
干货 | Elasticsearch 可搜索快照深入详解
0、可搜索快照认知前提
Elasticsearch 可搜索快照是 7.10 版本才有的新功能,之前呼声非常高。
Elastic 官方网站用一整页面介绍,可见对该功能的重视。
https://www.elastic.co/cn/elasticsearch/elasticsearch-searchable-snapshots

但,有个细节要跟大家强调:该功能是企业版本才有的收费功能,黄金版、白金版、基础免费开源版本都不具备该功能。
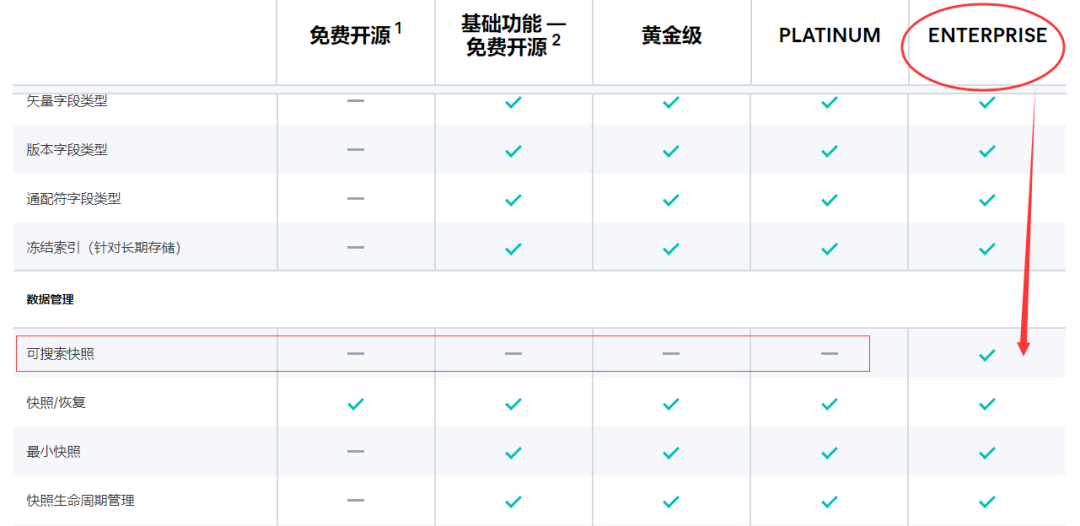
本文的相关实战验证,是基于 30 天试用版本做的验证。

1、什么是可搜索快照?
讲可搜索快照的定义前,先说一下大数据的存储。
对于小微企业来讲,硬件成本是产品、项目环节非常重要的考量因素。数据量的激增和项目的经费之间本来就是相生相克、相爱相杀的关系。
一方面:老板要控制成本的前提下满足甲方的功能需求、性能需求且追求利润最大化。
另一方面:开发人员为满足性能指标最大程度的优化,多少会涉及提升硬件资源配置的需求,比如:换 SSD 磁盘、加内存或更换CPU。
老板会说:经费有限,给老子优化性能,尽一切可能满足甲方的需求。
开发人员心里暗自嘀咕:不给老子提升资源配置,我优化个毛线。
当听说字节跳动线上环境:最小 256 GB内存,多数都是 1TB 内存的时候,除了羡慕还是羡慕。
然后,说一下用户的关注点。
拿大数据舆情场景,当前(此刻为:20210731)用户关注的肯定是时下最热新闻数据:奥运会。一年前的热点:“马老师,很快啊,不讲武德等”即便当时家喻户晓、妇孺皆知,现在看早已“打入冷宫”、“灰飞烟灭”,没有了任何热度可言。
热数据——更多用户关注的热点数据。
冷数据——6个月或1年前(时间自己界定)的热点数据。
热数据、冷数据都要保存怎么办?
一方面:要有足够的磁盘资源,数百TB甚至PB级别磁盘。只有超大规模的企业才有如此财力和资源。
另一方面:划分冷热集群架构,让高配硬件资源(如:SSD磁盘)用到刀刃(如:热点数据)上,冷数据或者低频数据考虑存储到:NFS 磁盘阵列或者云厂商的OSS。
快照:是继副本后保证集群数据高可用的利器。一般高可用的场景:除了副本至少设置为1,还要定期设置增量快照 snapshot。
设置快照的好处就在于:当集群故障时,即便数据丢失,也能通过快照的方式及时恢复。
我们在虚拟机集群 VSphere 中鼓弄虚拟机,一般都在适当的时机设置快照,这和 Elasticsearch 的增量快照是一样的道理。
线上环境不出问题一般都相安无事,一般出现问题多半都和数据有关系,有了快照至少多了一份保障,运维人员会多一份心安。
但是,早期的快照就是“死数据”,是不支持搜索的,但这种使用频次非常低的数据也是有搜索需求的。
传统做法可能是:将很久之前的“冷”数据以快照方式存储(副本设置为0,节约存储),当需要检索的时候,再由快照恢复到索引,实现检索。
势必,这会有较长的时间成本。
可搜索快照就在此大背景下应运而生的。
可搜索快照是指使用快照以极具成本效益的方式搜索不常访问的只读数据。冷数据层和冻结数据层( cold and frozen data tiers )使用可搜索的快照来降低存储和运营成本。
可搜索快照消除了对副本分片的需求(副本默认设置为0),会将搜索数据所需的本地存储减半。可搜索快照依赖于已用于备份的相同快照机制,并保障对快照存储库存储成本的影响最小。
关于快照,如果您感觉不大熟悉或者没有用过,推荐阅读:
干货 | Elasitcsearch7.X集群/索引备份与恢复实战
2、可搜索快照适用场景
可搜索快照非常适合管理大量历史归档数据。
历史信息的搜索频率通常低于最近的数据,因此可能不需要副本以获得性能优势。
对于更复杂或耗时的搜索,你可以将异步搜索与可搜索快照结合使用。
异步搜索推荐:
https://www.elastic.co/guide/en/elasticsearch/reference/current/async-search.html
3、可搜索快照的特点
以下三条内容来自官网文档,为了保证原汁原味,我没有任何删减。3.1、3.2、3.3 要连起来读完才能更好的理解可搜索快照的设计初衷和特点。
https://www.elastic.co/cn/elasticsearch/elasticsearch-searchable-snapshots
3.1 平衡存储成本
时序数据以指数速度增长。而且,随着数据对您的业务和运营方式的影响越来越大,存储和搜索所有数据的成本可能会非常高。
数据层是一种集成的自动化数据生命周期管理方法,它可以帮助您平衡存储成本。
3.2 管理数据生命周期
Elasticsearch 中的重要数据存储在热层中,用于快速搜索查询。随着数据越来越旧,它们变得不再重要,并且搜索的频率也降低了,这些数据会被移动到由较低成本、较低性能的计算和存储节点组成的温层。
‘’当数据变得不太重要且为只读时,会以快照形式将它们存储在对象存储(如 S3)中。但是,要搜索这类数据,需要进行恢复,无法立即进行搜索。
3.3 跳过手动恢复
引入可搜索快照这一功能为 S3 和其他对象存储带来全新的生命力:允许您直接搜索存储在快照中的数据。
在冷层利用可搜索快照,您可以进一步降低多达一半的存储成本,同时兼顾搜索性能。
这是通过将用于获得弹性的数据与用于搜索的数据分开存储来实现的,从而使您能够平衡存储成本和性能以满足您的需求。
4、可搜索快照实战
介绍两种实现方式:手动挂载快照、ILM(索引生命周期管理)可搜索快照。
手动是基础,理解了手动,再理解 ILM 自动管理可搜索快照会很容易。
4.1 手动挂载快照
4.1.1 步骤1:配置快照存储路径及注册快照存储库
在elasticsearch中添加如下配置:
"path.repo: "/www/elasticsearch_0713/elasticsearch-7.13.0/backup"
注册快照存储库(即设置存储路径)
PUT /_snapshot/my_repository
{
"type": "fs",
"settings": {
"location": "/www/elasticsearch_0713/elasticsearch-7.13.0/backup"
}
}
4.1.2 步骤2:为指定索引创建/拍摄快照
PUT my_docs/_doc/1
{
"title": "just testing"
}
PUT /_snapshot/my_repository/snapshot_docs_index?wait_for_completion=true
{
"indices": "my_docs",
"ignore_unavailable": true,
"include_global_state": false
}
前两步中规中矩,都是之前创建非可搜索快照的套路。
也就是说:在没有可搜索快照之前,要创建快照也得这么干。
4.1.3 步骤3:将快照挂载为可搜索的快照索引
这一步我们之前没有见过,这一步就是可搜索快照最为核心的地方。
重中之重:要搜索快照,必须首先将其作为索引挂载到本地。
通常 ILM 会自动执行此操作,手动创建可搜索快照需要自己调用挂载快照 API(这点很重要,后面还会强调一次)。
POST /_snapshot/my_repository/snapshot_docs_index/_mount?wait_for_completion=true
{
"index": "my_docs",
"renamed_index": "docs",
"index_settings": {
"index.number_of_replicas": 0
},
"ignored_index_settings": [ "index.refresh_interval" ]
}
挨个参数解读一下:
index:必须设置,要挂载数据的快照中包含的索引的名称。如果renamed_index不设置,该 index 将用以创建新索引。 renamed_index: 可选,将创建的索引的名称。 index_settings: 挂载时应添加到索引中的设置。 ingored_index_settings:挂载时应从索引中删除的设置。
执行结束,结果如下:
{
"snapshot" : {
"snapshot" : "snapshot_docs_index",
"indices" : [
"docs"
],
"shards" : {
"total" : 1,
"failed" : 0,
"successful" : 1
}
}
}
这里的 my_docs 是快照里面的索引,不是外层的索引,也就是说:把 my_docs 索引(非快照里)删除,上面的挂载操作照样可以运行。
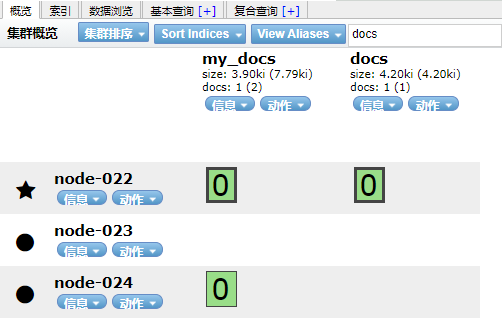
4.1.4 步骤4:挂载完毕后,执行快照搜索
GET docs/_search
4.2 基于 ILM 索引生命周期管理实现自动挂载快照
以下实战演练基于3节点 7.13.0 版本集群。
参见:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/ilm-searchable-snapshot.html
4.2.1 步骤1:注册快照存储库(即设置存储路径)
如下:在elasticsearch.yml 文件中配置。
"path.repo: "/home/elasticsearch/elasticsearch-7.13.0/backup"
PUT /_snapshot/my_repository
{
"type": "fs",
"settings": {
"location": "/home/elasticsearch/elasticsearch-7.13.0/backup"
}
}
4.2.2 步骤2:设置ilm policy
测试需要,刷新值调的很小,实战环境以需求为准。
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
# cold 阶段设置可搜索快照
PUT _ilm/policy/my_custom_policy_filter
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "3d",
"max_docs": 5,
"max_size": "50gb"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "15s",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"require": {
"box_type": "warm"
},
"number_of_replicas": 0
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "20s",
"actions": {
"allocate": {
"require": {
"box_type": "cold"
},
"number_of_replicas": 0
},
"searchable_snapshot": {
"snapshot_repository": "my_repository"
}
}
}
}
}
}
4.2.3 步骤3:创建模板,关联配置的ilm_policy
PUT _index_template/timeseries_template
{
"index_patterns": ["timeseries-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_custom_policy_filter",
"index.lifecycle.rollover_alias": "timeseries",
"index.routing.allocation.require.box_type": "hot"
}
}
}
4.2.4 步骤4:创建起始索引(便于滚动)
PUT timeseries-000001
{
"aliases": {
"timeseries": {
"is_write_index": true
}
}
}
4.2.5:批量插入数据,验证滚动和可搜索快照。
PUT timeseries/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
PUT timeseries/_bulk
{"index":{"_id":5}}
{"title":"testing 05"}
# # 临界值(会滚动至下一个索引)
PUT timeseries/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
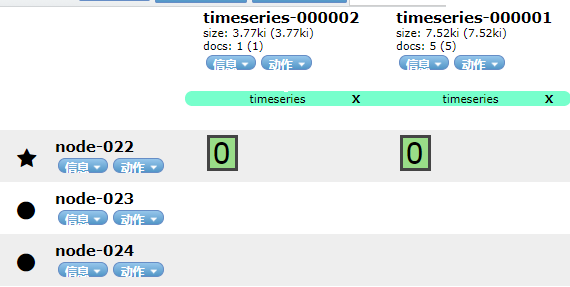
刚执行hot后的索引状态:
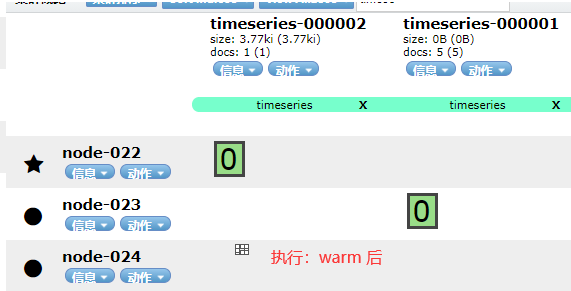
执行完warm后:
执行cold后的索引状态:
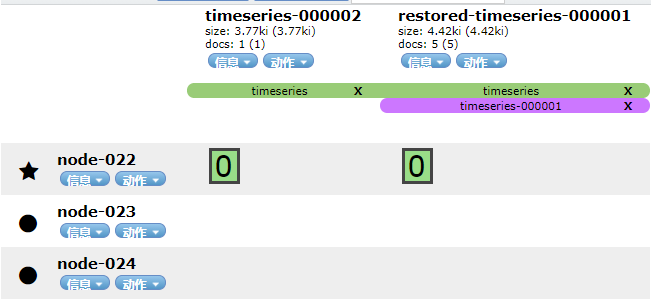
cold 阶段:原来的timeseries-000001不再存在,形成可搜索快照。索引名称前面加了前缀:restored-*,之前的索引名称变成了别名。
相比于手动实现,不需要人为实现挂载环节,ILM自动后台实现。
这点,官方文档也有强调:“Usually ILM will do this automatically, but you can also call the mount snapshot API yourself. ”。
到了这一步,下面就可以对可搜索快照进行检索了:
# 基于可搜索快照索引检索
POST restored-timeseries-000001/_search
# 基于别名检索
POST timeseries/_search
POST timeseries-000001/_search
5、可搜索快照的工作原理
当从快照挂载索引时,Elasticsearch 将其分片分配给集群内的数据节点。然后,数据节点根据指定的挂载选项自动从存储库检索相关分片数据到本地存储。如果可能,搜索使用本地存储中的数据。如果数据在本地不可用,Elasticsearch 会从快照存储库找它需要的数据。
如果持有这些分片之一的节点出现故障,Elasticsearch 会自动将受影响的分片分配到另一个节点上,并且该节点从存储库中恢复相关的分片数据。不需要副本,也不需要复杂的监控或处理来恢复丢失的分片。
尽管默认情况下可搜索快照索引没有副本,但仍可以通过调整 index.number_of_replicas 将副本添加到这些索引中。可搜索快照分片的副本通过从快照存储库复制数据来恢复,就像可搜索快照分片的主分片一样。相比之下,常规索引的副本是通过从主数据库复制数据来恢复的。
6、可搜索快照常见问题?
6.1 如何区分正常索引和可搜索快照索引
ILM 实现的话,看名字,前缀为:restored_*。 手动实现的场景的确不多,自己控制就可以,也可以参考ILM 的实现,设置 renamed_index 的名称。
6.2 除了挂载,还有哪些靠谱API?
获取快照缓存详情
GET /_searchable_snapshots/cache/stats
检索有关可搜索快照的统计信息
GET /_searchable_snapshots/stats
清理可搜索快照的缓存
POST /_searchable_snapshots/cache/clear
7、小结
实战出真知。本文讲解了可搜索快照的产生背景、定义、适用场景、特点、工作原理、两种方式实战演练以及常见问题与解答,但这些都是可搜索快照基础内容的冰山一角。
可搜索快照还有很多细节问题待实战验证、讨论。
欢迎大家就可搜索快照问题留言交流。
8、参考
https://www.elastic.co/guide/en/elasticsearch/reference/master/searchable-snapshots-apis.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/ilm-searchable-snapshot.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/searchable-snapshots.html
推荐
