
深入理解HBase Memstore
MemStore是HBase非常重要的组成部分,深入理解MemStore的运行机制、工作原理、相关配置,对HBase集群管理以及性能调优有非常重要的帮助。

首先通过简单介绍HBase的读写过程来理解一下MemStore到底是什么,在何处发挥作用,如何使用到以及为什么要用MemStore。
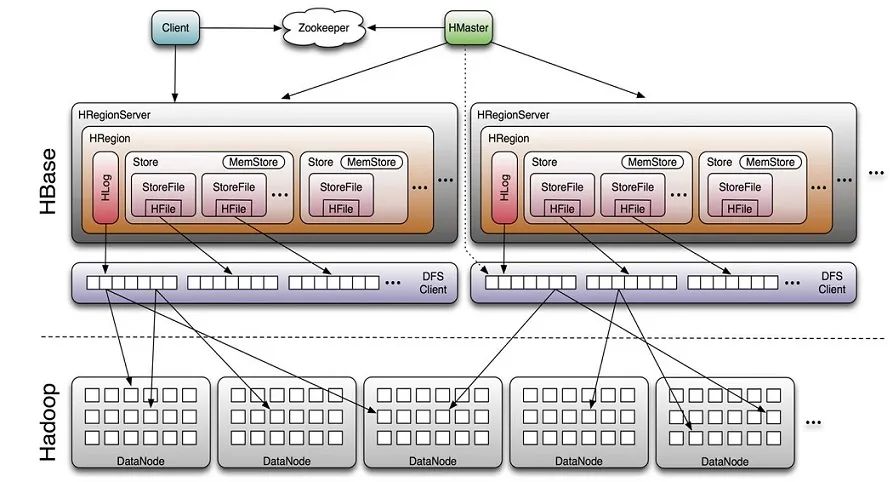
图一:Memstore Usage in HBase Read/Write Paths
当RegionServer(RS)收到写请求的时候(write request),RS会将请求转至相应的Region。每一个Region都存储着一些列(a set of rows)。根据其列族的不同,将这些列数据存储在相应的列族中(Column Family,简写CF)。不同的CFs中的数据存储在各自的HStore中,HStore由一个Memstore及一系列HFile组成。Memstore位于RS的主内存中,而HFiles被写入到HDFS中。当RS处理写请求的时候,数据首先写入到Memstore,然后当到达一定的阀值的时候,Memstore中的数据会被刷到HFile中。
用到Memstore最主要的原因是:存储在HDFS上的数据需要按照row key 排序。而HDFS本身被设计为顺序读写(sequential reads/writes),不允许修改。这样的话,HBase就不能够高效的写数据,因为要写入到HBase的数据不会被排序,这也就意味着没有为将来的检索优化。为了解决这个问题,HBase将最近接收到的数据缓存在内存中(in Memstore),在持久化到HDFS之前完成排序,然后再快速的顺序写入HDFS。需要注意的一点是实际的HFile中,不仅仅只是简单地排序的列数据的列表,详见Apache HBase I/O – HFile。
除了解决“无序”问题外,Memstore还有一些其他的好处,例如:
·作为一个内存级缓存,缓存最近增加数据。一种显而易见的场合是,新插入数据总是比老数据频繁使用。
·在持久化写入之前,在内存中对Rows/Cells可以做某些优化。比如,当数据的version被设为1的时候,对于某些CF的一些数据,Memstore缓存了数个对该Cell的更新,在写入HFile的时候,仅需要保存一个最新的版本就好了,其他的都可以直接抛弃。
有一点需要特别注意:每一次Memstore的flush,会为每一个CF创建一个新的HFile。 在读方面相对来说就会简单一些:HBase首先检查请求的数据是否在Memstore,不在的话就到HFile中查找,最终返回merged的一个结果给用户。
迫于以下几个原因,HBase用户或者管理员需要关注Memstore并且要熟悉它是如何被使用的:
·Memstore有许多配置可以调整以取得好的性能和避免一些问题。HBase不会根据用户自己的使用模式来调整这些配置,你需要自己来调整。
·频繁的Memstore flush会严重影响HBase集群读性能,并有可能带来一些额外的负载。
·Memstore flush的方式有可能影响你的HBase schema设计
接下来详细讨论一下这些要点:
对Memstore Flush来说,主要有两组配置项:
·决定Flush触发时机
·决定Flush何时触发并且在Flush时候更新被阻断(block)
第一组是关于触发“普通”flush,这类flush发生时,并不影响并行的写请求。该类型flush的配置项有:
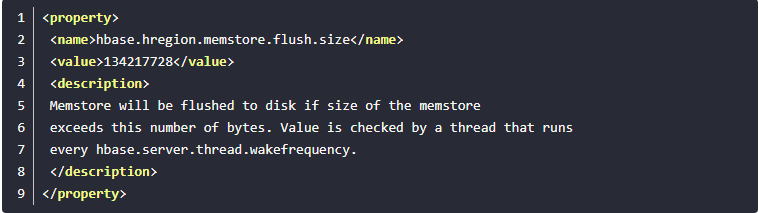
base.regionserver.global.memstore.lowerLimit
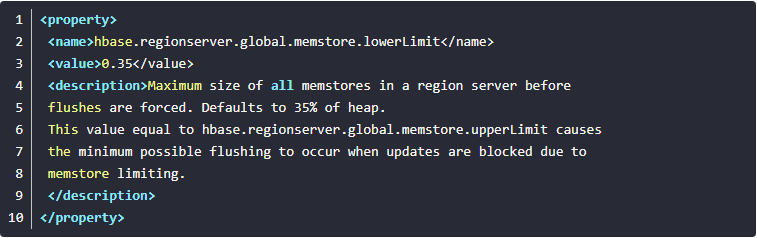
第二组设置主要是出于安全考虑:有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻止(blocked)一直到memstore恢复到一个“可管理”(manageable)的大小。该类型flush配置项有:需要注意的是第一个设置是每个Memstore的大小,当你设置该配置项时,你需要考虑一下每台RS承载的region总量。可能一开始你设置的该值比较小,后来随着region增多,那么就有可能因为第二个设置原因Memstore的flush触发会变早许多。
·hbase.regionserver.global.memstore.upperLimit
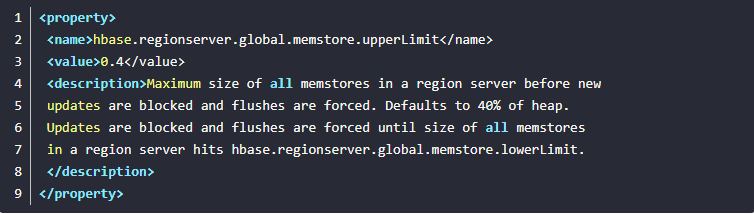
·hbase.regionserver.global.memstore.lowerLimit.

提示:严重关切Memstore的大小和Memstore Flush Queue的大小。理想情况下,Memstore的大小不应该达到hbase.regionserver.global.memstore.upperLimit的设置,Memstore Flush Queue 的size不能持续增长。某个节点“写阻塞”对该节点来说影响很大,但是对于整个集群的影响更大。HBase设计为:每个Region仅属于一个RS但是“写负载”是均匀分布于整个集群(所有Region上)。有一个如此“慢”的节点,将会使得整个集群都会变慢(最明显的是反映在速度上)。
要避免“写阻塞”,貌似让Flush操作尽量的早于达到触发“写操作”的阈值为宜。但是,这将导致频繁的Flush操作,而由此带来的后果便是读性能下降以及额外的负载。
每次的Memstore Flush都会为每个CF创建一个HFile。频繁的Flush就会创建大量的HFile。这样HBase在检索的时候,就不得不读取大量的HFile,读性能会受很大影响。
为预防打开过多HFile及避免读性能恶化,HBase有专门的HFile合并处理(HFile Compaction Process)。HBase会周期性的合并数个小HFile为一个大的HFile。明显的,有Memstore Flush产生的HFile越多,集群系统就要做更多的合并操作(额外负载)。更糟糕的是:Compaction处理是跟集群上的其他请求并行进行的。当HBase不能够跟上Compaction的时候(同样有阈值设置项),会在RS上出现“写阻塞”。像上面说到的,这是最最不希望的。
提示:严重关切RS上Compaction Queue 的size。要在其引起问题前,阻止其持续增大。
想了解更多HFile 创建和合并,可参看 Visualizing HBase Flushes And Compactions。
理想情况下,在不超过hbase.regionserver.global.memstore.upperLimit的情况下,Memstore应该尽可能多的使用内存(配置给Memstore部分的,而不是真个Heap的)。下图展示了一张“较好”的情况:
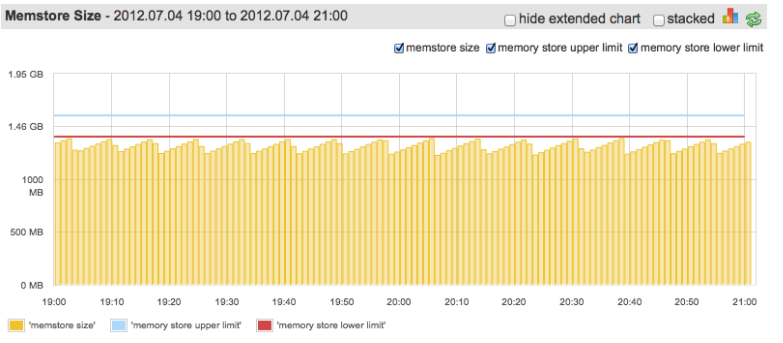
“Somewhat”, because we could configure lower limit to be closer to upper, since we barely ever go over it.
说是“较好”,是因为我们可以将“Lower limit”配置的更接近于“Upper limit”,我们几乎很少有超过它。
每次Memstore Flush,会为每个CF都创建一个新的HFile。这样,不同CF中数据量的不均衡将会导致产生过多HFile:当其中一个CF的Memstore达到阈值flush时,所有其他CF的也会被flush。如上所述,太频繁的flush以及过多的HFile将会影响集群性能。
提示:很多情况下,一个CF是最好的设计。
第一张HBase Read/Write path图中,你可能已经注意到当数据被写入时会默认先写入Write-ahead Log(WAL)。WAL中包含了所有已经写入Memstore但还未Flush到HFile的更改(edits)。在Memstore中数据还没有持久化,当RegionSever宕掉的时候,可以使用WAL恢复数据。
当WAL(在HBase中成为HLog)变得很大的时候,在恢复的时候就需要很长的时间。因此,对WAL的大小也有一些限制,当达到这些限制的时候,就会触发Memstore的flush。Memstore flush会使WAL 减少,因为数据持久化之后(写入到HFile),就没有必要在WAL中再保存这些修改。有两个属性可以配置:
·hbase.regionserver.hlog.blocksize
·hbase.regionserver.maxlogs
你可能已经发现,WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize (2GB by default)决定。一旦达到这个值,Memstore flush就会被触发。所以,当你增加Memstore的大小以及调整其他的Memstore的设置项时,你也需要去调整HLog的配置项。否则,WAL的大小限制可能会首先被触发,因而,你将利用不到其他专门为Memstore而设计的优化。抛开这些不说,通过WAL限制来触发Memstore的flush并非最佳方式,这样做可能会会一次flush很多Region,尽管“写数据”是很好的分布于整个集群,进而很有可能会引发flush“大风暴”。
提示:
最好将hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为稍微大于hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.
HBase建议压缩存储在HDFS上的数据(比如HFiles)。除了节省硬盘空间,同样也会显著地减少硬盘和网络IO。使用压缩,当Memstore flush并将数据写入HDFS时候,数据会被压缩。压缩不会减慢多少flush的处理过程,却会大大减少以上所述问题,例如因为Memstore变大(超过 upper limit)而引起的“写阻塞”等等。
提示:压缩库建议使用Snappy。有关Snappy的介绍及安装,可分别参考:《Hadoop压缩-SNAPPY算法》和《Hadoop HBase 配置 安装 Snappy 终极教程》。
猜你喜欢
HDFS的快照讲解
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个