
一文带你看懂Python数据分析利器——Pandas的前世今生

本文将从Python生态、Pandas历史背景、Pandas核心语法、Pandas学习资源四个方面去聊一聊Pandas,期望能带给大家一点启发。

一、Python生态里的Pandas
五月份TIOBE编程语言排行榜,Python追上Java又回到第二的位置。Python如此受欢迎一方面得益于它崇尚简洁的编程哲学,另一方面是因为强大的第三方库生态。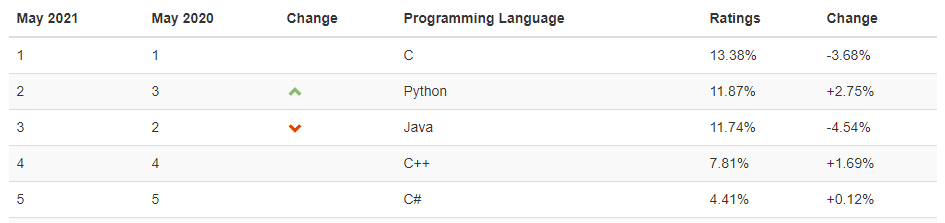
要说杀手级的库,很难排出个先后顺序,因为python的明星库非常多,在各个领域都算得上出类拔萃。
比如web框架-Django、深度学习框架-TensorFlow、自然语言处理框架-NLTK、图像处理库-PIL、爬虫库-requests、图形界面框架-PyQt、可视化库-Matplotlib、科学计算库-Numpy、数据分析库-Pandas......
上面大部分库我都用过,用的最多也最顺手的是Pandas,可以说这是一个生态上最完整、功能上最强大、体验上最便捷的数据分析库,称为编程界的Excel也不为过。
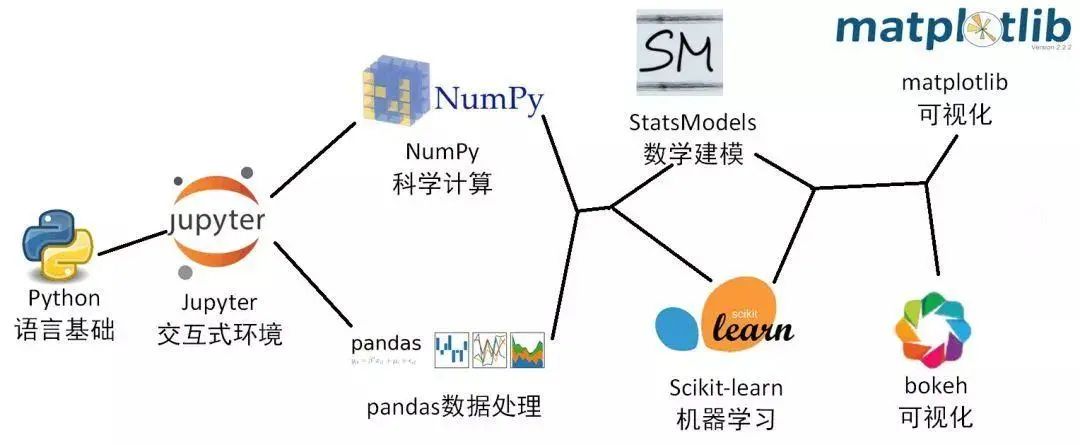
Pandas在Python数据科学链条中起着关键作用,处理数据十分方便,且连接Python与其它核心库。
二、十项全能的Pandas
Pandas诞生于2008年,它的开发者是Wes McKinney,一个量化金融分析工程师。

因为疲于应付繁杂的财务数据,Wes McKinney便自学Python,并开发了Pandas。
大神就是这么任性,没有,就创造。
为什么叫作Pandas,其实这是“Python data analysis”的简写,同时也衍生自计量经济学术语“panel data”(面板数据)。
所以说Pandas的诞生是为了分析金融财务数据,当然现在它已经应用在各个领域了。
❝2008: Pandas正式开发并发布
2009:Pandas成为开源项目
2012: 《利用Python进行数据分析》出版
2015: Pandas 成为 NumFOCUS 赞助的项目
❞
Pandas能做什么呢?
它可以帮助你任意探索数据,对数据进行读取、导入、导出、连接、合并、分组、插入、拆分、透视、索引、切分、转换等,以及可视化展示、复杂统计、数据库交互、web爬取等。
同时Pandas还可以使用复杂的自定义函数处理数据,并与numpy、matplotlib、sklearn、pyspark、sklearn等众多科学计算库交互。

Pandas有一个伟大的目标,即成为任何语言中可用的最强大、最灵活的开源数据分析工具。
让我们期待下。
三、Pandas核心语法
1. 数据类型
Pandas的基本数据类型是dataframe和series两种,也就是行和列的形式,dataframe是多行多列,series是单列多行。
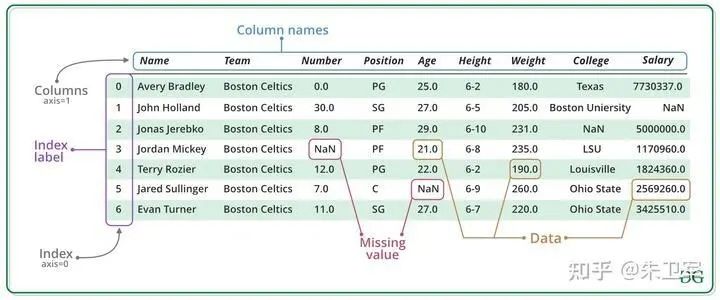
如果在jupyter notebook里面使用pandas,那么数据展示的形式像excel表一样,有行字段和列字段,还有值。
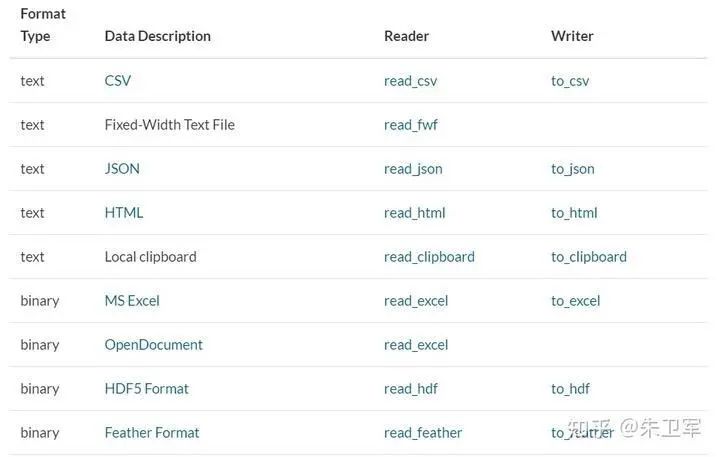
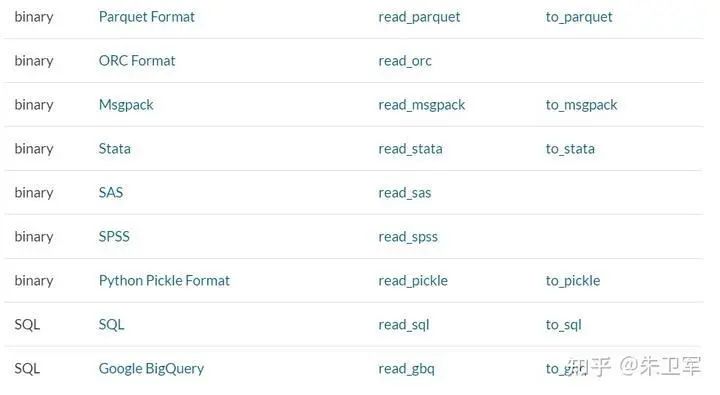
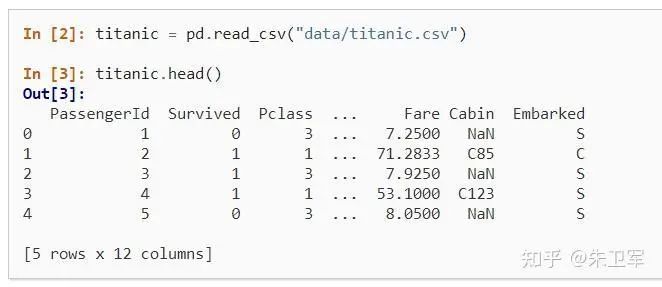
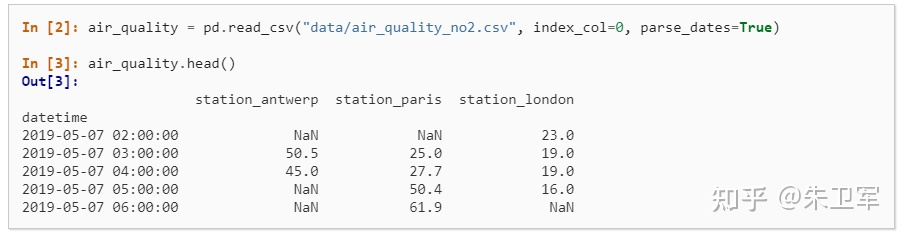
2. 读取数据
pandas支持读取和输出多种数据类型,包括但不限于csv、txt、xlsx、json、html、sql、parquet、sas、spss、stata、hdf5
读取一般通过read_*函数实现,输出通过to_*函数实现。

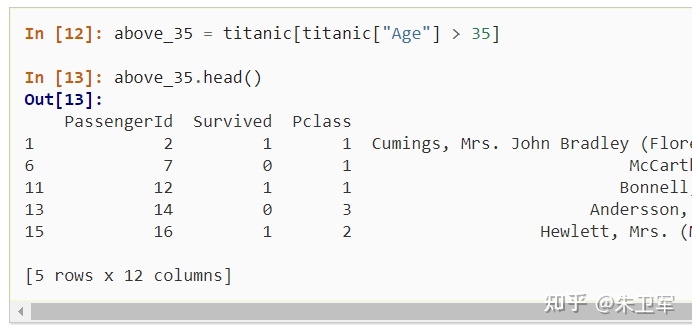
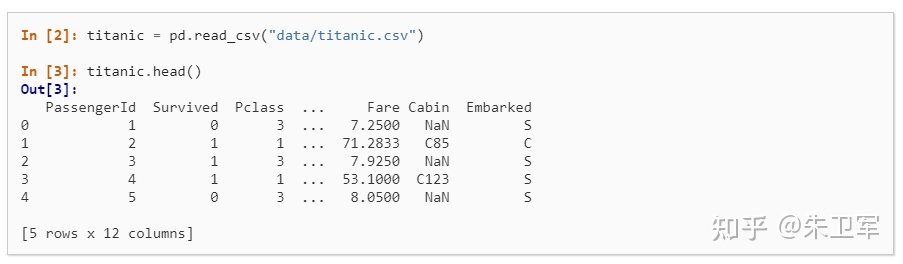
3. 选择数据子集
导入数据后,一般要对数据进行清洗,我们会选择部分数据使用,也就是子集。
在pandas中选择数据子集非常简单,通过筛选行和列字段的值实现。
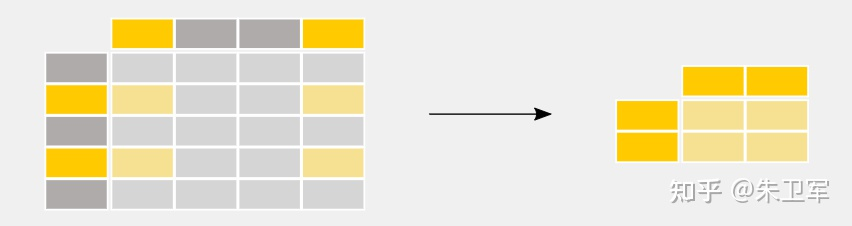
具体实现如下:
4. 数据可视化
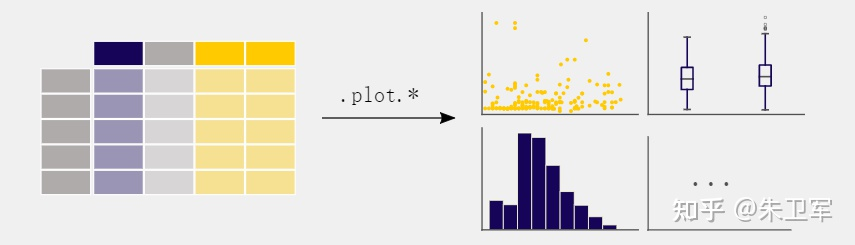
不要以为pandas只是个数据处理工具,它还可以帮助你做可视化图表,而且能高度集成matplotlib。
你可以用pandas的plot方法绘制散点图、柱状图、折线图等各种主流图表。
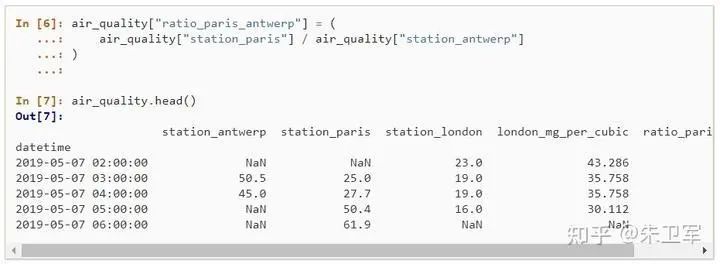
5. 创建新列
有时需要通过函数转化旧列创建一个新的字段列,pandas也能轻而易举的实现
6. 分组计算
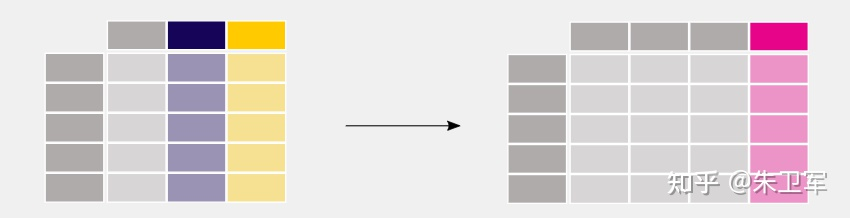
在sql中会用到group by这个方法,用来对某个或多个列进行分组,计算其他列的统计值。
pandas也有这样的功能,而且和sql的用法类似。


7. 数据合并
数据处理中经常会遇到将多个表合并成一个表的情况,很多人会打开多个excel表,然后手动复制粘贴,这样就很低效。
pandas提供了merge、join、concat等方法用来合并或连接多张表。

小结
pandas还有数以千计的强大函数,能实现各种骚操作。
python也还有数不胜数的宝藏库,等着大家去探索
