
用Python分析北京市蛋壳公寓租房数据

导读:近期,蛋壳公寓“爆雷”事件持续发酵,期间因拖欠房东房租与租客退款,蛋壳公寓陷入讨债风波,全国多地蛋壳公寓办公区域出现大规模解约事件,而作为蛋壳公寓总部所在地北京,自然首当其冲。
长租公寓暴雷,不少年轻人不得不流离失所,构成疫情下的另一个经济写照,事态何去何从,值得关注。本文从数据角度出发,爬取了蛋壳公寓北京区域共6025条公寓数据,清洗数据,并进行可视化分析,为大家了解蛋壳公寓提供一个新的视角。
01 数据获取
def get_danke(href):
time.sleep(random.uniform(0, 1)) #设置延时,避免对服务器产生压力
response = requests.get(url=href, headers=headers)
if response.status_code == 200: #部分网页会跳转404,需要做判断
res = response.content.decode('utf-8')
div = etree.HTML(res)
items = div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]")
for item in items:
house_price=item.xpath("./div[3]/div[2]/div/span/div/text()")[0]
house_area=item.xpath("./div[4]/div[1]/div[1]/label/text()")[0].replace('建筑面积:约','').replace('㎡(以现场勘察为准)','')
house_id=item.xpath("./div[4]/div[1]/div[2]/label/text()")[0].replace('编号:','')
house_type=item.xpath("./div[4]/div[1]/div[3]/label/text()")[0].replace('\n','').replace(' ','').replace('户型:','')
house_floor=item.xpath("./div[4]/div[2]/div[3]/label/text()")[0].replace('楼层:','')
house_postion_1=item.xpath("./div[4]/div[2]/div[4]/label/div/a[1]/text()")[0]
house_postion_2=item.xpath("./div[4]/div[2]/div[4]/label/div/a[2]/text()")[0]
house_postion_3=item.xpath("./div[4]/div[2]/div[4]/label/div/a[3]/text()")[0]
house_subway=item.xpath("./div[4]/div[2]/div[5]/label/text()")[0]
else:
house_price = None
house_area = None
house_id = None
house_type = None
house_floor = None
house_postion_1 = None
house_postion_2 = None
house_postion_3 = None
house_subway = None
......
02 数据处理
1. 导入数据分析包
import pandas as pd
import numpy as np
from pathlib import Path
import re
2. 导入数据并合并
files = Path(r"D:\菜J学Python\数据分析\蛋壳公寓").glob("*.csv")
dfs = [pd.read_csv(f) for f in files]
df = pd.concat(dfs)
df.head()
3. 数据去重
df = df.drop_duplicates()
4. 查看数据
df.info() <class 'pandas.core.frame.DataFrame'>
Int64Index:6026 entries, 0 to 710
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 价格 6025 non-null object
1 面积 6025 non-null object
2 编号 6025 non-null object
3 户型 6025 non-null object
4 楼层 6025 non-null object
5 位置16025 non-null object
6 位置26025 non-null object
7 小区 6025 non-null object
8 地铁 6025 non-null object
dtypes: object(9)
memory usage: 470.8+ KB
5. 数据类型转换
#删除包含脏数据的行
jg = df['价格'] != "价格"
df = df.loc[jg,:]
#将价格字段转为数字类型
df["价格"] = df["价格"].astype("float64")
#将面积字段转为数字类型
df["面积"] = df["面积"].astype("float64")
#提取所在楼层
df = df[df['楼层'].notnull()]
df['所在楼层']=df['楼层'].apply(lambda x:x.split('/')[0])
df['所在楼层'] = df['所在楼层'].astype("int32")
#提取总楼层
df['总楼层']=df['楼层'].apply(lambda x:x.split('/')[1])
df['总楼层'] = df['总楼层'].str.replace("层","").astype("int32")6. 地铁字段清洗
def get_subway_num(row):
subway_num=row.count('号线')
return subway_num
def get_subway_distance(row):
distance=re.search(r'\d+(?=米)',row)
if distance==None:
return-1
else:
return distance.group()
df['地铁数']=df['地铁'].apply(get_subway_num)
df['距离地铁距离']=df['地铁'].apply(get_subway_distance)
df['距离地铁距离']=df['距离地铁距离'].astype("int32")7. 保存数据
df.to_excel(r"\菜J学Python\数据分析\蛋壳公寓.xlsx")
df.head()
03 数据可视化
1. 导入可视化相关包
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置加载的字体名
plt.rcParams['axes.unicode_minus'] = False# 解决保存图像是负号'-'显示为方块的问题
import jieba
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import stylecloud
from IPython.display import Image2. 各行政区公寓数量
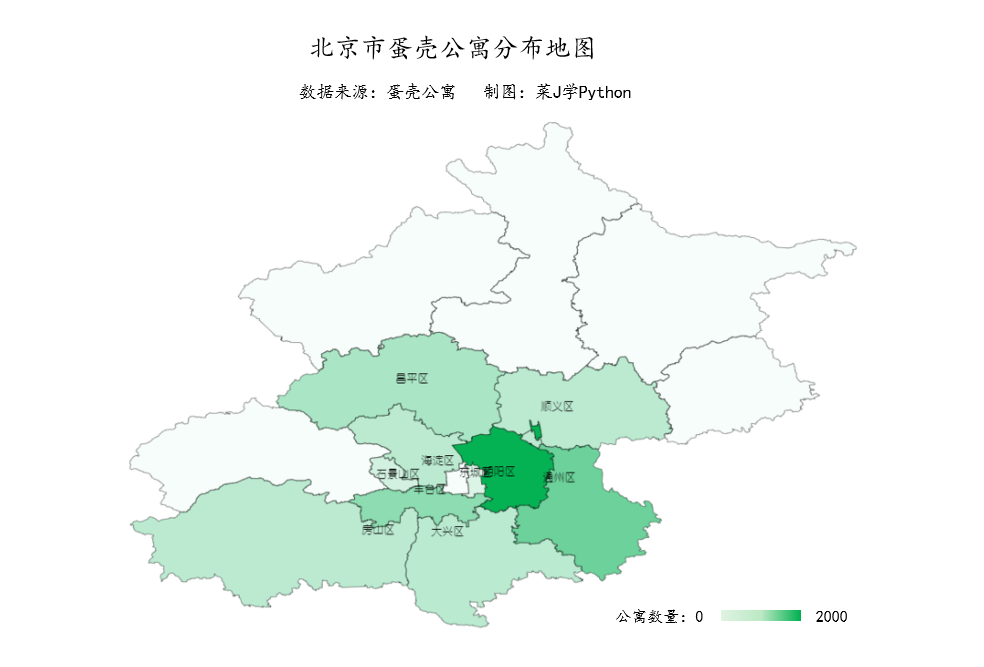
df7 = df["位置1"].value_counts()[:10]
df7 = df7.sort_values(ascending=True)
df7 = df7.tail(10)
print(df7.index.to_list())
print(df7.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(df7.index.to_list())
.add_yaxis("",df7.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="各行政区公寓数量",subtitle="数据来源:蛋壳公寓 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
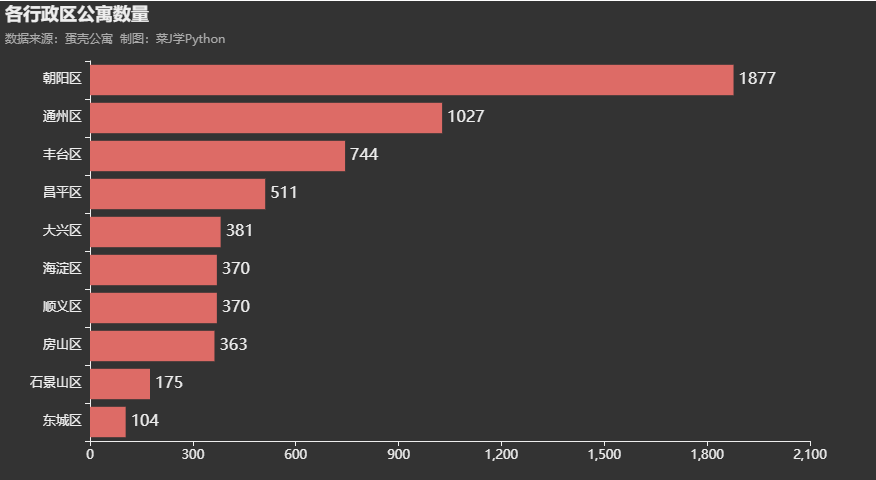
3. 小区公寓数量TOP10
df7 = df["小区"].value_counts()[:10]
df7 = df7.sort_values(ascending=True)
df7 = df7.tail(10)
print(df7.index.to_list())
print(df7.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK,width="1100px",height="600px"))
.add_xaxis(df7.index.to_list())
.add_yaxis("",df7.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="小区公寓数量TOP10",subtitle="数据来源:蛋壳公寓 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=11)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts={"rotate":30}), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
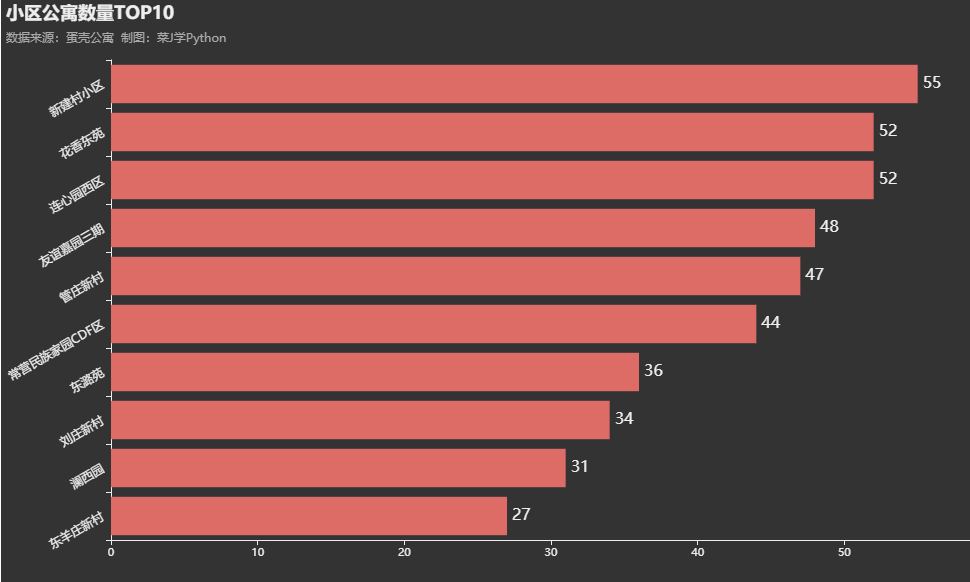
4. 蛋壳公寓租金分布
#租金分段
df['租金分段'] = pd.cut(df['价格'],[0,1000,2000,3000,4000,1000000],labels=['1000元以下','1000-2000元','2000-3000元','3000-4000元','4000元以上'],right=False)
df11 = df["租金分段"].value_counts()
df11 = df11.sort_values(ascending=False)
df11 = df11.round(2)
print(df11)
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add(
"",
[list(z) for z in zip(df11.index.to_list(),df11.to_list())],
radius=["20%", "80%"], #圆环的粗细和大小
rosetype='area'
)
.set_global_opts(legend_opts = opts.LegendOpts(is_show = False),title_opts=opts.TitleOpts(title="蛋壳公寓租金分布",subtitle="数据来源:蛋壳公寓\n制图:菜J学Python",pos_top="0.5%",pos_left = 'left'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=16))
)
c.render_notebook()
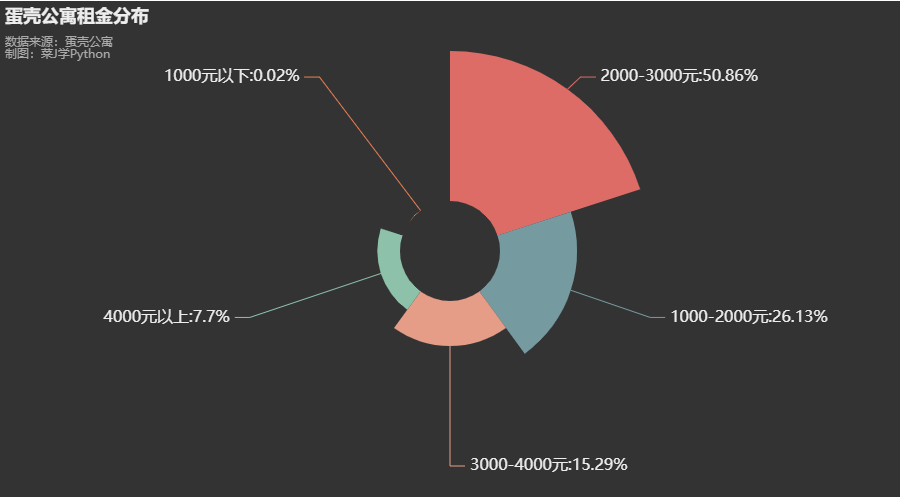
5. 各行政区租金分布
h = pd.pivot_table(df,index=['租金分段'],values=['价格'],
columns=['位置1'],aggfunc=['count'])
k = h.droplevel([0,1],axis=1) #删除指定的索引/列级别
c = (
Polar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_schema(angleaxis_opts=opts.AngleAxisOpts(data=k.columns.tolist(), type_="category"))
.add("1000以下",h.values.tolist()[0], type_="bar", stack="stack0")
.add("1000-2000元",h.values.tolist()[1], type_="bar", stack="stack0")
.add("2000-3000元", h.values.tolist()[2], type_="bar", stack="stack0")
.add("3000-4000元", h.values.tolist()[3], type_="bar", stack="stack0")
.add("4000元以上", h.values.tolist()[4], type_="bar", stack="stack0")
.set_global_opts(title_opts=opts.TitleOpts(title="各行政区租金情况",subtitle="数据来源:蛋壳公寓\n制图:菜J学Python"))
)
c.render_notebook()
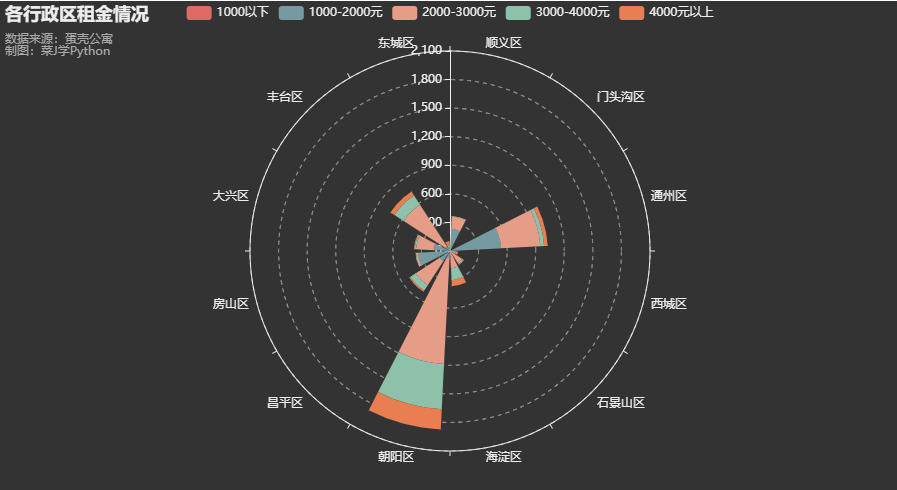
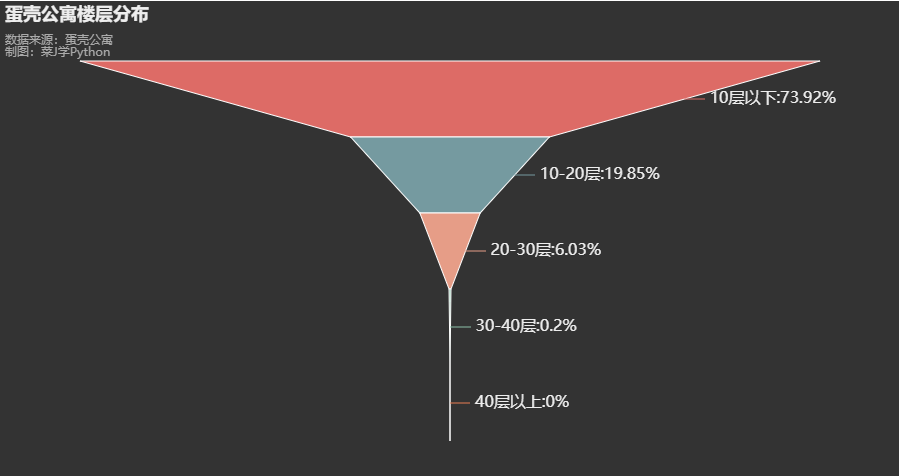
6. 蛋壳公寓楼层分布
# 漏斗图
df['楼层分段'] = pd.cut(df['所在楼层'],[0,10,20,30,40,1000000],labels=['10层以下','10-20层','20-30层','30-40层','40层以上'],right=False)
count = df['楼层分段'].value_counts() # pd.Series
print(count)
job = list(count.index)
job_count = count.values.tolist()
from pyecharts.charts import Funnel
c = (
Funnel(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add("", [list(i) for i in zip(job,job_count)])
.set_global_opts(
title_opts=opts.TitleOpts(title="蛋壳公寓楼层分布",subtitle="数据来源:蛋壳公寓\n制图:菜J学Python",pos_top="0.1%",pos_left = 'left'),legend_opts = opts.LegendOpts(is_show = False))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=16))
)
c.render_notebook()
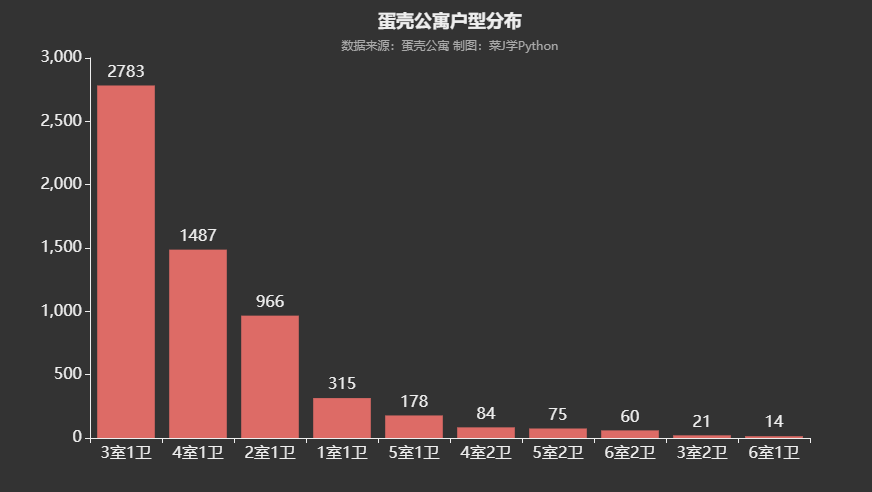
7. 蛋壳公寓户型分布
df2 = df.groupby('户型')['价格'].count()
df2 = df2.sort_values(ascending=False)[:10]
# print(df2)
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
bar.add_xaxis(df2.index.to_list())
bar.add_yaxis("",df2.to_list()) #X轴与y轴调换顺序
bar.set_global_opts(title_opts=opts.TitleOpts(title="蛋壳公寓户型分布",subtitle="数据来源:蛋壳公寓\t制图:菜J学Python",pos_top="2%",pos_left = 'center'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
bar.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='top'))
bar.render_notebook()
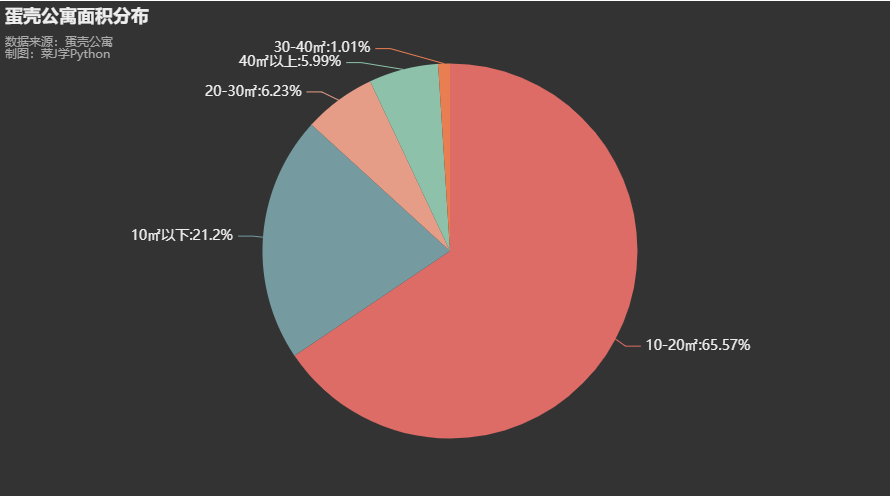
8. 蛋壳公寓面积分布
df['面积分段'] = pd.cut(df['面积'],[0,10,20,30,40,1000000],labels=['10㎡以下','10-20㎡','20-30㎡','30-40㎡','40㎡以上'],right=False)
df2 = df["面积分段"].astype("str").value_counts()
print(df2)
df2 = df2.sort_values(ascending=False)
regions = df2.index.to_list()
values = df2.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add("", list(zip(regions,values)))
.set_global_opts(legend_opts = opts.LegendOpts(is_show = False),title_opts=opts.TitleOpts(title="蛋壳公寓面积分布",subtitle="数据来源:蛋壳公寓\n制图:菜J学Python",pos_top="0.5%",pos_left = 'left'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=14))
)
c.render_notebook()
9. 蛋壳公寓商圈分布
# 绘制词云图
text1 = get_cut_words(content_series=df1['位置2'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=100,
collocations=False,
font_path=r'C:\WINDOWS\FONTS\MSYH.TTC',
icon_name='fas fa-home',
size=653,
palette='cartocolors.diverging.ArmyRose_2',
output_name='./1.png')
Image(filename='./1.png')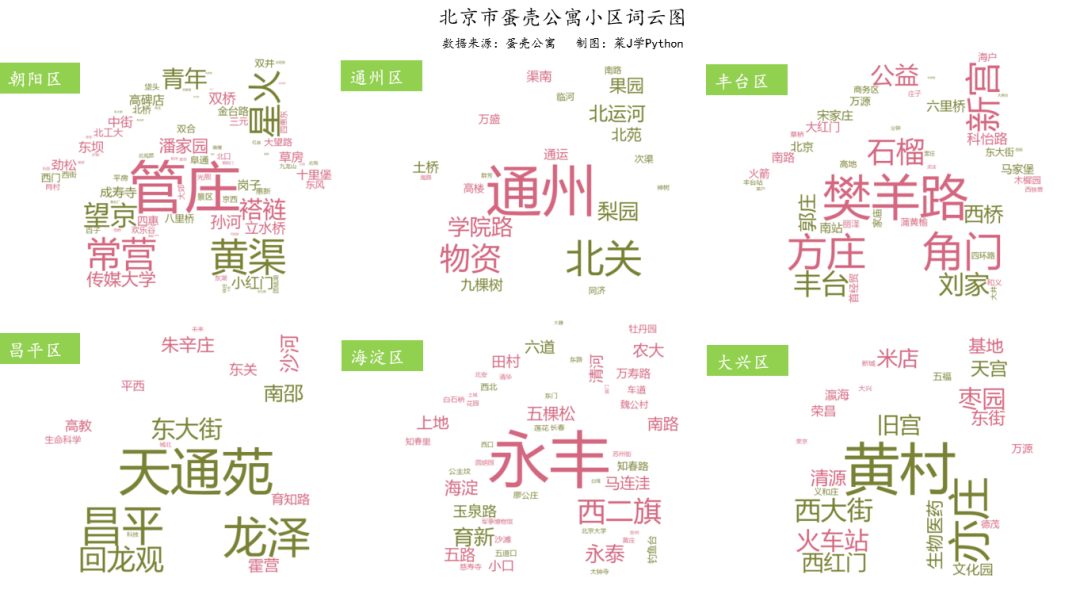
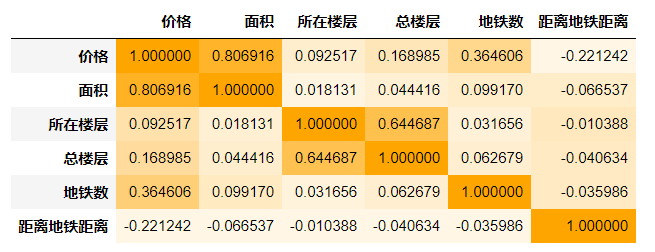
10. 相关性分析
color_map = sns.light_palette('orange', as_cmap=True) #light_palette调色板
df.corr().style.background_gradient(color_map)

干货直达👇
评论