
论文推荐-视频去锯齿
作者: 晟 沚
本文主要介绍论文:Real-timeDeepVideoDeinterlacing,主要解决由于隔行扫描导致的锯齿播放效果。
01
隔行扫描介绍
隔行扫描是一种广泛用于电视广播和视频录制的技术,可在不增加带宽的情况下将感知帧速率加倍。但它会在播放过程中呈现令人讨厌的视觉伪像,例如闪烁和剪影“锯齿”。现有的最先进的去隔行方法要么忽略时间信息以提供实时性能但降低视觉质量,要么估计运动以获得更好的去隔行但以更高的计算成本为代价。在本文中,作者提出了第一个和新颖的基于深度卷积神经网络 (DCNN) 的方法,以具有高视觉质量和实时性能的去隔行。与依赖平移不变假设的现有超分辨率问题模型不同,作者提出的 DCNN 模型利用来自奇数和偶数半帧的时间信息来仅重建丢失的扫描线,并保留给定的奇数和偶数扫描线用于生成完整的去隔行帧。通过进一步引入层共享架构,作者的系统可以在单个 GPU 上实现实时性能。实验表明,作者的方法在重建精度和计算性能方面优于所有现有方法。
隔行扫描技术在过去几十年中以模拟和数字方式广泛用于电视广播和视频录制。不是捕获每帧的所有 N 条扫描线,而是只捕获当前帧的 N/2 条奇数扫描线,其他 N/2 条偶数扫描线是为下一帧捕获。它基本上用帧分辨率换取帧速率,以便在不增加带宽的情况下将感知帧速率加倍。不幸的是,由于两个半帧是在不同的时间实例中捕获的,因此当奇数场和偶数场出现在移动物体的轮廓上时,会出现明显的视觉伪像,例如线条闪烁和“锯齿”(图 (b))隔行显示,称之为交错。“锯齿”的程度取决于物体的运动,因此在空间上是变化的。这使得去隔行(去除隔行伪影)成为一个不适定的问题。
目前已经提出了许多去隔行方法来抑制视觉伪影。一种典型的方法是独立地从奇数和偶数半帧重建两个完整帧。然而,由于大量的信息损失(50% 的损失),结果通常并不令人满意。通过首先估计对象运动可以获得更高质量的重建。然而,半隔行帧的运动估计并不可靠,而且计算成本也很高。因此,它们在实践中很少使用,更不用说实时应用了。
经典的超分辨率方法SRCNN基于单场重建每一帧,信息损失大。它还遵循传统的平移不变假设,该假设不适用于去隔行扫描问题。因此,它不可避免地会产生模糊的边缘和伪影,尤其是在清晰的边界周围。相比之下,本方法可以绕过这个问题并以更高的视觉质量和重建精度重建帧。
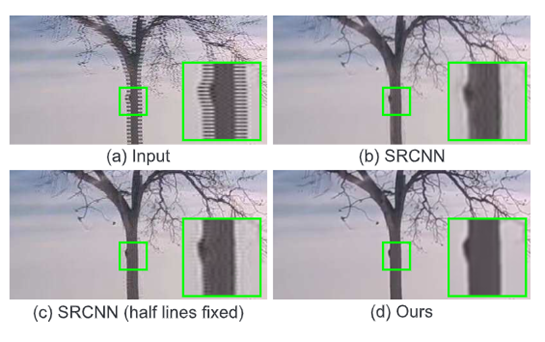
在本文中,作者提出了第一个为视频去隔行问题量身定制的深度卷积神经网络 (DCNN) 方法。不存在基于 DCNN 的去隔行方法。有人可能会争辩说,现有的基于 DCNN 的插值或超分辨率方法可用于从半帧重建全帧,以解决去隔行扫描问题。然而,这种朴素的方法缺乏利用奇偶半帧之间的时间信息,就像现有的场内去隔行方法。而且这种天真的方法遵循传统的平移不变假设。这意味着,即使一半的扫描线(奇数/偶数)实际上存在于输入半帧中,输出全帧中的所有像素都使用相同的一组卷积滤波器进行处理。下图b显示了一个全帧,由最先进的基于 DCNN 的超分辨率方法重建,SRCNN ,表现出明显的光晕伪影。作者认为应该只重建丢失的扫描线,而不是用输入半帧中的真实像素替换来自卷积滤波的潜在错误污染像素并导致视觉伪影,下图c原始奇数/偶数扫描线中的像素完好无损。所有这些都促使作者设计一种新颖的 DCNN 模型,用于解决去隔行扫描问题。
可以简单地重新训练这些最先进的基于神经网络的方法来达到作者的去隔行目的。然而,作者的实验表明,视觉伪影仍然不可避免,因为这些 DCNN 通常遵循传统的平移不变假设并修改所有像素的值,即使在已知的奇数/偶数扫描线中也是如此。使用更大的训练数据集或更深的网络结构可能会缓解这个问题,但计算成本会急剧增加,并且仍然无法保证已知像素的值保持不变。修复了已知像素的值(图(c)),质量也不会提高。相比之下,作者提出了一种为去隔行量身定制的新型DCNN。模型只估计丢失的像素而不是整个帧,并且还考虑了时间信息以提高视觉质量。
特别是,新提出的 DCNN 架构绕过了平移不变假设并考虑了时间信息,作者的模型只估计丢失的像素而不是整个帧,并且还考虑了时间信息以提高视觉质量。首先,只估计丢失的扫描线以避免修改来自奇数/偶数扫描线(输入)的真实像素值。也就是说,神经网络系统的输出是两个半帧,只包含缺失的扫描线。与大多数忽略奇数帧和偶数帧之间时间信息的现有方法不同,从奇数帧和偶数帧中重建每个半输出帧。换句话说,神经网络系统将两个原始半帧作为输入并输出两个缺失的半帧(补码)。
由于有两个输出,因此需要两个神经网络进行训练。通过组合两个神经网络 的较低层来进一步加速它,因为输入是相同的,因此较低层的卷积滤波器是可共享的。通过这种改进的网络结构,可以实现实时性能。为了验证方法,在包括直播、传统电影和传统卡通在内的各种具有挑战性的交错视频中对其进行了评估。在所有实验中都获得了令人信服且视觉上令人愉悦的结果。还在视觉比较和定量测量方面将方法与现有的去隔行方法和基于 DCNN 的模型进行了比较。所有实验都证实,不仅在准确性方面优于现有方法,而且在速度方面也优于现有方法。
02
网络结构
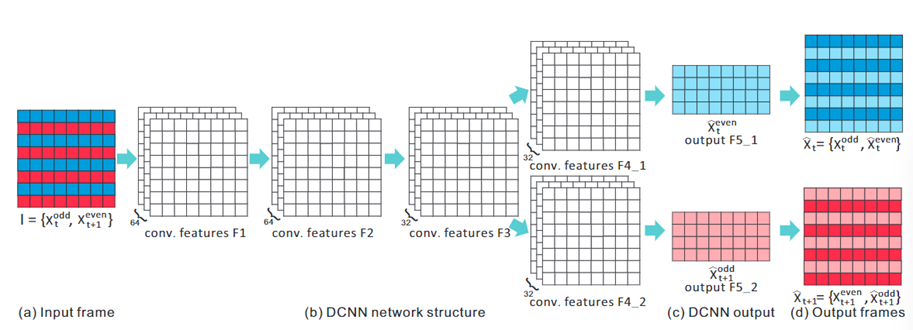
给定输入隔行帧I(图(a)),去隔行目标是从I重建两个全尺寸原始帧Xt和Xt+1(图(d))。将 I 的奇数场表示为 Xodd t(图(a)中的蓝色像素),将 I 的偶数场表示为 X even t+1(图 (a)中的红色像素)。上标奇数和偶数表示奇数或偶数半帧。下标 t 和 t + 1 表示两个字段是在两个不同的时间实例中捕获的。目标是重建两个丢失的半帧,X even t(图 (c)中的浅蓝色像素)和 X 奇数 Xoddt+1(图(c)中的粉红色像素)。请注意,保留了已知字段的两个输出全帧中的 X oddt(蓝色像素)和 Xevent+1(红色像素)(图(d))。为了从交错帧 I 中估计未知像素 X even t 和 Xoddt+1,提出了一种新颖的 DCNN 模型(图 (b)和(c))。输入的隔行帧可以是任意分辨率,用五个卷积层得到两个半输出图像。卷积算子的权重是从基于准备好的训练数据集的 DCNN 模型训练过程中训练出来的。在训练阶段,从不同类型的渐进视频合成一组交错视频作为训练对。需要合成隔行视频进行训练的原因是隔行扫描设备捕获的现有隔行视频不存在真实情况。
网络结构示意图如图所示。它包含五个卷积层。目标是从输入的隔行扫描帧 I 重建原始的两个帧 Xt 和Xt+1。在下面,首先解释设计原理,然后详细描述架构。
使用超分辨去做的缺点
输入/输出层一可能会建议利用现有的神经网络(例如 SRCNN )从 X odd t 中学习 Xt,从 X even t+1 中独立学习 Xt+1。这有效地将问题转化为超分辨率或图像放大问题。然而,有两个缺点。
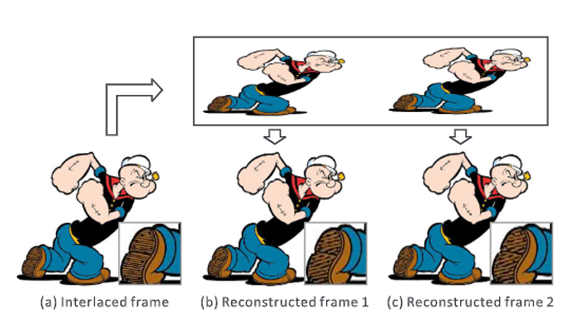
首先,由于两个帧重建过程(即从Xoddt到Xt和Xevent+1到Xt+1)是相互独立的,所以神经网络只能从已知的半帧估计全帧,而没有时间信息。由于大量 (50%) 的信息丢失,这不可避免地导致不太令人满意的结果。事实上,交错帧中的两个场在时间上是相关的。考虑一个极端情况,其中连续两次的场景帧是静态的。在这种情况下,两个连续的帧完全相同,隔行扫描的帧也应该是无伪影的,并且与正在寻找的gt完全相同。然而,使用这种朴素的超分辨率方法,必须输入半帧 X oddt (或 X even t+1 )来重建全帧。它完全忽略了另一半帧(现在包含精确的像素值)并引入了伪影(由于 50% 的信息丢失)。下图显示了这样一种情况的糟糕结果。相比之下,提出的神经网络将整个交错帧 I 作为输入(上图(a))。请注意,在的网络中隐式考虑了时间信息,因为在不同时间实例捕获的两个场用于重建每个单帧。网络可以利用字段之间的时间相关性来提高更高级别卷积层的视觉质量。
其次,标准神经网络通常遵循传统的平移不变假设。这意味着输入图像中的所有像素都使用相同的卷积滤波器集进行处理。然而,在的去隔行应用中,Xt 和 Xt+1 中的一半像素实际上存在于 I 中,应该直接从 I 中复制。在这些已知像素上应用卷积滤波器不可避免地会改变它们的原始颜色并导致清晰的伪影。相比之下,神经网络仅估计未知像素 X even t 和 X odd t+1并将已知像素从 I 直接复制到 Xt 和 Xt+1 .
路径设计
由于从隔行扫描帧 I 估计两个半帧 X even t 和 Xodd t+1,实际上必须独立地训练两个网络/路径。单独训练两个网络的计算成本很高。与其训练两个网络,不如建议训练一个网络,通过将每个卷积层的深度加倍来同时估计两个半帧。然而,这也大大增加了计算成本,因为训练的权重数量增加了一倍。深度神经网络是寻求输入数据的良好表示,如果输入数据相似,这种表示可以转移到许多其他任务中。例如,AlexNet(最初设计用于对象识别)的训练特征也可用于纹理识别和分割。事实上,低层卷积网络的层总是较低级别的特征检测器,可以检测边缘和其他基元。通过在它们之上训练新的更高级别的层,可以将经过训练的模型中的这些较低级别的层重用于新任务。因此,在去隔行场景中,很自然地将较低级别的卷积层结合起来以减少计算量,因为两个网络/路径的输入完全相同。在这些权重共享的低层之上,高层层分别被训练用于估计 X even t 和 X odd t+1。这使得更高级别的层更能适应不同的目标。方法可以看作是训练一个神经网络来估计 Xeven t ,然后固定前三个卷积层并重新训练第二个神经网络来估计 X odd t+1 。
详细架构
网络包含五个带权重的卷积层。第一层、第二层和第三层依次连接并由两条通路共享。第一个卷积层有 64 个大小为 3×3×1 的内核。第二个卷积层有 64 个大小为 3 × 3 × 64 的内核,并连接到第一层的输出。第三个卷积层有 64 个大小为 1 × 1 × 64 的内核,并连接到第二层的输出。第四层和第五层分支为两条路径,它们之间没有任何联系。第四个卷积层有 64 个大小为 3 × 3 × 64 的内核,其中每个路径有 32 个内核。第五个卷积有 2 个大小为 3×3×64 的内核,其中每个路径有 1 个内核。前两层的激活函数是 ReLU 函数,而其余层的激活函数是识别函数。前四层的卷积步长为 1 个像素。对于最后一层,水平步长保持1个像素,垂直步长为2个像素,得到半高图像。
03
数据及训练过程
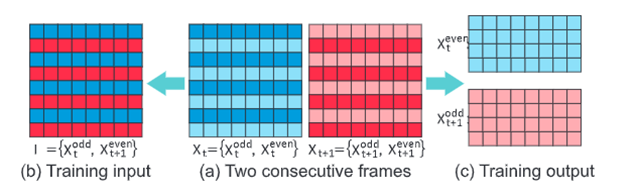
虽然 Internet 上存在大量交错视频,但不幸的是,这些视频缺乏真实性。因此,为了准备训练数据集,必须从现有的逐行视频中合成隔行视频。为了丰富数据种类,从互联网上收集了 33 个视频,并自己使用逐行扫描设备捕获了 18 个视频。这些视频具有不同的类型,从风景、体育、计算机渲染到经典电影和卡通。然后从每个收集的视频中随机抽取 3 对连续帧,总共获得 153 对帧。对于每对连续帧,将每帧重新缩放到 512 × 512 的大小,并将它们标记为一对原始帧 Xt 和 Xt+1(地面实况全帧)(图 (a))。然后在这两个原始帧的基础上合成一个交错的帧为 I = {Xodd t ,X even t+1 },即 I 的奇数行从 Xt 复制,I 的偶数行从 Xt+1 复制(图(b))。对于每个512 × 512 分辨率的三元组 ⟨I,Xt,Xt+1⟩,进一步将它们分成 64×64 分辨率的
训练得目标函数如下:
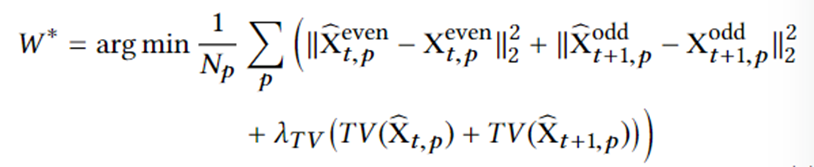
其中 Np 是训练样本的数量,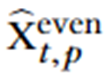 和
和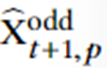 是神经网络的估计输出,TV(·) 是variation regularizere和 λTV是正则化标量。
是神经网络的估计输出,TV(·) 是variation regularizere和 λTV是正则化标量。
使用 Tensorflow 在配备单个nVidia TITAN X Maxwell GPU 的工作站上训练了神经网络。标准的 ADAM 优化方法用于求解方程。在实验中,学习率为 0.001,λT V 设置为 2 ×10 -8。epoch 数为 200,每个 epoch 的批次大小为 64。训练神经网络大约需要 4 小时。
04
结果
为了定量评估(与真实情况相比),从不同类型的逐行扫描视频中合成了一组测试隔行扫描视频。训练数据中不存在这些合成交错视频。虽然可以从每个单独的隔行帧中恢复两个全尺寸帧,但只在所有结果中显示第一帧。
视觉比较首先将本方法与经典的双三次插值和现有的为超分辨率定制的 DCNN,即 SRCNN进行比较。由于SRCNN 不是为去隔行而设计的,使用准备的数据集重新训练他们的模型以用于去隔行。结果如图所示。“Soccer”、“Bus”和“Tennis”采用1080i 格式并表现出严重的交错伪影。 此外,帧还包含运动模糊和视频压缩伪影。由于双三次插值和 SRCNN 都仅从单个场重建每一帧,因此它们的结果并不令人满意,并且由于大量的信息丢失而表现出明显的伪影。SRCNN 的性能甚至比双三次插值更差,因为它遵循传统的平移不变假设,而在去隔行场景中不适用。相比之下,本方法可以获得比竞争对手更清晰、更清晰的结果。“猎人”示例展示了游戏中的移动角色,其中计算机渲染的对象轮廓/边界被清晰地保留。双三次插值和 SRCNN 都会导致这些尖锐边缘附近出现模糊和锯齿形。相比之下,本方法在实现清晰和平滑的边界方面获得了最好的重建结果。“Haystack”和“Rangers”示例均取自隔行 NTSC 格式的旧版 DVD。在“干草堆”示例中,只有角色在移动,而背景保持静止。在不考虑时间信息的情况下,双三次插值和SRCNN 都无法恢复大海捞针的精细纹理并获得模糊的结果。与此形成鲜明对比的是,本方法通过考虑两个领域成功地恢复了精细纹理。

进一步将本方法与最先进的去隔行方法进行比较,包括 ELA、WLSD 和 FBA。由于 ELA 的高性能,它是最广泛使用的去隔行方法。它是一种场内方法,并使用边缘方向相关性来重建丢失的扫描线。WLSD 是最先进的基于优化的场内去隔行方法。它通常比 ELA 产生更好的结果,但计算成本更高。FBA 是最先进的场间方法。下图 显示了一组合成的所有方法的结果,其中有定量评估的基本事实。除了重建的帧,还放大了差异图像以获得更好的可视化。差异图像被简单地计算为输出和地面实况之间的像素级绝对差异。正如所观察到的,所有的竞争对手都会在边界周围产生伪影。越锋利界线越大,神器越明显。通常,ELA 产生最多的伪影,因为它采用简单的插值器并仅利用来自单个字段的信息。WLSD 产生较少的伪影,因为它采用更复杂的基于优化的策略来填充丢失的像素。但它仍然只利用了单一领域的信息,在重建过程中信息损失较大。尽管FBA利用时间信息,仍然无法获得良好的视觉质量,因为它们仅依赖于简单的插值器。相比之下,本方法产生的伪影比所有竞争对手都少得多。

定量评估
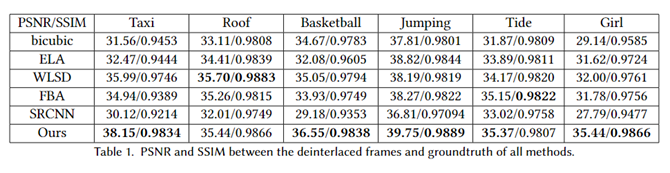
通过最小化方程的损失来训练神经网络。训练和验证损失在前几个时期后迅速减少,并在大约 50 个时期内收敛。还在峰值信噪比 (PSNR) 和结构相似性指数 (SSIM)方面将本方法的准确性与竞争对手进行了比较。请注意,只为那些具有 groundtruth 的测试视频计算 PSNR 和 SSIM。在计算两个测量值时取每个视频序列的所有帧的平均值。表 1 列出了统计数据。在大多数情况下,本方法在 PSNR 和 SSIM 方面都优于竞争对手。
时间
最后,在配备英特尔酷睿 CPU i7-5930、65GB RAM 并配备 nVidia TITAN X Maxwell GPU 的工作站上将本方法与竞争对手的运行时间进行了比较。统计数据如表 所示。本方法在所有分辨率下的所有方法中都取得了最高的性能。它的处理速度甚至比 ELA 还要快,而且视觉质量明显更好。ELA 和 SRCNN 具有相似的性能,但比本方法慢一些。双三次插值、WLSD 和 FBA 具有更高的计算复杂度并且远非实时处理。注意ELA只是没有GPU加速的CPU方式。特别是,使用单个GPU,本方法已经实现了分辨率高达 1024 × 768 (33 fps) 的实时性能。使用多一个 GPU,本方法还可以实现 1920 × 1080 分辨率视频的实时性能。还在不共享较低层的情况下测试模型,即重建两个帧需要两个单独的网络。统计数据显示在表 的最后一列中。该策略将计算时间大致增加了三倍,而质量与共享低级层的质量相似。

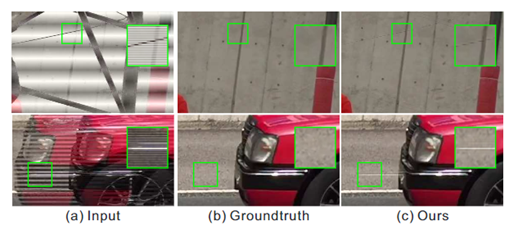
不足
由于本方法没有明确分离两个场来重建两个全帧,当两个场之间的运动非常大时,这两个场可能会严重相互干扰。图的第一行展示了一个例子,其中隔行帧有很大的运动,明显的伪影可以观察到。当交错帧包含非常薄的水平结构时,本方法也可能会失败。图 11 的第二行显示了一个例子,其中水平细反射条纹出现在汽车上。在隔行扫描帧中仅扫描反射条纹的一行。神经网络由于隔行扫描而无法识别它,而是将其视为原始结构并错误地将其保留在重建的帧中。这是因为这种补丁很少见,并且会被大量常见情况稀释。可以通过用更多这样的训练补丁训练神经网络来缓解这个问题

END
机器学习算法工程师
一个用心的公众号
