CVPR 2021 | 视觉目标检测大模型GAIA:面向行业的视觉物体检测一站式解决方案
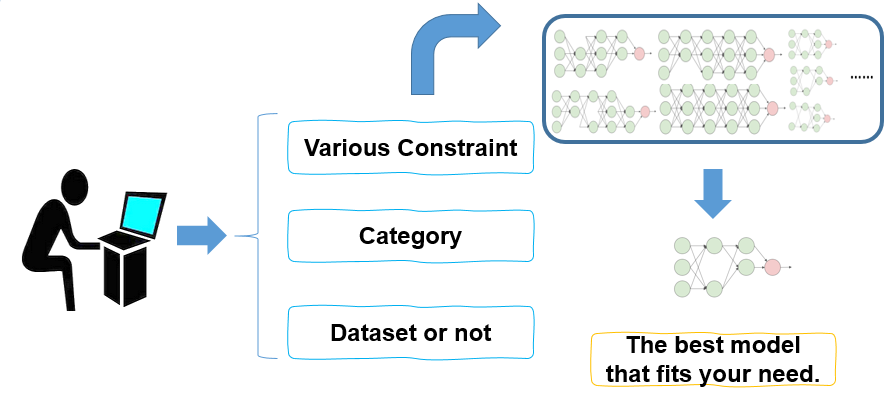
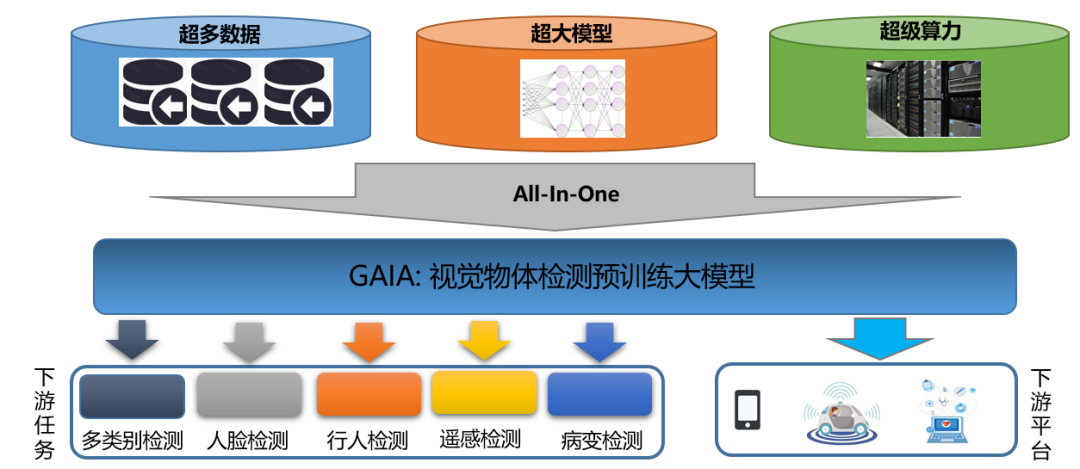
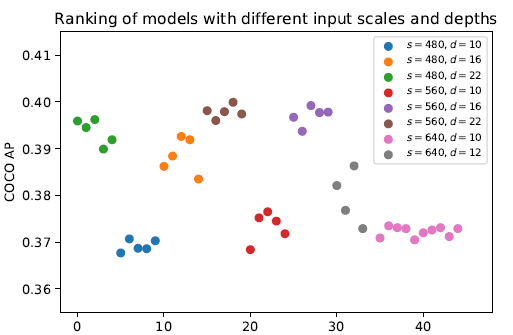
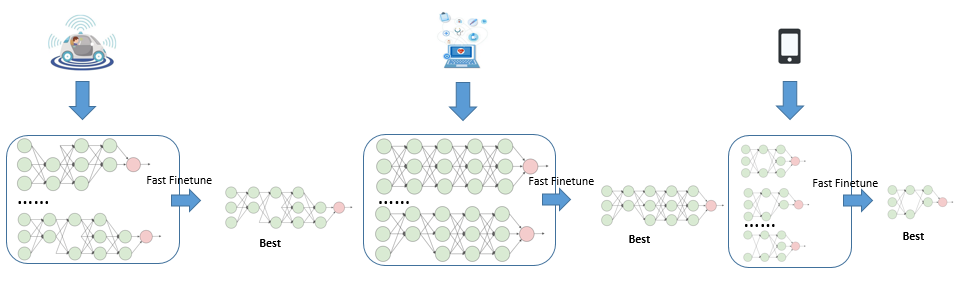
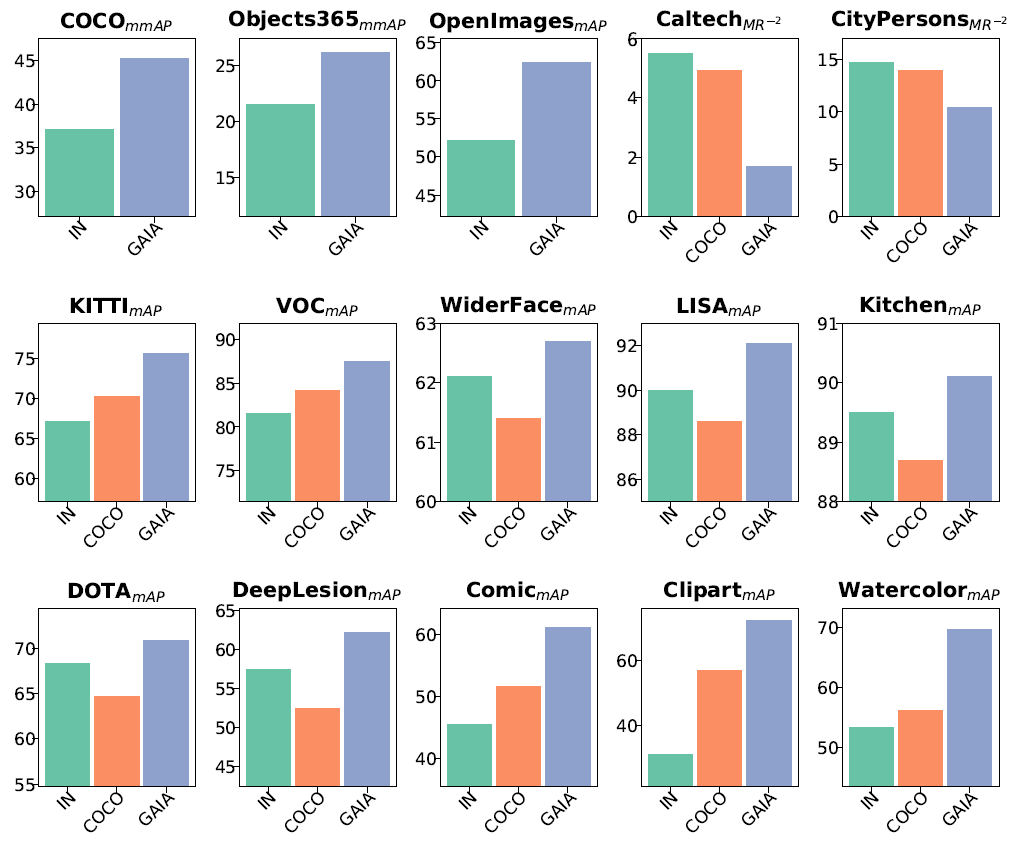
中国科学院自动化研究所智能感知与计算研究中心联合华为等企业提出面向行业的视觉物体检测一站式解决方案 GAIA。

论文地址:https://arxiv.org/pdf/2106.11346.pdf
开源框架:https://github.com/GAIA-vision

—版权声明—
来源:机器之心
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
评论
 下载APP
下载APP中国科学院自动化研究所智能感知与计算研究中心联合华为等企业提出面向行业的视觉物体检测一站式解决方案 GAIA。
论文地址:https://arxiv.org/pdf/2106.11346.pdf
开源框架:https://github.com/GAIA-vision
—版权声明—
来源:机器之心
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!