
基于度量学习的行人重识别(二)
前面我们已经说到了三元组损失以及MobileNet模型的搭建,我们再来看一下实现的具体流程,如下图:
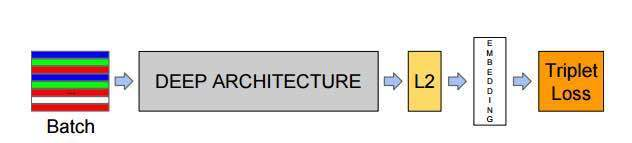
batch :是指输入的人脸图像样本,这里的样本是已经经过人脸检测找到人脸并裁剪到固定尺寸(例如160x160)的图片样本。
Deep architecture:指的是采用一种深入学习架构例如imagenet历年冠军网络中的VGG,GoogleNet等,本文中我们将使用MoblieNetv2 作为主要的特征提取网络。
L2 :是指特征归一化(使其特征的||f(x)||2=1,这里是2次方的意思。这样所有图像的特征都会被映射到一个超球面上)
Embeddings: 就是前面经过深度学习网络,L2归一化后生成的特征向量(这个特征向量就代表了输入的一张样本图片)
Triplet Loss:就是有三张图片输入的Loss(之前的都是Double Loss或者 是 SingleLoss)。直接学习特征间的可分性:相同身份之间的特征距离要尽可能的小,而不同身份之间的特征距离要尽可能的大
一|数据集处理。
SUMMER OF 2021
在数据集方面,我们同样使用了DukeMTMC-reID数据集,这是在杜克大学内采集的,图像来自8个不同的摄像头。该数据集提供训练集和测试集。训练集包含16522张图像,测试集包含1761张图像。训练集几乎共有702人,平均每个人有23.5张训练数据。是目前最大的行人重识别数据集,并且提供了行人属性,如性别,长短袖,是否有背包等标注。

接下来,我们进行数据处理,首先,我们先观察数据的命名格式,发现数据的命名是00xx_**_**.jpg。后面的不用管,我们的目的是提取对应行人的索引。所以可以对_前的数值进行提取,新建一个data2txt.py写入如下代码:
import osimport cv2data_path=r'E:\DataSets\DukeMTMC-reID\DukeMTMC-reID\bounding_box_train'image_paths=[os.path.join(data_path,p)for p in os.listdir(data_path)]nameid=[]for image_path in image_paths:name=image_path.split('\\')[-1].split('_')[0]if name+'\n' not in nameid:nameid.append(name+'\n')with open('train.txt', 'w', encoding='utf8') as f:f.writelines(nameid)
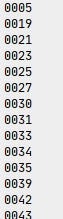
同样地,修改一下数据地路径以及最终的保存名称,运行程序我们可以生成train.txt以及test.txt文件,里面存放的是如下所示的标签:
二|数据处理。
SUMMER OF 2021
接下来,我们要编写一个读取数据集的类,用来训练时边训练边读取,这里我们不再使用生成器的模式来写,而是使用tf.keras.utils.Sequence来新建一个数据加载类。新建一个load_data.py文件,首先导入依赖库以及后面需要用到的一些函数,同学们也可以创建一个utils.py文件来存放这些函数:
import numpy as npimport tensorflow.keras as kimport globimport osfrom tqdm import tqdmimport jsonimport mathimport randomfrom PIL import Imageimport cv2from keras.utils import np_utils# 生成 a 到def rand(a=0, b=1):return np.random.rand()*(b-a) + a# 读取txt 文件def read_lines(path=r'datasets\train.txt'):with open(path,'r',encoding='utf8') as f:data= f.readlines()return data
接着,新建一个类叫Person_Dataset,并初始化数据,这里我们必须完成 __len__ 以及 __getitem__ 这两个函数,前者是用来判断总共需要多少次读取才能把数据完全拿到,公式为:读取次数 = 总图片数/batch_size ,而后者是用来获取每一个批次的可供训练的数据:
class Person_Dataset(k.utils.Sequence):def __init__(self,image_path,batch_size,train=True,input_size=(215,90,3)):self.image_path = image_pathself.num_len = len(os.listdir(image_path))self.batch_size = batch_sizeself.train = trainself.json_data = self.load_data_path()self.json_key = list(self.json_data.keys())self.image_height,self.image_width,self.channel = input_sizedef __len__(self):return math.ceil(self.num_len / float(self.batch_size))def __getitem__(self, item):pass
接着,我们再写入load_data_path函数,用来读取训练,或者测试时的json数据,并返回,为了方便,第一次读取时直接把数据写入到json中,后续直接读取json可以省点时间:
def load_data_path(self):if self.train:if not os.path.isfile('datasets/train.json'):label_data_dist={}label_names = read_lines()for labelname in tqdm(label_names):labelname = labelname.strip('\n')label_to_imagepaths= glob.glob(self.image_path+'\%s*'%labelname)label_data_dist[labelname]=label_to_imagepaths# print(label_to_imagepaths)json_ = json.dumps(label_data_dist)with open('datasets/train.json', 'w', encoding='utf8') as f:f.writelines(json_)return json_else:with open('datasets/train.json', 'r', encoding='utf8') as f:json_ = json.loads(f.read())return json_else:if not os.path.isfile('datasets/test.json'):label_data_dist={}label_names = read_lines(path=r'datasets\test.txt')for labelname in tqdm(label_names):labelname = labelname.strip('\n')label_to_imagepaths= glob.glob(self.image_path+'\%s*'%labelname)label_data_dist[labelname]=label_to_imagepaths# print(label_to_imagepaths)json_ = json.dumps(label_data_dist)with open('datasets/test.json', 'w', encoding='utf8') as f:f.writelines(json_)return json_else:with open('datasets/test.json', 'r', encoding='utf8') as f:json_ = json.loads(f.read())return json_
然后,为了使模型更具鲁棒性,所以我们再编写一个数据增强的函数,用来对行人数据进行随机裁剪、随机翻转、随机缩放等。
# 随机增强数据def get_random_data(self, image, input_shape, jitter=.1, hue=.1, sat=1.3, val=1.3, flip_signal=True):''':param image: PIL Image:param input_shape: 输入尺寸:param jitter: 裁剪:param hue: h:param sat: s:param val: v:param flip_signal: 翻转:return:'''image = image.convert("RGB")h, w = input_shaperand_jit1 = rand(1 - jitter, 1 + jitter)rand_jit2 = rand(1 - jitter, 1 + jitter)new_ar = w / h * rand_jit1 / rand_jit2# 随机裁剪图片scale = rand(0.9, 1.1)if new_ar < 1:nh = int(scale * h)nw = int(nh * new_ar)else:nw = int(scale * w)nh = int(nw / new_ar)image = image.resize((nw, nh), Image.BICUBIC)# 随机翻转图片flip = rand() < .5if flip and flip_signal:image = image.transpose(Image.FLIP_LEFT_RIGHT)dx = int(rand(0, w - nw))dy = int(rand(0, h - nh))new_image = Image.new('RGB', (w, h), (128, 128, 128))new_image.paste(image, (dx, dy))image = new_image# 旋转图片rotate = rand() < .5if rotate:angle = np.random.randint(-10, 10)a, b = w / 2, h / 2M = cv2.getRotationMatrix2D((a, b), angle, 1)image = cv2.warpAffine(np.array(image), M, (w, h), borderValue=[128, 128, 128])return image
最后就是完成__getitem__函数中的内容啦,我们先使用numpy新创建两个全0的数组,维度分别为(batch_size,3,h,w,c)以及(batch_size,3),用来存放图片数据以及标签数据。
def __getitem__(self, item):images = np.zeros((self.batch_size, 3, self.image_height, self.image_width, self.channel))labels = np.zeros((self.batch_size, 3))
然后使用循环读取一个批次的数据并返回,具体流程如下:
在读取的json中随机取得第一个人,并判断这个人拥有的图片数是否大于2,否则重取
在取得的第一个人的图片中随机获取2张图片分别进行图像处理以及标签处理
在取得的json中随机取得第二个人,并判断此人与第一个人是否是同一个人,是则重取
在取得的第二个人的图片中随机获取1张图片并进行图像处理以及标签处理
组合数据与标签
返回
# 循环获取一个批次的数据for i in range(self.batch_size):# 随机在json中获取一个人c = np.random.choice(self.json_key, 1)select_path = self.json_data[c[0]]# 当获取人的图片数量小于2 则重新获取while len(select_path) < 2:c = np.random.choice(self.json_key, 1)select_path = self.json_data[c[0]]# 在随机获取的人 的图片中 随机取得两张image_index = np.random.choice(select_path, 2)# 第一张图片image1 = Image.open(image_index[0])# 数据增强image1 = self.get_random_data(image1, [self.image_height, self.image_width])image1 = np.asarray(image1).astype(np.float64) / 255.# 获取当前人的标签label = self.json_key.index(c[0])images[i, 0, :, :, :] = image1labels[i, 0] = label# 第二张图片image2 = Image.open(image_index[1])image2 = self.get_random_data(image2, [self.image_height, self.image_width])image2 = np.asarray(image2).astype(np.float64) / 255.images[i, 1, :, :, :] = image2labels[i, 1] = label# 随机获取第二个人的图片路径diff_c = np.random.choice(self.json_key, 1)# 如果和第一个人 是同一人则重新取while diff_c[0] == c[0]:diff_c = np.random.choice(self.json_key, 1)# 随机取得不同人的一张图片diff_select_path = self.json_data[diff_c[0]]diff_c_image_path = np.random.choice(diff_select_path, 1)# 图片读取diff_image = Image.open(diff_c_image_path[0])diff_image = self.get_random_data(diff_image, [self.image_height, self.image_width])diff_image = np.asarray(diff_image).astype(np.float64) / 255.diff_label = self.json_key.index(diff_c[0])images[i, 2, :, :, :] = diff_imagelabels[i, 2] = diff_label# 组合3张图片images1 = np.array(images)[:, 0, :, :, :]images2 = np.array(images)[:, 1, :, :, :]images3 = np.array(images)[:, 2, :, :, :]images = np.concatenate([images1, images2, images3], 0)# 组合3个标签labels1 = np.array(labels)[:, 0]labels2 = np.array(labels)[:, 1]labels3 = np.array(labels)[:, 2]labels = np.concatenate([labels1, labels2, labels3], 0)# 独热编码labels = np_utils.to_categorical(np.array(labels), num_classes=len(self.json_key))return images, {'Embedding': np.zeros_like(labels), 'Softmax': labels}
三|数据验证。
SUMMER OF 2021
这样一个数据读取的类就完成了,我们可以使用如下的方式进行验证,看看返回的数据是否是我们所需的。
image_dir = r'E:\DataSets\DukeMTMC-reID\DukeMTMC-reID\bounding_box_train'batch_size=1# 实例化数据dataset=Face_Dataset(image_dir,batch_size)# 获得第一个batch_size 的数据image,dict = dataset.__getitem__(1)embb=dict['Embedding']label = dict['Softmax']# 风别取得3张图片的索引for i in range(3):image_ = np.array(image[i]*255.,dtype='uint8')cv2.imshow('s%s'%i,image_)print(label[i].argmax())cv2.waitKey(0)
程序运行结果如下,我们可以看到第一第二张图片很明显就是同一个人,所以他们的索引是一致的,第三张图片是不同人,所以索引是不一样的。

以上就是本期推文的全部内容了,由于数据处理方面还是比较复杂的,模型训练以及测试将会在下个推文给出,喜欢的可以点个关注噢!