
讲一些关于Spark的Broadcast你不知道的细节
问题:为什么只能 broadcast 只读的变量?
问题:broadcast 到节点而不是 broadcast 到每个 task?
问题:具体怎么用 broadcast?
val data = List(1, 2, 3, 4, 5, 6)
val bdata = sc.broadcast(data)
val rdd = sc.parallelize(1 to 6, 2)
val observedSizes = rdd.map(_ => bdata.value.size)
sc.broadcast() 声明要 broadcast 的 data,bdata 的类型是 Broadcast。rdd.transformation(func) 需要用 bdata 时,直接在 func 中调用,比如上面的例子中的 map() 就使用了 bdata.value.size。问题:怎么实现 broadcast?
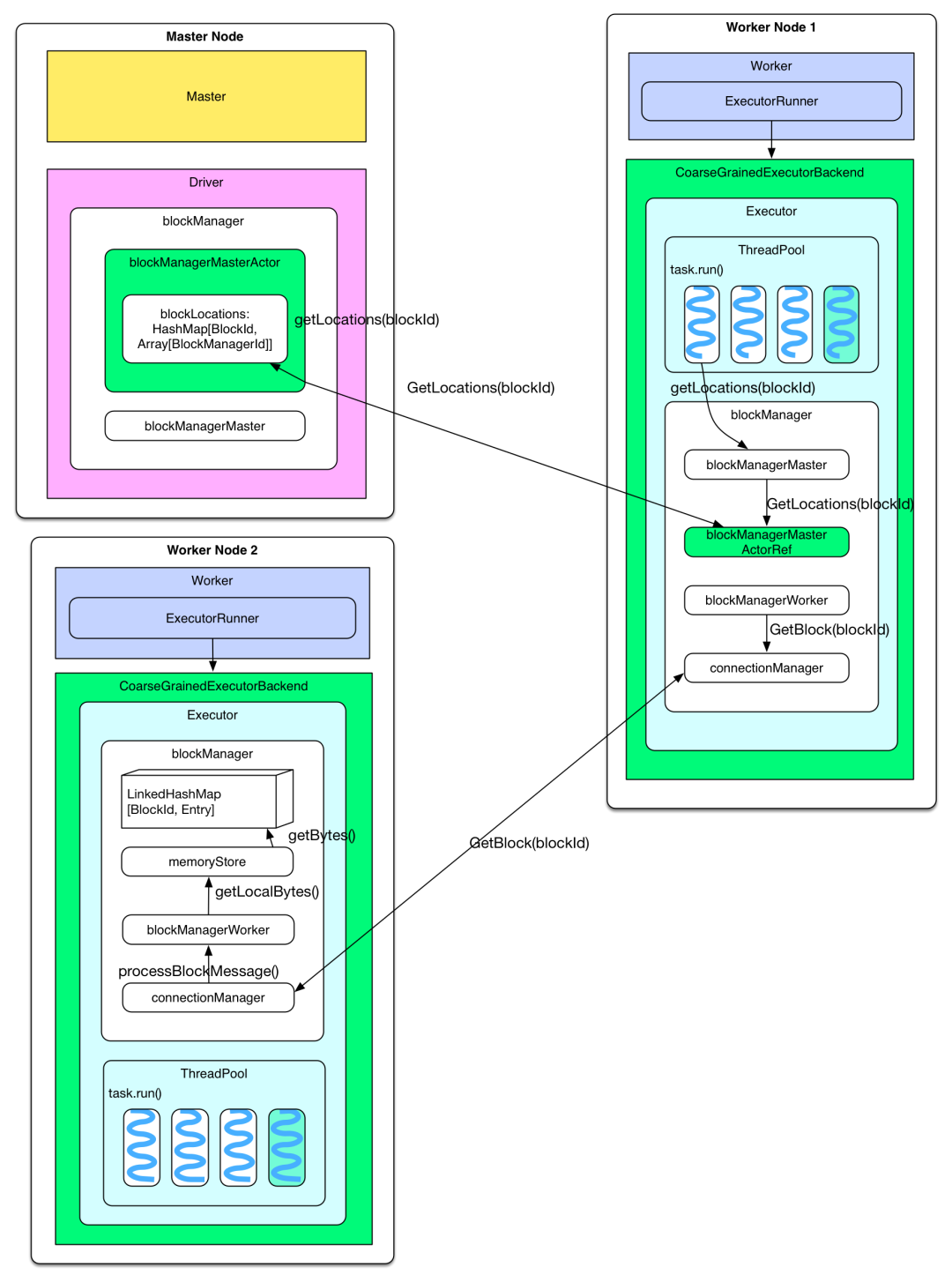
val bdata = sc.broadcast(data)时就把 data 写入文件夹,同时写入 driver 自己的 blockManger 中(StorageLevel 为内存+磁盘),获得一个 blockId,类型为 BroadcastBlockId。当调用rdd.transformation(func)时,如果 func 用到了 bdata,那么 driver submitTask() 的时候会将 bdata 一同 func 进行序列化得到 serialized task,注意序列化的时候不会序列化 bdata 中包含的 data。上一章讲到 serialized task 从 driverActor 传递到 executor 时使用 Akka 的传消息机制,消息不能太大,而实际的 data 可能很大,所以这时候还不能 broadcast data。driver 为什么会同时将 data 放到磁盘和 blockManager 里面?放到磁盘是为了让 HttpServer 访问到,放到 blockManager 是为了让 driver program 自身使用 bdata 时方便(其实我觉得不放到 blockManger 里面也行)。
sc.broadcast(data)后会调用工厂方法建立一个 HttpBroadcast 对象。该对象做的第一件事就是将 data 存到 driver 的 blockManager 里面,StorageLevel 为内存+磁盘,blockId 类型为 BroadcastBlockId。/var/folders/87/grpn1_fn4xq5wdqmxk31v0l00000gp/T/spark-6233b09c-3c72-4a4d-832b-6c0791d0eb9c/broadcast_0, 这个文件夹作为 HttpServer 的文件目录。Driver 和 executor 启动的时候,都会生成 broadcastManager 对象,调用 HttpBroadcast.initialize(),driver 会在本地建立一个临时目录用来存放 broadcast 的 data,并启动可以访问该目录的 httpServer。
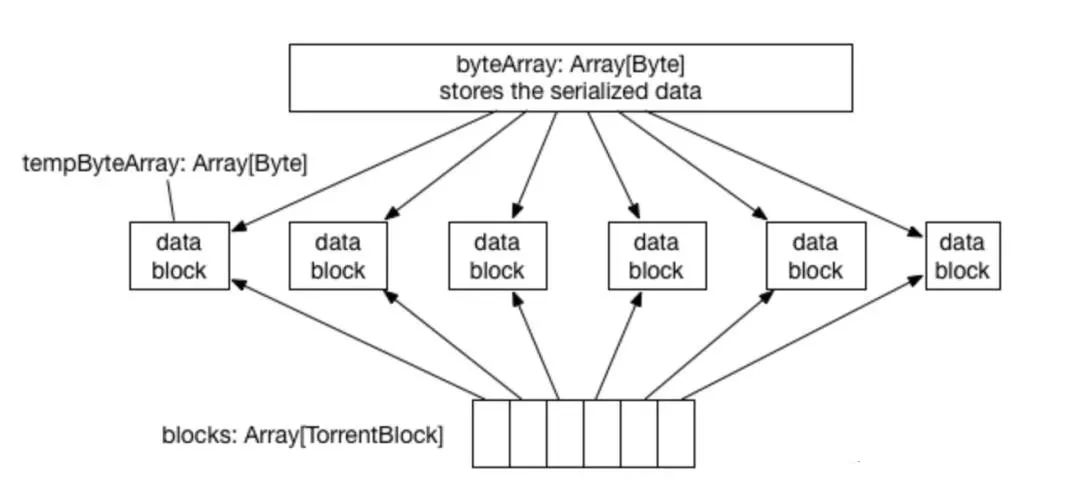
driver 端:
spark.broadcast.blockSize = 4MB 设置)大小的 data block,每个 data block 被 TorrentBlock 对象持有。切割完 byteArray 后,会将其回收,因此内存消耗虽然可以达到 2 * Size(data),但这是暂时的。Executor 端:
arrayOfBlocks = new Array[TorrentBlock](totalBlocks),TorrentBlock 是对 data block 的包装。然后打乱要 fetch 的 data blocks 的顺序,比如如果 data block 共有 5 个,那么打乱后的 fetch 顺序可能是 3-1-2-4-5。然后按照打乱后的顺序去 fetch 一个个 data block。fetch 的过程就是通过 “本地 blockManager -本地 connectionManager-driver/executor 的 connectionManager-driver/executor 的 blockManager-data” 得到 data,这个过程与 fetch cached rdd 类似。每 fetch 到一个 block 就将其存放到 executor 的 blockManager 里面,同时通知 driver 上的 blockManagerMaster 说该 data block 多了一个存储地址。这一步通知非常重要,意味着 blockManagerMaster 知道 data block 现在在 cluster 中有多份,下一个不同节点上的 task 再去 fetch 这个 data block 的时候,可以有两个选择了,而且会随机选择一个去 fetch。这个过程持续下去就是 BT 协议,随着下载的客户端越来越多,data block 服务器也越来越多,就变成 p2p下载了。关于 BT 协议)。问题:broadcast RDD 会怎样?
-libjars就是使用 DistributedCache 来将 task 依赖的 jars 分发到每个 task 的工作目录。不过分发前 DistributedCache 要先将文件上传到 HDFS。这种方式的主要问题是资源浪费,如果某个节点上要运行来自同一 job 的 4 个 mapper,那么公共数据会在该节点上存在 4 份(每个 task 的工作目录会有一份)。但是通过 HDFS 进行 broadcast 的好处在于单点瓶颈不明显,因为公共 data 首先被分成多个 block,然后不同的 block 存放在不同的节点。这样,只要所有的 task 不是同时去同一个节点 fetch 同一个 block,网络拥塞不会很严重。评论