
10个人有9个答错,另外1个只对一半:数据库的锁,到底锁的是什么?

Record Lock
SELECT c1 FROM t WHERE c1 = 10 For UPDATE;会对c1=10这条记录加锁,为了防止任何其他事务插入、更新或删除c1值为10的行。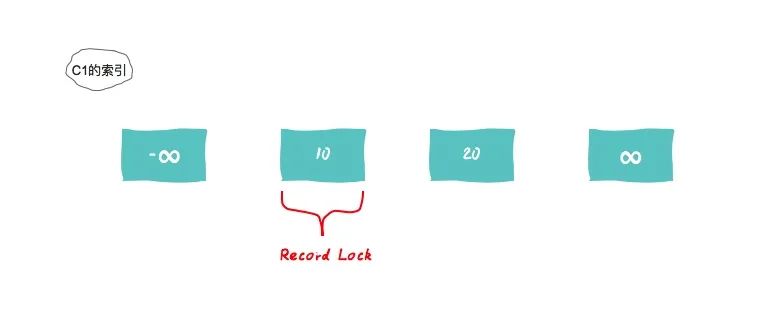
需要特别注意的是,记录锁锁定的是索引记录。即使表没有定义索引,InnoDB也会创建一个隐藏的聚集索引,并使用这个索引来锁定记录。
Gap Lock
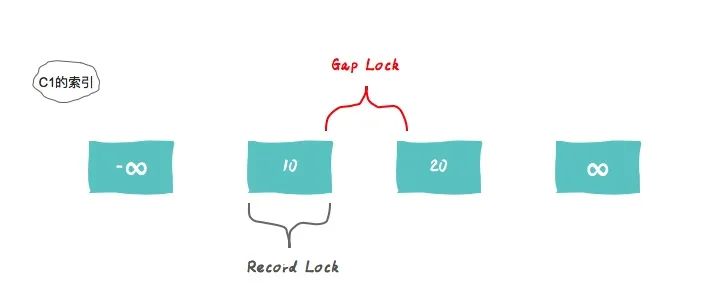
既然是锁,那么就可能会影响到数据库的并发性,所以,间隙锁只有在Repeatable Reads这种隔离级别中才会起作用。
对于具有唯一搜索条件的唯一索引,InnoDB只锁定找到的索引记录,而不会锁定间隙。 对于其他搜索条件,InnoDB锁定扫描的索引范围,使用gap lock或next-key lock来阻塞其他事务插入范围覆盖的间隙。
Next-Key Lock
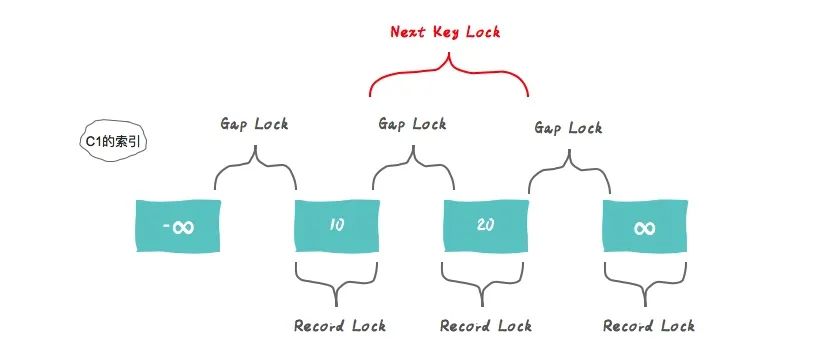
假设一个索引包含值10、11、13和20。此索引可能的next-key锁包括以下区间:
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
(20, ∞ ]
Repeatable Reads能解决幻读
MySQL的加锁原则
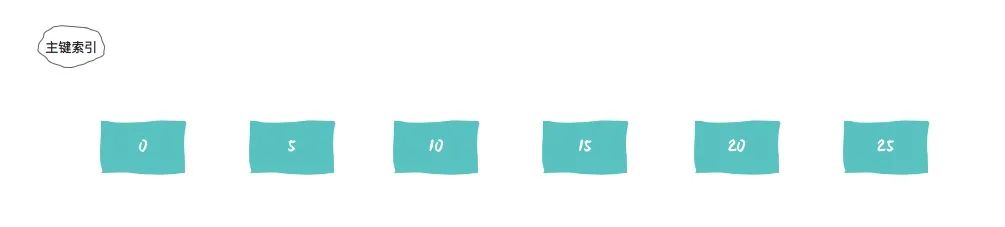
当我们执行update t set d=d+1 where id = 7的时候,由于表 t 中没有 id=7 的记录,所以:
根据原则 1,加锁单位是 next-key lock,session A 加锁范围就是 (5,10]; 根据优化 2,这是一个等值查询 (id=7),而 id=10 不满足查询条件,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10)。
select * from t where id>=10 and id<11 for update的时候:根据原则 1,加锁单位是 next-key lock,会给 (5,10]加上 next-key lock,范围查找就往后继续找,找到 id=15 这一行停下来 根据优化 1,主键 id 上的等值条件,退化成行锁,只加了 id=10 这一行的行锁。 根据原则 2,访问到的都要加锁,因此需要加 next-key lock(10,15]。因此最终加的是行锁 id=10 和 next-key lock(10,15]。
select * from t where id>10 and id<=15 for update的时候:* 根据原则 1,加锁单位是 next-key lock,会给 (10,15]加上 next-key lock,并且因为 id 是唯一键,所以循环判断到 id=15 这一行就应该停止了。* 但是,InnoDB 会往前扫描到第一个不满足条件的行为止,也就是 id=20。而且由于这是个范围扫描,因此索引 id 上的 (15,20]这个 next-key lock 也会被锁上。
当我们执行select id from t where c=5 lock in share mode的时候:
根据原则 1,加锁单位是 next-key lock,因此会给 (0,5]加上 next-key lock。要注意 c 是普通索引,因此仅访问 c=5 这一条记录是不能马上停下来的,需要向右遍历,查到 c=10 才放弃。 根据原则 2,访问到的都要加锁,因此要给 (5,10]加 next-key lock。 根据优化 2:等值判断,向右遍历,最后一个值不满足 c=5 这个等值条件,因此退化成间隙锁 (5,10)。 根据原则 2 ,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁。
select * from t where c>=10 and c<11 for update的时候:根据原则 1,加锁单位是 next-key lock,会给 (5,10]加上 next-key lock,范围查找就往后继续找,找到 id=15 这一行停下来 根据原则 2,访问到的都要加锁,因此需要加 next-key lock(10,15]。 由于索引 c 是非唯一索引,没有优化规则,也就是说不会蜕变为行锁,因此最终 sesion A 加的锁是,索引 c 上的 (5,10] 和 (10,15] 这两个 next-key lock。
总结
索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。 索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
评论