对标的模型包含:
ESRGAN;更详细信息可参见【科技猛兽:ESRGAN原理分析和代码解读】(https://zhuanlan.zhihu.com/p/156505590); BSRGAN:更详细信息可参见【真正实用的退化模型,ETH开源业界首个广义盲图像超分退化模型】; RealSR:更细信息可参见【显著提升真实数据超分性能,南大&腾讯开源图像超分新方案RealSR】; Real-ESRGAN:更详细可参见【Real-ESRGAN:走出温室,迈向实用!】
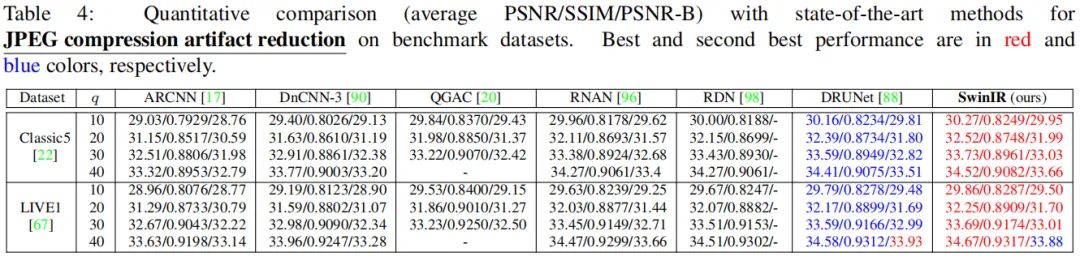
JPEG压缩伪影移除
上表给出了JPEG压缩伪影移除任务上的性能对比,从中可以看到:
在两个数据集上,所提SwinIR分别取得了平均0.11dB、0.07dB指标提升; 相比此前最佳DRUNet(参数量为32.7M),SwinIR参数量仅为11.5M参数。

图像降噪
上面两个表给出了灰度/彩色图像降噪方面的性能对比,从中可以看到:
相比其他方案,所提SwinIR在图像降噪任务上同样具有更优异的性能;在Urban100数据上,SwinIR超出DRUNet0.3dB; 在参数量方面,SwinIR仅需12M,而DRUNet则具有32.7M;这说明:SwinIR在学习用于复原的特征表达上非常高效。

上面两个图给出了灰度/彩色图像降噪方面的视觉效果对比,从中可以看到:SwinIR可以有效移除重度噪声干扰,同时保留高频图像细节,进而生成更锐利的边缘、更自然的纹理;而其他方案要么过于平滑,要么过度锐化,难以重建丰富纹理。
消融实验

对通道数量、RSTB 模块数和 STL 数的影响
上图a、b、c对通道数、模块数以及STL数进行消融分析对比,从中可以看到:
PSNR指标与上述三个超参成正相关关系; 对于通道数而言,尽管通道数越多性能越好,但总参数成二次方关系增长。为平衡性能与模型大小,我们设置通道数180; 随RSTB模块数与STL数增加,模型性能很快饱和。我们将两者数量设为6以得到一个相对小的模型。
上图d、e、f对训练过程中的超参进行了消融分析对比,从中可以看到:
在不同patch尺寸下,SwinIR均取得了比RCAN更佳的性能,见上图d; SwinIR性能会随训练数据量提升而提升且均比RCAN更优,见上图e; SwinIR的收敛速度要比RCAN更快、更好,见上图f。

上表对RSTB的各成分进行了消融对比,从中可以看到:
残差连接非常重要,它可以提升的性能高达0.16dB; 卷积带来的性能增强非常有限,这是因为它不会像卷积一样提取局部近邻信息; 尽管采用三个卷积(减少中间卷积通道数)可以降低参数量,但性能同样轻微下降。
本文亮点总结
基于内容交互的图像内容与注意力权值可以视作空域可变卷积; RSTB中的移位窗口机制可以进行长距离依赖建模; 更优的性能、更少的参数
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“85”获取ICCV2021 oral直播分享PPT下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV领域八年深耕码农
研究领域:专注low-level领域,同时对CNN、Transformer、MLP等前沿网络架构保持学习心态,对detection的落地应用甚感兴趣。
公众号:AIWalker
作品精选
