
漫画 | Google剽窃了我的算法?
上世纪90年代,互联网的大幕刚刚拉开......
此时的张大胖,还是一个正在读博的穷学生。
这一天,导师交给他一个光荣的任务。

Yahoo在当时用手工分类的方式来整理Web网页,解决了网民找网站的问题, 深受大家的喜爱。
但是导师表示Web即将爆发式增长,手工的方式根本不可持续,以后将是搜索的时代。
张大胖脑子中立刻就想到了解决方案。
导师看到张大胖迷茫的脸色,告诉他一个秘诀 :倒排索引。
张大胖到图书馆借了一本书,研究起来。
他觉得倒排索引这个词很古怪,但概念却非常简单。
比如说有这么两个网页:
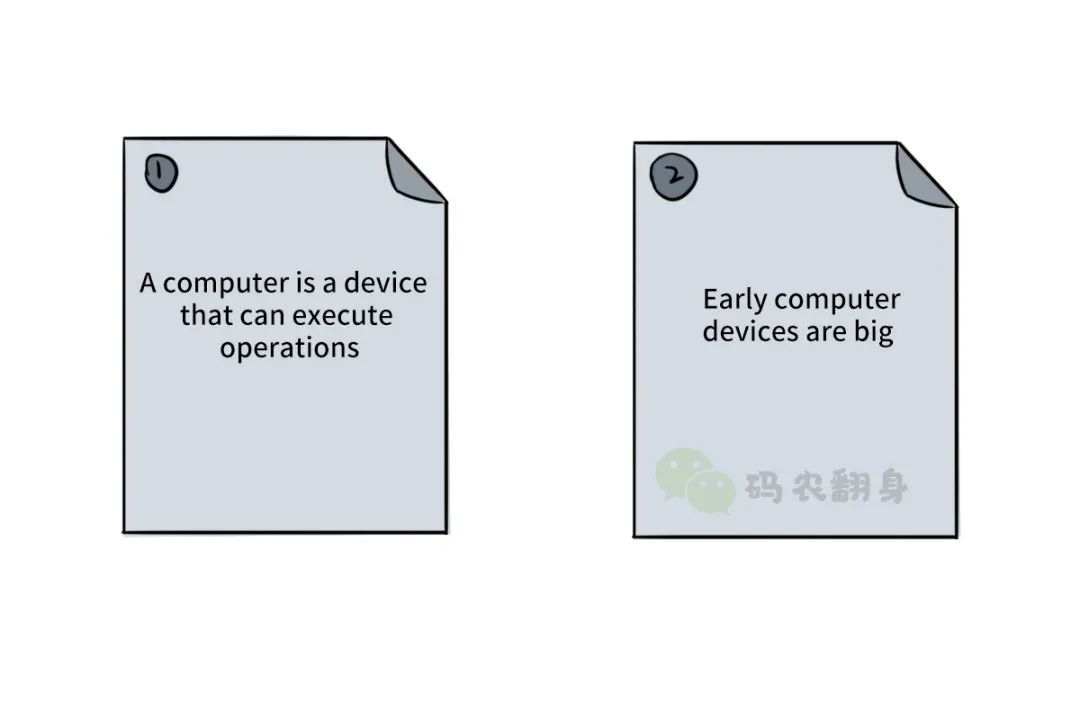
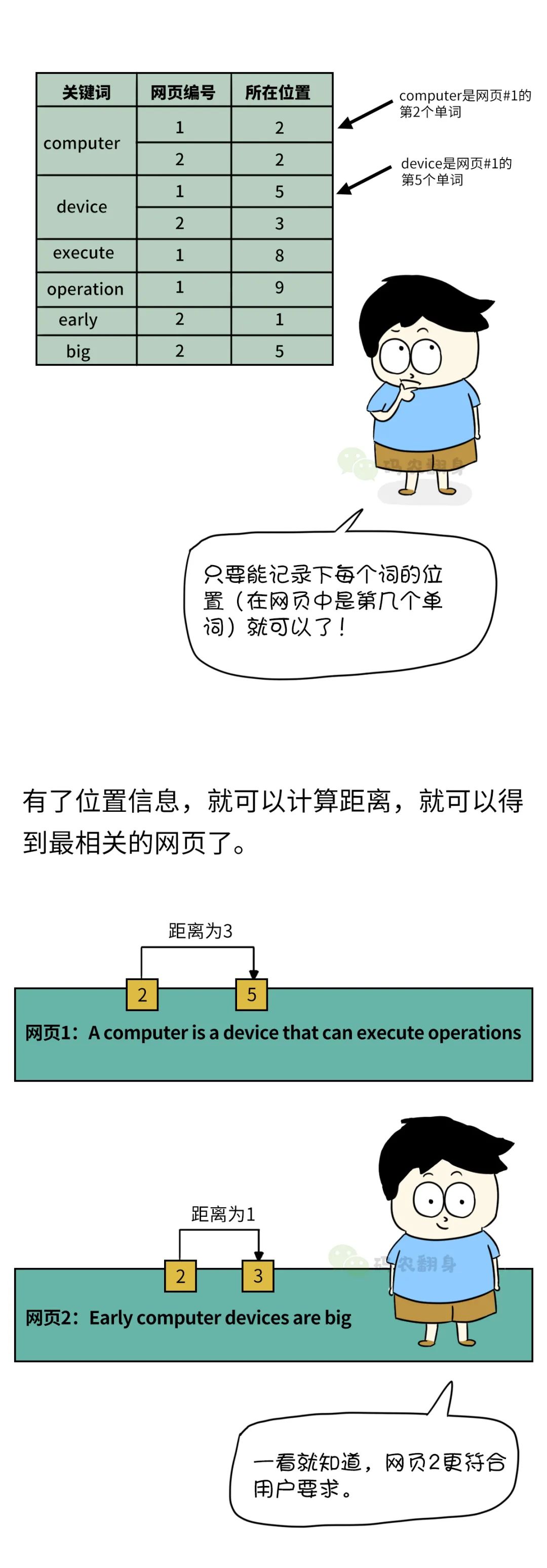
只要把其中的单词都抽取出来,记录下单词出现在哪个文档中,就形成了倒排索引。
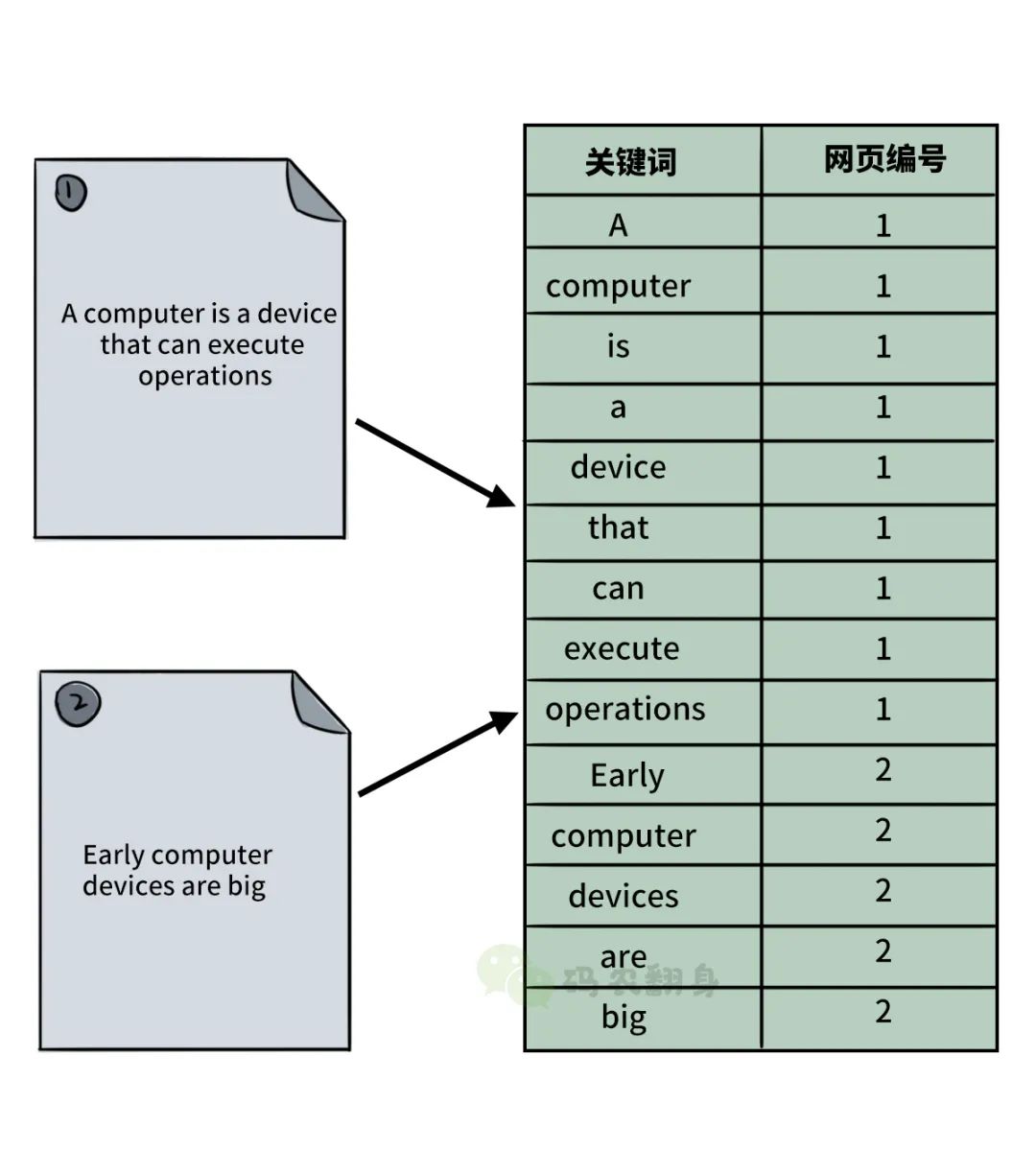
由于记录了每个单词所在的网页,只要给出一个单词,就可以迅速地定位到它在哪个网页中。
但是上面的倒排索引有点“粗糙”,还可以再“精化”一下。
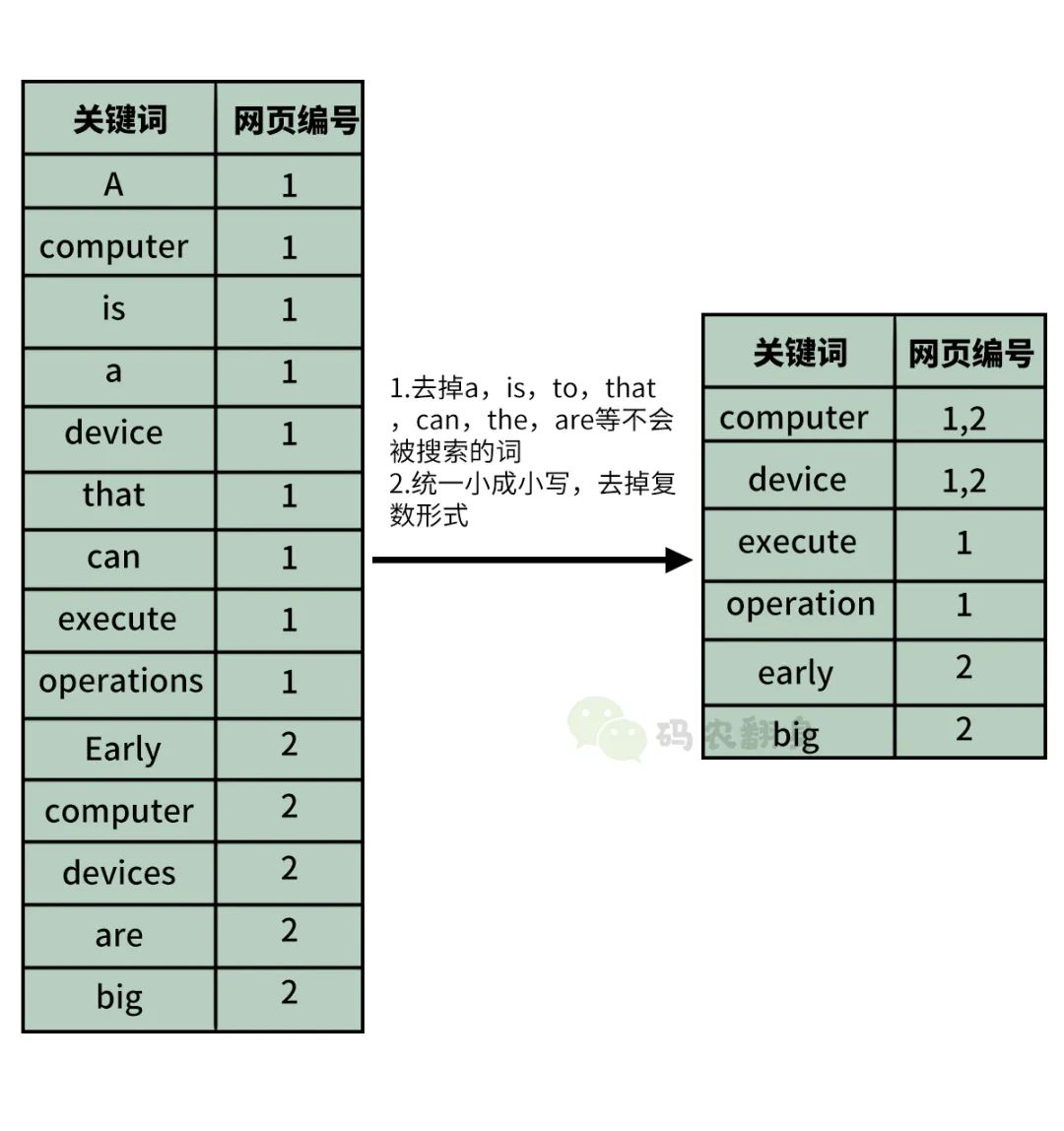
张大胖拿着这个倒排索引去找导师。

张大胖想了想, 其实要计算两个词的距离,这其实也并不很难。
张大胖以为这次可以交差了, 没想到导师再次提出难题。

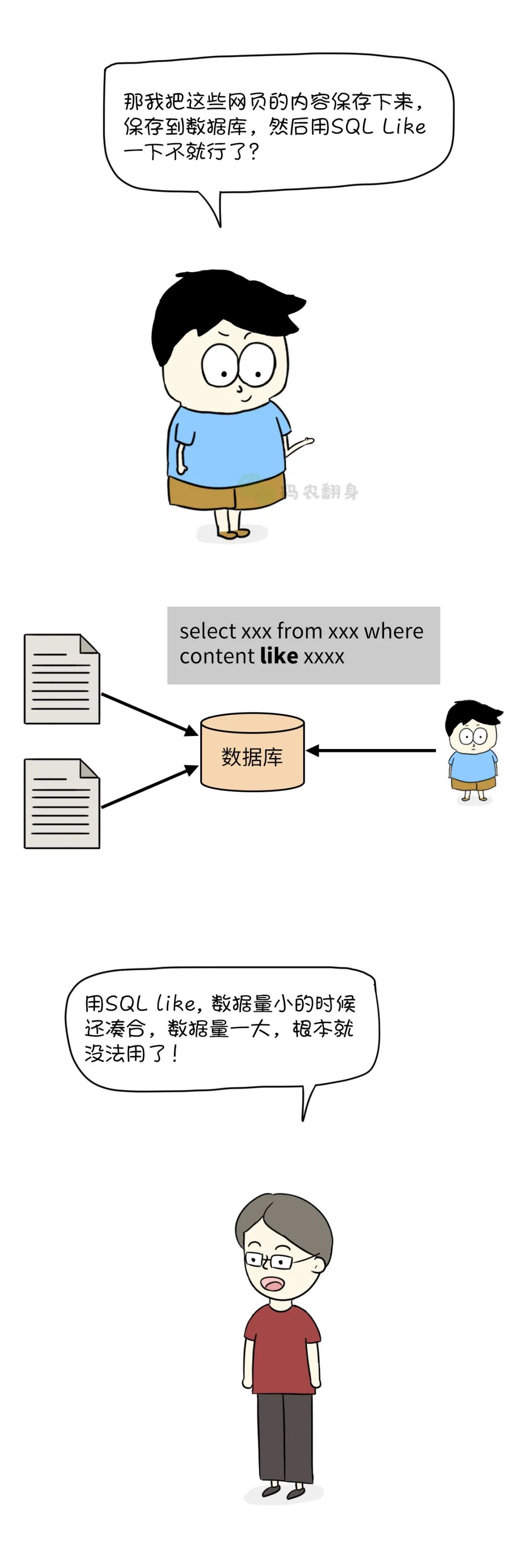
张大胖心说这导师真会难为人, 要不我把每个网页中的title内容单独搞个索引,这有点麻烦。
对了,能不能也记录下<title>和</title> 在文档中出现的位置呢?
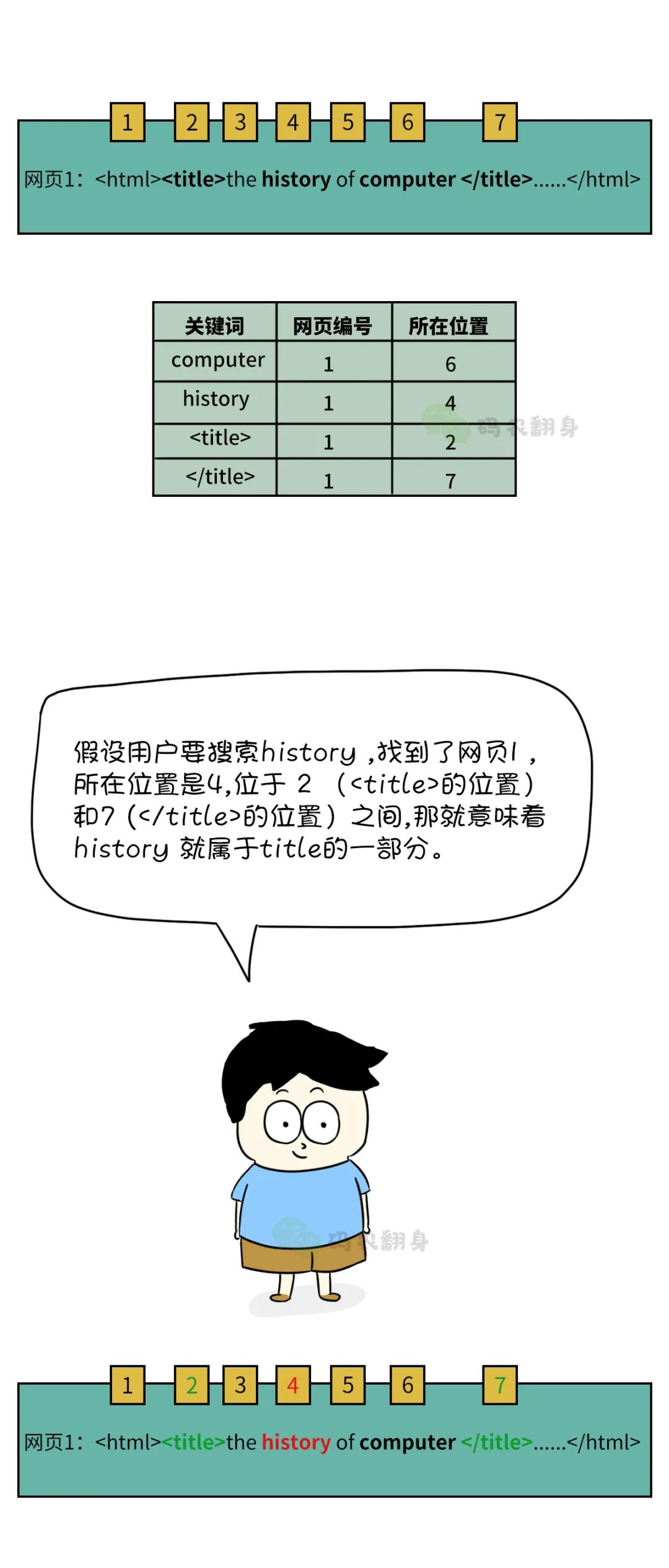
张大胖得意地给老师做了展示, 表示只要查看一份索引,就能实现对title搜索的功能了。

话虽这么说,张大胖还是试图去解决这个问题:如何衡量一个网页的重要性呢?
如果只看关键字在网页中出现的次数,那么可能会有人作弊:疯狂地向网页增加相关词,以此增加重要性,这肯定不行。
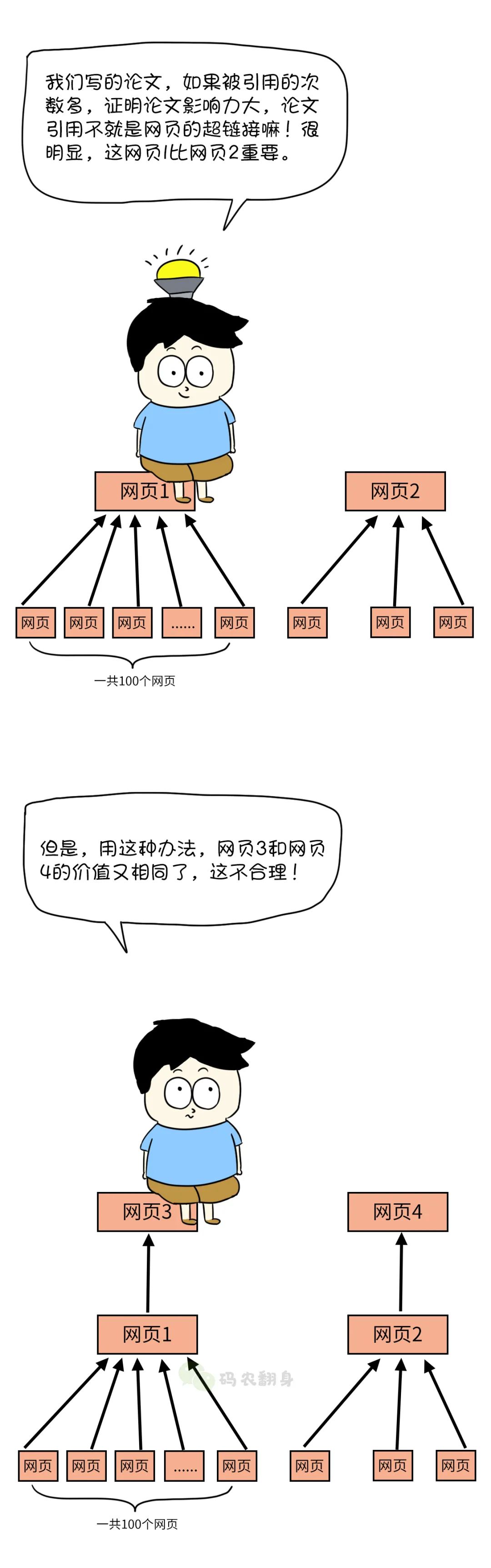
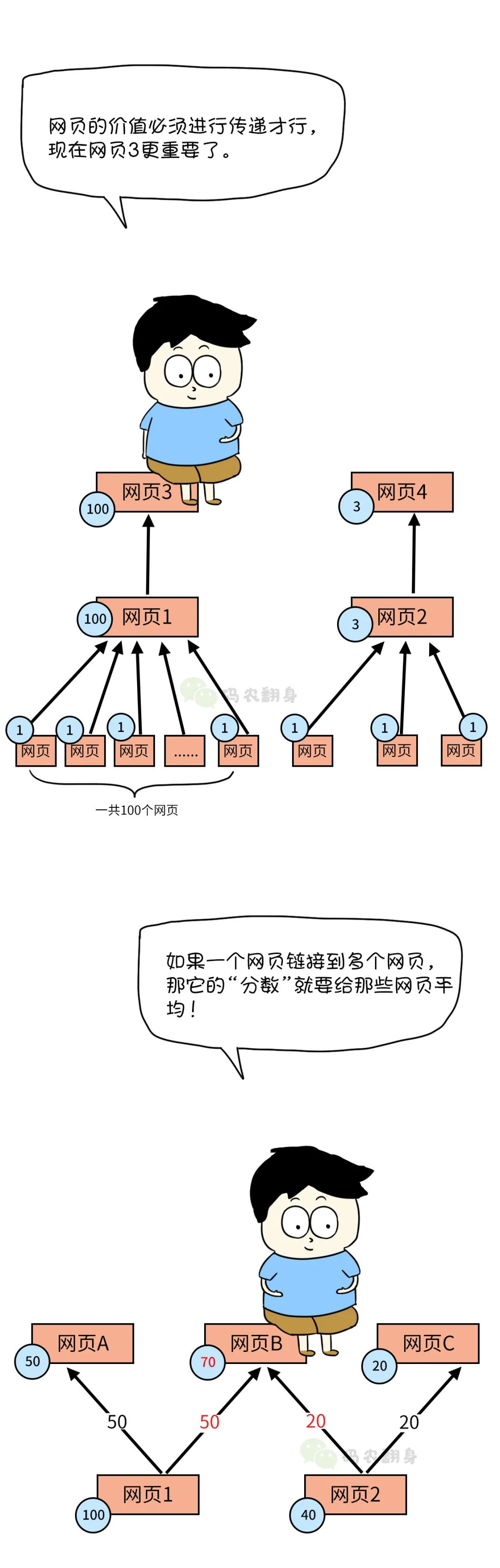
首先,先给每个网页一个相同的分数,然后使用这个算法计算出最终的“分数”, 也就是网页的价值了。
张大胖开始发挥自己的“数学能力”,把思路转化为数学公式。
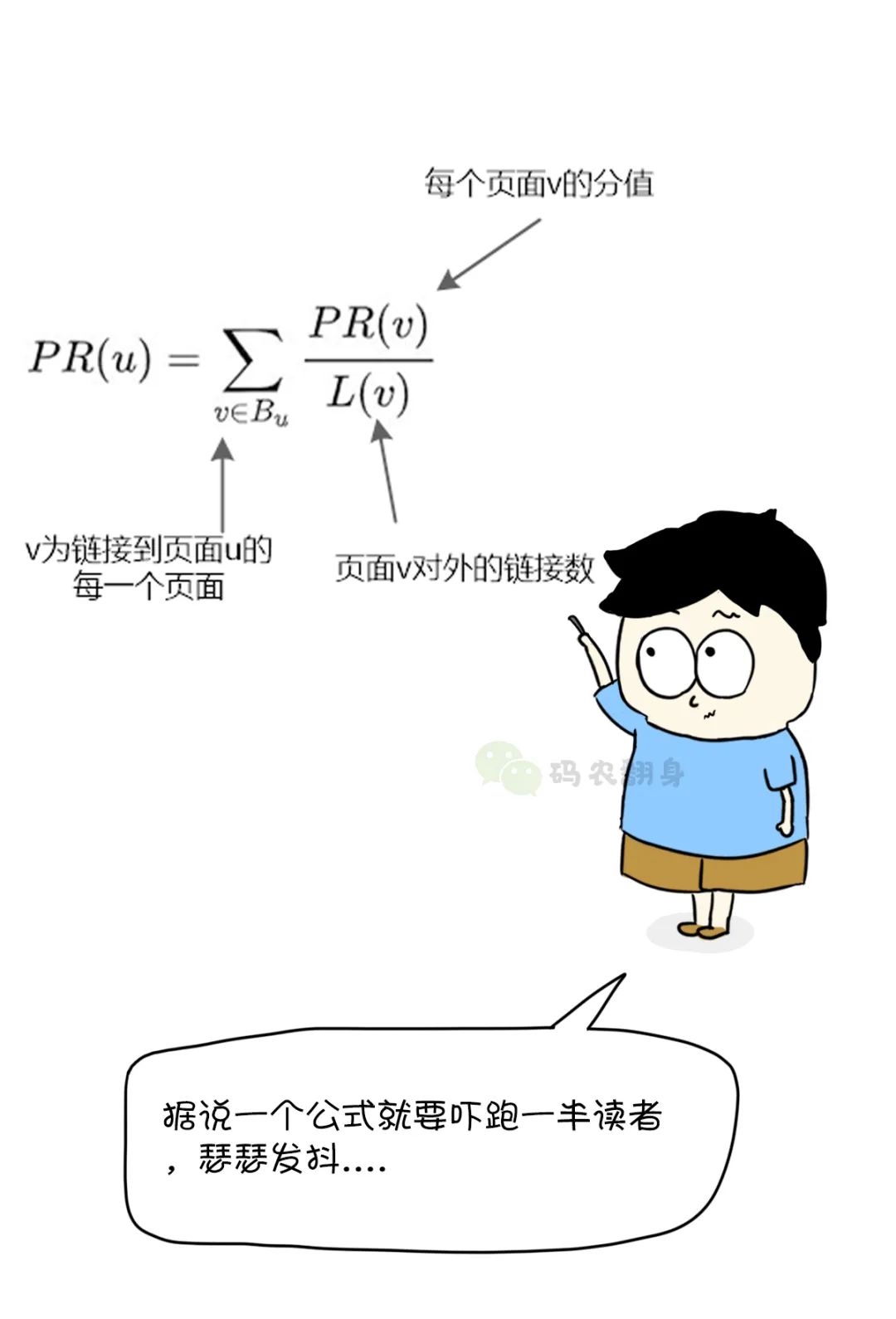
张大胖兴冲冲地拿着自己的研究成果去找导师。



在老师的指导下,张大胖发表了一篇论文《大规模网络搜索引擎的算法》,博士顺利毕业。
既然理论都搞定了,能不能把这么伟大的算法在现实网络中实现了呢?

张大胖没办法,面试进了一家著名外企,开始了打工人的生活。
一年以后, 美国传来消息, 有个叫Google的搜索引擎公司横空出世,很快就统治了搜索市场, 公司上市后, 创始人瞬间财务自由 。
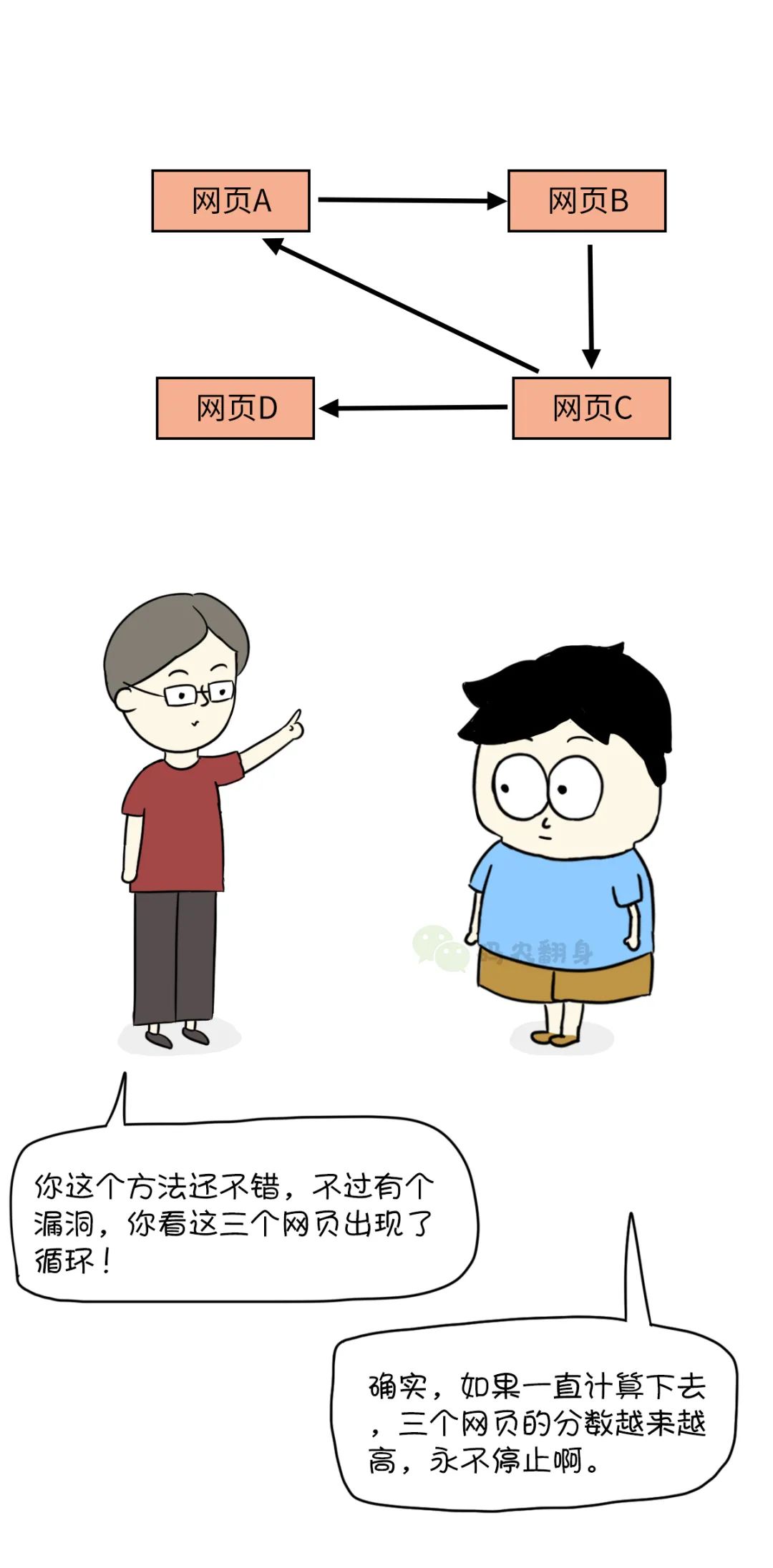
张大胖好奇地查看Google的核心技术: PageRank, 发现和自己的思路好像,难道它剽窃了自己的算法?这当然是不可能的!!
想到错失的机会,张大胖非常沮丧。
—— 图书推荐 ——

《码农翻身》
刘欣(@码农翻身) 著
本书讲了很多很多故事,在读故事的过程中就能轻松掌握相关技术,让你在畅快的阅读后,会有一种“原来如此”的感觉。
书中把计算机元素和行为用拟人手法编成一个个精彩纷呈的故事,绘声绘色且深入浅出地演绎晦涩枯燥的编程知识。学习优秀的架构师是如何思考、如何抽象、如何成长的,从操作系统、Java语言到Web技术,每个主题都深入浅出。
▲扫码获取本书详情▲
如果喜欢本文
欢迎 在看丨留言丨分享至朋友圈 三连
热文推荐
▼点击阅读原文,获取本书详情~