
同事问我MySQL怎么递归查询,我懵逼了...
前言
最近在做的业务场景涉及到了数据库的递归查询。我们公司用的 Oracle ,众所周知,Oracle 自带有递归查询的功能,所以实现起来特别简单。
但是,我记得 MySQL 是没有递归查询功能的,那 MySQL 中应该怎么实现呢?
于是,就有了这篇文章。
文章主要知识点:
Oracle 递归查询, start with connect by prior 用法
find_in_set 函数
concat,concat_ws,group_concat 函数
MySQL 自定义函数
手动实现 MySQL 递归查询
Oracle 递归查询
在 Oracle 中是通过 start with connect by prior 语法来实现递归查询的。
按照 prior 关键字在子节点端还是父节点端,以及是否包含当前查询的节点,共分为四种情况。
prior 在子节点端(向下递归)
第一种情况:start with 子节点id = ' 查询节点 ' connect by prior 子节点id = 父节点id
select * from dept start with id='1001' connet by prior id=pid;
这里,按照条件 id='1001' 对当前节点以及它的子节点递归查询。查询结果包含自己及所有子节点。
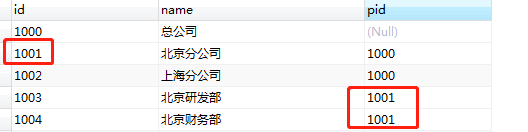
第二种情况:start with 父节点id= ' 查询节点 ' connect by prior 子节点id = 父节点 id
select * from dept start with pid='1001' connect by prior id=pid;
这里,按照条件 pid='1001' 对当前节点的所有子节点递归查询。查询结果只包含它的所有子节点,不包含自己。
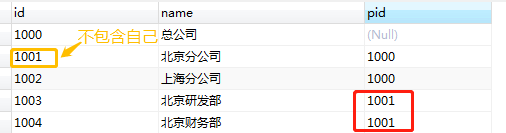
其实想一想也对,因为开始条件是以父节点为根节点,且向下递归,自然不包含当前节点。
prior 在父节点端(向上递归)
第三种情况:start with 子节点id= ' 查询节点 ' connect by prior 父节点id = 子节点id
select * from dept start with id='1001' connect by prior pid=id;
这里按照条件 id='1001' ,对当前节点及其父节点递归查询。查询结果包括自己及其所有父节点。
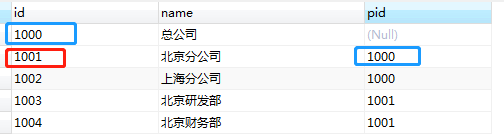
第四种情况:start with 父节点id= ' 查询节点 ' connect by prior 父节点id = 子节点id
select * from dept start with pid='1001' connect by prior pid=id;
这里按照条件 pid='1001',对当前节点的第一代子节点以及它的父节点递归查询。查询结果包括自己的第一代子节点以及所有父节点。(包括自己)
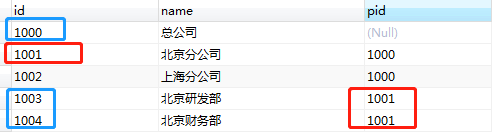
其实这种情况也好理解,因为查询开始条件是以 父节点为根节点,且向上递归,自然需要把当前父节点的第一层子节点包括在内。
以上四种情况初看可能会让人迷惑,容易记混乱,其实不然。
我们只需要记住 prior 的位置在子节点端,就向下递归,在父节点端就向上递归。
开始条件若是子节点的话,自然包括它本身的节点。
开始条件若是父节点的话,则向下递归时,自然不包括当前节点。而向上递归,需要包括当前节点及其第一代子节点。
MySQL 递归查询
可以看到,Oracle 实现递归查询非常的方便。但是,在 MySQL 中并没有帮我们处理,因此需要我们自己手动实现递归查询。
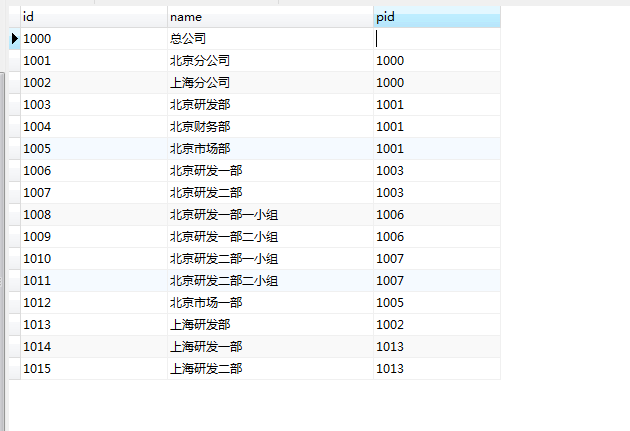
为了方便,我们创建一个部门表,并插入几条可以形成递归关系的数据。
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`id` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`pid` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1000', '总公司', NULL);
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1001', '北京分公司', '1000');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1002', '上海分公司', '1000');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1003', '北京研发部', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1004', '北京财务部', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1005', '北京市场部', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1006', '北京研发一部', '1003');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1007', '北京研发二部', '1003');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1008', '北京研发一部一小组', '1006');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1009', '北京研发一部二小组', '1006');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1010', '北京研发二部一小组', '1007');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1011', '北京研发二部二小组', '1007');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1012', '北京市场一部', '1005');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1013', '上海研发部', '1002');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1014', '上海研发一部', '1013');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1015', '上海研发二部', '1013');
没错,刚才 Oracle 递归,就是用的这张表。
另外,在这之前,我们需要复习一下几个 MYSQL中的函数,后续会用到。
find_in_set 函数
函数语法:find_in_set(str,strlist)
str 代表要查询的字符串 , strlist 是一个以逗号分隔的字符串,如 ('a,b,c')。
此函数用于查找 str 字符串在字符串 strlist 中的位置,返回结果为 1 ~ n 。若没有找到,则返回0。
举个栗子:
select FIND_IN_SET('b','a,b,c,d');
结果返回 2 。因为 b 所在位置为第二个子串位置。

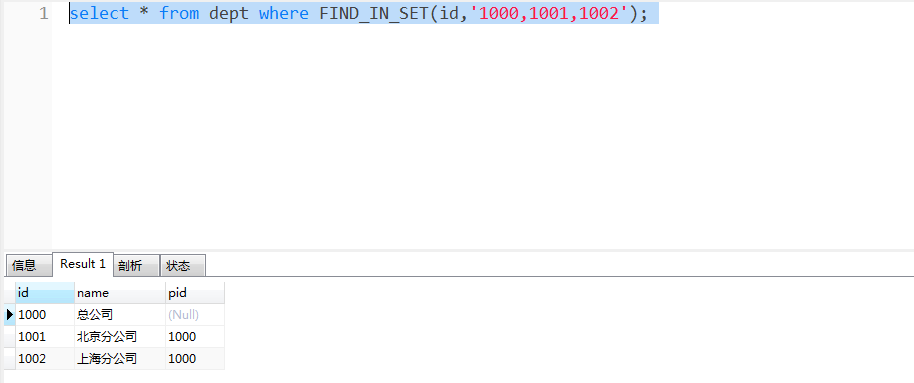
此外,在对表数据进行查询时,它还有一种用法,如下:
select * from dept where FIND_IN_SET(id,'1000,1001,1002');
结果返回所有 id 在 strlist 中的记录,即 id = '1000' ,id = '1001' ,id = '1002' 三条记录。
看到这,对于我们要解决的递归查询,不知道你有什么启发没。
以向下递归查询所有子节点为例。我想,是不是可以找到一个包含当前节点和所有子节点的以逗号拼接的字符串 strlist,传进 find_in_set 函数。就可以查询出所有需要的递归数据了。
那么,现在问题就转化为怎样构造这样的一个字符串 strlist 。
这就需要用到以下字符串拼接函数了。
concat,concat_ws,group_concat 函数
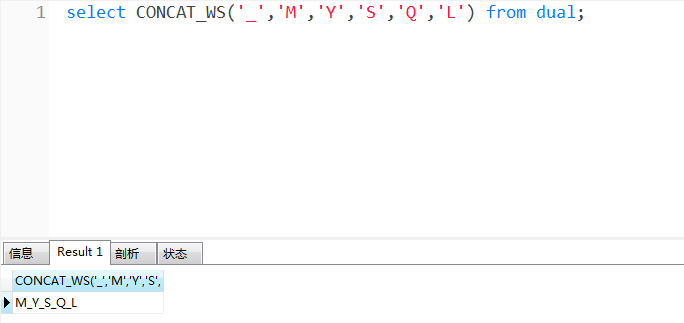
一、字符串拼接函数中,最基本的就是 concat 了。它用于连接N个字符串,如,
select CONCAT('M','Y','S','Q','L') from dual;
结果为 'MYSQL' 字符串。

二、concat 是以逗号为默认的分隔符,而 concat_ws 则可以指定分隔符,第一个参数传入分隔符,如以下划线分隔。
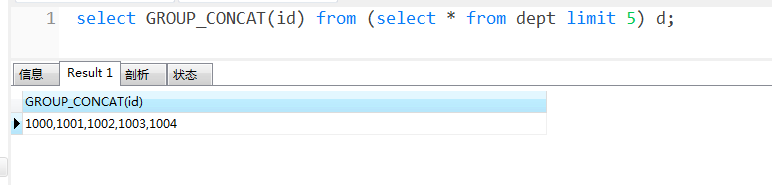
三、group_concat 函数更强大,可以分组的同时,把字段以特定分隔符拼接成字符串。
用法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
可以看到有可选参数,可以对将要拼接的字段值去重,也可以排序,指定分隔符。若没有指定,默认以逗号分隔。
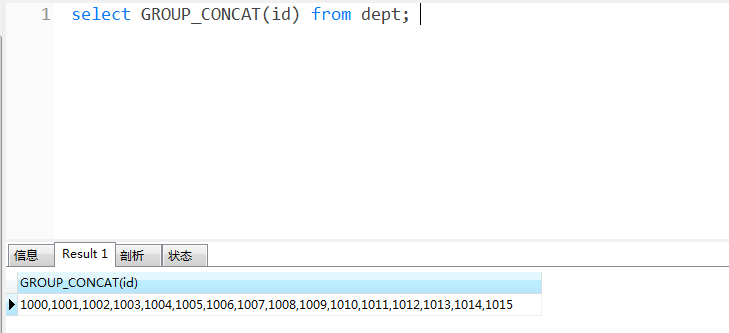
对于 dept 表,我们可以把表中的所有 id 以逗号拼接。(这里没有用到 group by 分组字段,则可以认为只有一组)
MySQL 自定义函数,实现递归查询
可以发现以上已经把字符串拼接的问题也解决了。那么,问题就变成怎样构造有递归关系的字符串了。
我们可以自定义一个函数,通过传入根节点id,找到它的所有子节点。
以向下递归为例。 (讲解自定义函数写法的同时,讲解递归逻辑)
delimiter $$
drop function if exists get_child_list$$
create function get_child_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000) default '';
declare tempids varchar(1000);
set tempids = in_id;
while tempids is not null do
set ids = CONCAT_WS(',',ids,tempids);
select GROUP_CONCAT(id) into tempids from dept where FIND_IN_SET(pid,tempids)>0;
end while;
return ids;
end
$$
delimiter ;
(1) delimiter $$ ,用于定义结束符。我们知道 MySQL 默认的结束符为分号,表明指令结束并执行。但是在函数体中,有时我们希望遇到分号不结束,因此需要暂时把结束符改为一个随意的其他值。我这里设置为 $$,意思是遇到 $$ 才结束,并执行当前语句。
(2)drop function if exists get_child_list$$ 。若函数 get_child_list 已经存在了,则先删除它。注意这里需要用 当前自定义的结束符 $$ 来结束并执行语句。因为,这里需要数和下边的函体单独区分开来执行。
(3)create function get_child_list 创建函数。并且参数传入一个根节点的子节点id,需要注意一定要注明参数的类型和长度,如这里是 varchar(10)。returns varchar(1000) 用来定义返回值参数类型。
(4)begin 和 end 中间包围的就是函数体。用来写具体的逻辑。
(5)declare 用来声明变量,并且可以用 default 设置默认值。
这里定义的 ids 即作为整个函数的返回值,是用来拼接成最终我们需要的以逗号分隔的递归串的。
而 tempids 是为了记录下边 while 循环中临时生成的所有子节点以逗号拼接成的字符串。
(6) set 用来给变量赋值。此处把传进来的根节点赋值给 tempids 。
(7) while do ... end while; 循环语句,循环逻辑包含在内。注意,end while 末尾需要加上分号。
循环体内,先用 CONCAT_WS 函数把最终结果 ids 和 临时生成的 tempids 用逗号拼接起来。
然后以 FIND_IN_SET(pid,tempids)>0 为条件,遍历在 tempids 中的所有 pid ,寻找以此为父节点的所有子节点 id ,并且通过 GROUP_CONCAT(id) into tempids 把这些子节点 id 都用逗号拼接起来,并覆盖更新 tempids 。
等下次循环进来时,就会再次拼接 ids ,并再次查找所有子节点的所有子节点。循环往复,一层一层的向下递归遍历子节点。直到判断 tempids 为空,说明所有子节点都已经遍历完了,就结束整个循环。
这里,用 '1000' 来举例,即是:(参看图1的表数据关系)
第一次循环:
tempids=1000 ids=1000 tempids=1001,1002 (1000的所有子节点)
第二次循环:
tempids=1001,1002 ids=1000,1001,1002 tempids=1003,1004,1005,1013 (1001和1002的所有子节点)
第三次循环:
tempids=1003,1004,1005,1013
ids=1000,1001,1002,1003,1004,1005,1013
tempids=1003和1004和1005及1013的所有子节点
...
最后一次循环,因找不到子节点,tempids=null,就结束循环。
(8)return ids; 用于把 ids 作为函数返回值返回。
(9)函数体结束以后,记得用结束符 $$ 来结束整个逻辑,并执行。
(10)最后别忘了,把结束符重新设置为默认的结束符分号 。
自定义函数做好之后,我们就可以用它来递归查询我们需要的数据了。如,我查询北京研发部的所有子节点。
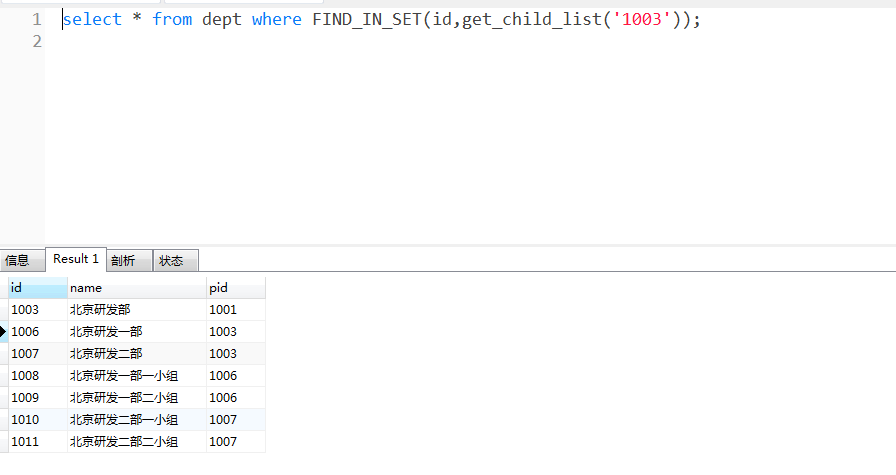
以上是向下递归查询所有子节点的,并且包括了当前节点,也可以修改逻辑为不包含当前节点,我就不演示了。
手动实现递归查询(向上递归)
相对于向下递归来说,向上递归比较简单。
因为向下递归时,每一层递归一个父节点都对应多个子节点。
而向上递归时,每一层递归一个子节点只对应一个父节点,关系比较单一。
同样的,我们可以定义一个函数 get_parent_list 来获取根节点的所有父节点。
delimiter $$
drop function if exists get_parent_list$$
create function get_parent_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000);
declare tempid varchar(10);
set tempid = in_id;
while tempid is not null do
set ids = CONCAT_WS(',',ids,tempid);
select pid into tempid from dept where id=tempid;
end while;
return ids;
end
$$
delimiter ;
查找北京研发二部一小组,以及它的递归父节点,如下:
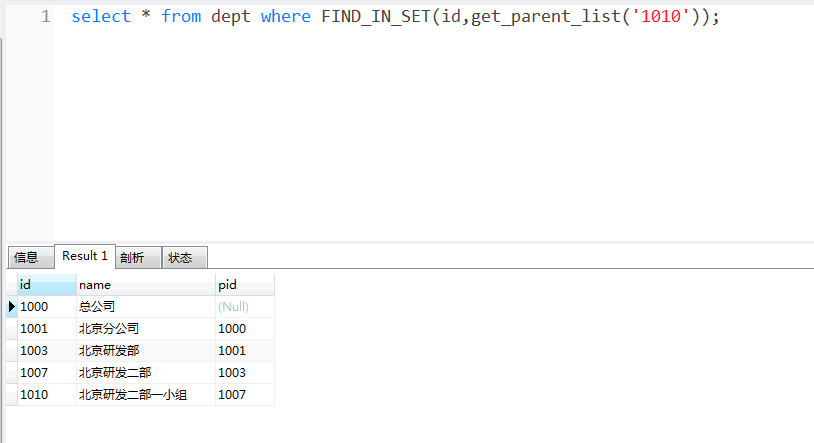
注意事项
我们用到了 group_concat 函数来拼接字符串。但是,需要注意它是有长度限制的,默认为 1024 字节。可以通过 show variables like "group_concat_max_len"; 来查看。
注意,单位是字节,不是字符。在 MySQL 中,单个字母占1个字节,而我们平时用的 utf-8下,一个汉字占3个字节。
这个对于递归查询还是非常致命的。因为一般递归的话,关系层级都比较深,很有可能超过最大长度。(尽管一般拼接的都是数字字符串,即单字节)
所以,我们有两种方法解决这个问题:
修改 MySQL 配置文件 my.cnf ,增加 group_concat_max_len = 102400 #你要的最大长度。执行以下任意一个语句。 SET GLOBAL group_concat_max_len=102400;或者SET SESSION group_concat_max_len=102400;他们的区别在于,global是全局的,任意打开一个新的会话都会生效,但是注意,已经打开的当前会话并不会生效。而 session 是只会在当前会话生效,其他会话不生效。 共同点是,它们都会在 MySQL 重启之后失效,以配置文件中的配置为准。所以,建议直接修改配置文件。102400 的长度一般也够用了。假设一个id的长度为10个字节,也能拼上一万个id了。

有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️