
全网最详尽的负载均衡原理图解


负载均衡由来
在业务初期,我们一般会先使用单台服务器对外提供服务。随着业务流量越来越大,单台服务器无论如何优化,无论采用多好的硬件,总会有性能天花板,当单服务器的性能无法满足业务需求时,就需要把多台服务器组成集群系统提高整体的处理性能。
基于上述需求,我们要使用统一的流量入口来对外提供服务,本质上就是需要一个流量调度器,通过均衡的算法,将用户大量的请求流量均衡地分发到集群中不同的服务器上。这其实就是我们今天要说的负载均衡。
使用负载均衡可以给我们带来的几个好处:
提高了系统的整体性能;
提高了系统的扩展性;
提高了系统的可用性;
负载均衡类型
广义上的负载均衡器大概可以分为 3 类,包括:DNS 方式实现负载均衡、硬件负载均衡、软件负载均衡。
(一)DNS 实现负载均衡
DNS 实现负载均衡是最基础简单的方式。一个域名通过 DNS 解析到多个 IP,每个 IP 对应不同的服务器实例,这样就完成了流量的调度,虽然没有使用常规的负载均衡器,但实现了简单的负载均衡功能。
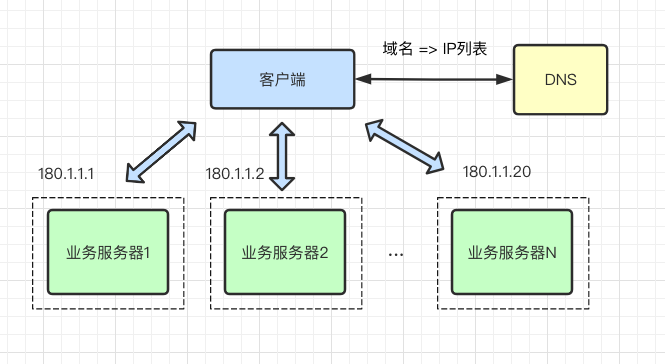
通过 DNS 实现负载均衡的方式,最大的优点就是实现简单,成本低,无需自己开发或维护负载均衡设备,不过存在一些缺点:
服务器故障切换延迟大,服务器升级不方便。我们知道 DNS 与用户之间是层层的缓存,即便是在故障发生时及时通过 DNS 修改或摘除故障服务器,但中间经过运营商的 DNS 缓存,且缓存很有可能不遵循 TTL 规则,导致 DNS 生效时间变得非常缓慢,有时候一天后还会有些许的请求流量。
流量调度不均衡,粒度太粗。DNS 调度的均衡性,受地区运营商 LocalDNS 返回 IP 列表的策略有关系,有的运营商并不会轮询返回多个不同的 IP 地址。另外,某个运营商 LocalDNS 背后服务了多少用户,这也会构成流量调度不均的重要因素。
流量分配策略太简单,支持的算法太少。DNS 一般只支持
rr的轮询方式,流量分配策略比较简单,不支持权重、Hash 等调度算法。DNS 支持的 IP 列表有限制。我们知道 DNS 使用 UDP 报文进行信息传递,每个 UDP 报文大小受链路的 MTU 限制,所以报文中存储的 IP 地址数量也是非常有限的,阿里 DNS 系统针对同一个域名支持配置 10 个不同的 IP 地址。
实际上生产环境中很少使用这种方式来实现负载均衡,毕竟缺点很明显。文中之所以描述 DNS 负载均衡方式,是为了能够更清楚地解释负载均衡的概念。
像 BAT 体量的公司一般会利用 DNS 来实现地理级别的全局负载均衡,实现就近访问,提高访问速度,这种方式一般是入口流量的基础负载均衡,下层会有更专业的负载均衡设备实现的负载架构。
(二)硬件负载均衡
硬件负载均衡是通过专门的硬件设备来实现负载均衡功能,是专用的负载均衡设备。目前业界典型的硬件负载均衡设备有两款:F5 和 A10。
这类设备性能强劲、功能强大,但价格非常昂贵,一般只有土豪公司才会使用此类设备,中小公司一般负担不起,业务量没那么大,用这些设备也是挺浪费的。
硬件负载均衡的优点:
功能强大:全面支持各层级的负载均衡,支持全面的负载均衡算法。
性能强大:性能远超常见的软件负载均衡器。
稳定性高:商用硬件负载均衡,经过了良好的严格测试,经过大规模使用,稳定性高。
安全防护:还具备防火墙、防 DDoS 攻击等安全功能,以及支持 SNAT 功能。
硬件负载均衡的缺点也很明显:
价格贵;
扩展性差,无法进行扩展和定制;
调试和维护比较麻烦,需要专业人员;
(三)软件负载均衡
软件负载均衡,可以在普通的服务器上运行负载均衡软件,实现负载均衡功能。目前常见的有 Nginx、HAproxy、LVS。其中的区别:
Nginx:七层负载均衡,支持 HTTP、E-mail 协议,同时也支持 4 层负载均衡;HAproxy:支持七层规则的,性能也很不错。OpenStack 默认使用的负载均衡软件就是 HAproxy;LVS:运行在内核态,性能是软件负载均衡中最高的,严格来说工作在三层,所以更通用一些,适用各种应用服务。
软件负载均衡的优点:
易操作:无论是部署还是维护都相对比较简单;
便宜:只需要服务器的成本,软件是免费的;
灵活:4 层和 7 层负载均衡可以根据业务特点进行选择,方便进行扩展和定制功能。
负载均衡LVS
软件负载均衡主要包括:Nginx、HAproxy 和 LVS,三款软件都比较常用。四层负载均衡基本上都会使用 LVS,据了解 BAT 等大厂都是 LVS 重度使用者,就是因为 LVS 非常出色的性能,能为公司节省巨大的成本。
LVS,全称 Linux Virtual Server 是由国人章文嵩博士发起的一个开源的项目,在社区具有很大的热度,是一个基于四层、具有强大性能的反向代理服务器。
它现在是标准内核的一部分,它具备可靠性、高性能、可扩展性和可操作性的特点,从而以低廉的成本实现最优的性能。
Netfilter基础原理
LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡功能,所以要学习 LVS 之前必须要先简单了解 netfilter 基本工作原理。netfilter 其实很复杂,平时我们说的 Linux 防火墙就是 netfilter,不过我们平时操作的都是 iptables,iptables 只是用户空间编写和传递规则的工具而已,真正工作的是 netfilter。通过下图可以简单了解下 netfilter 的工作机制:
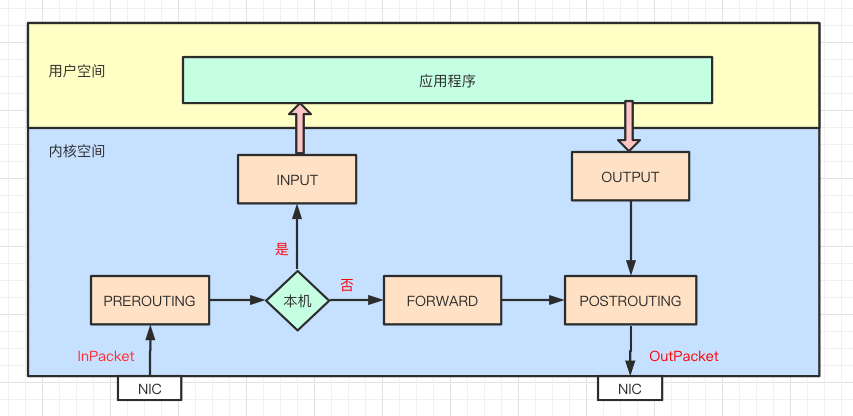
netfilter 是内核态的 Linux 防火墙机制,作为一个通用、抽象的框架,提供了一整套的 hook 函数管理机制,提供诸如数据包过滤、网络地址转换、基于协议类型的连接跟踪的功能。
通俗点讲,就是 netfilter 提供一种机制,可以在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关的操作。netfilter 总共设置了 5 个点,包括:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
PREROUTING:刚刚进入网络层,还未进行路由查找的包,通过此处INPUT:通过路由查找,确定发往本机的包,通过此处FORWARD:经路由查找后,要转发的包,在POST_ROUTING之前OUTPUT:从本机进程刚发出的包,通过此处POSTROUTING:进入网络层已经经过路由查找,确定转发,将要离开本设备的包,通过此处
当一个数据包进入网卡,经过链路层之后进入网络层就会到达 PREROUTING,接着根据目标 IP 地址进行路由查找,如果目标 IP 是本机,数据包继续传递到 INPUT 上,经过协议栈后根据端口将数据送到相应的应用程序。
应用程序处理请求后将响应数据包发送到 OUTPUT 上,最终通过 POSTROUTING 后发送出网卡。
如果目标 IP 不是本机,而且服务器开启了 forward 参数,就会将数据包递送给 FORWARD 上,最后通过 POSTROUTING 后发送出网卡。
LVS基础原理
LVS 是基于 netfilter 框架,主要工作于 INPUT 链上,在 INPUT 上注册 ip_vs_in HOOK 函数,进行 IPVS 主流程,大概原理如图所示:
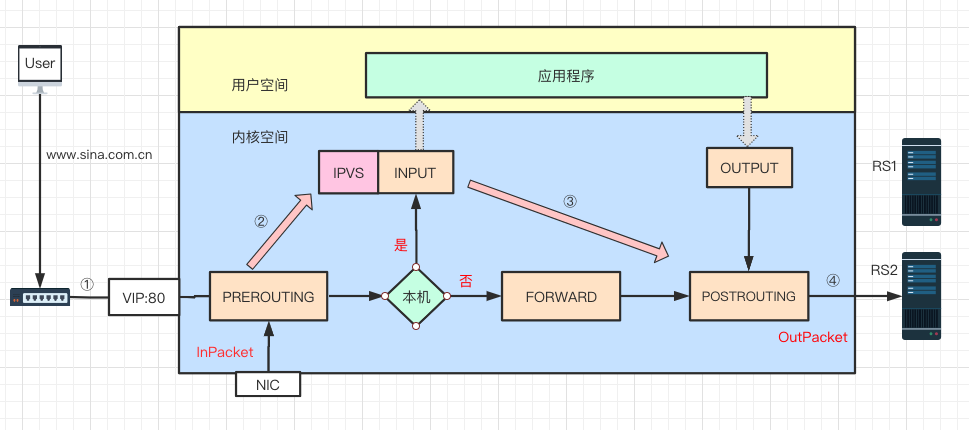
当用户访问 www.sina.com.cn 时,用户数据通过层层网络,最后通过交换机进入 LVS 服务器网卡,并进入内核网络层。
进入 PREROUTING 后经过路由查找,确定访问的目的 VIP 是本机 IP 地址,所以数据包进入到 INPUT 链上
LVS 是工作在 INPUT 链上,会根据访问的
IP:Port判断请求是否是 LVS 服务,如果是则进行 LVS 主流程,强行修改数据包的相关数据,并将数据包发往 POSTROUTING 链上。POSTROUTING 上收到数据包后,根据目标 IP 地址(后端真实服务器),通过路由选路,将数据包最终发往后端的服务器上。
开源 LVS 版本有 3 种工作模式,每种模式工作原理都不同,每种模式都有自己的优缺点和不同的应用场景,包括以下三种模式:
DR模式NAT模式Tunnel模式
这里必须要提另外一种模式是 FullNAT,这个模式在开源版本中是模式没有的。这个模式最早起源于百度,后来又在阿里发扬光大,由阿里团队开源,代码地址如下:
https://github.com/alibaba/lvs
LVS 官网也有相关下载地址,不过并没有合进到内核主线版本。
后面会有专门章节详细介绍 FullNAT 模式。下边分别就 DR、NAT、Tunnel 模式分别详细介绍原理。
DR 模式实现原理
LVS 基本原理图中描述的比较简单,表述的是比较通用流程。下边会针对 DR 模式的具体实现原理,详细的阐述 DR 模式是如何工作的。
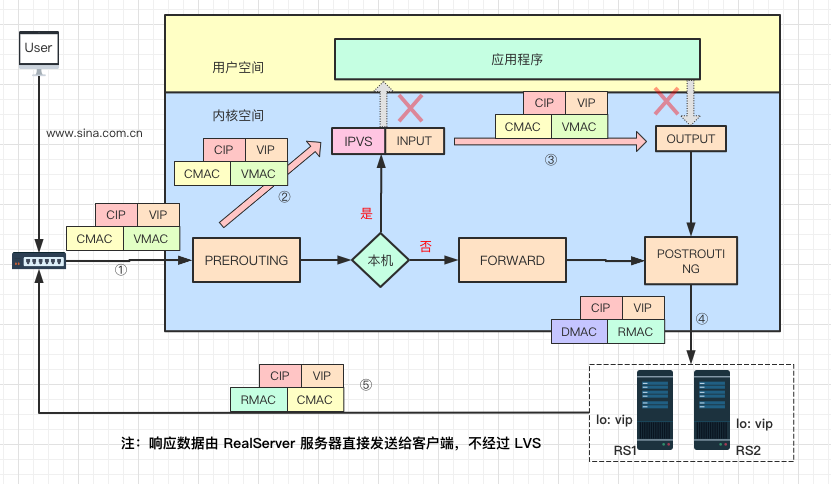
其实 DR 是最常用的工作模式,因为它的强大的性能。下边试图以某个请求和响应数据流的过程来描述 DR 模式的工作原理
(一)实现原理过程
① 当客户端请求 www.sina.com.cn 主页,请求数据包穿过网络到达 Sina 的 LVS 服务器网卡:源 IP 是客户端 IP 地址 CIP,目的 IP 是新浪对外的服务器 IP 地址,也就是 VIP;此时源 MAC 地址是 CMAC,其实是 LVS 连接的路由器的 MAC 地址(为了容易理解记为 CMAC),目标 MAC 地址是 VIP 对应的 MAC,记为 VMAC。
② 数据包经过链路层到达 PREROUTING 位置(刚进入网络层),查找路由发现目的 IP 是 LVS 的 VIP,就会递送到 INPUT 链上,此时数据包 MAC、IP、Port 都没有修改。
③ 数据包到达 INPUT 链,INPUT 是 LVS 主要工作的位置。此时 LVS 会根据目的 IP 和 Port 来确认是否是 LVS 定义的服务,如果是定义过的 VIP 服务,就会根据配置信息,从真实服务器列表 中选择一个作为 RS1,然后以 RS1 作为目标查找 Out 方向的路由,确定一下跳信息以及数据包要通过哪个网卡发出。最后将数据包投递到 OUTPUT 链上。
④ 数据包通过 POSTROUTING 链后,从网络层转到链路层,将目的 MAC 地址修改为 RealServer 服务器 MAC 地址,记为 RMAC;而源 MAC 地址修改为 LVS 与 RS 同网段的 selfIP 对应的 MAC 地址,记为 DMAC。此时,数据包通过交换机转发给了 RealServer 服务器(注:为了简单图中没有画交换机)。
⑤ 请求数据包到达后端真实服务器后,链路层检查目的 MAC 是自己网卡地址。到了网络层,查找路由,目的 IP 是 VIP(lo 上配置了 VIP),判定是本地主机的数据包,经过协议栈拷贝至应用程序(比如 nginx 服务器),nginx 响应请求后,产生响应数据包。
然后以 CIP 查找出方向的路由,确定下一跳信息和发送网卡设备信息。此时数据包源、目的 IP 分别是 VIP、CIP,而源 MAC 地址是 RS1 的 RMAC,目的 MAC 是下一跳(路由器)的 MAC 地址,记为 CMAC(为了容易理解,记为 CMAC)。然后数据包通过 RS 相连的路由器转发给真正客户端,完成了请求响应的全过程。
从整个过程可以看出,DR 模式 LVS 逻辑比较简单,数据包通过直接路由方式转发给后端服务器,而且响应数据包是由 RS 服务器直接发送给客户端,不经过 LVS。
我们知道通常请求数据包会比较小,响应报文较大,经过 LVS 的数据包基本上都是小包,所以这也是 LVS 的 DR 模式性能强大的主要原因。
(二)优缺点和使用场景
DR 模式的优点
响应数据不经过 lvs,性能高
对数据包修改小,信息保存完整(携带客户端源 IP)
DR 模式的缺点
lvs 与 rs 必须在同一个物理网络(不支持跨机房)
服务器上必须配置 lo 和其它内核参数
不支持端口映射
DR 模式的使用场景
如果对性能要求非常高,可以首选 DR 模式,而且可以透传客户端源 IP 地址。
NAT 模式实现原理
lvs 的第 2 种工作模式是 NAT 模式,下图详细介绍了数据包从客户端进入 lvs 后转发到 rs,后经 rs 再次将响应数据转发给 lvs,由 lvs 将数据包回复给客户端的整个过程。
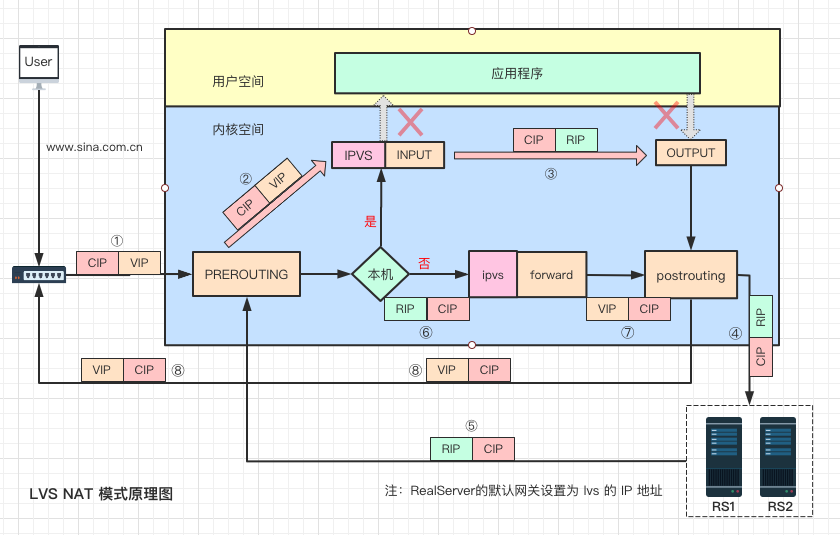
(一)实现原理与过程
① 用户请求数据包经过层层网络,到达 lvs 网卡,此时数据包源 IP 是 CIP,目的 IP 是 VIP。
② 经过网卡进入网络层 prerouting 位置,根据目的 IP 查找路由,确认是本机 IP,将数据包转发到 INPUT 上,此时源、目的 IP 都未发生变化。
③ 到达 lvs 后,通过目的 IP 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 RS 作为后端服务器,将数据包目的 IP 修改为 RIP,并以 RIP 为目的 IP 查找路由信息,确定下一跳和出口信息,将数据包转发至 output 上。
④ 修改后的数据包经过 postrouting 和链路层处理后,到达 RS 服务器,此时的数据包源 IP 是 CIP,目的 IP 是 RIP。
⑤ 到达 RS 服务器的数据包经过链路层和网络层检查后,被送往用户空间 nginx 程序。nginx 程序处理完毕,发送响应数据包,由于 RS 上默认网关配置为 lvs 设备 IP,所以 nginx 服务器会将数据包转发至下一跳,也就是 lvs 服务器。此时数据包源 IP 是 RIP,目的 IP 是 CIP。
⑥ lvs 服务器收到 RS 响应数据包后,根据路由查找,发现目的 IP 不是本机 IP,且 lvs 服务器开启了转发模式,所以将数据包转发给 forward 链,此时数据包未作修改。
⑦ lvs 收到响应数据包后,根据目的 IP 和目的 port 查找服务和连接表,将源 IP 改为 VIP,通过路由查找,确定下一跳和出口信息,将数据包发送至网关,经过复杂的网络到达用户客户端,最终完成了一次请求和响应的交互。
NAT 模式双向流量都经过 LVS,因此 NAT 模式性能会存在一定的瓶颈。不过与其它模式区别的是,NAT 支持端口映射,且支持 windows 操作系统。
(二)优点、缺点与使用场景
NAT 模式优点
能够支持 windows 操作系统
支持端口映射。如果 rs 端口与 vport 不一致,lvs 除了修改目的 IP,也会修改 dport 以支持端口映射。
NAT 模式缺点
后端 RS 需要配置网关
双向流量对 lvs 负载压力比较大
NAT 模式的使用场景
如果你是 windows 系统,使用 lvs 的话,则必须选择 NAT 模式了。
Tunnel 模式实现原理
Tunnel 模式在国内使用的比较少,不过据说腾讯使用了大量的 Tunnel 模式。它也是一种单臂的模式,只有请求数据会经过 lvs,响应数据直接从后端服务器发送给客户端,性能也很强大,同时支持跨机房。下边继续看图分析原理。
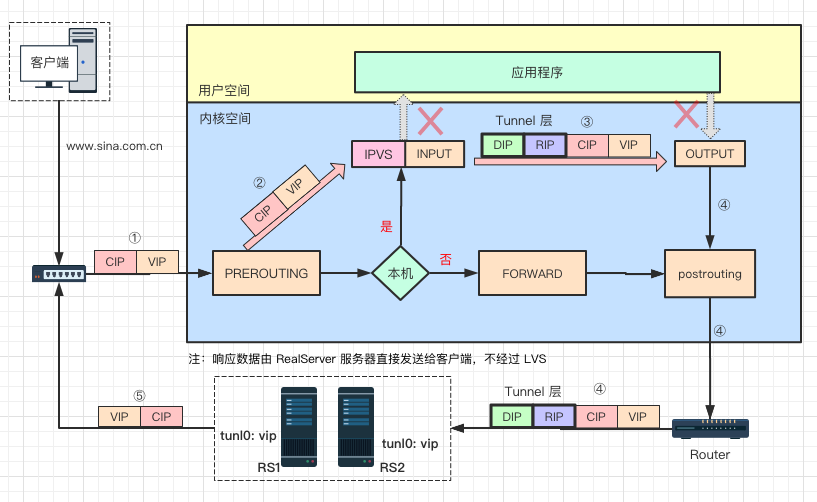
(一)实现原理与过程
① 用户请求数据包经过多层网络,到达 lvs 网卡,此时数据包源 IP 是 cip,目的 ip 是 vip。
② 经过网卡进入网络层 prerouting 位置,根据目的 ip 查找路由,确认是本机 ip,将数据包转发到 input 链上,到达 lvs,此时源、目的 ip 都未发生变化。
③ 到达 lvs 后,通过目的 ip 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 rs 作为后端服务器,以 rip 为目的 ip 查找路由信息,确定下一跳、dev 等信息,然后 IP 头部前边额外增加了一个 IP 头(以 dip 为源,rip 为目的 ip),将数据包转发至 output 上。
④ 数据包根据路由信息经最终经过 lvs 网卡,发送至路由器网关,通过网络到达后端服务器。
⑤ 后端服务器收到数据包后,ipip 模块将 Tunnel 头部卸载,正常看到的源 ip 是 cip,目的 ip 是 vip,由于在 tunl0 上配置 vip,路由查找后判定为本机 ip,送往应用程序。应用程序 nginx 正常响应数据后以 vip 为源 ip,cip 为目的 ip 数据包发送出网卡,最终到达客户端。
Tunnel 模式具备 DR 模式的高性能,又支持跨机房访问,听起来比较完美。不过国内运营商有一定特色性,比如 RS 的响应数据包的源 IP 为 VIP,VIP 与后端服务器有可能存在跨运营商的情况,很有可能被运营商的策略封掉,Tunnel 在生产环境确实没有使用过,在国内推行 Tunnel 可能会有一定的难度吧。
(二)优点、缺点与使用场景
Tunnel 模式的优点
单臂模式,对 lvs 负载压力小
对数据包修改较小,信息保存完整
可跨机房(不过在国内实现有难度)
Tunnel 模式的缺点
需要在后端服务器安装配置 ipip 模块
需要在后端服务器 tunl0 配置 vip
隧道头部的加入可能导致分片,影响服务器性能
隧道头部 IP 地址固定,后端服务器网卡 hash 可能不均
不支持端口映射
Tunnel 模式的使用场景
理论上,如果对转发性能要求较高,且有跨机房需求,Tunnel 可能是较好的选择。
到此为止,已经将 LVS 原理讲清楚了,内容比较多,建议多看两遍,由于文章篇幅太长,实践操作的内容就放到下篇文章再来讲好了。
推荐阅读:
刚刚用华为鸿蒙跑了个“hello world”!跑通后,我特么开始怀疑人生....
5T技术资源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,单片机,树莓派,等等。在公众号内回复「1024」,即可免费获取!!