Allow the use of ";" to delimit multiple queries during one statement. This option does not affect the 'addBatch()' and 'executeBatch()' methods, which rely on 'rewriteBatchStatements' instead. 允许在一条语句中使用"; "分隔多个查询。该选项不会影响 "addBatch() "和 "executeBatch() "方法,因为它们依赖于 "rewriteBatchStatements"。
begin; delete from table1 where user_id=xxx; delete from table2 where user_id=xxx; delete from table3 where user_id=xxx; update table4 set user_status=1 where user_id=xxx; commit;
和卖货的场景不一样的是,在这个场景下如果每个 sql 执行成功,则代表业务执行成功。
看起来,似乎没什么问题。
但是我问你一个问题:这一组 SQL 一定会走都 commit 吗?
你好好想想?
肯定不一定嘛,保不齐执行的过程中出什么幺蛾子。
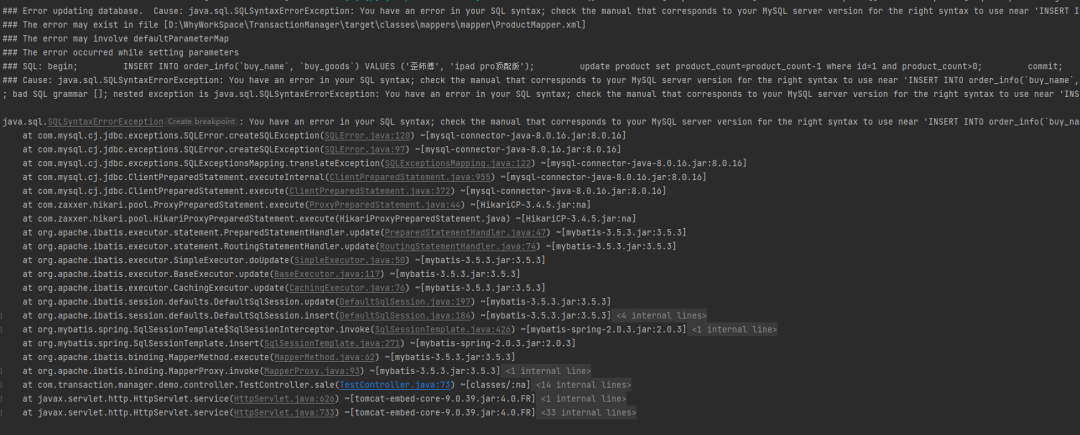
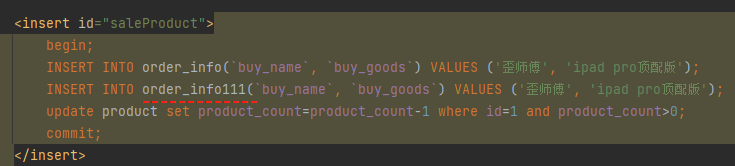
举个最简单的例子,表写错了:
在这个场景下,再次发起调用:
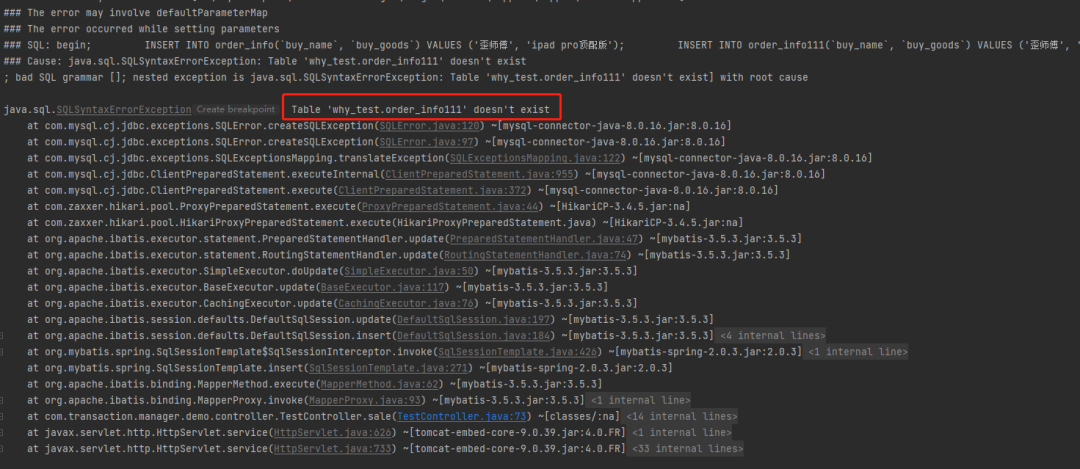
程序报错说找不到这个表。
那么请问:此时,订单表是否应该有数据被插入?
出异常了,肯定不应该有数据插入。我看了数据库,确实也没有新数据插入。
看起来确实没问题。
那么再请问:在这种写法的情况下,当前这个事务是被回滚了还是被提交了?
。。。
。。。
。。。
正确答案是被挂起了。
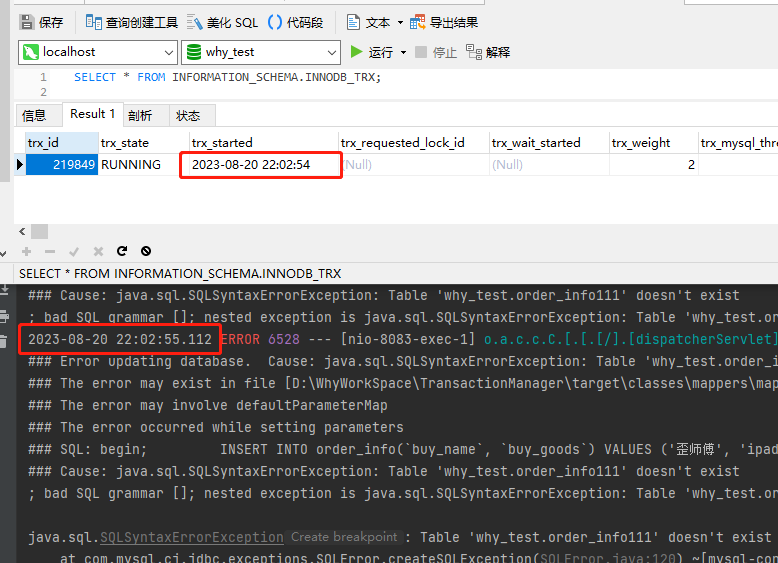
通过执行下面这个 SQL,我们可以获取到当前事务列表:
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
通过查询结果可以发现,在我们程序抛出异常之后,当前事务还在 RUNNING 状态:
而且,这个事务在服务重启之前,将一直在 RUNNING 状态,即被挂起了。
但仅从程序的角度看,抛出异常,没有数据,符合预期,没有任何毛病。
埋雷了。
所以,听歪师傅一句劝,千万别这样写!
老老实实的写大家都看得懂的 Java 代码,不要在 mapper.xml 里面搞事情。
扩展
其实我觉得吧,前面都属于卵用不大的知识点,因为大家一般都不会这样去写。
但是既然都写到这里了,场景也有了,我也给大家扩展一个稍微有点用的知识。
还是在卖货的场景下。
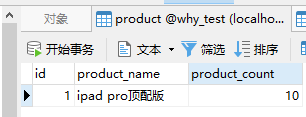
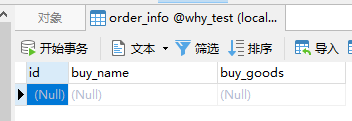
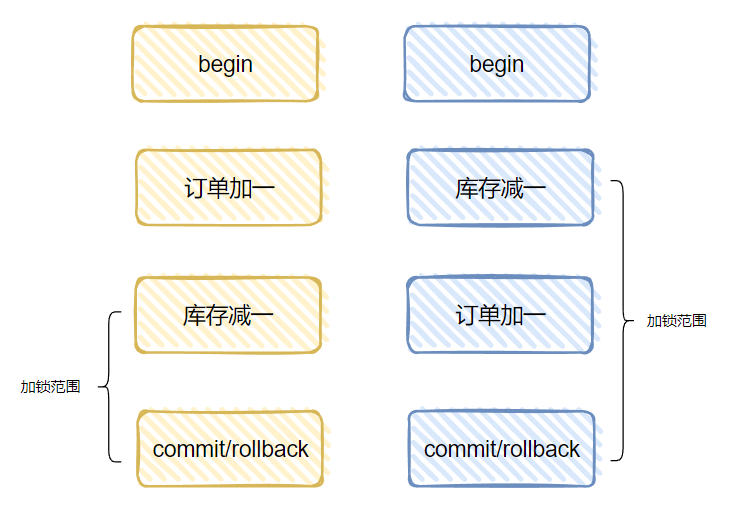
订单加一,库存减一是这样的。
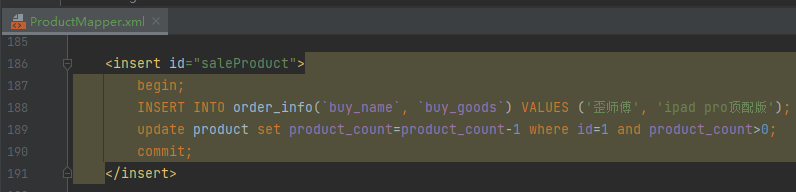
begin; INSERT INTO order_info(`buy_name`, `buy_goods`) VALUES ('歪师傅', 'ipad pro顶配版'); update product set product_count=product_count-1 where id=1 and product_count>0; commit;
而库存减一,订单加一是这样的:
begin; update product set product_count=product_count-1 where id=1 and product_count>0; INSERT INTO order_info(`buy_name`, `buy_goods`) VALUES ('歪师傅', 'ipad pro顶配版'); commit;