
LeetCode刷题实战79:单词搜索
算法的重要性,我就不多说了吧,想去大厂,就必须要经过基础知识和业务逻辑面试+算法面试。所以,为了提高大家的算法能力,这个公众号后续每天带大家做一道算法题,题目就从LeetCode上面选 !
今天和大家聊的问题叫做 单词搜索,我们先来看题面:
https://leetcode-cn.com/problems/word-search/
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cells, where "adjacent" cells are horizontally or vertically neighboring. The same letter cell may not be used more than once.
题意
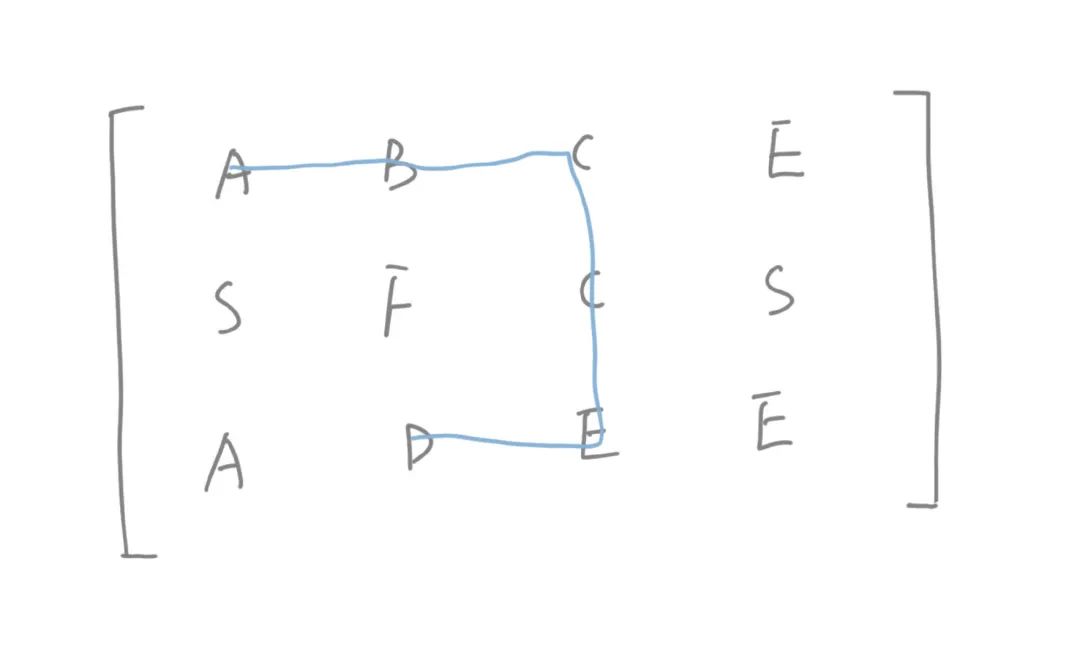
board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
给定 word = "ABCCED", 返回 true
给定 word = "SEE", 返回 true
给定 word = "ABCB", 返回 false
解题
题解
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
fx = [[0, 1], [0, -1], [1, 0], [-1, 0]]
def dfs(x, y, l):
if l == len(word):
return True
for i in range(4):
nx = x + fx[i][0]
ny = y + fx[i][1]
# 出界或者是走过的时候,跳过
if nx < 0 or nx == n or ny < 0 or ny == m or visited[nx][ny]:
continue
if board[nx][ny] == word[l]:
visited[nx][ny] = 1
if dfs(nx, ny, l+1):
return True
visited[nx][ny] = 0
return False
n = len(board)
if n == 0:
return False
m = len(board[0])
if m == 0:
return False
visited = [[0 for i in range(m)] for j in range(n)]
for i in range(n):
for j in range(m):
# 找到合法的起点
if board[i][j] == word[0]:
visited = [[0 for _ in range(m)] for _ in range(n)]
visited[i][j] = 1
if dfs(i, j, 1):
return True
return False
总结
上期推文: