
横空出世的可视化新工具,帮你更轻松地探索数据
探索性的数据分析是一种态度,是一种灵活性,是一种去寻找那些我们认为不存在的事物以及我们相信存在的事物的意愿。— John W Tukey
在数据科学领域,数据可视化的重要性和必要性并没有得到足够的重视。一张图片胜过千言万语,这句话适用于任何与数据相关的项目的生命周期中。然而很多时候,实现这些可视化的工具往往不够智能。事实上这意味着,尽管我们有数以百计的可视化库,但其中绝大多数都要求用户自己编写大量代码才能绘制简单图形。这会让人们的关注焦点转移到可视化的内部机制上,而不是真正重要的东西:数据内的关系上。
如果说现在有一种工具可以通过向用户推荐相关的可视化建议来简化数据探索的过程呢?一个名为 Lux💡的新库横空出世,它正是为解决这些问题而开发的。
https://github.com/lux-org/lux
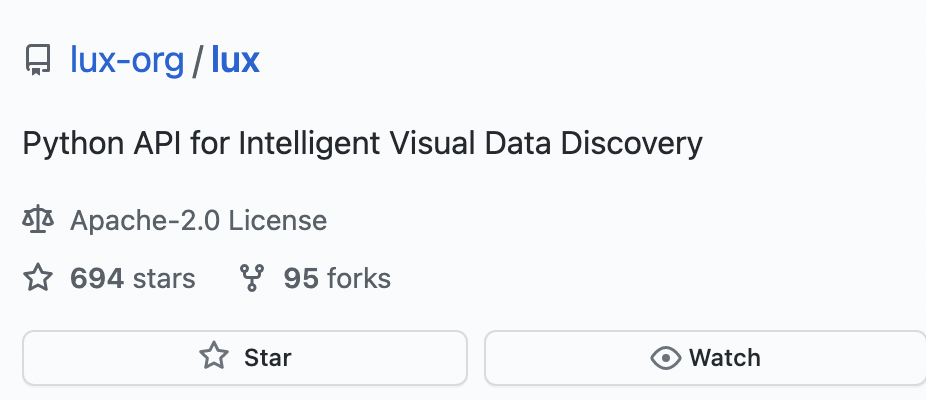
当前高效数据探索面临的挑战
如今,数据分析师可以使用多种工具进行数据探索。尽管交互式Jupyter笔记本允许人们在其之上迭代实验,还有一些强大的BI工具,如Power BI 和 Tableau,让普通人仅需单击遍可实现高级别的数据探索,可即便有这些功能强大的工具问世,阻碍数据探索流程的挑战仍然存在。当我们从在脑中分析问题转向在实际探寻可行的解决方案时尤其如此。让我们看一下数据分析师当前面临的三个主要的、可识别的障碍:
代码与交互工具之间的脱节
虽然需要编程的工具提供了灵活性,但是编程经验较少的人通常不会使用它们。另一方面,虽然点击交互的工具易于使用,但它们的灵活性有限且难以自定义。
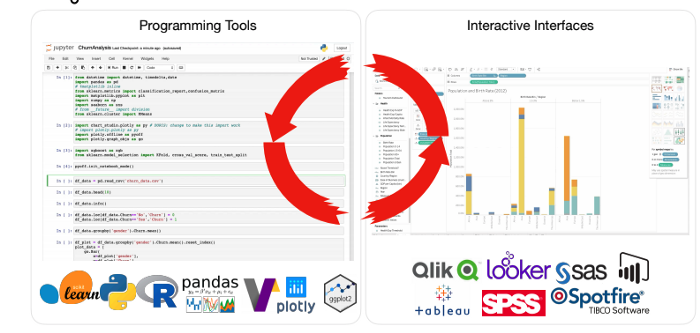
绘图需要大量代码和先决条件

其次,需要创建可视化时,我们首先需要考虑的是所有的规格应当如何被可视化。之后我们需要将这些规格的细节信息转换为代码。上图显示了在两个流行的python库(Matplotlib和Plotly)中,仅仅是为了输出一个柱状图就需要大量的的代码。这种情况同样会影响数据浏览,尤其是当用户对所要查找的内容只有模糊的概念时。
试错是一个即繁琐又令人窒息的过程
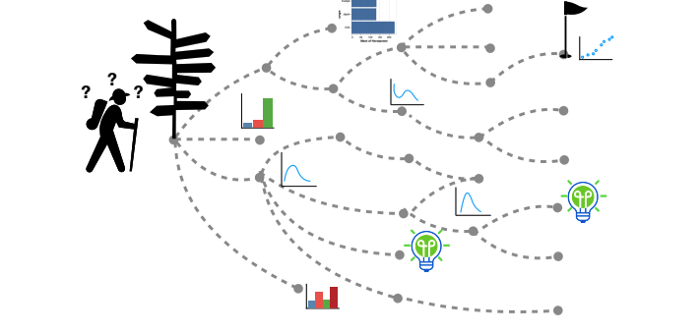
每次EDA(Exploratory data analysis)都需要不断的反复试验。用户必须先试验多种可视化效果,然后才能确定最终的可视化效果。分析人员有可能会因此错过数据集中的关键信息。另一个常见的问题是分析人员可能并不知道应该对数据执行哪些操作才能获得所需的关键信息,并且他们往往会迷失方向,无法分析出有效的结论。
在人们分析和思考他们的数据与实际如何处理数据才能获得有价值的信息之间存在明显的鸿沟。Lux正是解决这些可能的鸿沟一步。
Lux

Lux是一个旨在通过自动执行某些方面的数据探查,来帮助用户探索和发现他们数据中的有意义的见解的Python库。它试图弥合代码与交互式界面之间的鸿沟。Lux以一种表意语言的方式,使得在用户仅仅给出一个模糊的分析意图的情况下,它也能自动推断出其中未指定的细节并决定适当的可视化映射。
Lux的目标是,即使数据科学家对还没想好他们需要什么有用的信息,他们也可以更轻松地探索数据。
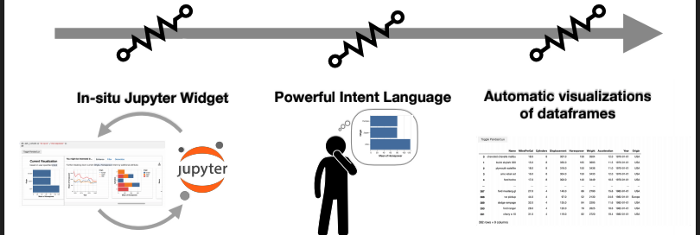
Lux将交互式可视化的功能直接集成进了Jupyter notebooks,以弥合代码与交互式界面之间的鸿沟。 Lux使用强大的表意语言,允许用户指定其在分析中感兴趣的部分以降低编程成本。 Lux会自动向用户提供数据的可视化建议。
现在,我们对Lux怎样参与用户探索数据时遇到的常见问题有了一个清晰的认识。现在让我们来看一个使用Lux库的示例。为了提供一个快速演示,我将使用一个简单的案例。在你对这个例子有了清晰地认识之后,便可以将其与你选择的数据集结合使用。
案例研究:分析Palmer Penguins🐧数据集

Palmer企鹅数据集目前已成为数据科学界的新宠,它是被过度使用的Iris数据集的直接替代品。该数据集包含344个企鹅的数据。数据由Kristen Gorman[1]博士和南极洲Palmer Station[2]站收集并提供。首先让我们安装并导入Lux库。你可以通过Binder[3]在Jupyter notbook中继续阅读本教程。
安装
pip install lux-api
# 激活Jupyter notebook扩展
jupyter nbextension install --py luxwidget
jupyter nbextension enable --py luxwidget
# 激活Jupyter lab拓展
jupyter labextension install @jupyter-widgets/jupyterlab-manager
jupyter labextension install luxwidget
有关如何将Lux与SQL引擎配合使用的更多详细信息,请阅读文档[4],该文档非常详实并且包含许多动手示例。
导入必要的库与数据集
一旦Lux库安装完毕,我们就可以导入数据集了。
import pandas as pd
import lux
df = pd.read_csv('penguins_size.csv')
df.head()
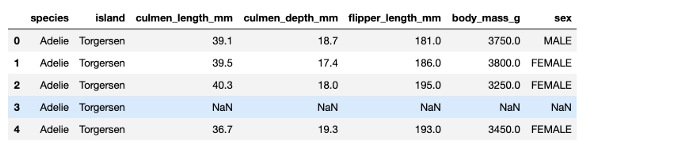
Lux的一个不错的点是它可以与Pandas框架一起使用并且无需对现有的格式进行任何修改。比如说,如果你想删除任何行或列,Lux的建议会根据更新的dataframe生成。Pandas中的删除列,导入CSV等优秀的功能也被保留。接下来让我们来概览一下数据集。
df.info()
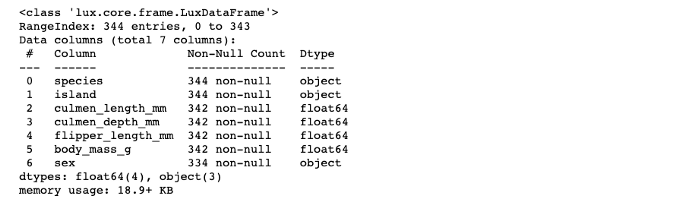
数据集里有些空值,让我们摆脱它们。
df = df.dropna()
现在我们的数据已被加载至内存,接下来看Lux如何为我们简化EDA的流程。
使用Lux进行EDA:支持可视化dataframe工作流

df
当dataframe被打印出来时,我们看到的是Pandas默认的表格格式。我们可以点击切换来获得由Lux自动生成的一组可视化建议。
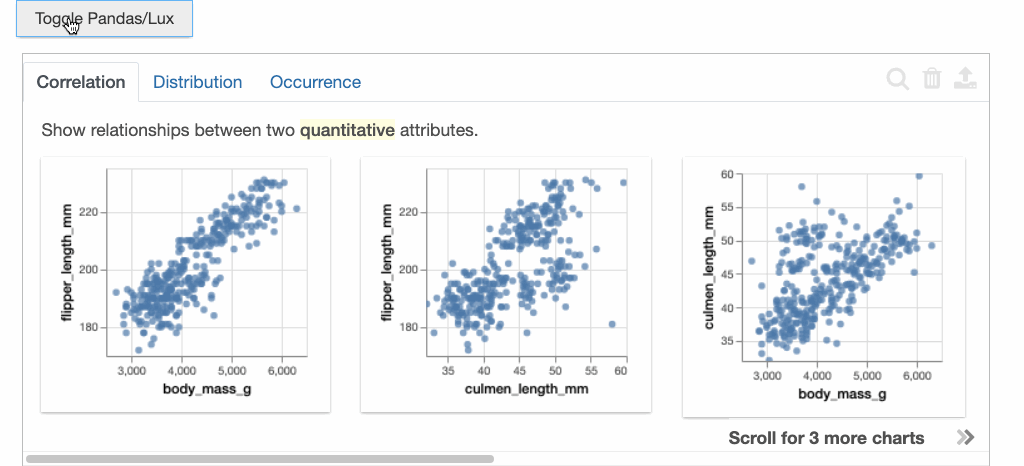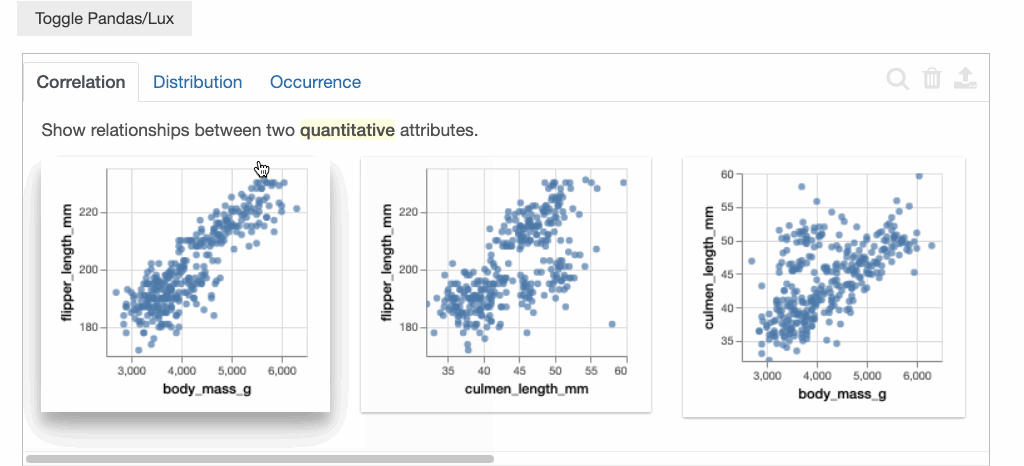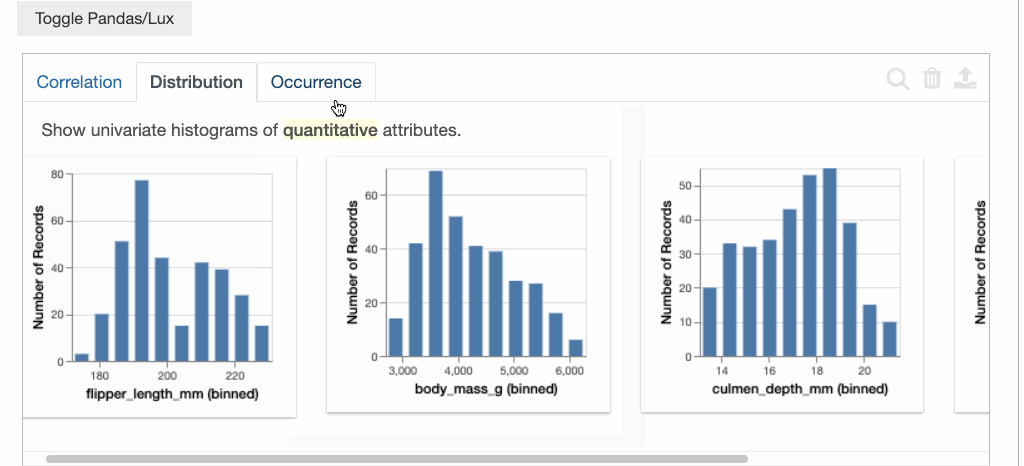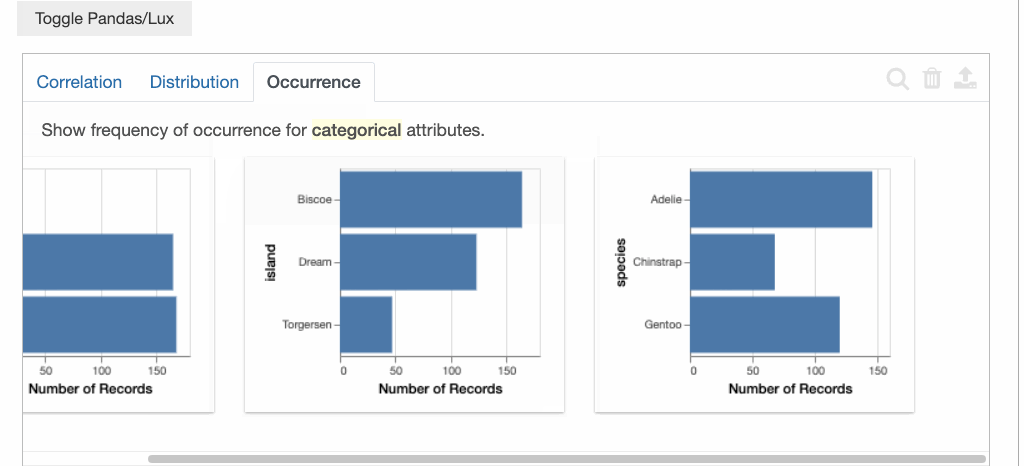
Lux中的建议组织在三个不同的选项卡中,分别表示用户可以在其探索过程中可以采取的下一步。
相关性选项卡: 显示定量属性之间的成对关系,按最高相关至最低相关排序。
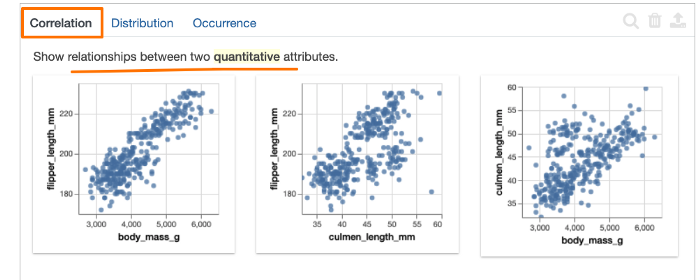
我们可以看到企鹅鳍的长度与体重呈正相关。企鹅嘴峰(culmen)的长度和深度也显现出一些有趣的模式,它们显然存在着某种负相关。具体来说,“嘴峰”就是鸟类的上脊。
分布选项卡: 显示一组单变量分布,按偏度从大到小排序。
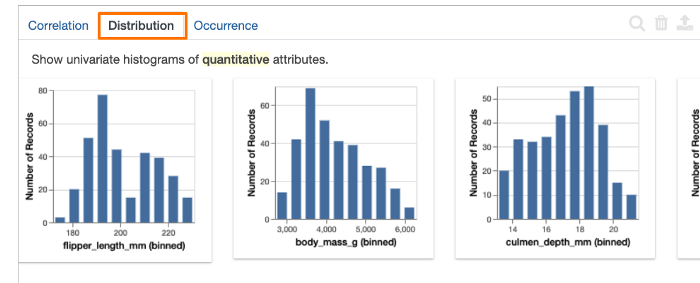
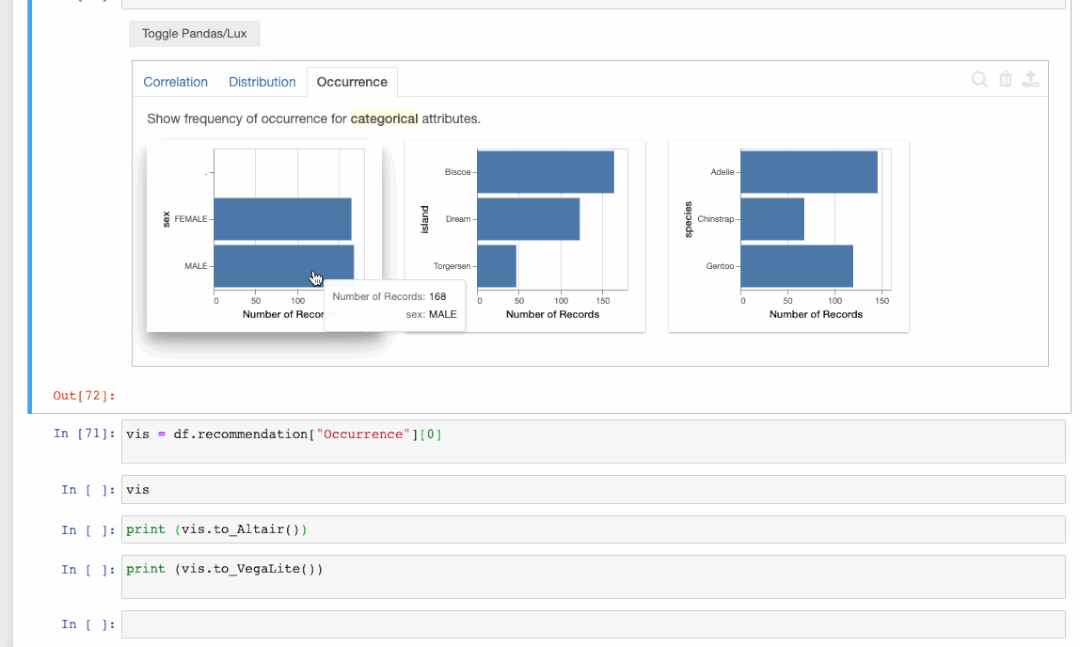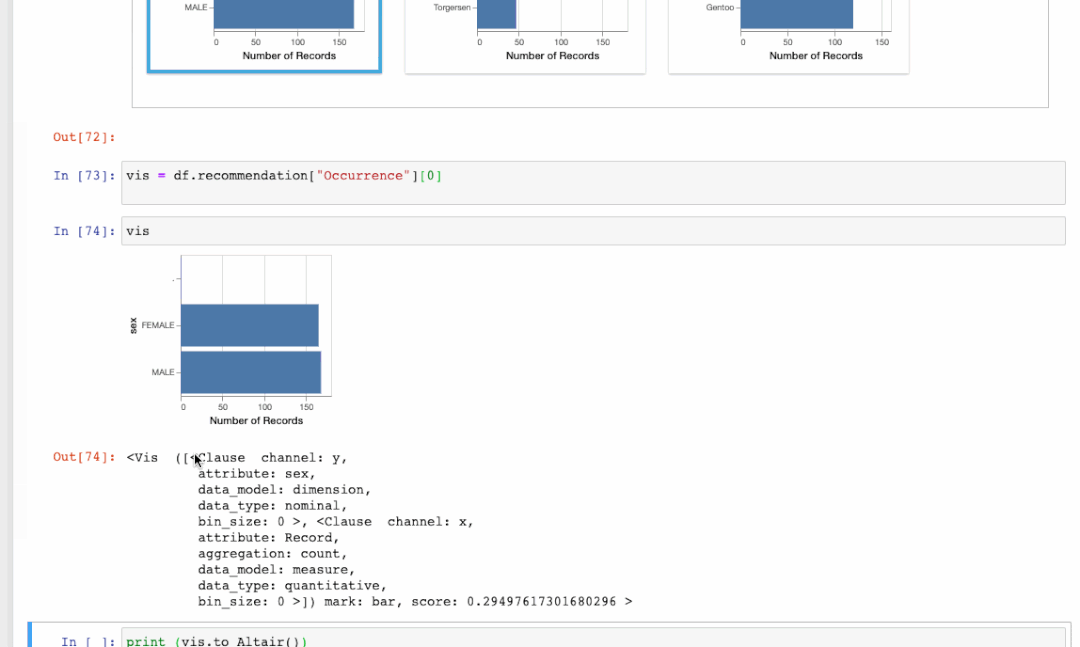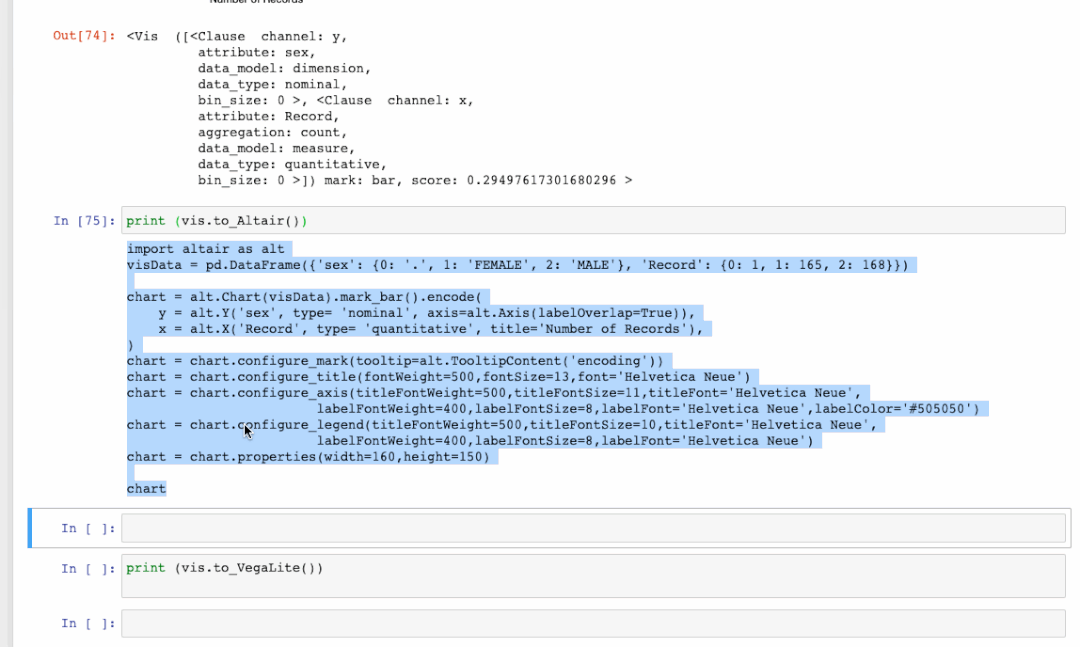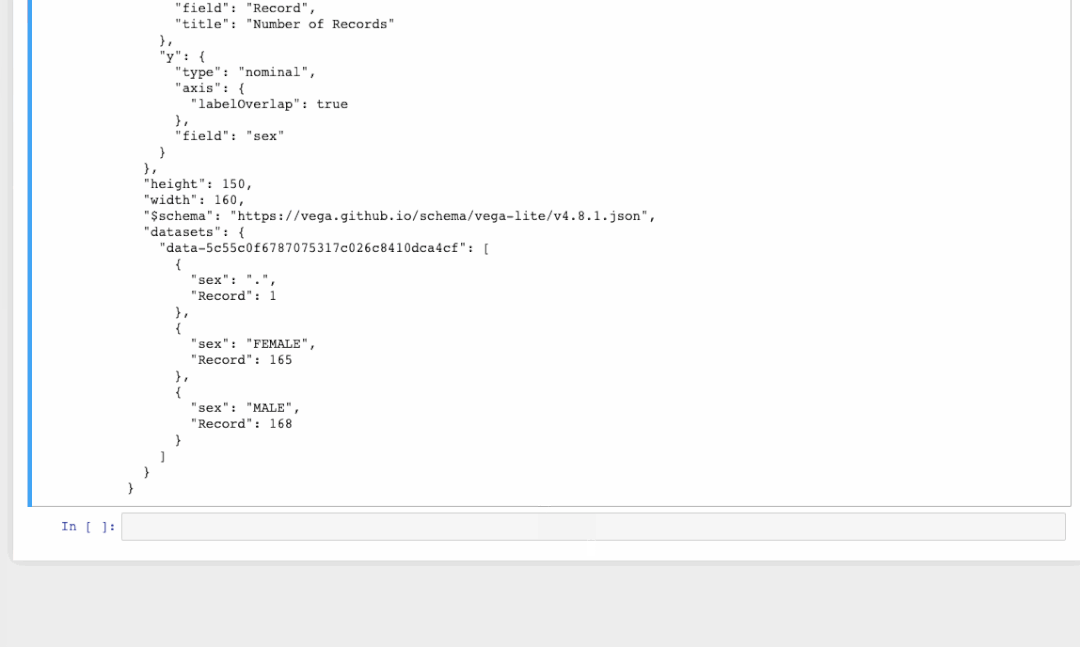
出现率选项卡: 显示了一组从数据集中生成的条形图。
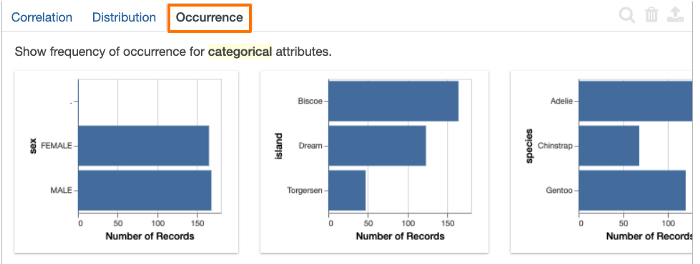
此选项卡展示了三种不同的企鹅 - Adelie,Chinstrap 和 Gentoo。还有三个不同的岛屿,分别是Torgersen,Biscoe 和 Dream。被包含在数据集中雄性和雌性出现率也能在图表中清楚的看到。
基于意图的建议
除了基本的推荐功能外,我们还可以指定分析意图。比方说,我们想找出嘴峰长度随企鹅物种变化的模式。我们可以在此处将意图设置为['culmen_length_mm','species']。再次打印数据框时,就可以看到推荐已经编程与我们指定的意图相关的内容。
df.intent = ['culmen_length_mm','species']
df
在下图的左侧,我们看到的是与所选属性相对应的Current Visualization。右侧则是Enhace:即在向当前选择中添加属性时会发生什么。还有Filter选项卡,允许在固定选择的变量的同时添加过滤器。
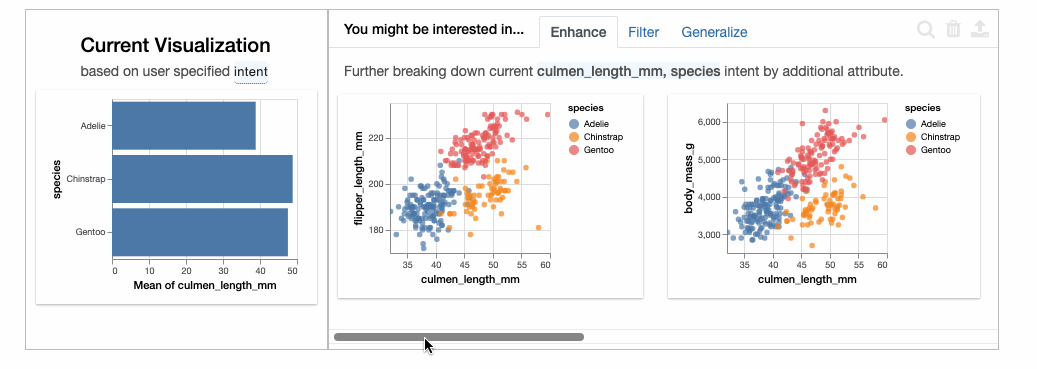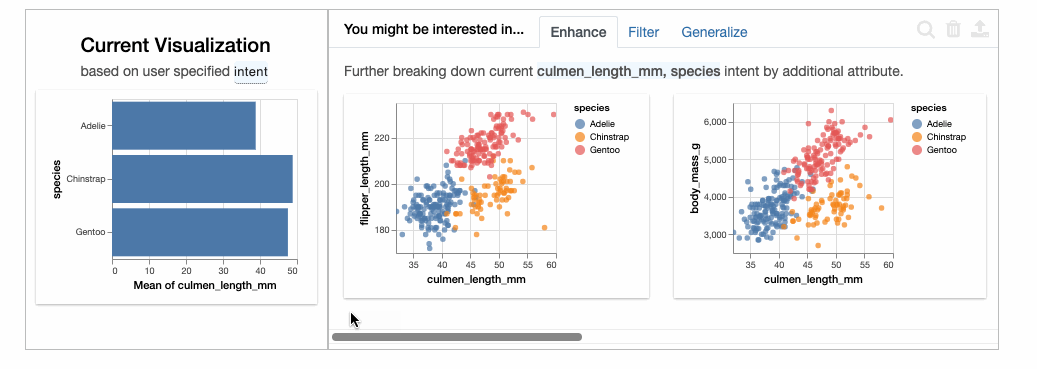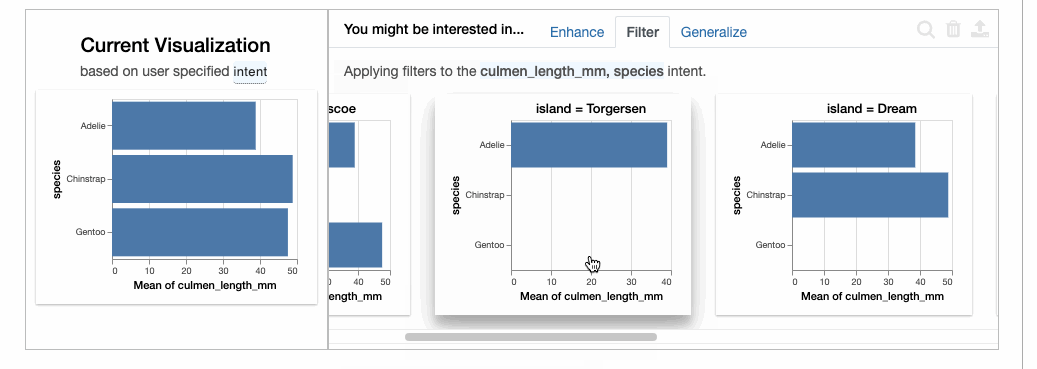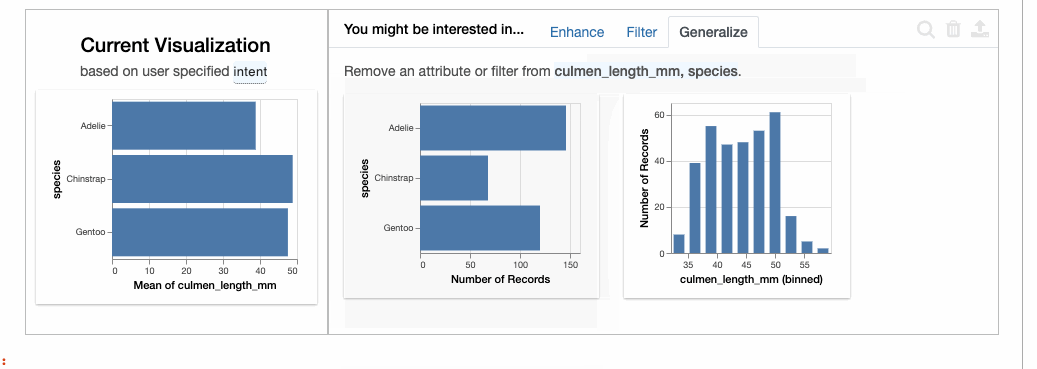
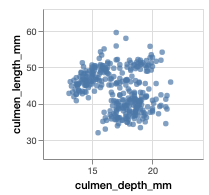
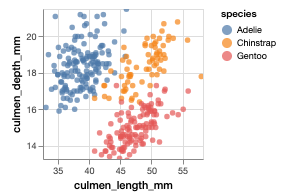
如果我们仔细观察物种内部的相关性,则会发现嘴峰长度和深度是正相关的,与之前的推测正相反。这是一个典型的[辛普森悖论](https://en.wikipedia.org/wiki/Simpson%27s_paradox[5])的例子。
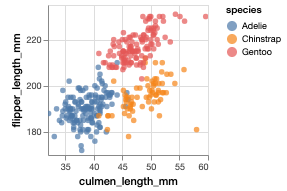
最后,通过比较鳍状肢的长度与嘴峰的长度,我们可以很清楚地将这三个物种分开。
用插件导出可视化结果
Lux使得导出和分享生成的可视化结果变得异常简单。这些可视化图表可以以如下方式被导出成静态的HTML文件:
df.save_as_html('file.html')
我们还可以通过recommendation属性获得为dataframe生成的建议集[6]。它的返回格式为字典,由推荐类别的名称构成字典的关键字。
df.recommendation

以代码的格式导出可视化结果
我们不仅可以将可视化导出为HTML,还可以将其导出为代码。下面的GIF显示了如何在发生率选项卡中查看第一个条形图的代码。之后我们可以将可视化结果导出成代码至Altair[7]中,以便进行进一步编辑或作为Vega-Lite[8]规范。你可以在这个文档中[9]找到更多详细信息。
相关资源和练习
上面的一系列演示只是一个简单的入门教程。Lux的Github[10]中包含许多资源以及有关如何使用Lux的交互式Binder notebook。那里将会是一个很好的起点。此外,这里还有还有详细的文档[11]。
lux-binder[12]
结论与下一步
在以上文章中,我们看到了如何通过使用Lux来完全转换Jupyter notebook中的数据分析工作流。Lux提供了更多的视觉丰富性以鼓励有意义的数据探索。Lux仍在积极开发中,其维护者希望从正在使用或可能对使用Lux感兴趣的用户得到更多反馈。如果您有兴趣为这个库做贡献,请填写以下表格。这将帮助团队了解他们如何为您改进工具。
参考资料
Kristen Gorman: https://www.uaf.edu/cfos/people/faculty/detail/kristen-gorman.php
[2]Palmer Station: https://pal.lternet.edu/
[3]Binder: https://mybinder.org/v2/gh/lux-org/lux-binder/master?urlpath=tree/demo/penguin_demo.ipynb
[4]文档: https://lux-api.readthedocs.io/en/latest/source/getting_started/installation.html
[5]辛普森悖论: https://en.wikipedia.org/wiki/Simpson's_paradox
[6]建议集: https://lux-api.readthedocs.io/en/latest/source/guide/export.html
[7]Altair: https://altair-viz.github.io/
[8]Vega-Lite: https://vega.github.io/vega-lite/
[9]这个文档中: https://lux-api.readthedocs.io/en/latest/source/guide/export.html
[10]Lux的Github: https://github.com/lux-org/lux
[11]文档: https://lux-api.readthedocs.io/en/latest/source/getting_started/installation.html
[12]lux-binder: https://github.com/lux-org/lux-binder
- EOF -
更多优秀开源项目(点击下方图片可跳转)



开源前哨
日常分享热门、有趣和实用的开源项目。参与维护10万+star 的开源技术资源库,包括:Python, Java, C/C++, Go, JS, CSS, Node.js, PHP, .NET 等
关注后获取
回复 资源 获取 10万+ star 开源资源
分享、点赞和在看
支持我们分享更多优秀开源项目,谢谢!